记一次对Pixiv日榜的爬虫
Pixiv爬虫
- Pixiv是个啥
- 爬虫过程
Pixiv是个啥
pixiv是一个以插图、漫画和小说、艺术为中心的社交网络服务里的虚拟社区网站。于2007年9月10日推出第一个测试版。公司总部位于日本东京都涩谷区千驮谷。pixiv创办初衷是为全球艺术家提供一个能发表他们的作品,并透过评级系统反应其他用户意见的地方。网站以用户投稿的原创图画为中心,辅以标签、书签、作品回应、排行榜等功能形成具有其特色的社交网络。
-----摘自 百度百科
爬虫过程
##PS:由于pixiv的特殊性,访问该网站需要某种工具(笑)##
按照以往爬虫经验,以为爬pixiv依旧是一件很容易的事情,于是按照常规导入库:
import requests#爬虫必备库
import re#正则表达式提取链接等
import time#加入延迟
自定义使用浏览器headers:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}#防止反爬
找到pixiv的日榜网页链接:
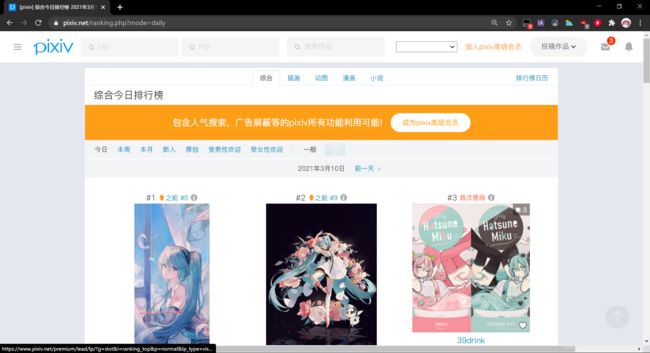
使用requests.get.text获取该页面的网页源代码:
response_1 = requests.get("https://www.pixiv.net/ranking.php?mode=daily",headers=headers)#请求该网页
daily_list = response_1.text#获取pixiv日榜的网页的源代码
进入到日榜页面,右键查看网页源代码;
找到相似结构,data-id后跟的是榜单图片的id:
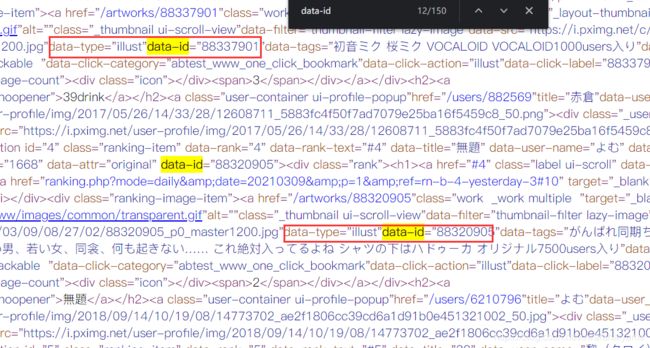
因为有相似性,因此可以使用正则表达式可以提取出图片id:
ID = re.findall('"data-type=".*?"data-id="(.*?)"',daily_list)#获取日榜图片的id
print (ID)#打印id检查是否成功
id获取成功:

随便点进两张张图片,观察其网址可发现除id外网址相同:

由此考虑使用for循环得到图片链接:
part = "https://www.pixiv.net/artworks/" #定义除id以外的部分
for site in ID:
URL = part + str(site)#得到榜单每张图片的URL
URL = URL.split(" ")#将URL转换成列表类型便于下次循环
点进一张图片,右键检查网页,可以找到图片下载链接:

右键查看源代码,找到下载链接位置:

使用for循环从URL中获取到下载链接:
'''此处的for循环为上一循环的嵌套'''
for download in URL:
response_2 = requests.get(download,headers = headers)#获取展示页面的源代码
html = response_2.text#得到源代码文字
download_links = re.findall('"original":"(.*?)"}', html)#使用正则表达式提取出下载链接
准备下载:
'''此处的for循环为上一循环的嵌套'''
for url in download_links:
time.sleep(5)#5秒爬一张防止网页被爬崩溃以及防止被禁ip
file_name = url.split('/')[-1]
response = requests.get(url, headers=headers)
with open(file_name, 'wb') as f:
f.write(response.content)
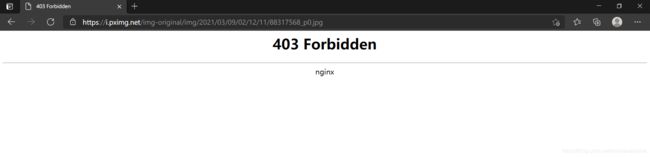
本以为万无一失,结果下载下来的图片无法打开,新建一个python文件,使用requests.get查看请求结果时发现请求为403:
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
print (requests.get("https://i.pximg.net/img-original/img/2021/03/09/02/12/11/88317568_p0.jpg",headers = headers))
结果:
<Response [403]>
初次猜测是ip被服务器ban了,换了headers和ip以后,请求该网址依旧是403,因此考虑是网站自身问题。换浏览器打开这个网址,发现显示403,那么便确定是网站问题。
CSDN搜索相关问题,发现有前辈遇到过相同问题并解决:
查看链接
考虑到该前辈的代码中两个链接的数据类型全为字符串,因此在第二次循环将URL和download_links的数据类型改为字符串:
for download in URL:
URL = "".join(URL) # 将URL的类型改成str
response_2 = requests.get(download,headers = headers)#获取展示页面的源代码
html = response_2.text#得到源代码文字
download_links = re.findall('"original":"(.*?)"}', html)#使用正则表达式提取出下载链接
download_links = "".join(download_links) # 将 download_links的类型改成str
最后加上前辈的代码,得到完整代码如下:
import urllib.request
import ssl
import requests
import re
import time
ssl._create_default_https_context = ssl._create_unverified_context#解决不受信任SSL证书问题
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}#定义headers
response_1 = requests.get("https://www.pixiv.net/ranking.php?mode=daily",headers=headers)
daily_list = response_1.text#获取pixiv日榜的html文字
ID = re.findall('"data-type=".*?"data-id="(.*?)"',daily_list)
print (ID)#获取日榜图片的id
part = "https://www.pixiv.net/artworks/" #定义除ID外的部分
'''得到图片id'''
for site in ID:
URL = part + str(site)
URL = URL.split(" ")#将URL转换成list
'''得到图片页面网址'''
for download in URL:
opener = urllib.request.build_opener()
URL = "".join(URL) # 将URL的类型改成str
opener.addheaders = [('Referer', URL)]
response_2 = requests.get(download,headers = headers)#获取展示页面的html文字
html = response_2.text#得到文字
download_links = re.findall('"original":"(.*?)"}', html)#使用正则表达式得到下载链接
download_links = "".join(download_links) # 将 download_links的类型改成str
urllib.request.install_opener(opener)
print (download_links)#打印download_links检查
'''得到文件名'''
file_name = download_links.split('/')[-1]#对链接反向切片得到文件名
print (file_name)#打印文件名检查
'''五秒下载一次防止被ban'''
time.sleep(5)
'''增加重连的次数防止报错'''
requests.DEFAULT_RETRIES = 100 # 增加重试连接次数
s = requests.session()
s.keep_alive = False # 关闭多余连接
'''需要提前创建好文件夹'''
urllib.request.urlretrieve(download_links, ("E://pixiv//" + str(file_name)))#将URL文件复制到本地
运行:
PS:
1. urllib.request.urlretrieve 语句会出现不确定的抽风问题(无法下载,下载卡住等),
该程序可以继续优化,此问题可以考虑socket模块设置超时时间,具体可以参考站内解答;
2.该网站图片无法使用requests库中的with open方案下载,但是其余大部分站是可以使用的,不需要这么麻烦(笑)。
参考链接:
python爬虫遇到403错误
urllib.request.urlretrieve()函数下载文件卡死解决办法