引出
获取多线程的方法,我们都知道有三种,还有一种是实现Callable接口
- 实现Runnable接口
- 实例化Thread类
- 实现Callable接口
- 使用线程池获取
Callable接口
Runnable和Callable的区别
- Runnable接口没有返回值,Callable接口有返回值
- Runnable接口不会抛异常,Callable接口可以抛异常
- 接口的方法不一样,一个run方法,一个call方法
- Callable方法支持泛型
Callable接口实现多线程
- Callable接口,是一种让线程执行完成后,能够返回结果的
当我们实现Ruannable接口的时候,需要重写run方法,也就是线程启动的时候,会自动调用的方法。
同理,我们实现Callable接口,也需要实现call方法,但是这个时候我们还需要有返回值。这个Callable接口的应用场景一般在于批处理业务,比如转账的时候,需要给返回结果的状态码回来,代表本次操作成功还是失败。
public class MyThread implements Callable {
@Override
public Integer call() throws Exception {
System.out.println("进入了Callable方法");
return 1024;
}
} 然后通过Thread线程,将MyThread实现Callable接口的类包装起来。
这里需要用到FutureTask类,他实现了Runnable接口,类的构造函数需要传递一个实现Callable接口的类。
public static void main(String[] args){
// 1、实例化FutureTask类,传进去一个实现了Callable的类
FutureTask futureTask = new FutureTask<>(new MyThread());
// 2、然后在用Thread进行实例化,传入实现Runnable接口的FutureTask的类
Thread t1 = new Thread(futureTask, "A线程");
t1.start();
// 3、最后通过 futureTask.get() 获取到返回值
System.out.println("FutureTask的返回值为:" + futureTask.get());
} 原来我们的方式是一个main方法冰糖葫芦似的串下去,引入Callable后,对于执行比较久的线程,可以单独新开一个线程进行执行,最后再进行汇总输出。
如果我们用
get()获取Callable的计算结果,但是如果并没有计算完成,会导致阻塞,直到计算完成为止。也就是说,futureTask.get()需要放在最后执行,这样不会导致主线程阻塞。//也可以使用下面算法,使用类似自旋锁的方式来进行判断是否运行完毕 while(!futureTask.isDone()){ }
注意
多个线程执行一个FutureTask对象的时候,只会计算一次。
FutureTask futureTask = new FutureTask<>(new MyThread());
// 开启两个线程计算futureTask
new Thread(futureTask, "A线程").start();
new Thread(futureTask, "B线程").start(); 如果我们需要两个线程同时计算任务的话,那么需要定义两个FutureTask对象
FutureTask futureTask1 = new FutureTask<>(new MyThread);
FutureTask futureTask2 = new FutureTask<>(new MyThread);
// 开启两个线程计算futureTask
new Thread(futureTask1, "A线程").start();
new Thread(futureTask2, "B线程").start(); ThreadPoolExecutor
为什么要用线程池?
线程池做的主要工作就是控制运行的线程的数量,处理过程中,将任务放入到阻塞队列中,然后线程创建后,启动这些任务,如果线程数量超过了最大数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用、控制最大并发数、管理线程
线程池的好处
- 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就立即执行。
- 提高线程的可管理性。使用线程池可以进行统一的分配,调优和监控。
线程池的实现原理
说白了就是一个线程集合(workerSet)和一个阻塞队列(workQueue)。当用户向线程池提交一个任务时,线程池会先将任务放入阻塞队列中。线程集合中的线程会不断的从阻塞队列中获取任务执行,当阻塞队列中没有任务的时候,就会阻塞,直到队列中有任务了就取出来继续执行。
任务:客户。 线程集合:办理窗口。 阻塞队列:候客区。
架构说明
Java中线程池是通过Executor框架实现的,该框架中用到了Executor,Executors(辅助工具类),ExecutorService,ThreadPoolExecutor这几个类。
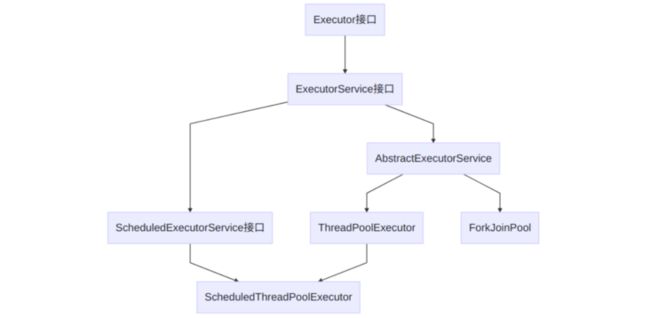
创建线程池
- 我们通过Executors工具类来创建线程池
1、FixedThreadPool(固定线程的线程池)
ExecutorService threadPool = Executors.newFixedThreadPool(5);- 执行长期的任务,性能好很多
- 可控制线程数最大并发数,超出的线程会在队列中等待
- 使用场景:执行长期的任务
2、SingleThreadExecutor(一个线程的 单线程池)
ExecutorService threadPool = Executors.newSingleThreadExecutor();- 一个任务一个任务执行的场景
- 用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行
- 执行场景:一个任务一个任务执行的场景
3、newCacheThreadPool(可扩容的线程池)
ExecutorService threadPool = Executors.newCacheThreadPool();- 执行很多短期异步的小程序或者负载较轻的服务器
- 线程长度超过处理需要,可灵活回收空闲线程,如无可回收,则新建新线程
- 执行很多短期异步的小程序或者负载较轻的服务器
代码演示
- 模拟10个用户来办理业务,每个用户就是一个来自外部请求线程
ExecutorService threadPool = Executors.newFixedThreadPool(5);
// 模拟10个用户来办理业务,每个用户就是一个来自外部请求线程
try {
// 循环十次,模拟业务办理,让5个线程处理这10个请求
for (int i = 0; i < 10; i++) {
final int tempInt = i;
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + " 给用户:" + tempInt + "办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown(); // 用池化技术,一定要记得关闭
}结果:
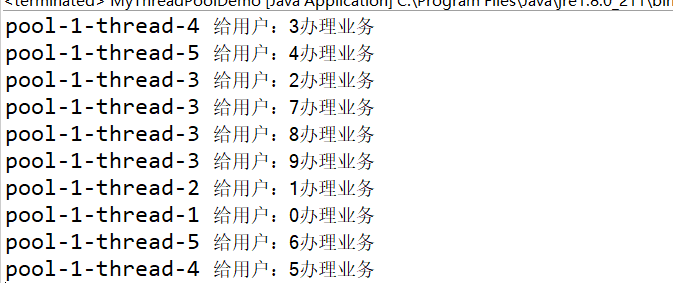
我们能够看到,一共有5个线程,在给10个用户办理业务。
底层实现
我们通过查看源码,发现底层都是使用了ThreadPoolExecutor。

为什么单线程池和固定线程池使用的任务阻塞队列是LinkedBlockingQueue(),而缓存线程池使用的是SynchronousQueue()呢?
因为在单线程池和固定线程池中,线程数量是有限的,因此提交的任务需要在队列中等待空闲的线程。
而在缓存线程池中,线程数量几乎无限,因此提交的任务在 SynchronousQueue 队列中同步给空余线程即可。
Tips:SynchronousQueue是一个没有存储空间的队列,生产者进行 put 操作时,必须要等待消费者的 take 操作。
线程池的重要参数
线程池在创建的时候,一共有7大参数:

- corePoolSize:核心线程数,线程池中的常驻核心线程数
- maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1
- keepAliveTime:多余的空闲线程存活时间
- unit:keepAliveTime的单位
workQueue:任务队列,被提交的但未被执行的任务(类似于银行里面的候客区)
- LinkedBlockingQueue:链表阻塞队列
- SynchronousBlockingQueue:同步阻塞队列
- threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程池 一般用默认即可
- handler:拒绝策略,表示当队列满了并且工作线程大于线程池的最大线程数(maximumPoolSize)时,如何来拒绝请求执行的Runnable的策略
线程池底层工作原理

整个线程池的工作就像银行办理业务一样。
- 最开始假设来了两个顾客,因为corePoolSize为2,因此这两个顾客直接能够去窗口办理。
- 后面又来了三个顾客,因为corePool已经被顾客占用了,因此只有去候客区,也就是阻塞队列中等待
- 后面人越来越多,候客区可能不够用了,这时需要申请增加处理请求的窗口,假如maximumPoolSize为5,就会创建这3个非核心线程运行这个任务。
- 假设受理窗口已经达到最大数,并且请求数还是不断递增,此时候客区和线程池都已经满了,为了防止大量请求冲垮线程池,已经需要开启拒绝策略
- 临时增加的线程如果超过了最大存活时间,就会销毁,最后从最大数缩容到核心线程数
ps:临时增加的业务窗口,会先处理那些后面来的,没位置坐的客户。(候客区客户os:凭什么= =)
四种拒绝策略的解析
以下所有拒绝策略都实现了RejectedExecutionHandler接口
- AbortPolicy(默认):直接抛出
RejectedExcutionException异常,阻止系统正常运行 - DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常,如果运行任务丢失,这是一种好方案
- CallerRunsPolicy:用调用者所在的线程处理任务,能够减缓新任务的提交速度。
- DiscardOldestPolicy:丢弃最老的任务,执行当前任务。
为什么不用默认创建的线程池?
工作中应该用哪一个方法来创建线程池呢?答案是一个都不用,我们生产上只能使用自定义的。
阿里巴巴开发手册:【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
弊端如下:
- FixedThreadPool 和 SingleThreadPool 使用了无界队列(LinkedBlockingQueue),可能会堆积大量的请求,从而导致OOM
- CacheThreadPool 和 ScheduledThreadPool 的最大线程为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM
手写线程池
采用默认拒绝策略(AbortPolicy)
ExecutorService threadPool = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue(3),//候客区3个座位
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()); //然后使用for循环,模拟10个用户来进行请求
for (int i = 0; i < 10; i++) {
final int tempInt = i;
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName()+" 给用户:"+tempInt+"办理业务");
});
}但是用户执行到第九个的时候,触发了异常,程序中断。
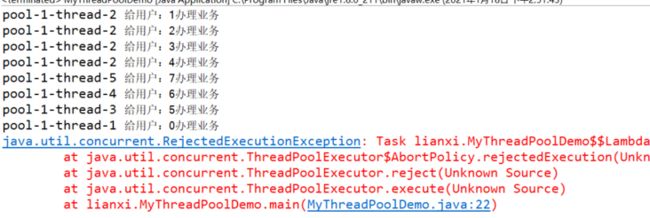
这是因为触发了AbortPolicy的拒绝策略:直接报异常。
触发条件是,请求的线程大于 阻塞队列大小 + 最大线程数 = 8的时候,也就是说第9个线程来获取线程池中的线程时,就会抛出异常。
采用CallerRunsPolicy拒绝策略
也称为回退策略,就是用调用者所在的线程处理任务。
我们看运行结果:

我们发现,输出的结果里面出现了main线程,因为线程池触发了拒绝策略,把任务回退到main线程,然后main线程对任务进行处理。
DiscardPolicy拒绝策略、DiscardOldestPolicy拒绝策略
这两种策略都是把任务丢弃。
前者丢弃的是,进来排队排不上的任务。
后者丢弃的是当前队列中最老的任务,即排队下一个就到你了,但是因为有人进来,导致你被丢弃了(为什么这么惨?)。处理逻辑如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll(); //用 poll() 移除队列中的首个元素
e.execute(r); //执行当前任务
}
}线程池的合理参数
生产环境中如何配置 corePoolSize 和 maximumPoolSize?。这个是根据具体业务来配置的,分为CPU密集型和IO密集型。
//可以看CPU是几核的
Runtime.getRuntime().availableProcessors();- CPU密集型
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能比CPU要好,CPU的IO操作很快,但是CPU还有很多运算要处理,导致系统的CPU大部分都是 100%。
需要尽可能少的线程数量,一般为:CPU核数 + 1
- IO密集型
即该任务需要大量的IO,即大量的阻塞。IO包括:数据库交互,文件上传下载,网络传输等
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多。此时大部分的状况是CPU在等IO操作,则应配置尽可能多的线程,如 CPU核数 * 2。
参考公式:CPU核数 / (1 - 阻塞系统)。一般阻塞系数是0.9,比如 8 核CPU,应该配置 8 / 0.1 = 80 个线程数
一个线程池中的线程异常了,那么线程池会怎么处理这个线程?
如果执行方式是 execute 时,会看到堆栈异常的输出。
当执行方式是 submit 时,堆栈异常没有输出。并且调用 Future.get() 方法时,可以捕获到异常。不会影响线程池里面其他线程的正常执行,线程池会把这个异常的线程移除掉,并创建一个新的线程放入线程池中。?