本周AI热点回顾:伯克利大神一人投中16篇:ICLR 2021论文接收统计出炉
点击左上方蓝字关注我们

01
伯克利大神一人投中16篇:ICLR 2021论文接收统计出炉
ICLR 2021 会议中投稿量和论文接收量最多的作者和机构都有哪些?这个 GitHub 项目做了一个统计。
人工智能顶会 ICLR 2021 于 1 月 12 日放出了今年的论文接收结果。此次会议共收到 2997 篇有效投稿,最终接收 860 篇,其中 53 篇为 Oral 论文,114 篇 Spotlight 论文,其余为 Poster 论文。接收率为 29%,相比去年的 26.5% 有所提升。
近日,斯坦福大学在读博士 Sharon Zhou 整理了 ICLR 2021 的论文统计结果,包括作者、机构等信息。
项目地址:https://github.com/sharonzhou/ICLR2021-Stats
ICLR 2021 论文作者统计结果
该项目统计了 ICLR 2021 被接收论文数量最多的 top 20 作者,其中 UC 伯克利电气工程与计算机科学系(EECS)助理教授 Sergey Levine 以 16 篇接收论文数量名列第一,2018 年图灵奖得主、深度学习先驱 Yoshua Bengio 紧随其后,共有 10 篇论文被接收。
值得一提的是,Sergey Levine 在此前的 NeurIPS 2020 大会上也有 12 篇论文被收录,排名第一,NeurIPS 2019 的数据也是一样。他的研究方向主要集中在控制与机器学习之间的交叉融合。
此外,该名单中还有多名华人作者,如 UT Austin 助理教授汪张扬(Zhangyang Wang)、微软亚洲研究院副院长刘铁岩等。

ICLR 2021 会议中被接收论文数量最多的 top 20 作者。
上述 top 20 作者的论文接收率情况参见下图:

如果仅仅简单统计人名的话,论文数量榜前列均为教授。该项目还统计了 ICLR 2021 会议以第一作者身份投稿数量最多的 top 20 作者,可以看到其中华人占一半以上。百度旧金山实验室的研究科学家 Yuanpeng Li 有五篇论文,与 Dani Kiyasseh 并列第一。
ICLR 2021 论文列表参见:
https://openreview.net/group?id=ICLR.cc/2021/Conference
信息来源:机器之心
02
击败酷睿i9之后,有人又拿苹果M1去挑战英伟达V100了
有工程师用 M1 版 Mac Mini 训练小架构深度学习模型,结果好像还可以。
众所周知,大多数 Mac 产品都是生产力工具,你甚至可以用它们训练神经网络。去年 11 月推出的,搭载 M1 芯片的 Mac 更是将这种生产力水平提到了一个新的高度。
那么,如果拎出来和专业的比一下,M1 版的 Mac 在训练模型方面是个什么水平?为了解答这个疑问,最近有人将 M1 版的 Mac Mini 与 Nvidia V100 放到一起比了一下。
M1 版 Mac Mini 的售价最低是 5000 元左右。此前,国外知名硬件评测网站 anandtech 发布了对这款产品的详细测试,结果显示,在 CPU 性能测试中,M1 版 Mac Mini 的单线程和多线程都很优秀。在 GPU 性能测试中,它在多个基准测试中超越了之前的 Mac 系列产品,在某些情况下还能超越独显产品。
Nvidia V100 则是专业的 AI 训练卡,单精度浮点性能达到 15 TFLOPS,双精度浮点 7.5 TFLOPS,显存带宽 900GB/s,售价高达五位数。当然,你可以选择在 Colab 上租用。

评测者是「Weights and Biases」公司的联合创始人 Chris Van Pelt。Weights and Biases 简称 W&B,是一家致力于机器学习工具开发的公司。
为了进行这次测试,作者设计了 8 种不同的训练设置。结果显示,对于较小的架构和数据集,苹果 M1 的性能与 Nvidia V100 的差距并没有想象中那么大,而且在能效等方面表现要更为出色。

信息来源:机器之心
03
Github全球趋势榜Python区第一!覆盖CV任务,带GUI Demo,还有超多产业项目实践
宁德时代、广东电网电科院、机科院等等巨头都在用的AI算法开发神器PaddleX又升级了!它不仅为产业开发者提供面向实践的AI算法训练及部署方式,使开发者无需数学基础,即可快速训练AI算法并投产应用,而且此次新版本的PaddleX中新增了RESTful API模块,使开发者可以自由搭建定制化的AI开发软件。简直是猜透了产业开发者的心~
下面就让我们详细看看这个在短短几个月的时间里,两次登上Github Daily全球趋势榜,迅速获得1.1k Star的项目,它到底有什么过人之处呢?
它包含通用图像分类、目标检测、语义分割、实例分割的高性能算法及预训练模型,且可以满足移动端,服务端等对模型轻量化、高精度、高推理速度的诉求。
提供工业、遥感、互联网等行业的完整项目示例,包括从数据集处理到部署的端到端流程,以及从多模型串联到可视化推理等实用方案级别的讲解说明,简直是保姆级指南!

支持可视化界面,无代码完成AI算法训练!也太神奇了吧!
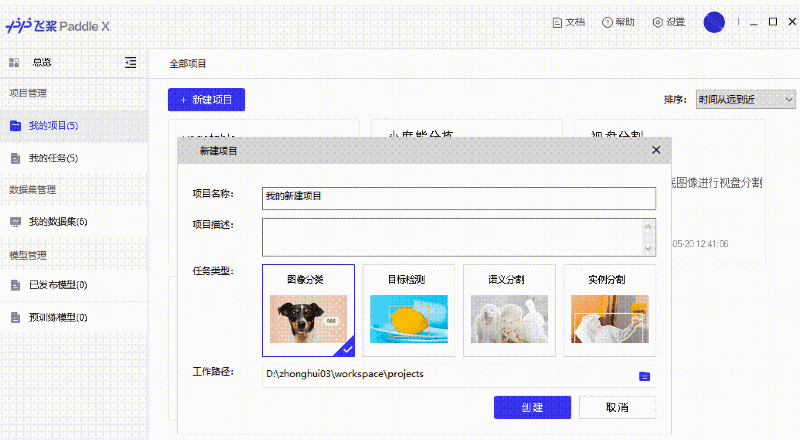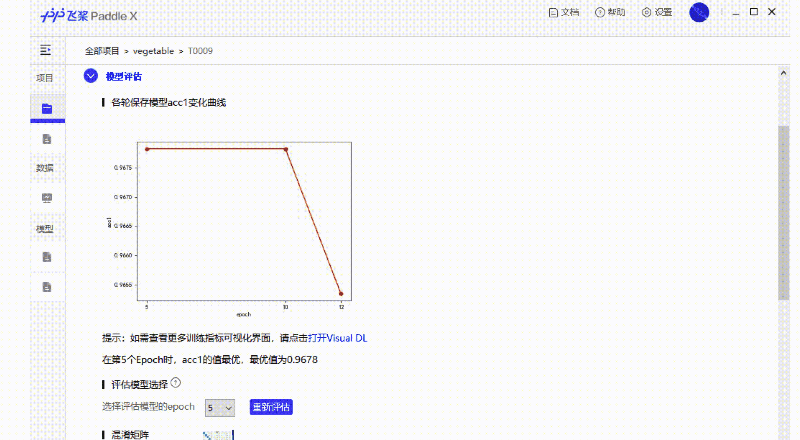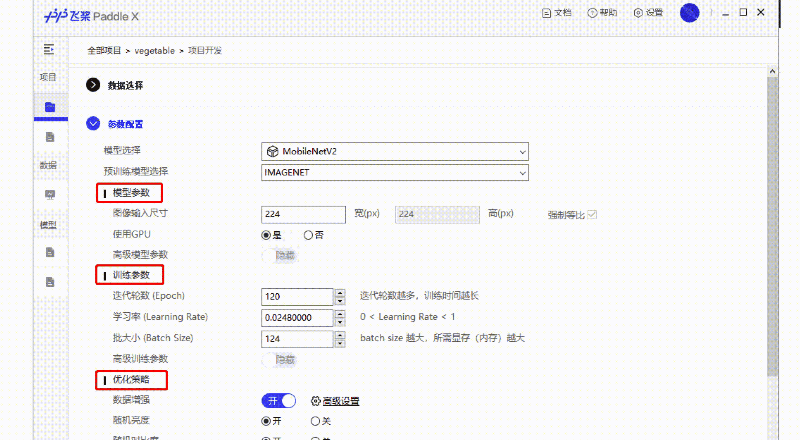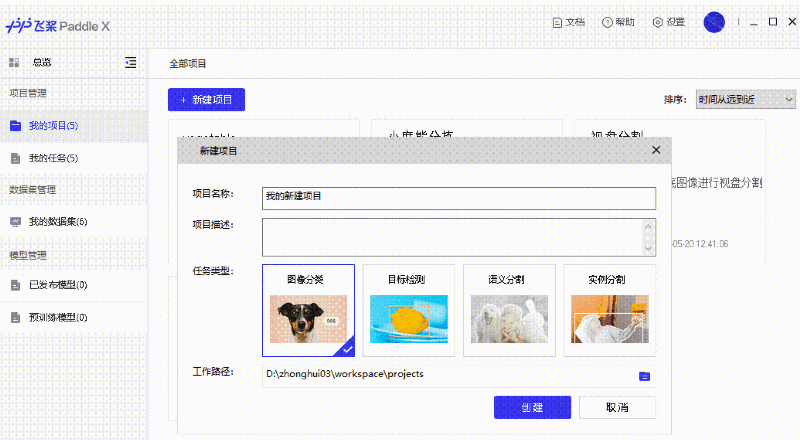
支持使用面向实践的极简API接口直接开发。最少4个API即可完成深度学习算法训练,真香!
不仅覆盖数据标注、模型训练、模型部署,还提供模型量化压缩、模型加密部署等功能。
可一键下载图形化界面,也可直接pip install安装后通过API开发,并且RESTful API更可以帮助开发者自主定制AI开发平台或无缝集成原有系统。为了使开发者方便开发参考,PaddleX还提供了RESTful API Demo示例代码覆盖开发全流程,简直太贴心了!
项目链接:
https://github.com/PaddlePaddle/PaddleX

信息来源:飞桨PaddlePaddle
04
ImageNet的top-1终于上了90%,网友质疑:用额外数据集还不公开,让人怎么信服?
近日,谷歌大脑研究科学家、AutoML 鼻祖 Quoc Le 发文表示,他们提出了一种新的半监督学习方法,可以将模型在 ImageNet 上的 top-1 准确率提升到 90.2%,与之前的 SOTA 相比实现了 1.6% 的性能提升。

这一成果刷新了 Quoc Le 对于 ImageNet 的看法。2016 年左右,他认为深度学习模型在 ImageNet 上的 top-1 准确率上限是 85%,但随着这一数字被多个模型不断刷新,Quoc Le 也开始对该领域的最新研究抱有更多期待。而此次 90.2% 的新纪录更是让他相信:ImageNet 的 top-1 还有很大空间。

Quoc Le 介绍称,为了实现这一结果,他们使用了一种名为「元伪标签(Meta Pseudo Label)」的半监督学习方法来训练 EfficientNet-L2。
和伪标签(Pseudo Label)方法类似,元伪标签方法有一个用来在未标注数据上生成伪标签并教授学生网络的教师网络。然而,与教师网络固定的伪标签方法相比,元伪标签方法有一个从学生网络到教师网络的反馈循环,其教师网络可以根据学生网络在标记数据集上的表现进行调整,即教师和学生同时接受训练,并在这一过程中互相教授。

这篇有关元伪标签的论文最早提交于 2020 年 3 月,最近又放出了最新版本。

论文链接:https://arxiv.org/pdf/2003.10580.pdf
代码链接:https://github.com/google-research/google-research/tree/master/meta_pseudo_labels
在新版本中,研究者针对元伪标签方法进行了实验,用 ImageNet 数据集作为标记数据,JFT-300M 作为未标记数据。他们利用元伪标签方法训练了一对 EfficientNet-L2 网络,其中一个作为教师网络,另一个作为学生网络。最终,他们得到的学生模型在 ImageNet ILSVRC 2012 验证集上实现了 90.2% 的 top-1 准确率,比之前的 SOTA 方法提升了 1.6 个百分点(此前 ImageNet 上 top-1 的 SOTA 是由谷歌提出的 EfficientNet-L2-NoisyStudent + SAM(88.6%)和 ViT(88.55%))。这个学生模型还可以泛化至 ImageNet-ReaL 测试集,如下表 1 所示。

在 CIFAR10-4K、SVHN-1K 和 ImageNet-10% 上使用标准 ResNet 模型进行的小规模半监督学习实验也表明,元伪标签方法的性能优于最近提出的一系列其他方法,如 FixMatch 和无监督数据增强。
论文作者还表示,他们之所以在方法的命名中采用「meta」这个词,是因为他们让教师网络根据学生网络反馈进行更新的方法是基于双层优化问题(bi-level optimization problem),而该问题经常出现在元学习的相关文献中。
不过,这篇论文也受到了一些质疑,比如使用的数据集 JFT-300M 是未开源的数据集(不知道该数据集中有没有和 ImageNet 测试集相似的图片),导致外部人士很难判断其真正的含金量。
信息来源:机器之心
05
寒武纪首颗AI训练芯片亮相:7纳米制程,算力提升四倍,已规模化出货
1 月 21 日,寒武纪思元 290 智能芯片及加速卡、玄思 1000 智能加速器在官网低调亮相,寒武纪表示该系列产品已实现规模化出货。去年,寒武纪招股书曾简单披露了一款训练芯片的 “彩蛋”,此后,寒武纪思元 290 芯片就一直被业界广泛关注并引发行业诸多猜想。如今,随着新一代训练产品线集中亮相,寒武纪略显“神秘” 的训练芯片及相应的业务布局逐渐清晰。
思元 290 智能芯片是寒武纪的首颗训练芯片,采用台积电 7nm 先进制程工艺,集成 460 亿个晶体管,支持 MLUv02 扩展架构,全面支持 AI 训练、推理或混合型人工智能计算加速任务。

寒武纪首颗训练芯片思元 290
寒武纪 MLU290-M5 智能加速卡搭载思元 290 智能芯片,采用开放加速模块 OAM 设计,具备 64 个 MLU Core,1.23TB/s 内存带宽以及全新 MLU-Link™多芯互联技术,在 350W 的最大散热功耗下提供 AI 算力高达 1024 TOPS(INT4)。
寒武纪玄思 1000 智能加速器,在 2U 机箱内集成 4 颗思元 290 智能芯片,高速本地闪存、Mellanox InfiniBand 网络,对外提供高速 MLU-Link™接口,打破智能芯片、服务器、POD 与集群的传统数据中心横向扩展架构,实现 AI 算力在计算中心级纵向扩展,是 AI 算力的高集成度平台。
寒武纪训练产品线采用自适应精度训练方案,面向互联网、金融、交通、能源、电力和制造等领域的复杂 AI 应用场景提供充裕算力,推动人工智能赋能产业升级。
信息来源:机器之心
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
