[TOC]
本文主要讲述一个 topic 的创建过程,从 topic 是如何创建到 topic 真正创建成功的中间详细过程,文章主要内容可以分为以下几个部分
- topic 是如何创建的?
- 命令行创建;
- Producer 发送数据时,自动创建;
- topic 创建时,replicas 是如何分配的?
- 指定 replicas 的分配;
- 自动 replicas 分配;
- replicas 更新到 zk 后,底层如何创建一个 topic?
- 创建 Partition 对象及状态更新;
- 创建 Partition 的 replica 对象及状态更新。
一个 topic 的完整创建过程如下图所示(以 topic 的 replicas 自动创建,且 broker 没有机架感知为例)
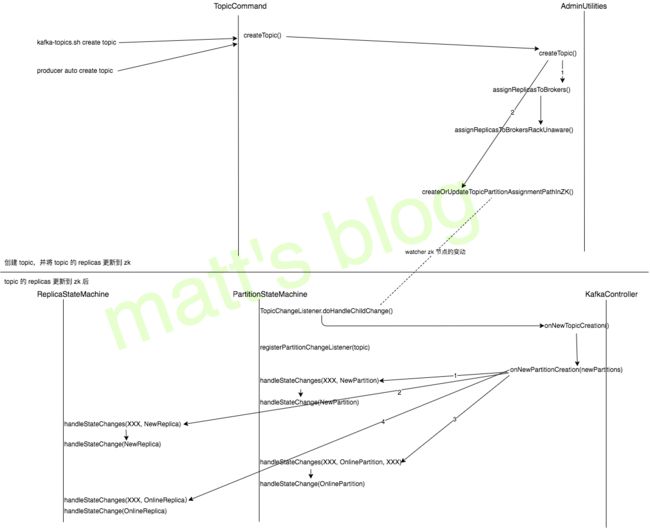
上图只是列出一些主要的方法调用,具体内容下面会详细讲述(在看下面的内容时,最后配合上面这张图来看)。
topic 介绍
topic 是 Kafka 中的一个消息队列的标识,也可以认为是消息队列的一个 id,用于区分不同的消息队列,一个 topic 由多个 partition 组成,这些 partition 是通常是分布在不同的多台 Broker 上的,为了保证数据的可靠性,一个 partition 又会设置为多个副本(replica),通常会设置两副本或三副本。如下图所示,这个一个名为『topic』的 topic,它由三个 partition 组成,两副本,假设 Kafka 集群有三台 Broker(replica 0_1 代表 partition 0 的第一个副本)。
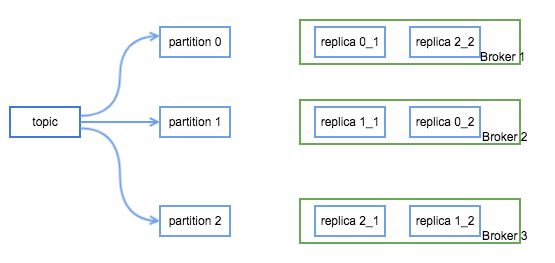
在设置副本时,副本数是必须小于集群的 Broker 数的,副本只有设置在不同的机器上才有作用。
topic 如何创建
topic 在创建时有两种方式:
- 通过 kafka-topics.sh 创建一个 topic,可以设置相应的副本数让 Server 端自动进行 replica 分配,也可以直接指定手动 replica 的分配;
- Server 端如果 auto.create.topics.enable 设置为 true 时,那么当 Producer 向一个不存在的 topic 发送数据时,该 topic 同样会被创建出来,此时,副本数默认是1。
下面看一下这两种方式的底层实现。
kafka-topics.sh 创建 topic
在 Kafka 的安装目录下,通过下面这条命令可以创建一个 partition 为3,replica 为2的 topic(test)
kafka-topics.sh 创建 topic
在 Kafka 的安装目录下,通过下面这条命令可以创建一个 partition 为3,replica 为2的 topic(test)
./bin/kafka-topics.sh --create --topic test --zookeeper XXXX --partitions 3 --replication-factor
kafka-topics.sh 实际上是调用 kafka.admin.TopicCommand 的方法来创建 topic,其实现如下:
//note: 创建 topic
def createTopic(zkUtils: ZkUtils, opts: TopicCommandOptions) {
val topic = opts.options.valueOf(opts.topicOpt)
val configs = parseTopicConfigsToBeAdded(opts)
val ifNotExists = opts.options.has(opts.ifNotExistsOpt)
if (Topic.hasCollisionChars(topic))
println("WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.")
try {
if (opts.options.has(opts.replicaAssignmentOpt)) {//note: 指定 replica 的分配,直接向 zk 更新即可
val assignment = parseReplicaAssignment(opts.options.valueOf(opts.replicaAssignmentOpt))
AdminUtils.createOrUpdateTopicPartitionAssignmentPathInZK(zkUtils, topic, assignment, configs, update = false)
} else {//note: 未指定 replica 的分配,调用自动分配算法进行分配
CommandLineUtils.checkRequiredArgs(opts.parser, opts.options, opts.partitionsOpt, opts.replicationFactorOpt)
val partitions = opts.options.valueOf(opts.partitionsOpt).intValue
val replicas = opts.options.valueOf(opts.replicationFactorOpt).intValue
val rackAwareMode = if (opts.options.has(opts.disableRackAware)) RackAwareMode.Disabled
else RackAwareMode.Enforced
AdminUtils.createTopic(zkUtils, topic, partitions, replicas, configs, rackAwareMode)
}
println("Created topic \"%s\".".format(topic))
} catch {
case e: TopicExistsException => if (!ifNotExists) throw e
}
}
如果指定了 partition 各个 replica 的分布,那么将 partition replicas 的结果验证之后直接更新到 zk 上,验证的 replicas 的代码是在 parseReplicaAssignment 中实现的,如下所示
def parseReplicaAssignment(replicaAssignmentList: String): Map[Int, List[Int]] = {
val partitionList = replicaAssignmentList.split(",")
val ret = new mutable.HashMap[Int, List[Int]]()
for (i <- 0 until partitionList.size) {
val brokerList = partitionList(i).split(":").map(s => s.trim().toInt)
val duplicateBrokers = CoreUtils.duplicates(brokerList)
if (duplicateBrokers.nonEmpty)//note: 同一个 partition 对应的 replica 是不能相同的
throw new AdminCommandFailedException("Partition replica lists may not contain duplicate entries: %s".format(duplicateBrokers.mkString(",")))
ret.put(i, brokerList.toList)
if (ret(i).size != ret(0).size)//note: 同一个 topic 的副本数必须相同
throw new AdminOperationException("Partition " + i + " has different replication factor: " + brokerList)
}
ret.toMap
}
如果没有指定 parittion replicas 分配的话,将会调用 AdminUtils.createTopic 方法创建 topic,这个方法首先会检测当前的 Kafka 集群是否机架感知,如果有的话先获取 Broker 的机架信息,接着再使用 Replica 自动分配算法来分配 Partition 的 replica,最后就跟指定 replica 方式一样,将 replicas 的结果更新到 zk 中。
def createTopic(zkUtils: ZkUtils,
topic: String,
partitions: Int,
replicationFactor: Int,
topicConfig: Properties = new Properties,
rackAwareMode: RackAwareMode = RackAwareMode.Enforced) {
val brokerMetadatas = getBrokerMetadatas(zkUtils, rackAwareMode)//note: 有机架感知的情况下,返回 Broker 与机架之间的信息
val replicaAssignment = AdminUtils.assignReplicasToBrokers(brokerMetadatas, partitions, replicationFactor)//note: 获取 partiiton 的 replicas 分配
AdminUtils.createOrUpdateTopicPartitionAssignmentPathInZK(zkUtils, topic, replicaAssignment, topicConfig)//note: 更新到 zk 上
}
Producer 创建 topic
只有当 Server 端的 auto.create.topics.enable 设置为 true 时,Producer 向一个不存在的 topic 发送数据,该 topic 才会被自动创建。
当 Producer 在向一个 topic 发送 produce 请求前,会先通过发送 Metadata 请求来获取这个 topic 的 metadata。Server 端在处理 Metadata 请求时,如果发现要获取 metadata 的 topic 不存在但 Server 允许 producer 自动创建 topic 的话(如果开启权限时,要求 Producer 需要有相应权限:对 topic 有 Describe 权限,并且对当前集群有 Create 权限),那么 Server 将会自动创建该 topic.
//note: 获取 topic 的 metadata 信息
private def getTopicMetadata(topics: Set[String], listenerName: ListenerName, errorUnavailableEndpoints: Boolean): Seq[MetadataResponse.TopicMetadata] = {
val topicResponses = metadataCache.getTopicMetadata(topics, listenerName, errorUnavailableEndpoints)
if (topics.isEmpty || topicResponses.size == topics.size) {
topicResponses
} else {
val nonExistentTopics = topics -- topicResponses.map(_.topic).toSet//note: 集群上暂时不存在的 topic 列表
val responsesForNonExistentTopics = nonExistentTopics.map { topic =>
if (topic == Topic.GroupMetadataTopicName) {
createGroupMetadataTopic()
} else if (config.autoCreateTopicsEnable) {//note: auto.create.topics.enable 为 true 时,即允许自动创建 topic
createTopic(topic, config.numPartitions, config.defaultReplicationFactor)
} else {
new MetadataResponse.TopicMetadata(Errors.UNKNOWN_TOPIC_OR_PARTITION, topic, false,
java.util.Collections.emptyList())
}
}
topicResponses ++ responsesForNonExistentTopics
}
}
其中 createTopic 还是调用了 AdminUtils.createTopic 来创建 topic,与命令行创建的底层实现是一样。
private def createTopic(topic: String,
numPartitions: Int,
replicationFactor: Int,
properties: Properties = new Properties()): MetadataResponse.TopicMetadata = {
try {
//note: 还是调用 AdminUtils 命令创建 topic
AdminUtils.createTopic(zkUtils, topic, numPartitions, replicationFactor, properties, RackAwareMode.Safe)
info("Auto creation of topic %s with %d partitions and replication factor %d is successful"
.format(topic, numPartitions, replicationFactor))
new MetadataResponse.TopicMetadata(Errors.LEADER_NOT_AVAILABLE, topic, Topic.isInternal(topic),
java.util.Collections.emptyList())
} catch {
case _: TopicExistsException => // let it go, possibly another broker created this topic
new MetadataResponse.TopicMetadata(Errors.LEADER_NOT_AVAILABLE, topic, Topic.isInternal(topic),
java.util.Collections.emptyList())
case ex: Throwable => // Catch all to prevent unhandled errors
new MetadataResponse.TopicMetadata(Errors.forException(ex), topic, Topic.isInternal(topic),
java.util.Collections.emptyList())
}
}
replica 如何分配
通过前面的内容,可以看到,无论使用哪种方式,最后都是通过 AdminUtils.createOrUpdateTopicPartitionAssignmentPathInZK() 将 topic 的 Partition replicas 的更新到 zk 上,这中间关键的一点在于:Partition 的 replicas 是如何分配的。在创建时,我们既可以指定相应 replicas 分配,也可以使用默认的算法自动分配。
创建时指定 replicas 分配
在创建 topic 时,可以通过以下形式直接指定 topic 的 replica
./bin/kafka-topics.sh --create --topic test --zookeeper XXXX --replica-assignment 1:2,3:4,5:6
该 topic 有三个 partition,其中,partition 0 的 replica 分布在1和2上,partition 1 的 replica 分布在3和4上,partition 3 的 replica 分布在5和6上。
这样情况下,在创建 topic 时,Server 端会将该 replica 分布直接更新到 zk 上。
replicas 自动分配算法
在创建 topic 时,Server 通过 AdminUtils.assignReplicasToBrokers() 方法来获取该 topic partition 的 replicas 分配。
/**
* 副本分配时,有三个原则:
* 1. 将副本平均分布在所有的 Broker 上;
* 2. partition 的多个副本应该分配在不同的 Broker 上;
* 3. 如果所有的 Broker 有机架信息的话, partition 的副本应该分配到不同的机架上。
*
* 为实现上面的目标,在没有机架感知的情况下,应该按照下面两个原则分配 replica:
* 1. 从 broker.list 随机选择一个 Broker,使用 round-robin 算法分配每个 partition 的第一个副本;
* 2. 对于这个 partition 的其他副本,逐渐增加 Broker.id 来选择 replica 的分配。
*
* @param brokerMetadatas
* @param nPartitions
* @param replicationFactor
* @param fixedStartIndex
* @param startPartitionId
* @return
*/
def assignReplicasToBrokers(brokerMetadatas: Seq[BrokerMetadata],
nPartitions: Int,
replicationFactor: Int,
fixedStartIndex: Int = -1,
startPartitionId: Int = -1): Map[Int, Seq[Int]] = {
if (nPartitions <= 0) // note: 要增加的 partition 数需要大于0
throw new InvalidPartitionsException("number of partitions must be larger than 0")
if (replicationFactor <= 0) //note: replicas 应该大于0
throw new InvalidReplicationFactorException("replication factor must be larger than 0")
if (replicationFactor > brokerMetadatas.size) //note: replicas 超过了 broker 数
throw new InvalidReplicationFactorException(s"replication factor: $replicationFactor larger than available brokers: ${brokerMetadatas.size}")
if (brokerMetadatas.forall(_.rack.isEmpty))//note: 没有开启机架感知
assignReplicasToBrokersRackUnaware(nPartitions, replicationFactor, brokerMetadatas.map(_.id), fixedStartIndex,
startPartitionId)
else { //note: 机架感知的情况
if (brokerMetadatas.exists(_.rack.isEmpty)) //note: 并不是所有的机架都有机架感知
throw new AdminOperationException("Not all brokers have rack information for replica rack aware assignment")
assignReplicasToBrokersRackAware(nPartitions, replicationFactor, brokerMetadatas, fixedStartIndex,
startPartitionId)
}
}
这里没有开启机架感知模式来介绍 topic partition replicas 的分配情况,其分配算法主要是 assignReplicasToBrokersRackUnaware() 方法中实现。
//note: partition 分配
private def assignReplicasToBrokersRackUnaware(nPartitions: Int,
replicationFactor: Int,
brokerList: Seq[Int],
fixedStartIndex: Int,
startPartitionId: Int): Map[Int, Seq[Int]] = {
val ret = mutable.Map[Int, Seq[Int]]()
val brokerArray = brokerList.toArray
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length) //note: 随机选择一个Broker
var currentPartitionId = math.max(0, startPartitionId) //note: 开始增加的第一个 partition
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
for (_ <- 0 until nPartitions) { //note: 对每个 partition 进行分配
if (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0))
nextReplicaShift += 1 //note: 防止 partition 过大时,其中某些 partition 的分配(leader、follower)完全一样
val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length //note: partition 的第一个 replica
val replicaBuffer = mutable.ArrayBuffer(brokerArray(firstReplicaIndex))
for (j <- 0 until replicationFactor - 1) //note: 其他 replica 的分配
replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length))
ret.put(currentPartitionId, replicaBuffer)
currentPartitionId += 1
}
ret
}
//note: 为 partition 设置完第一个 replica 后,其他 replica 分配的计算
private def replicaIndex(firstReplicaIndex: Int, secondReplicaShift: Int, replicaIndex: Int, nBrokers: Int): Int = {
val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)//note: 在 secondReplicaShift 的基础上增加一个 replicaIndex
(firstReplicaIndex + shift) % nBrokers
}
这里举一个栗子,假设一个 Kafka 集群有5个节点,新建的 topic 有10个 partition,并且是三副本,假设最初随机选择的 startIndex 和 nextReplicaShift 节点均为0
- partition 为0时,那第一副本在 (0+0)%5=0,第二个副本在 (0+(1+(0+0)%4)))%5=1,第三副本在 (0+(1+(0+1)%4)))%5=2;
- partition 为2时,那第一副本在 (0+2)%5=2,第二个副本在 (2+(1+(0+0)%4)))%5=3,第三副本在 (2+(1+(0+1)%4)))%5=4;
- partition 为5时,那第一副本在 (0+5)%5=0,第二个副本在 (0+(1+(1+0)%4)))%5=2,第三副本在 (0+(1+(1+1)%4)))%5=3(partition 数是 Broker 数一倍时,nextReplicaShift 值会增加1);
- partition 为8时,那第一副本在 (0+8)%5=3,第二个副本在 (3+(1+(1+0)%4)))%5=0,第三副本在 (3+(1+(1+1)%4)))%5=1。
replicas 更新到 zk 后触发的操作
这一部分的内容是由 Kafka Controller 来控制的(Kafka Controller 将会在后续文章中讲解),当一个 topic 的 replicas 更新到 zk 上后,监控 zk 这个目录的方法会被触发(TopicChangeListener.doHandleChildChange()方法),可以配合文章第一张图来看。
//note: 当 zk 上 topic 节点上有变更时,这个方法就会调用
def doHandleChildChange(parentPath: String, children: Seq[String]) {
inLock(controllerContext.controllerLock) {
if (hasStarted.get) {
try {
val currentChildren = {
debug("Topic change listener fired for path %s with children %s".format(parentPath, children.mkString(",")))
children.toSet
}
val newTopics = currentChildren -- controllerContext.allTopics//note: 新创建的 topic 列表
val deletedTopics = controllerContext.allTopics -- currentChildren//note: 已经删除的 topic 列表
controllerContext.allTopics = currentChildren
//note: 新创建 topic 对应的 partition 列表
val addedPartitionReplicaAssignment = zkUtils.getReplicaAssignmentForTopics(newTopics.toSeq)
controllerContext.partitionReplicaAssignment = controllerContext.partitionReplicaAssignment.filter(p =>
!deletedTopics.contains(p._1.topic))//note: 把已经删除 partition 过滤掉
controllerContext.partitionReplicaAssignment.++=(addedPartitionReplicaAssignment)//note: 将新增的 tp-replicas 更新到缓存中
info("New topics: [%s], deleted topics: [%s], new partition replica assignment [%s]".format(newTopics,
deletedTopics, addedPartitionReplicaAssignment))
if (newTopics.nonEmpty)//note: 处理新建的 topic
controller.onNewTopicCreation(newTopics, addedPartitionReplicaAssignment.keySet)
} catch {
case e: Throwable => error("Error while handling new topic", e)
}
}
}
}
这个方法主要做了以下内容:
- 获取 zk 的 topic 变更信息,得到新创建的 topic 列表(newTopics)以及被删除的 topic 列表(deletedTopics);
- 将 deletedTopics 的 replicas 从 controller 的缓存中删除,并将新增 topic 的 replicas 更新到 controller 的缓存中;
- 调用 KafkaController 的 onNewTopicCreation() 创建 partition 和 replica 对象。
KafkaController 中 onNewTopicCreation() 方法先对这些 topic 注册 PartitionChangeListener,然后再调用 onNewPartitionCreation() 方法创建 partition 和 replicas 的实例对象,topic 创建的主要实现是在 KafkaController onNewPartitionCreation() 这个方法中。
//note: 当 partition state machine 监控到有新 topic 或 partition 时,这个方法将会被调用
/**
* 1. 注册 partition change listener;
* 2. 触发 the new partition callback,也即是 onNewPartitionCreation()
* 3. 发送 metadata 请求给所有的 Broker
* @param topics
* @param newPartitions
*/
def onNewTopicCreation(topics: Set[String], newPartitions: Set[TopicAndPartition]) {
info("New topic creation callback for %s".format(newPartitions.mkString(",")))
// subscribe to partition changes
topics.foreach(topic => partitionStateMachine.registerPartitionChangeListener(topic))
onNewPartitionCreation(newPartitions)
}
//note: topic 变化时,这个方法将会被调用
//note: 1. 将新创建的 partition 置为 NewPartition 状态; 2.从 NewPartition 改为 OnlinePartition 状态
//note: 1. 将新创建的 Replica 置为 NewReplica 状态; 2.从 NewReplica 改为 OnlineReplica 状态
def onNewPartitionCreation(newPartitions: Set[TopicAndPartition]) {
info("New partition creation callback for %s".format(newPartitions.mkString(",")))
partitionStateMachine.handleStateChanges(newPartitions, NewPartition)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions), NewReplica)
partitionStateMachine.handleStateChanges(newPartitions, OnlinePartition, offlinePartitionSelector)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions), OnlineReplica)
}
在详细介绍这四个方法的调用之前,先简单详述一下 Partition 和 Replica 状态机的变化。
Partition 状态机
关于 Partition 状态的变化可以参考 Kafka 中的这个方法 PartitionStateMachine,状态机的具体转换情况如下图所示
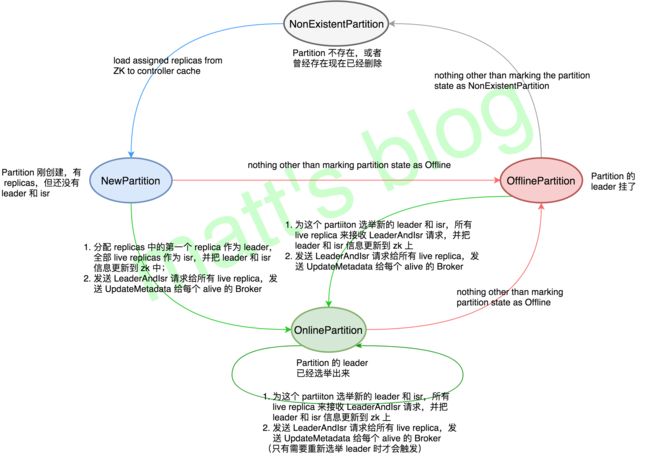
一个 Partition 对象有四种状态:
- NonExistentPartition:这个 partition 不存在;
- NewPartition:这个 partition 刚创建,有对应的 replicas,但还没有 leader 和 isr;
- OnlinePartition:这个 partition 的 leader 已经选举出来了,处理正常的工作状态;
- OfflinePartition:partition 的 leader 挂了。
partition 只有在 OnlinePartition 这个状态时,才是可用状态。
Replica 状态机
关于 Replica 状态的变化可以参考 Kafka 中的这个方法 ReplicaStateMachine,,状态机的具体转换情况如下图所示
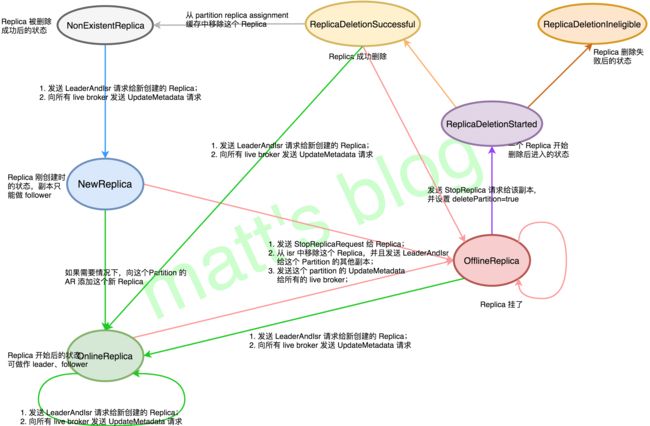
Replica 对象有七种状态,中文解释的比较难以理解,直接上原文对这几种状态的解释。
- NewReplica:The controller can create new replicas during partition reassignment. In this state, a replica can only get become follower state change request.
- OnlineReplica:Once a replica is started and part of the assigned replicas for its partition, it is in this state. In this state, it can get either become leader or become follower state change requests.
- OfflineReplica:If a replica dies, it moves to this state. This happens when the broker hosting the replica is down.
- ReplicaDeletionStarted:If replica deletion starts, it is moved to this state.
- ReplicaDeletionSuccessful:If replica responds with no error code in response to a delete replica request, it is moved to this state.
- ReplicaDeletionIneligible:If replica deletion fails, it is moved to this state.
- NonExistentReplica:If a replica is deleted successfully, it is moved to this state.
onNewPartitionCreation() 详解
这个方法有以下四步操作:
- partitionStateMachine.handleStateChanges(newPartitions, NewPartition): 创建 Partition 对象,并将其状态置为 NewPartition 状态
- replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions), NewReplica):创建 Replica 对象,并将其状态置为 NewReplica 状态;
- partitionStateMachine.handleStateChanges(newPartitions, OnlinePartition, offlinePartitionSelector):将 partition 对象从 NewPartition 改为 OnlinePartition 状态;
- replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions), OnlineReplica):将 Replica 对象从 NewReplica 改为 OnlineReplica 状态。
partitionStateMachine > NewPartition
这部分的作用是,创建分区对象,并将其状态设置为 NewPartition。
case NewPartition =>
//note: 新建一个 partition
assertValidPreviousStates(topicAndPartition, List(NonExistentPartition), NewPartition)
partitionState.put(topicAndPartition, NewPartition) //note: 缓存 partition 的状态
val assignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition).mkString(",")
stateChangeLogger.trace("Controller %d epoch %d changed partition %s state from %s to %s with assigned replicas %s"
.format(controllerId, controller.epoch, topicAndPartition, currState, targetState,
assignedReplicas))
replicaStateMachine > NewReplica
这部分是为每个 Partition 创建对应的 replica 对象,并将其状态设置为 NewReplica,参照状态机的变化图更好理解。
case NewReplica =>
assertValidPreviousStates(partitionAndReplica, List(NonExistentReplica), targetState) //note: 验证
// start replica as a follower to the current leader for its partition
val leaderIsrAndControllerEpochOpt = ReplicationUtils.getLeaderIsrAndEpochForPartition(zkUtils, topic, partition)
leaderIsrAndControllerEpochOpt match {
case Some(leaderIsrAndControllerEpoch) =>
if(leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId)//note: 这个状态的 Replica 不能作为 leader
throw new StateChangeFailedException("Replica %d for partition %s cannot be moved to NewReplica"
.format(replicaId, topicAndPartition) + "state as it is being requested to become leader")
//note: 向所有 replicaId 发送 LeaderAndIsr 请求,这个方法同时也会向所有的 broker 发送 updateMeta 请求
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(List(replicaId),
topic, partition, leaderIsrAndControllerEpoch,
replicaAssignment)
case None => // new leader request will be sent to this replica when one gets elected
partitionStateMachine > OnlinePartition
这个方法的主要的作用是将 partition 对象的状态由 NewPartition 设置为 OnlinePartition,从状态机图中可以看到,会有以下两步操作:
- 初始化 leader 和 isr,replicas 中的第一个 replica 将作为 leader,所有 replica 作为 isr,并把 leader 和 isr 信息更新到 zk;
- 发送 LeaderAndIsr 请求给所有的 replica,发送 UpdateMetadata 给所有 Broker。
// post: partition has been assigned replicas
case OnlinePartition =>
assertValidPreviousStates(topicAndPartition, List(NewPartition, OnlinePartition, OfflinePartition), OnlinePartition)
partitionState(topicAndPartition) match {
case NewPartition =>
// initialize leader and isr path for new partition
initializeLeaderAndIsrForPartition(topicAndPartition) //note: 为新建的 partition 初始化 leader 和 isr
case OfflinePartition =>
electLeaderForPartition(topic, partition, leaderSelector)
case OnlinePartition => // invoked when the leader needs to be re-elected
electLeaderForPartition(topic, partition, leaderSelector)
case _ => // should never come here since illegal previous states are checked above
}
实际的操作是在 initializeLeaderAndIsrForPartition() 方法中完成,这个方法是当 partition 对象的状态由 NewPartition 变为 OnlinePartition 时触发的,用来初始化该 partition 的 leader 和 isr。简单来说,就是选取 Replicas 中的第一个 Replica 作为 leader,所有的 Replica 作为 isr,最后调用 brokerRequestBatch.addLeaderAndIsrRequestForBrokers 向所有 replicaId 发送 LeaderAndIsr 请求以及向所有的 broker 发送 UpdateMetadata 请求(关于 Server 对 LeaderAndIsr 和 UpdateMetadata 请求的处理将会后续文章中讲述)。
//note: 当 partition 状态由 NewPartition 变为 OnlinePartition 时,将触发这一方法,用来初始化 partition 的 leader 和 isr
private def initializeLeaderAndIsrForPartition(topicAndPartition: TopicAndPartition) {
val replicaAssignment = controllerContext.partitionReplicaAssignment(topicAndPartition)
val liveAssignedReplicas = replicaAssignment.filter(r => controllerContext.liveBrokerIds.contains(r))
liveAssignedReplicas.size match {
case 0 =>
val failMsg = ("encountered error during state change of partition %s from New to Online, assigned replicas are [%s], " +
"live brokers are [%s]. No assigned replica is alive.")
.format(topicAndPartition, replicaAssignment.mkString(","), controllerContext.liveBrokerIds)
stateChangeLogger.error("Controller %d epoch %d ".format(controllerId, controller.epoch) + failMsg)
throw new StateChangeFailedException(failMsg)
case _ =>
debug("Live assigned replicas for partition %s are: [%s]".format(topicAndPartition, liveAssignedReplicas))
// make the first replica in the list of assigned replicas, the leader
val leader = liveAssignedReplicas.head //note: replicas 中的第一个 replica 选做 leader
val leaderIsrAndControllerEpoch = new LeaderIsrAndControllerEpoch(new LeaderAndIsr(leader, liveAssignedReplicas.toList),
controller.epoch)
debug("Initializing leader and isr for partition %s to %s".format(topicAndPartition, leaderIsrAndControllerEpoch))
try {
zkUtils.createPersistentPath(
getTopicPartitionLeaderAndIsrPath(topicAndPartition.topic, topicAndPartition.partition),
zkUtils.leaderAndIsrZkData(leaderIsrAndControllerEpoch.leaderAndIsr, controller.epoch))//note: zk 上初始化节点信息
// NOTE: the above write can fail only if the current controller lost its zk session and the new controller
// took over and initialized this partition. This can happen if the current controller went into a long
// GC pause
controllerContext.partitionLeadershipInfo.put(topicAndPartition, leaderIsrAndControllerEpoch)
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(liveAssignedReplicas, topicAndPartition.topic,
topicAndPartition.partition, leaderIsrAndControllerEpoch, replicaAssignment)//note: 向 live 的 Replica 发送 LeaderAndIsr 请求
} catch {
case _: ZkNodeExistsException =>
// read the controller epoch
val leaderIsrAndEpoch = ReplicationUtils.getLeaderIsrAndEpochForPartition(zkUtils, topicAndPartition.topic,
topicAndPartition.partition).get
val failMsg = ("encountered error while changing partition %s's state from New to Online since LeaderAndIsr path already " +
"exists with value %s and controller epoch %d")
.format(topicAndPartition, leaderIsrAndEpoch.leaderAndIsr.toString(), leaderIsrAndEpoch.controllerEpoch)
stateChangeLogger.error("Controller %d epoch %d ".format(controllerId, controller.epoch) + failMsg)
throw new StateChangeFailedException(failMsg)
}
}
replicaStateMachine > OnlineReplica
这一步也就是最后一步,将 Replica 对象的状态由 NewReplica 更新为 OnlineReplica 状态,这些 Replica 才真正可用。
case OnlineReplica =>
assertValidPreviousStates(partitionAndReplica,
List(NewReplica, OnlineReplica, OfflineReplica, ReplicaDeletionIneligible), targetState)
replicaState(partitionAndReplica) match {
case NewReplica =>
// add this replica to the assigned replicas list for its partition
//note: 向 the assigned replicas list 添加这个 replica(正常情况下这些 replicas 已经更新到 list 中了)
val currentAssignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition)
if(!currentAssignedReplicas.contains(replicaId))
controllerContext.partitionReplicaAssignment.put(topicAndPartition, currentAssignedReplicas :+ replicaId)
stateChangeLogger.trace("Controller %d epoch %d changed state of replica %d for partition %s from %s to %s"
.format(controllerId, controller.epoch, replicaId, topicAndPartition, currState,
targetState))
一直到这一步,一个 topic 就才算真正被创建完成。