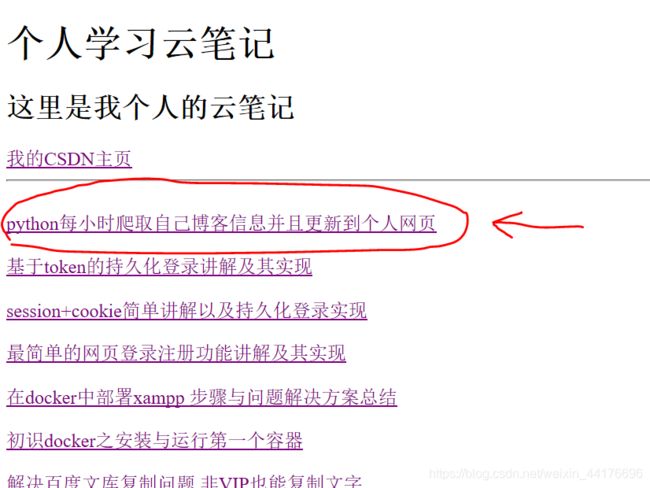
python每小时爬取自己博客信息并且更新到个人网页
目录
- 前言
- 总体思路
- 安装python环境与对应的包
- python代码爬取博客信息
- shell脚本更新index.html
- 添加脚本到定时启动
- 效果
前言
网站的备案也有一段时间了,主站点当时为了应付审核,做了个很丑的页面。。。今天来优化以下这个页面。
今天来使用python爬取自己的csdn博客
我们每小时更新一次,爬取最新的一页博客,然后更新自己个人网页的内容,如下图,更新后的效果,每小时爬取一次并且更新这个简单的html文件,效果如下图,下图中红色箭头指向的,是动态更新的内容
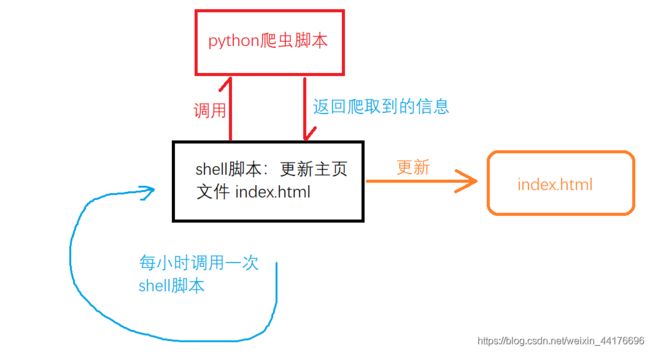
总体思路
- 我们使用一个python脚本并且运行一个简单的不能再简单的爬虫,获取一下自己的博客的文章列表,并且输出博客信息
- 然后使用一个shell脚本,shell里面启动python脚本,引导python脚本的输出,更新index.html主页的内容
- 设置Ubuntu定时更新,我们每一小时运行一次shell脚本
安装python环境与对应的包
安装python
sudo apt-get install python3.7
安装pip
sudo apt-get install pip
安装bs4包和requests包到python3.7
sudo python3.7 -m pip install bs4
sudo python3.7 -m pip install requests
python代码爬取博客信息
我们使用python来爬取我csdn博客的信息,这里是我csdn博客的地址 https://blog.csdn.net/weixin_44176696
我希望爬取最新一页的博客的标题,如图
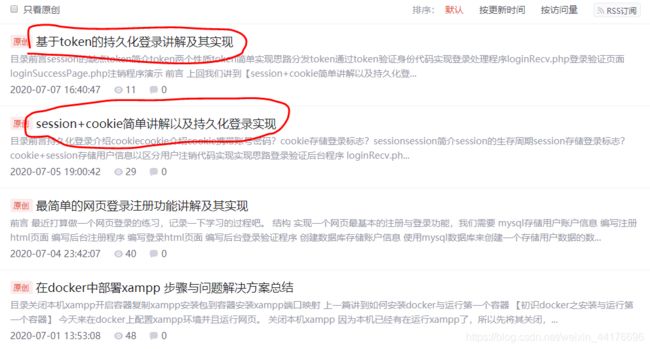
我们希望爬取两个信息:
- 博客标题
- 博客超链接跳转地址
我们打开浏览器的开发者模式,我们看一下自己需要的信息在哪里,我们找到对应的div
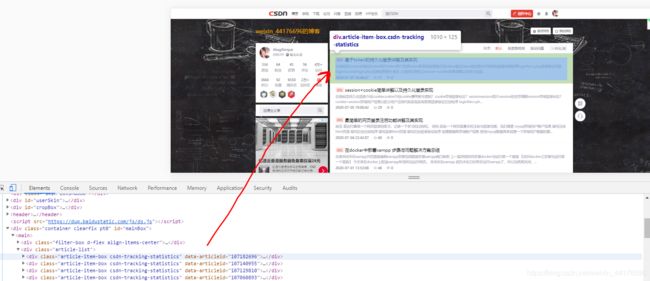
进一步展开这个div,我们发现里面有一个a超链接标签,这个标签里面有我们需要的两个信息,即文章名字和超链接
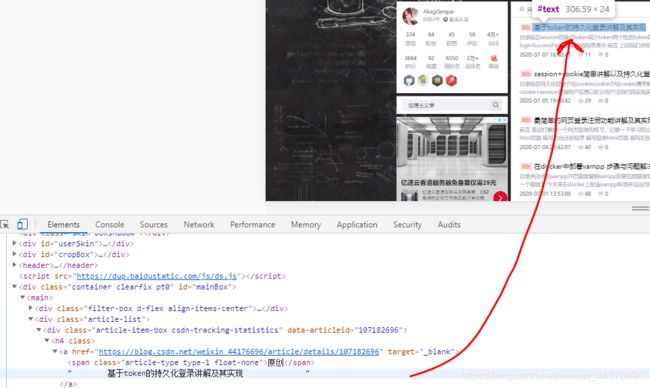
那么思路很明确了:我们找到class 属性为 article-item-box csdn-tracking-statistics的标签,然后我们提取每个标签里面的内容
我们在python3.7的环境下编写以下的代码,我们需要用到两个库:
- requests
- bs4
requests用来爬取html的源码,然后我们将html的源码送入bs4进行解析。bs4提供了快捷的方式以使我们快速找到想要的标签及其信息。我们编写名为test.py的一个简单爬虫脚本
from bs4 import BeautifulSoup
import requests
# 设置http请求头伪装成浏览器
send_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"}
# requests获取博客页面html文本
url = "https://blog.csdn.net/weixin_44176696"
r = requests.get(url, headers=send_headers)
r.encoding = "utf-8"
html = r.text
# 将获取到的html送入bs4进行解析
soup = BeautifulSoup(html, "html.parser") # 获得解析后对象
mainBox = soup.find("div", id="mainBox") # 找到id是mainBox的div
# 找到这个div中所有 class 是 article-item-box csdn-tracking-statistics 的div
artlist = mainBox.find_all("div", attrs={
"class":"article-item-box csdn-tracking-statistics"})
# 遍历每个div 输出内容 以html形式输出
for div in artlist:
a = div.h4.a
print("" + a.text[11:-14] + "
")
这是这些代码的输出,我们以html超链接标签的格式输出我们爬取到的信息
这样一坨输出,直接输出到html文件里面,就能产生超链接,超链接的文字是我文章的标题,而跳转的目标地址则是我博客文章的地址。
<a href='https://blog.csdn.net/weixin_44176696/article/details/107182696'>基于token的持久化登录讲解及其实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/107140955'>session+cookie简单讲解以及持久化登录实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/107129810'>最简单的网页登录注册功能讲解及其实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/107060893'>在docker中部署xampp 步骤与问题解决方案总结</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/107048914'>初识docker之安装与运行第一个容器</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/107017726'>解决百度文库复制问题 非VIP也能复制文字</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/107003903'>三种cache映射方式简单讲解</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106986435'>深圳大学算法实验总结2020(实验1~6+大作业)</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106984435'>最大流应用问题(深大算法实验6)报告+代码</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106984100'>无向图求桥(深大算法实验5)报告+代码</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106983748'>代码查重实验(深大算法实验4)报告+代码</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106983431'>消消乐实验回溯法(深大算法实验3)报告+代码</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106983182'>分治法求最近点对 (深大算法实验2)报告+代码</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106982336'>排序算法性能分析实验(深大算法实验1)报告+代码</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106933631'>LC-3 中断实验 (深大计系1实验5)</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106899149'>C++ unordered_set 真的快吗?小规模下用时约等于顺序查找</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106876543'>cache高速缓存 简单讲解与验证</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106875850'>proteus 8 仿真时 时间流动过慢的解决方案</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106840779'>java swing 简易浏览器(其三)下载器,智能搜索栏与邮件发送</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106790076'>Java swing 带界面和进度条的多线程下载器实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106773061'>Java swing简易浏览器(其二)前进后退与收藏夹实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106746305'>Java swing简易浏览器(其一)页面显示,超链接跳转与手动输入URL跳转</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106692746'>SCC算法求强连通分量简单讲解证明及实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106685862'>C++类模板 简单讲解与实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106666236'>符号引用重定位 重定位PC相对引用 简单讲解</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106638163'>Java UDP通信 讲解与简单实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106587629'>Edmonds-Karp算法(EK算法)简单讲解及实现(邻接表)</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106550045'>C++ 模板函数 讲解及实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106526201'>LC-3 子程序调用与模拟栈调用递归函数</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106494356'>C++自定义数据类型与标准数据类型的转换 讲解及实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106434770'>简单并查集讲解(并+查)与代码实现</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106414223'>c++运算符重载简单讲解 cout输出自定义数据类型</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106387897'>Tarjan算法求桥 思路+代码 无向图</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106363156'>LC-3简易四子棋(深大计系1实验4) 思路+代码+详细注释</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106322020'>Keras简单实现自定义损失函数</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106303566'>jmeter初次尝试 下载与简单测试</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106290745'>缓冲区溢出攻击实验(深大计系2实验4)三题思路+答案</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106265042'>C++虚函数简单讲解</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106255149'>C++虚继承简单讲解</a><br>
<a href='https://blog.csdn.net/weixin_44176696/article/details/106246711'>LC-3指令集 字符的输入与输出</a><br>
shell脚本更新index.html
我们编写一个简单shell脚本,他叫updateBlog1h.sh,这个脚本分为三行
#! /bin/bash
echo "-8">主页 个人学习云笔记
这里是我个人的云笔记
//blog.csdn.net/weixin_44176696">我的CSDN主页
" > ./index.html
python3.7 ./test.py >> index.html
echo "
 .png">//www.beian.gov.cn" target="_blank">粤ICP备20048898号-1" >> ./index.html
.png">//www.beian.gov.cn" target="_blank">粤ICP备20048898号-1" >> ./index.html
第一行我们输入静态的html代码到index.html,这部分是不变的,所以我们可以写在脚本里,html代码我们去除了格式,未格式化之前的html代码如下
<!DOCTYPE html>
<meta charset="utf-8">
<html>
<head>
<title>主页</title>
</head>
<body>
<h1>个人学习云笔记</h1>
<h2>这里是我个人的云笔记</h2>
<a href="https://blog.csdn.net/weixin_44176696">我的CSDN主页</a><br><hr><br>
第二行我们通过shell调用python爬虫脚本,就是我们刚刚编写的test.py,我们通过输出重定向符号 > 来将python脚本的输出,导入到index.html
第三行我们同样输入静态的html代码到index.html,这部分和第一行是一样的,下面展示未格式化的html代码
<br><hr><br>
<img src="1.png"><a href="http://www.beian.gov.cn" target="_blank">粤ICP备20048898号-1</a>
</body>
</html>
shell脚本编写完成,
添加脚本到定时启动
我们编辑位于 etc/ 目录下的 crontab 文件
sudo vim etc/crontab
我们添加红色下划线的语句到指定位置,我们设置只要分钟数为1,就执行,即以ubuntn这个用户,执行一次如下命令
cd .. && cd ../opt/lampp/htdocs/myPage && ./updateBlog1h.sh
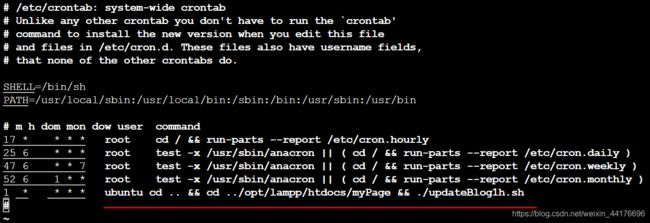
值得注意的是,因为这里的定时命令的默认路径是我们这个账户的工作路径,即 /home/ubuntn,所以实际执行时,要做路径跳转。我们可以通过以下的代码来查看默认的路径
cd ~
pwd
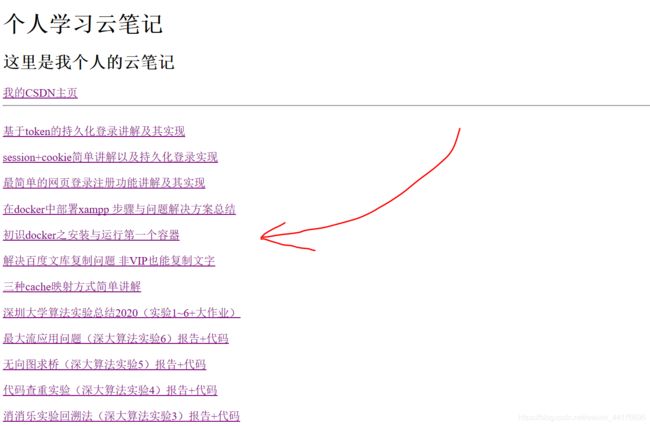
效果
这部分是我发布博客后,洗了个澡,再来访问我的个人网站,所看到的更新的内容(和之前的截图对比,可以看到多了一篇)。这表明我们的代码有在好好工作