突然翻到很久以前的Mysql笔记,特此重做为方便查看保存。
数据库基础
1.什么是数据库?
数据库:database,存储数据的仓库
数据库:高效的存储数据的介质(介质主要是两种:磁盘和内存)
2.数据库的分类?
数据库基于存储介质的不同:进行了分类,分为两类:关系型数据库(SQL)和非关系型数据库(NoSQL:不是关系型的数据库都是非关系型数据库)
3.不同数据库阵营中的产品?
关系型数据库:
大型:Oracle,DB2
中型:SQL-SERVER,Mysql。。。
小型:access。。。
非关系型数据库:memcached,mongodb,redis(同步到磁盘,redis不会丢失)
4.两种数据库阵营的区别?
关系型数据库:安全(保存磁盘基本不可能丢失),容易理解,但比较浪费空间(二维表存储)
非关系型数据库:效率高,不安全(断电丢失)
关系型数据库
1.定义
关系型数据库:是一种建立在关系模型上的数据库。
关系模型:一种所谓建立在关系上的模型,关系模型包含三个方面:
数据结构:数据存储的问题,二维表(有行有列)
操作指令集合:所有SQL语句
完整性约束:表内数据约束(字段与字段),表与表之间约束(外键)
2.关系型数据库的设计?
关系型数据库:从需要存储的数据需求中分析,如果是一类数据(实体)应该设计成一张二维表:表是由表头(字段名:用来规定数据的名字)和数据部分组成(实际存储的数据单元)
二维表:行和列
| 表头 | 字段名1 | 字段名2 | 字段名3 |
|---|---|---|---|
| 数据单元 | 数据1 | 数据2 | 数据3 |
例:分析一个教学系统,讲师负责教学,教学生,在教室教学生。
①找出系统中所存在的实体:讲师表,学生表,班级表
②找出实体中应该存在的数据信息
讲师:姓名,性别,年龄,工资
学生:姓名,性别,学号,学科
班级:班级名字,教室编号
关系型数据库:维护实体内部,实体与实体之间的联系
实体内部联系:每个学生都有姓名,性别,学号,学科信息
班级表
| 姓名 | 性别 | 学号 | 学科 | 年龄 | 班级 |
|---|---|---|---|---|---|
| 杨小平 | 男 | 2016211555 | JavaScript | 23 | 04051601 |
| 周声烈 | 男 | 2016211855 | C | 25 | 04911601 |
| 王思伟 | 女 | 2016211868 | Python | 18 | 04051603 |
第二行的所有字段,都是在描述杨小平这个学生(内部联系);第二列只能放性别(内部约束
关系型数据库的特点之一:如果表中对应的某个字段没有值(数据),系统依然要分配空间:所已数据库比较浪费空间
班级表
| 班级 | 教室 |
|---|---|
| 04051601 | B405 |
| 04911601 | C122 |
| 04051603 | A555 |
关键字说明
数据库:database
数据库系统:DBS(Database System):是一种虚拟系统,将多种内容关联起来的称呼
DBs = DBMS+ DB
DBMS:Database Management System,数据库管理系统,专门管理数据库
DBA:Database Administrator,数据库管理员
行/记录:row/record,本质是一个东西,都是值标中的一行(一条记录):行是从角度出发,
记录是从数据角度出发
列/字段:column/field,本质是一个东西
SQL
SQL:Structured Query Language,结构化查询语言(数据以查询为主:99%是在进行查询操作)
SQL分为三个部分
DDL:Data Definition Language,数据定义语言,用来维护存储数据的结构(数据库,表),代表指令:create,drop,alter等
DML:Data Manipulation Language,数据操作语言,用来对数据进行操作(数据表中的内容),代表指令:insert,delete,update等:其中DML内部又单独进行了一个分类:DQL(Data Query Language,数据查询语言,如select)
DCL:Data Control Language,数据控制语言,主要是负责权限管理(用户),代表指令:grant,revoke等
SQL是关系型数据库的操作指令,SQL是一种约束,但不强制(类似W3C):不同的数据库产品(如Oracle,MYSQL)可能会有一些细微的差别。
MYSQL数据库
MYSQL数据库是一种c/s结构的软件:客户端、服务端,弱项访问服务器必须通过客户端(服务器一直运行,客户端在需要使用的时候运行)
交互方式
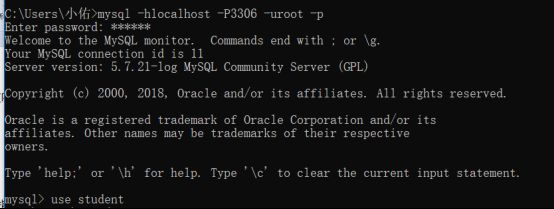
- 客户端连接认证:连接服务器,认证身份:mysql -h主机地址 -P端口 -u名字 -p(例:mysql -hlocalhost -P3306 -uroot -p)
发送SQL指令
服务器接受SQL指令:处理SQL指令:返回操作结果
客户端接受结果:显示结果
断开连接(释放资源:服务器并发限制)
MYSQL服务器对象
没有办法完全了解服务器内部的内容,只能粗略的去分析数据库服务器的内部的结构。
将MYSQL服务器内部的对象分成了四层:系统(DBMS)->数据库(DB)->数据表(Table)->字段(field)
SQL基本操作
基本操作:CRUD
将SQL的基本操作根据操作对象进行分类,分为三类:库操作,表操作(字段),数据操作
库操作
对数据库的增删改查
新增数据库
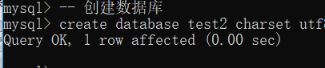
基本语法
Create database 数据库名字【库选项】;

库选项;:用来约束数据库,分为两个选项
字符集设定:charset/character set 具有字符集(数据存储的编码格式):常用字符集:GBK / UTF8
校对集设定:collate 具体校对集(数据比较的规则)
双中划线 + 空格(-- ):注释(单行注释),也可以使用#号
其中:数据库名字不能用关键字(已经使用的字符)或保留字(以后可能会用到的)
非要使用的话可以加反引号(ese键下的键在英文输入下)
查看数据库
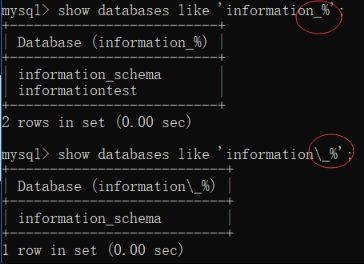
1.查看所有数据库: show databases;
2.查看指定部分的数据库:模糊查询
Show databases like ‘pattern’; --pattern是匹配模式(即需要替换的)
%;表示匹配多个字符 表示匹配一个字符
例:以下划线开始的数据库: 需要被转义
如:以information开始:
Show databases like ‘information%; --此处相当于information
Show databases like ‘’information_%’; --这样才对
3.查看数据库创建语句:show create database 数据库名;

更新数据库
数据库名字不可以修改。
数据库的修改仅限库选项:字符集和校对集(校对集依赖字符集)
Alter database 数据库名字 [库选项];
Charset/character set [=] 字符集
Collate = 校对集
Ps:一般不用等号,字符集依赖于校对集
例:

删除数据库
所有的操作中:删除最简单(。。。挣钱难花钱容易)
Drop database 数据库名字
注意执行此语句后什么东西都没有了(删除要慎重:一定要备份 )
表操作
表与字段是密不可分的。
新增数据表
创建之前先指定数据库:use 数据库名;
例:
也可再在下面直接创建时这样写 : create table if not exists 数据库名.表名{ }
Create table [if not exists] 表名(
字段名字 数据类型
字段名字 数据类型 -- 最后一行不需要逗号
)[表选项]

If not exists : 如果表名不存在,就创建,否者不执行:检查功能
表选项:控制表的的表现
字符集:charset/character set 具体字符集; --保证表中数据存储的字符集
校对集:collate 具体校对集
存储引擎:engine 具体的存储引擎(innodb 和 myisam)
查看数据表
数据库能查看的方法数据表都能查看
1.查看所有表:show tables;
2.查看部分表(模糊查询):show tables like 关键字+%;
3.查看表创建语句:show create table class\g -- \g相当于分号(;)

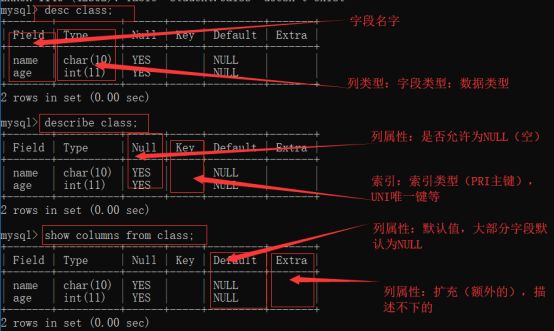
4.查看表结构:查看表中的字段信息
Desc/describe./show columns from 表名;
修改数据表
表本身存在,还包含字段:表的修改分为两个部分:修改表本身和修改字段
修改表本身
表本身可以修改:表名和表选项
Rename table 表名 to 新表名;

修改表选项:字符集,校对集和存储引擎
Alter table 表名 表选项 [=] 值;

修改字段
字段操作:新增,修改,重名,删除
新增字段
Alter table 表名 add[column] 字段名 数据类型 [列属性][位置];
位置:字段名可以存放在表中任意位置
First:第一个字段
After:在哪个字段之后 直接after:默认在最后一个字段之后

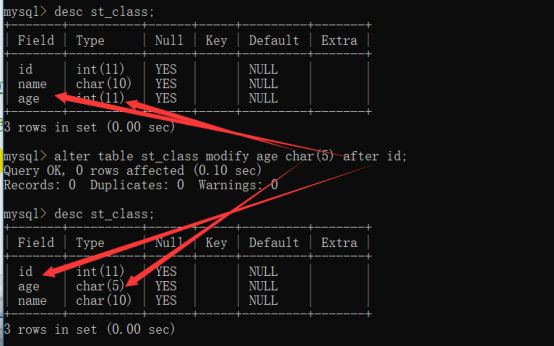
修改字段
Alter table 表名 modify 字段名 数据类型[属性]位置]
重命名字段
Alter table 表名 change 旧字段 新字段名字 数据类型[属性][位置]

删除字段
Alter table表名 drop 字段名;

注意:如果表中已经存在数据,删除字段将会清空其中的所有数据!
删除数据表
Drop table 表名1,表名2。。。 -- 可以同时删除多张表

注意:删除是不可逆的(一定要谨慎!)
数据操作
新增数据
有两种方案
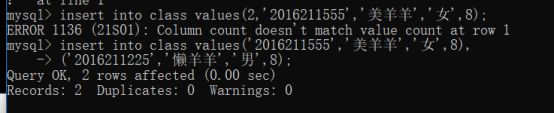
方案1:给全表字段插入数据,不需要指定字段列表:要求数据的值出现的顺序必须与涉及到字段出现的顺序一致:凡是非数值数据,都需要使用引号(建议是单引号)包裹
Insert into 表名 values(值列表)[,(值列表)]; -- 可以一次性插入多条数据
方案2:给部分字段插入数据,需要选定字段列表:字段列表出现的顺序与字段的顺序无关;但是值列表的顺序必须与选定的字段顺序一致。
Insert into 表名 (字段列表) values(值列表)[,(值列表)];

查看数据
Select */字段列表 from 表名 [where 条件];
查看所有字段

查看指定字段,指定条件的数据

更新数据
Update 表名 set 字段 = 值[where 条件]; -- 只要不是更新全部,建议都用where。
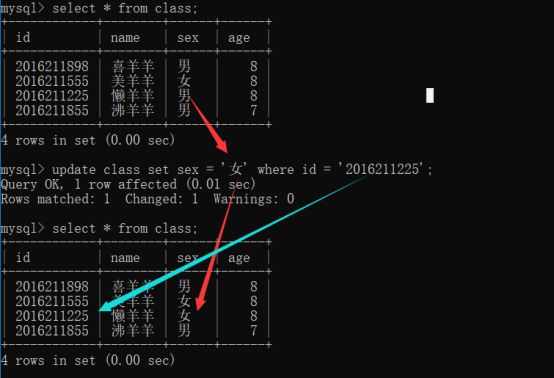
删除数据
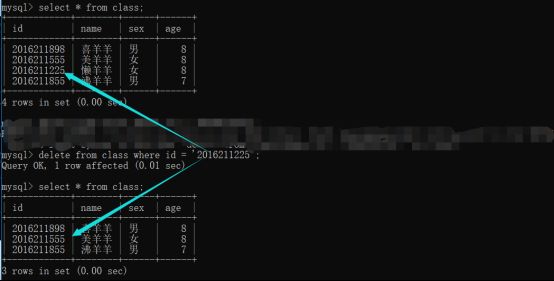
删除不可逆,谨慎行事!
Delete from表名 [where条件];
中文数据问题
中文数据问题本质是字符集问题
计算机只识别二进制:人类更多是识别符号:需要有个二进制与字符的对应关系(字符集)
中文数据解决方法:
方法1:通过在输入中文数据前运行set names gbk;解决
方法2:打开mysql安装目录,里面有个my.ini文件,打开这个文件,里面有两处字符
集的设置,将其设置为gbk然后启动mysql服务,以后创建的数据库默认字符集就可以直接输入中文了。
Ps:utf8三个字节一个汉字,gbk两个字节一个汉字
查看服务器能识别的字符集:
Show character set;
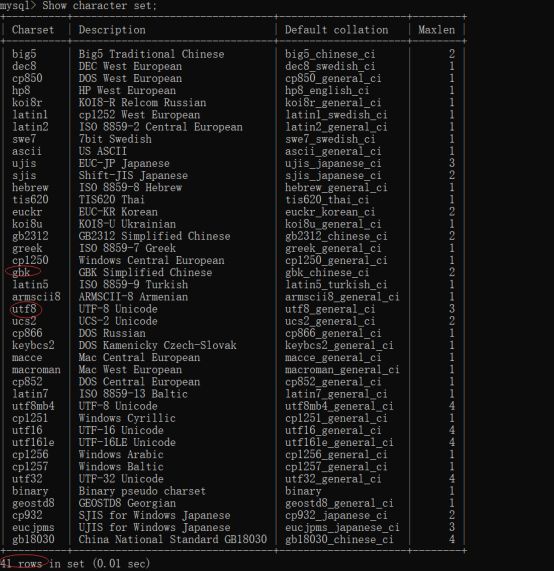
可以看出mysql服务器支持41种字符集。
查看服务器默认对外处理的字符集:
Show variables like ‘character_set%’;

校对集问题
校对集:数据比较的方式
校对集有三种格式
_bin::binary,二进制比较,取出二进制位,一位一位的比较,区分大小写
_cs:: case sensitive,大小写敏感,区分大小写
_ci : case insensitive 大小写不敏感,不区分大小写
查看数据库所支持的校对集
show collation;

从这里可以看出为什么utf8输入中文出错,gbk却行。
校对集应用
只有当数据进行比较时,校对集才生效
例:对比gbk的_ci 和 _bin 来验证不同的校对集的效果
1.创建不同校对集对应的表
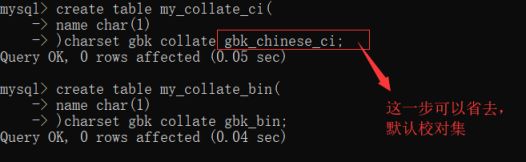
Ps: 默认校对集查看方法,上一标题查看所有校对集中的default选项里打了yes的即为默认。

2.插入数据

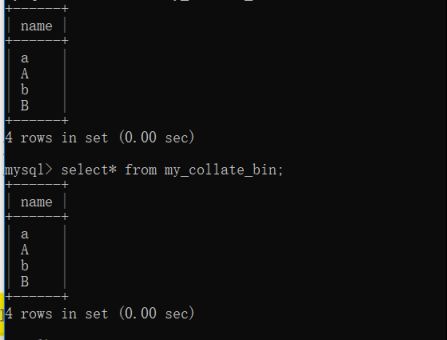
插入成功。
3.比较
根据某个字段进行排序:order by 字段名 [asc|desc],asc升序,desc降序,默认升序。
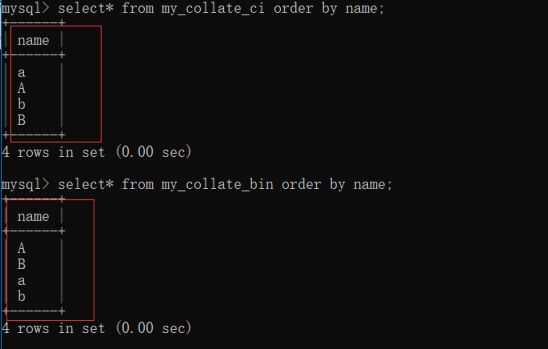
现在可以看出不同了
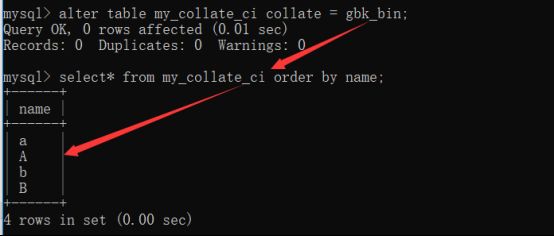
Ps:校对集必须在没有数据之前设置好,如果有了数据,那么再进行校对集修改是无效的。
数据类型
数据类型:对数据进行统一的分类,从系统的角度出发为了能够使用统一的方式进行管理:更好的利用有限的空间。
SQL中将数据类型分成了三大类“数值类型,字符串类型和时间日期类型。

数值型
数值型数据:都是数值
系统将数值型分为整数型和小数型
整数型
存放整形数据:在SQL中因为更多要考虑如何节省磁盘空间,所以系统将整形又细分成了5类:
Timyint:迷你整形,使用1个字节存储,表示的状态最多256种
Smallint:小整形,使用2个字节存储,表示的状态最多为65536种
Mediumint:中整形,使用3个字节存储
Int:标准整形,使用4个字节存储
Bigint:大整形,使用8个字节存储

创建一张整型表

插入数据

SQL中的数值类型全部默认有符号:分正负、
有时候需要使用无符号数据:需要给数据类型限定:int unsigned – 无符号
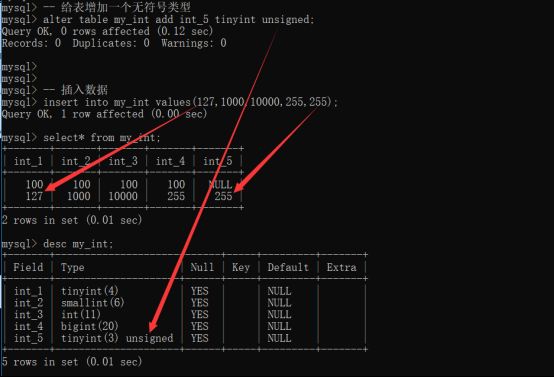
查看表结构时发现这里有些不同,老师说这是显示宽度

显示宽度:没有特别的含义:只是默认的告诉用户可以显示的形式而已:用户是可以控制的,这种控制也不会改变数据本身的大小。(上图原因:有符号的为-127到128,负数时是四位宽度,无符号255是三位)

显示宽度的意义:在于当数据不够显示宽度的时候,会自动让数据变成对应的显示宽度,通常需要一个前导0来增加宽度,不改变大小:zerofill。
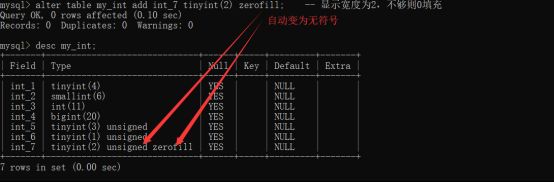
零填充效果

零填充意义:保证数据格式!!!可能有大用
小数型
小数型:带有小数点或者范围超出整数的数值类型
SQl中:将小数型分为:浮点型和定点型
浮点型:精度有限,而却会丢失精度
定点型:精度固定,不会丢失精度,
浮点型:
浮点型数据是一种精度类型数据:因为超出指定范围精度会消失(自动四舍五入),理论上分为两种精度。
Float:单精度,占用4个字节存储数据,精度范围大概为7位左右
Double:双精度,占用8个字节存储数据,精度范围15位左右

创建浮点数表:浮点的使用方式:直接float表示小数部分;float(M,D):M代表总长度,D代表小数部分长度,整数部分长度为M-D

插入数据,科学计数法也行
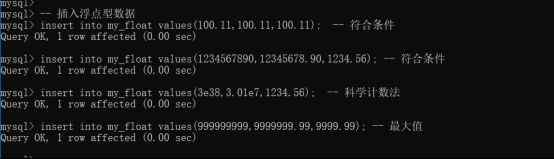
整型部分是不能超出长度的,小数部分可以(系统会自动四舍五入)

SQL高级操作
以下操作均使用这两个表
TEST表

TEST1表

表连接
sql表连接分成外连接、内连接和交叉连接
内连接
内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值
select * from Table1, Table2 where Table1.字段名 = Table.字段名
也可这样写:
select * from Table1 JOIN Table2 on Table1.字段名=Table2.字段名
或则:
select * from Table1 cross join Table2 where Table1.z字段名=Table2.i字段名(cross join 后只能用where不能用on)
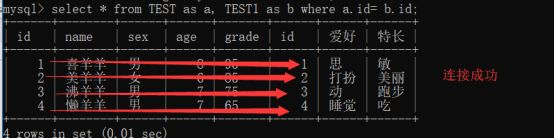
外连接
外连接包括三种,分别是左外连接、右外连接、全外连接。
对应的sql关键字:LEFT/RIGHT/FULL OUTER JOIN,通常我们都省略OUTER关键字,写成LEFT/RIGHT/FULL JOIN。
在左、右外连接中都会以一种表为基表,基表的所有行、列都会显示
全外连接则所有表的行、列都会显示
左连接
左外连接(简单说,左表数据全显示,右不匹配的显示null)
select * from Table1 left join Table2 on aTable1.字段名 = Table2.字段名
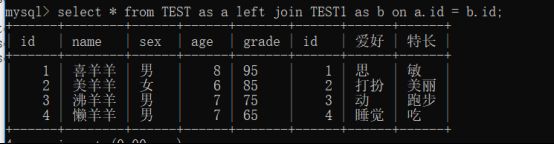

右连接
和左连接相反
select * from Table1 right join Table2 on Table1.字段名 = Table2.字段名
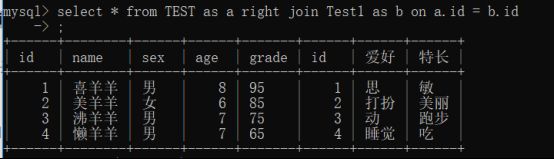
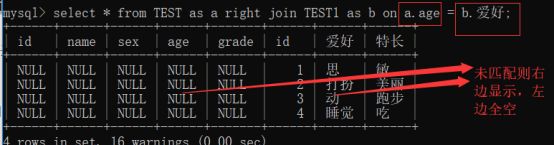
全连接
全连接(当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值)
select * from Table1 full outer join Table2 on Table1.字段名 = Table2.字段名;


交叉连接
没有where条件的交叉连接将产生连接表所涉及的笛卡尔积。即TableA的行数*TableB的行数的结果集。
select * from Table1,Table2;

聚合函数
| 函数 | 用法及功能 |
|---|---|
| SUM | 这个函数通常在SELECT语句中使用,返回系列值的总数 |
| AVG | 使用方法和SUM类似,它给我们提供系列值的算术平均数 |
| COUNT | 我们可以使用单独COUNT(*)语法来检索一个表内的行数。此外,还可以利用WHERE子句来设置计数条件,返回特定记录的条数 |
| MAX | 返回给定数据集中的最大值。我们可以给该函数一个字段名称来返回表中给定字段的最大值。还可以在MAX()函数中使用表达式和GROUP BY从句来加强查找功能。 |
| MIN | 与MAX类似,但返回表达式的最小值。 |
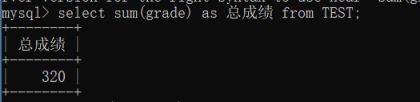
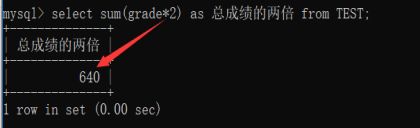
SUM函数:
返回系列数的总值
Select sum(字段名[+-*/…][字段名]) from 表名;
括号里面可以进行运算
AVG函数:
返回系列值的算术平均数
Select avg(字段名[+-*/…][字段名])from 表名;
括号里面可以进行运算

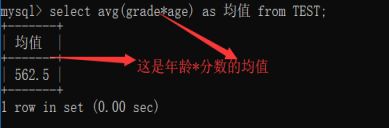
COUNT函数:
返回指定数值的个数
Select count() from 表名 where 控制条件

使用all关键字查询
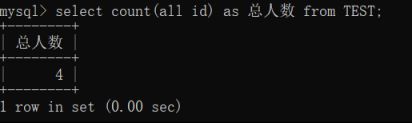
但是用all关键字查询却有点问题,例如:

这里性别也有四个,显然不是我们想要的结果,解决方法如下:
使用distinct关键字查询
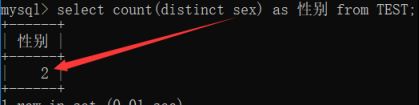
现在就行了。
MAX函数:
返回指定数据集中的最大值
Select max(字段名[+-*/…][字段名])from 表名;
括号里面可以进行运算
该函数还可以使用group by语句


MIN函数:
返回指定数据集中的最小值
Select min(字段名[+-*/…][字段名])from 表名;
括号里面可以进行运算
该函数还可以使用group by语句
子查询
定义
子查询允许把一个查询嵌套在另一个查询当中,实际就是嵌套查询。
子查询,又叫内部查询,相对于内部查询,包含内部查询的就称为外部查询
操作
对于上面两张表,如果我想要查询名字叫“喜羊羊”的“爱好”是什么,但他们在两张表里,但又有id是相同的,所以可以如下分两步查询
第一步:返回姓名叫喜羊羊的id

第二步:通过id在另一张表中查询爱好

但是这样两步就感觉有些麻烦,所以我们用子查询:

可以看出返回了一样的结果,而且其核心就是嵌套
再来一个例子,要得到每一个人的爱好

带有exists关键字的子查询
MySQL EXISTS 和 NOT EXISTS 子查询语法如下:
SELECT … FROM table WHERE EXISTS (subquery)
该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否得以保留。
下面我们先添加一个表TEST2
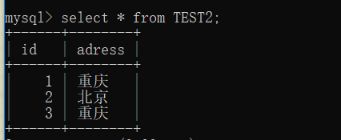
下面用实例来说明exists用法:
这里因为表TEST2中没有ID = 4的数据项,所以返回了false,表TEST中第四条数据没有被保留。
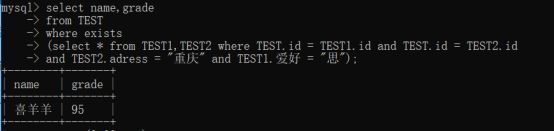
三张表的实例:查询在三张表中的数据中,地址在重庆,且爱好为’思’的名字和成绩: