网易伏羲论文入选 CVPR:AI 感知表情能力或实现巨大突破!

出品 | AI科技大本营(ID:rgznai100)
2月28日,人工智能顶级会议CVPR 2021(国际计算机视觉与模式识别会议,Conference onComputer Vision and Pattern Recognition)公布论文录取结果,网易伏羲共有3篇论文入选。
其中,由网易伏羲虚拟人团队发表的一项研究颇为引人关注。该研究提出了一种人类表情编码的创新提取方法,大幅提升了AI感知人类表情的精度。随着该技术的发展,未来,AI感知人类表情的能力甚至有望超越人类感知平均水平。

过去,学术界对人类表情的识别和描述,一般源于两种传统理论:一种源自150年前的达尔文时期,学者们从心理学出发,基于高兴、惊讶、生气、悲伤等有限的情绪类别描述人类表情;另一种起源于上世纪70年代末,知名心理学家Paul Ekman博士从解剖学角度出发,基于人脸肌肉运动,用27种动作单元来描述人类表情。
从数量上看,传统理论对人类表情的描述极为有限。网易伏羲的人类表情编码提取方法,则以人工智能的方式进一步突破了这一瓶颈。通过学习大量的人脸表情数据,AI可以无穷尽、无上限地感知人类表情。
《去ID信息的表情编码》(Learning aFacial Expression Embedding Disentangled from Identity)
论文简介:
本文研究的主要目的,是获取一种紧致的,且与ID信息无关的人脸表情表征。
本研究中,网易伏羲虚拟人团队首次提出,将表情特征建模为从ID身份特征出发的一个差值向量,以这种显式方式去掉ID的影响。为此,本研究设计了一个伪孪生结构的网络去学习这种差值。同时,为了加强网络在深层的学习能力,本研究通过高阶多项式的方法替代一般的全连接层去完成从高维到低维的映射。另外,考虑到不同标注者存在一定标注噪音,本研究增加了众包层学习不同标注者的偏差,使学习到的表情表征更加鲁棒。
定性和定量的实验结果表明,该方法在FEC数据集上超越了前沿水平。同时在情绪识别、图像检索以及人脸表情生成等应以用上都有不错的效果。

(论文的Pipeline)
下图展示了该工作的表情表征编码的效果,输入一张检索(Query)表情,通过比较表情编码的距离,从一个足够大的人脸数据集中检索出与之最相似的一些表情(Results),下图中展示了TOP5的结果。

(本研究中表情表征的效果)
由图可知,所检索出来的图像和目标表情非常接近,说明本研究提出的表情表征编码可以感知微妙且精细的表情。

显性去ID信息的人类表情编码方法的突破性意义
论文中所说显性去ID信息的人类表情编码方法是该论文提出的主要方法,但这个词汇究竟是什么意思,对于人类情感识别来说又怎样的意义?AI科技大本营采访到网易伏羲相关负责人进行了通俗的解释。
专家解释称,人类能够通过面部表情,表达和感知丰富而又细腻的内心状态;让AI能够像人类一样感知人脸的表情,一直是很多计算机科学家的梦想。
长期以来,这个课题的难点在于,AI无法在从一张人脸中准确地区别哪些信息是表情动作(来自于面部肌肉和下颚骨运动)引起的视觉感知,哪些是人脸身份信息(不随表情动作改变的信息,比如:无论什么表情下,都能判断这张脸是谁,这种判断就仅仅依赖人脸身份信息)带来的。
一方面,在人脸身份信息的干扰下,人工智能技术(AI)解读表情的能力一直不够出色,落地应用场景非常有限。另一方面,人脸表情能够表达人类丰富且细腻的内心状态,但此前AI多局限于有限类别的表情识别(例如:高兴、悲伤、生气等),无法感知细腻的人脸表情,更难以进一步理解人类丰富的内心状态。
通俗地说,《去ID信息的表情编码》这篇论文所做的研究,就是在人工智能深度神经网络的框架下,基于人脸身份特征向量,提出“减法”:“减去”人脸身份信息,获得一个差值用以量化表情动作,使得AI能够有效地从一张带表情的人脸图像中,剔除身份信息,仅仅保留表情信息。这样就解决了长期困恼计算机科学家的难题,即无法从一张人脸中,精准地解耦合表情动作和身份信息,避免身份信息对表情动作的干扰,从而提高精度。另一个非常值得关注的突破,是该论文改进了人类表情编码的提取方法,使得AI可以不受限于有限的情绪类别,能够逼近任意粒度地解读人脸表情,大幅提升了AI感知人类表情的精度。
只要能够彻底地从当表情信息中剔除身份信息,同时将表情编码的粒度做到足够细,专家相信,AI解读表情的能力能达到人类的水平。这对于学界和产业界来说,将是代表AI进步的又一里程碑。

数据集将开源
为了让AI更懂人类的喜怒哀乐,技术人员还需要大量细颗粒度、人工标注的人脸表情数据用于算法参数迭代,进一步提升表情编码的精度。专家表示,本论文中的数据均来自Google AI LAB整理的数据集FEC,而网易伏羲的数据采集方式与Google相似。网易伏羲表示,未来他们计划开源这个数据集,与行业共享网易伏羲的最新研究成果,共同加速推进该技术的应用落地。
此外,网易伏羲正在开发一个游戏化标注小程序,让普通用户能够在游戏的过程中参与表情标注,加速推进人类表情领域的人工智能研究与应用。这款游戏化的标注小程序叫做《微表情大师》,目前主要功能已经开发完毕,正在添加更多趣味化的游戏设定,不久之后将推出。

将是学界和产业界的一粒“慢性兴奋剂”
最后是这项研究成果的应用场景。除了性格评估,测谎、自闭症检测、表演能力评估、虚拟人表情丰富度评估等应用场景,这个方法还可以应用于表情检索、人脸表情生成、动漫/游戏模型的表情绑定、表情迁移等方面。以动漫/游戏模型的表情绑定为例,网易伏羲已经可以通过利用这套表情编码,控制一些游戏人物2D图像的表情生成。下一步,一个很重要的潜在应用就是游戏人物的表情绑定,获得更贴近人类的,自然的表情过渡效果。
更长远地看,这一研究成果可以帮助机器更好地理解人类,促进自然和谐的人机交互功能发展。用一个比喻来形容,这一技术对学界和产业界的影响,将是一粒慢性“兴奋剂”。当技术到达一定精度后,它的应用空间将远远不止上面提到的这些案例。这种方法还可以应用于哪些意想不到的场景中去,我们拭目以待。

还有两篇入选论文
除了这篇引人关注的论文成果之外,网易伏羲同时还有两篇论文入选CVPR,分别为《基于稠密运动场的高清说话人脸视频生成》和《神经风格画笔》,感兴趣的同学可以详读论文。
《基于稠密运动场的高清说话人脸视频生成》(Flow-based One-shot Talking Face Genaration with a High-resolutionAudio-visual Dataset)
论文简介:
One-shot说话人脸合成的目的,是给定任意一张人脸图像和任意一段语音,合成具有语音口型同步、眉眼头动自然的高清说话人脸视频。之前工作合成的视频分辨率之所以一直受到限制,主要有两个原因:1、目前没有合适的高清视听数据集。2.之前的工作使用人脸特征引导人脸图像合成,而对于高分辨率图像来说特征太稀疏。
为了解决上述问题,本研究首先收集了一个无约束条件下(in-the-wild)的高清人脸音视数据集YAD,该数据集比之前无约束条件下的数据集更加高清,也比之前实验室环境下(in-the-lab)数据集包含有更多的人物ID。
基于高清数据集YAD,本研究借助三维人脸重建(3DMM)将整个方法分成表情参数合成和视频图像合成两个阶段;在表情参数合成阶段中,使用多任务的方法合成嘴唇运动参数、眉眼运动参数和头部运动参数。在视频图像合成阶段,则使用稠密运动场替代人脸关键点引导人脸图像生成。定性和定量结果表明,与之前的工作相比,本研究可以合成更加高清的视频。以下二图分别展示方法的流程图和视频合成效果。
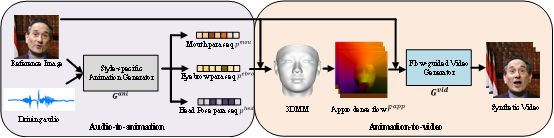
(论文的pipeline)
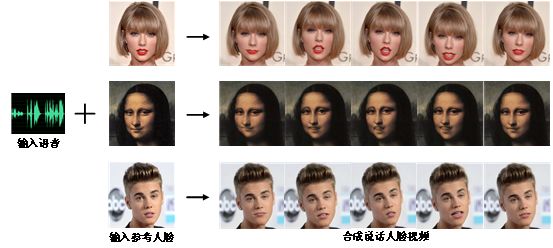
(实验的合成结果)
《神经风格画笔》(Stylized Neural Painting)
论文简介:
网易伏羲与密歇根大学合作研究,提出了一种图像到绘画的转换方法。该方法可以生成风格可控、生动逼真的绘画作品。不同于神经风格迁移方法,网易伏羲在参数化的条件下处理这种艺术创作过程,并产生一系列具有物理意义的画笔参数。

(借助神经可微渲染器,AI可以创造出高相似度,又独具风格的绘画作品)
由于经典的矢量渲染是不可微的,因此网易伏羲设计了一种全新的神经可微渲染器。它可以模仿矢量渲染器的行为,然后将画笔预测转换为参数搜索过程,即最大化输入与渲染输出之间的相似度。
实验表明,通过该方法生成的绘画在整体外观、局部纹理上都具有很高的保真度;该方法也可以与神经风格迁移共同优化,后者可以进一步迁移其他图像的视觉样式。


更多精彩推荐
☞关于深度学习编译器,这些知识你需要知道☞小小几张图,把深度学习讲透彻☞Python 搭建车道智能检测系统☞“踢爆”职场焦虑、玩机车、文科转大厂程序媛,乘风破浪的 IT 女神太飒了!点分享点收藏点点赞点在看