本文首发于: 行者AI
在整篇文章论述开始之前,我们先做一些概念性的讲解铺垫。卷积神经网络的各层卷积单元在模型网络中实际上有充当了目标检测器的作用,尽管没有提供对目标位置的监督。虽然其拥有在卷积层中定位对象的非凡能力,但当使用全连接层进行分类时,这种能力就会丧失。基于此,提出了CAM(类激活映射)的概念,采用全局平均池化,以热力图的形式告诉我们,模型通过哪些像素点得知图片属于某个类别,使模型透明化和具有可解释性,如下图所示:

1. Global Average Pooling的工作机制
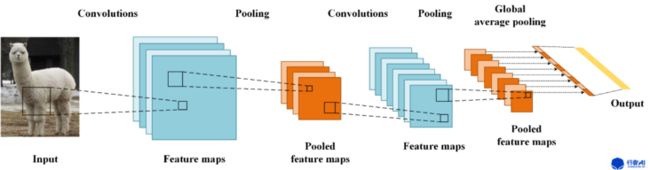
这里我们假设最后的类别数为n,最后一层含有n个特征图,求每张特征图所有像素的平均值,后接入一个有n个神经元的全连接层。要有n个特征图的原因在于,每个特征图主要提取了某一类别相关的某些特征。
2. 什么是CAM?
CNN最后一层特征图富含有最为丰富类别语意信息(可以理解为高度抽象的类别特征),因此CAM基于最后一层特征图进行可视化。CAM能让我们对CNN网络有很好的解释作用,利用特征图权重叠加的原理获得热图,详细工作原理如下图所示。
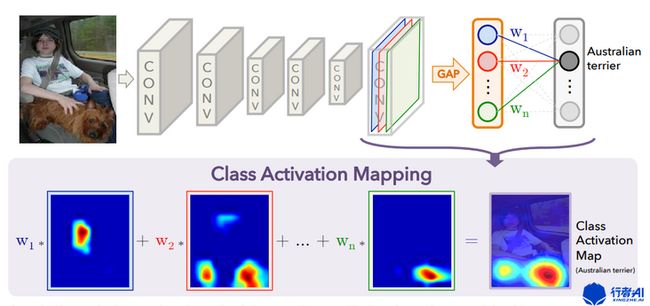
设最后一层有n张特征图,记为$A^1,A^2,...A^n$,分类层中一个神经元有n个权重,一个神经元对应一类,设第$i$个神经元的权重为$w^1,w^2,...w^n$,则第c类的CAM的生成方式为:
$$ L_{CAM}^c = \sum_{i=1}^n w_i^cA^i (式1) $$
生成的CAM大小与最后一层特征图的大小一致,接着进行上采样即可得到与原图大小一致的CAM。
2.1. 为什么如此计算可以得到类别相关区域
用GAP表示全局平均池化函数,沿用上述符号,第c类的分类得分为$S_c$,GAP的权重为$w_i^c$,特征图大小为$c_1*c_2$,第$i$个特征图第$k$行第$j$列的像素值为$A_{kj}^i$,则有:
$$ S_c = \sum_{i=1}^n w_i^c GAP(A_i) $$
$$ = \sum_{i=1}^n w_i^c \frac 1Z \sum_{k=1}^{c_1} \sum_{j=1}^{c_2}A_{kj}^i $$
$$ = \frac 1Z \sum_{i=1}^n \sum_{k=1}^{c_1} \sum_{j=1}^{c_2} w_i^c A_{kj}^i (式2) $$
特征图中的一个像素对应原图中的一个区域,而像素值表示该区域提取到的特征,由上式可知$S_c$的大小由特征图中像素值与权重决定,特征图中像素值与权重的乘积大于0,有利于将样本分到该类,即CNN认为原图中的该区域具有类别相关特征。式1就是计算特征图中的每个像素值是否具有类别相关特征,如果有,我们可以通过上采样,看看这个像素对应的是原图中的哪一部分。GAP的出发点也是如此,即在训练过程中让网络学会判断原图中哪个区域具有类别相关特征,由于GAP去除了多余的全连接层,并且没有引入参数,因此GAP可以降低过拟合的风险。可视化的结果也表明,CNN正确分类的确是因为注意到了原图中正确的类别相关特征。
2.2. CAM缺陷
需要修改网络结构并重新训练模型,导致在实际应用中并不方便。
3. Grad-CAM
3.1. Grad-CAM结构

Grad-CAM 和 CAM 基本思路一样,区别就在于如何获取每个特征图的权重,采用了梯度的全局平均来计算权重。定义了Grad-CAM中第$\kappa$个特征图对应类别c的权重:
$$ \alpha_\kappa^c = \frac 1Z \sum_i \sum_j \frac {y^c}{\alpha A_{ij}^k} (式3) $$
其中,Z表示特征图像素个数,$y^c$表示第c类得分梯度,$A_{ij}^k$表示第$k$个特征图中,$(i,j)$位置处的像素值。然后再求得所有的特征图对应的类别的权重后进行加权求和,这样便可以得到最后的热力图,求和公式如下:
$$ L_{Grad-CAM}^c = ReLU(\sum_k \alpha_k^c A^k)(式4) $$
3.2. Grad-CAM效果
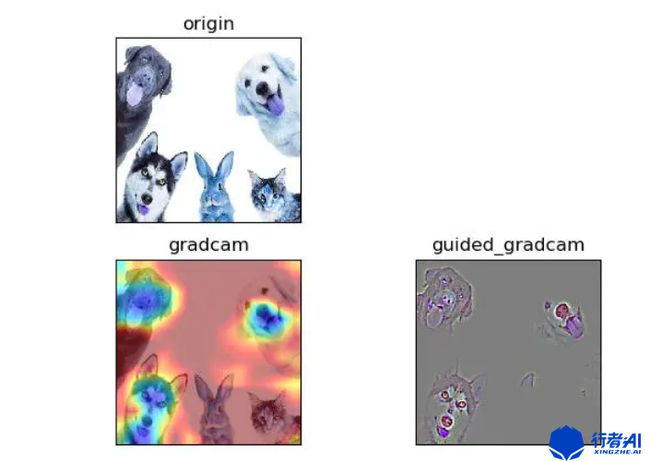
4. 结论
可视化可以进一步区别分类,准确地更好地揭示分类器的可信赖性,并帮助识别数据集中的偏差。真正的AI应用,也更应该让人们信任和使用它的行为。
5. 代码实现
https://github.com/jacobgil/keras-cam
参考文献
- B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene cnns. International Conference on Learning Representations, 2015.
- Computers - Computer Graphics; Investigators from Georgia Institute of Technology Have Reported New Data on Computer Graphics (Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization). 2020, :355-.