学生成绩统计---pyspark练习
学生成绩统计---pyspark练习
- 题目需求、数据、字段说明
- 1、统计每门课程的参考人数和课程平均分
- 2、统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
- 3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分。
pyspark练习,有不对或需要改进的地方还请大佬们指点出来,大家相互学习
题目需求、数据、字段说明
统计需求:
1、统计每门课程的参考人数和课程平均分
2、统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分。
数据及字段说明:
computer,huangxiaoming,85,86,41,75,93,42,85
computer,xuzheng,54,52,86,91,42
computer,huangbo,85,42,96,38
english,zhaobenshan,54,52,86,91,42,85,75
english,liuyifei,85,41,75,21,85,96,14
algorithm,liuyifei,75,85,62,48,54,96,15
computer,huangjiaju,85,75,86,85,85
english,liuyifei,76,95,86,74,68,74,48
english,huangdatou,48,58,67,86,15,33,85
algorithm,huanglei,76,95,86,74,68,74,48
algorithm,huangjiaju,85,75,86,85,85,74,86
computer,huangdatou,48,58,67,86,15,33,85
english,zhouqi,85,86,41,75,93,42,85,75,55,47,22
english,huangbo,85,42,96,38,55,47,22
algorithm,liutao,85,75,85,99,66
computer,huangzitao,85,86,41,75,93,42,85
math,wangbaoqiang,85,86,41,75,93,42,85
computer,liujialing,85,41,75,21,85,96,14,74,86
computer,liuyifei,75,85,62,48,54,96,15
computer,liutao,85,75,85,99,66,88,75,91
computer,huanglei,76,95,86,74,68,74,48
english,liujialing,75,85,62,48,54,96,15
math,huanglei,76,95,86,74,68,74,48
math,huangjiaju,85,75,86,85,85,74,86
math,liutao,48,58,67,86,15,33,85
english,huanglei,85,75,85,99,66,88,75,91
math,xuzheng,54,52,86,91,42,85,75
math,huangxiaoming,85,75,85,99,66,88,75,91
math,liujialing,85,86,41,75,93,42,85,75
english,huangxiaoming,85,86,41,75,93,42,85
algorithm,huangdatou,48,58,67,86,15,33,85
algorithm,huangzitao,85,86,41,75,93,42,85,75
数据解释
数据字段个数不固定:
第一个是课程名称,总共四个课程,computer,math,english,algorithm,
第二个是学生姓名,后面是每次考试的分数,但是每个学生在某门课程中的考试次数不固定。
1、统计每门课程的参考人数和课程平均分
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext('local', 'score1')
(sc.textFile("dataset/score.txt")
# map--->(课程,姓名,平均分)
.map(lambda x: (x.split(",")[0], x.split(",")[1], sum(list(map(int, x.split(",")[2:]))) / (len(x.split(",")) - 2)))
# groupBy ---> [(课程1,[(课程1,姓名1,平均分1),(课程1,姓名2,平均分2)...]...),
.groupBy(lambda x: x[0])
.map(lambda x: f"{x[0]}\t{len(x[1])}\t{sum(map(lambda y: y[2], list(x[1]))) / len(x[1])}")
.saveAsTextFile("dataset/score1")
)

2、统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
repartitionAndSortWithinPartitions()同时完成了分区和排序的功能。
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext('local', 'score2')
(sc.textFile("dataset/score.txt")
# map---> ((课程,平均分),姓名)
.map(lambda x: ((x.split(",")[0], sum(map(int, x.split(",")[2:])) / (len(x.split(",")) - 2)), x.split(",")[1]))
# x === (课程,平均分)
.repartitionAndSortWithinPartitions(numPartitions=4, # 分区数
partitionFunc=
lambda x: ["computer", "math", "english", "algorithm"].index(x[0]), # 分区方法
ascending=False, # 降序
keyfunc=lambda x: x[1] # 指定排序字段(平均分
)
.map(lambda x: "%s\t%s\t%.1f" % (x[0][0], x[1], x[0][1]))
.saveAsTextFile("dataset/score2")
)

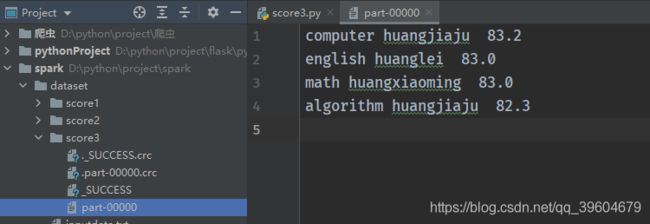
3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分。
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext('local', 'score3')
(sc.textFile("dataset/score.txt")
.map(lambda x: (x.split(",")[0], x.split(",")[1], sum(list(map(int, x.split(",")[2:]))) / (len(x.split(",")) - 2)))
.sortBy(keyfunc=lambda x: x[2], ascending=False)
.groupBy(lambda x: x[0], numPartitions=1)
.map(lambda x: "%s %s %.1f" % list(x[1])[0])
.saveAsTextFile("dataset/score3")
)