一文搞懂知识蒸馏
关注公众号"DataPlayer"
重磅机器学习干货,第一时间送达

知识蒸馏(Knowledge Distilling),你或许在吃饭的间隔,在电梯间的片刻,多多少少都听身边的算法狗聊到过这个名词,却因为它晦涩无比,没有深究;那它背后隐藏了什么算法呢~?小喵今天就用简单的描述,带大家一起了解了解它~
话题1:什么是知识?
在日常生活中,我们对客观世界的认知,就是一种知识;但是这不是我们今天的主角--【知识蒸馏】所描述的"知识",在算法的世界里呢~我们的网络模型就代表了类似人脑神经元的结构,那么反之,知识,也可以解读为人脑神经元的某些关系或者状态,对应的,在神经网络模型中,知识也就可以理解为模型中的参数权重啦~
所以我们关注的主角【知识蒸馏】中的"知识",其实指的就是对于网络模型中参数权重的一些抽取/迁移的操作~
话题2:那什么是蒸馏呢?
蒸馏,我们都知道,从一些混合液体中蒸馏出纯净水就是蒸馏嘛,那对于深度神经网络来讲,蒸馏又是什么意思呢~?我们先埋一个坑~
说这么虚,我们还是不知道这个【知识蒸馏】是做什么的啊!
![]()
话题3:知识蒸馏是做什么的?
简而言之,就是模型压缩啦hh(~ ̄▽ ̄)~
我们都知道,在物联网稳步发展的今天,许多深度学习算法已经不适合部署在强大的的服务器上了:
好比说智能音箱(小爱同学,小度小度)上的语音识别算法,如果我们将唤醒词识别的算法部署在云端服务器,那我们的云端服务器持续接收终端设备的请求,重复得判断一件事:这几秒的语音,到底有没有唤醒词?云端服务器一定会肥肠崩溃的(T▽T),所以呢我们就要把算法部署在cpu内存状态都比较辣鸡的设备终端上~这样一来,算法就不能过于复杂,过于复杂的算法,小小cpu可是会表示带不动.......所以我们就需要一些模型压缩方面的技术,让小小辣鸡cpu,也能有还不错的效果~!!
那诸如此类的算法还有很多辣~好比移动端视觉上面的识别技术啊,搜狗输入法的智能纠错啊~等等;即使我们是在云端做算法,也要考虑到整个服务的平响时间,内存占用,cpu占用等因素,尽量节省计算资源,不能铺张浪费是不是~(〃'▽'〃)

话题4:那模型压缩一般有什么其他的方法呢~?
当然也有了~不使用我们今天的主角:【知识蒸馏】的话,还有一些其他的方法来解决这个巨大的痛点,今天也跟大家简单地分享分享~
方案1:模型剪枝(Model Pruning)
模型剪枝从字面进行理解,也就是删除模型中的一些要素了~方法呢也有好几种:
1.1权重剪枝
也就是将模型中的一些不重要的权重删除~ 最简单的判断"不重要"的方式,就是"约等于0",但是删除后我们会想,这个原来可以被GPU加速的矩阵运算,你删除一些部分,岂不是就不能享受加速的赶脚了呢?(。ì _ í。) 确实是这样的.......那所以,我们将权重变成0怎么样,但是这样又并不能很显著地降低模型的大小啊.......
对,所以这个方法并不是很实用o(╥﹏╥)o
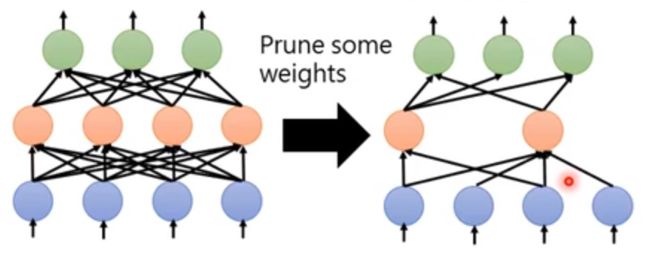
图1.参数剪枝
1.2神经元剪枝
神经元剪枝的操作就很方便了,去掉网络中的一些神经元,哪些呢?其实可以随机选取~~那么对应在实践操作中,删除参数矩阵的一行元素就好啦~~
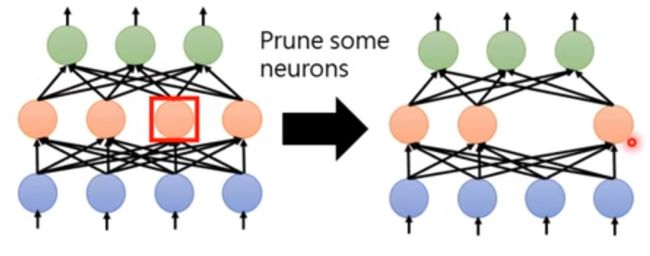
图2.神经元剪枝
但是呢,剪枝有一个究极奥义需要记住:如果你想获得一个减小50%的模型,千万不可以直接踢掉50%的神经元!!需要一点点剔除掉,每次提出掉之后,都需要再训练几个epoch,去fine-tuning剩下的model,不然模型整个剪坏掉了......
说到这里有人会问了(自我捧场......)我为什么要费劲吧啦地训练一个大模型,然后剪枝成小模型,而不是直接训练一个小模型呢???
原因是,很多paper都通过研究得到了这样一个认识:小模型相对大模型而言,更加不容易训练,比方说掉入鞍点出不来啦,拟合能力过弱达不到要求啦~等等,大模型反而没有很多优化上面的问题,虽然很吃数据吧,但是拟合能力很强大!用大模型每一步进行剪枝,就等同于用一个很接近GroundTruth的强大网络,为小模型做pretrain了~~这样小模型效果就好起来了~~~
![]()
方案2:网络架构设计(Network Architecture)
1.1 DNN添加中间层

图2.DNN添加中间层
像图中这样,假设原本我们有一层N个神经元的layer,下面接了一个M个神经元的layer,对于第二层而言,它就有M * N个参数需要拟合;然而,如果我们在这两层中添加一个小于M 和 N的全连接层,有K个神经元,加入之后,虽然新增了一层,但是参数却变小了有没有!! 我们的参数量从M *N降低到了 M *K + N *K ,如果之前我们的M = 500,N = 300的话,选用 K =100的中间层,参数量可以瞬间从15万降低到8万!!
然而模型的拟合能力却并没有降低很多~因为我们可以从矩阵分解的角度理解~ UV两个参数矩阵可以是原M矩阵的奇异值分解矩阵~重要信息都保留啦~
1.2 深度可分离卷积(depthwise separable conv)
如果我们将普通的卷积核称为pointwise的conv,那么深度可分离卷积可以是一种在卷积的基础上降低参数量的方案:
假设我们有一个6*6*2的input feature map,加上4个3*3的卷积核,我们可以使用36个参数,获得一个4*4*4的output feature map的输出~
如果使用深度可分离卷积:
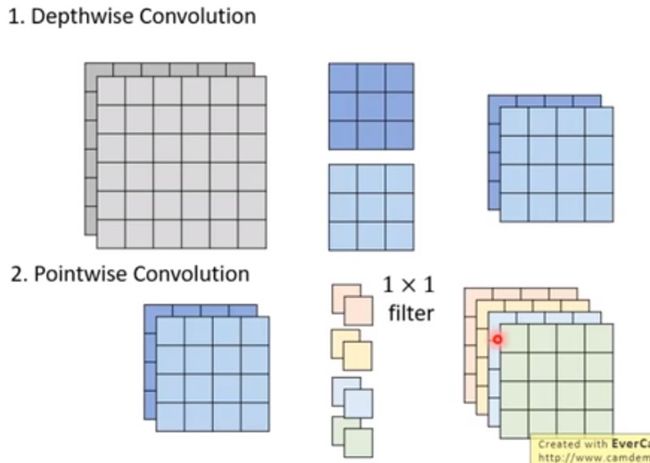
图4.深度可分离卷积
第一步,使用2个depthwise的3*3卷积核,分别负责不同通道上的特征提取;第二步,再通过4个pointwise的1*1*2的卷积核融合各个通道的特征,我们会获得和直接卷积相同的output feature map,但是只试用到了 9*2 + 4*2 = 26个参数!︿( ̄︶ ̄)︿
![]()
那大名鼎鼎的MobileNet就是用到了这个卷积核作为核心设计才如此声名远扬~~
方案3:其他方案
剩下的方案就比较容易想到啦~好比说压缩权重的精度位数啦,将权重分桶聚类啦,这种数值量化的方式,都可以尝试使用~~
话题5:所以讲了半天,知识蒸馏到底怎么压缩模型呢?
知识蒸馏是Hinton老爷子最早提出在【https://arxiv.org/abs/1503.02531】这篇大名鼎鼎的论文当中的,后续有很多基于这篇文章的算法研究,对【知识蒸馏】又有了新的演绎,我们今天还是以这篇开山之作作为对象进行解读~
文章的核心思想是:
我们可以有一个复杂而强大的Teacher Model(简称Net-T),以及另一个简单而弱小的Student Model(简称Net-S),由Net-T完整地学习Ground Truth,然后再由Net-S同时学习Net-T的Logit和Ground Truth,最终Net-S作为应用模型,而Net-T并不进行部署上线
所以呢~知识蒸馏是一种"伪"压缩,或者广义的压缩方法
话题6:为什么要学习logit?
logit是我们模型输出的对于各个类别的概率预测值。
学习logit的一个非常感性的认知是:除了正例GroundTruth之外,负例也携带了很多有价值的信息呀!
比如说:我们有一个手写字体识别分类任务,0~9的数字中,7和1写起来很像,但是7和5就很不像,GroundTruth只告诉了我们,这个图片是7,但是logit还告诉了我们:这个图片大概率是7,小概率是1,几乎不太像其他数字。这其中携带了的信息量,也就是我们后面希望Net-S蒸馏学到的知识!!!ヾ(๑╹◡╹)ノ"
![]()
话题7:Net-S要学习两部分的知识,那损失函数是什么?
![]()
酱酱~Net-S需要学习的两部分知识,分别对应了Net-S的输出和Net-T的分布差异Loss-soft和与GroundTruth的分布差异Loss-hard,我们都知道,交叉熵能很好地表达"分布差异",那因此:
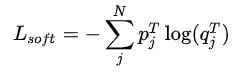
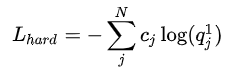
这两部分分布就是损失函数的细分表达啦~~
公式中的p,q,c分别指代什么呢~?q是我们Net-S的输出,p是Net-T的输出,c是Ground Truth,又有大可爱要问了(谁要问你....)那这个q/p的输出就应该是softmax的输出吧~~?
诶嘿,这就是我们知识蒸馏的重头戏了~问题的但是:是,也不是~这个输出叫做softmax-T~是带了参数的softmax哦
话题6:这个softmax-T是啥?
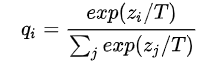
上公式~我们都知道softmax是啥,这个softmax-T的T意思是Temperature,就是一个在softmax操作前需要统一除以的小参数,这个小参数有这样的属性:
如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率;
如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码
如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用
那没事加这个参数做什么呢?原因是这样的:
如果我们使用原始的softmax,我们都明白它的属性,它会使得那个最大值的类别,在经过自然指数操作后,在概率上显得"更大"。举例来说,如果0-9的手写字体识别中,7-1-5这三个数值的预测,在softmax转化前,是[7,2,1],在经过了softmax转化后,基本也就变成和[1,0,0]无差异的一个结果了,这并不是我们想要学习logit的初衷啊(๑ó﹏ò๑)........

我们希望的效果是学习数字1-5直接的差异,然而这点"知识"被正常的softmax给"吃掉了"。所以,我们需要做点小变更,提升我们的温度--Temperature,把本来差异较小的"知识"给"蒸馏"出来,让Net-S能学习到这些知识~~!!
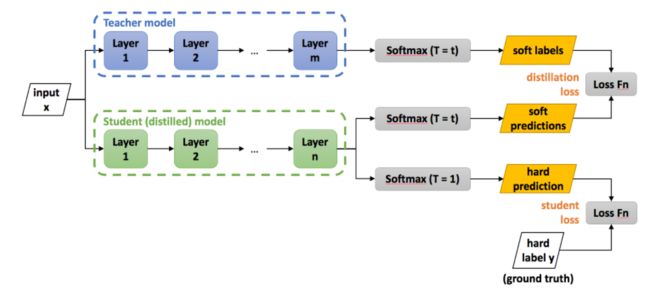
图5.知识蒸馏过程
那么我们回到之前p,q分布来看看:它们都是加了T的softmax哦~
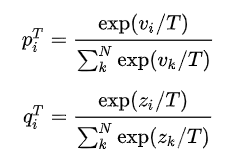
话题7:那要如何实践知识蒸馏呢~?
知识蒸馏中Teacher Model和Student Model并没有太多网络结构上面过多的限制,用nlp领域举例的话~ Teacher Model大可以使用当下应用的很复杂的Bert作为老师,反之是离线训练嘛,又不部署,可是很香啊~Student Model 使用一个不是很深的全连接DNN就行啦~
有的人又会动起聪明的小脑筋了~诶嘿~如果部署一直是一个简单模型的话,那岂不是我可以不更改/很小更改现在的线上模型原型,在离线加一个强大的复杂模型做Teacher,就能让我现在的Model变强啊~~ 是这样的啊~~ 所以快点用起来~~( ˘▽˘)っ
![]()
小喵的福利环节
![]()
关注公众号DataPlayer,后台回复【知识蒸馏代码】
将会放送 tensorflow知识蒸馏实践代码哦~~
小喵才做选择,成年喵,从原理到落地,我都要~!
文章参考:
1.Distilling the Knowledge in a Neural Network
2.李宏毅深度学习