本文首发于:行者AI
由于目前团队性能测试需求较多,所以调研了目前比较流行的几款压测工具,由于Jmeter与LoadRunner基于多线程实现并发,多线程由操作系统决定,由于上下文切换频繁,内核调度频繁导致单台机器很难产生大量的线程并发。以多线程方式运行会有很多线程切换的开销导致资源的浪费,故而考虑用多协程的方式实现,Jmeter由Java语言编写但Java不支持协程机制。 Python语言通过async/await的方式实现协程,恰好Locust正是基于python。所以这次把侧重点放在Locust性能测试工具。
首先,我们要明白只有产生压力才能评估项目的性能,性能测试关键是要通过工具产生大量的并发,而并发的强弱取决于工具的实现原理,由于Locust比较轻量,脚本设计较为灵活,很多重量级压测工具可以实现的功能在Locust中同样可以实现。且python语言的locust则可以以更轻量级的方式实现高并发,所以接下来将通过重要功能的介绍与代码示例来带大家看下如何快速上手Locust。
1. Locust的特点
(1)基于python开发脚本;
(2)开源免费,可以二次开发;
(3)分布执行。配置master和slave(主从机器),在多要机器上对系统持续发起请求;
(4)基于事件驱动。与其他工具使用进程和线程来模拟用户不同,Locust借助gevent库对协程的支持,可以达到更高数量级的并发;
(5)不支持监控被测机器,需要配合其他工具的辅助;
(6)在Locust类中,具有一个client属性,对应着虚拟用户作为客户端所具备的请求能力,也就是我们常说的请求方法;所以在使用Locust时,需要先继承Locust类,然后在继承子类中的client属性中绑定客户端的实现类;
(7)HttpUser使用到了requests.Session,因此后续所有任务执行过程中就都具有登录态;
(8)版本变动:1.0版本之后的更新重点是将HttpLocust替换为Httpuser,task_set任务集需要数据类型为列表类型,且task_set需要修改为tasks。
2. Locust的指标体系及常用使用流程
(1)响应时间:反应系统处理效率指标,从开始到完成某项工作所需要时间的度量,响应时间通常随着负载的增加而增加;
(2)吞吐量:反应系统处理能力的指标,指单位时间内完成工作的度量,可以从客户端或服务端视角两方面来进行综合评估;
(3)事务处理能力(TPS在locust中为RPS):对一笔业务进行处理时的相应情况,通常包含三个指标,一是处理该业务的响应时间,二是处理该业务的成功率,三是单位时间内(每秒钟,每分钟,每小时等)可以处理的业务数量。
cmd命令执行脚本
web界面操作(web界面不会自动停止,需要手动stop);
进入到项目目录,py文件这一层级;
locust -f test.py 或者 locust -f test.py --host=http://example.com;
打开浏览器进入web界面 添入 模拟的用户总数和每秒启动的虚拟用户数;
http://localhost:8089;
测试结果界面:

纯命令运行
locust -f test.py --no-web -c 100 -r 20 -t 5 或者 locust -f test.py --host=http://example.com --no-web -c 100 -r 20 -t 5;
-c: 用户数量;
-r: 每秒生成数量;
-t: 限制运行时间;
-n: 请求总次数;
3. Locust的语法格式
(1)定义一个任务类,这个类名称自己随便定义;
(2)继承SequentialTaskSet 或 TaskSet类,所以要从locust中,引入SequentialTaskSet或TaskSet;
(3)当类里面的任务请求有先后顺序时继承SequentialTaskSet类;
(4)没有先后顺序,可以使用继承TaskSet类;
import random
from locust import HttpUser, task, between, SequentialTaskSet, tag
class MyTaskCase(SequentialTaskSet):
# 初始化方法,相当于 setup
def on_start(self):
pass
# @task python中的装饰器,告诉下面的方法是一个任务,
# 这个装饰器和下面的方法被复制多次,改动一下,就能写出多个接口
# 装饰器后面带上(数字)代表在所有任务中,执行比例
# 要用这个装饰器,需要头部引入 从locust中,引入 task
@task
@tag("leave_1")
def regist_(self): # 一个方法, 方法名称可以自己改
url = '/erp/regist' # 接口请求的URL地址
# 定义请求头为类变量,这样其他任务也可以调用该变量
self.headers = {"Content-Type": "application/json"}
self.username = "locust_" + str(random.randint(10000, 100000))
self.pwd = '1234567890'
# post请求的 请求体
data = {"name": self.username, "pwd": self.pwd}
# 使用self.client发起请求,请求的方法根据接口实际选,
# catch_response 值为True 允许为失败 ,
# name 设置任务标签名称 -----可选参数
with self.client.post(url,
json=data,
headers=self.headers,
catch_response=True) as rsp:
if rsp.status_code > 400:
print(rsp.text)
rsp.failure('regist_ 接口失败!')
@task # 装饰器,说明下面是一个任务
def login_(self):
url = '/erp/loginIn' # 接口请求的URL地址
data = {"name": self.username, "pwd": self.pwd}
with self.client.post(url,
json=data,
headers=self.headers,
catch_response=True) as rsp:
# 提取响应json 中的信息,定义为 类变量
self.token = rsp.json()['token']
if rsp.status_code < 400 \
and rsp.json()['code'] == "200":
rsp.success()
else:
rsp.failure('login_ 接口失败!')
@task # 装饰器,说明下面是一个任务
def getuser_(self):
url = '/erp/user' # 接口请求的URL地址
# 引用上一个任务的 类变量值 实现参数关联
headers = {"Token": self.token}
# 使用self.client发起请求,请求的方法 选择 get
with self.client.get(url,
headers=headers,
catch_response=True) as rsp:
if rsp.status_code < 400:
rsp.success()
else:
rsp.failure('getuser_ 接口失败!')
# 结束方法, 相当于teardown
def on_stop(self):
pass
# 定义一个运行类 继承HttpUser类, 所以要从locust中引入 HttpUser类
class UserRun(HttpUser):
tasks = [MyTaskCase]
# 设置运行过程中间隔时间 需要从locust中 引入 between
wait_time = between(0.1, 3)
4. 单接口压测示例
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from locust import task,TaskSet,HttpUser
class UserTasks(TaskSet):
# 声明下面是一个任务
@task
def getIndex(self):
# self.client是TaskSet的成员,相当于一个request对象
self.client.get("/path")
print("here")
class WebUser(HttpUser):
# 声明执行的任务集是哪个类
tasks = [UserTasks]
# 最小等待时间和最大等待时间 请求间的间隔时间
min_wait = 1000
max_wait = 2000
运行:
在终端中输入:locust -f 被执行的locust文件.py --host=http://被测服务器域名或ip端口地址,也可以不指定host,如 "locust -f locust_test.py --host=http://localhost:8082"; 当命令执行成功,会提示服务端口,如:*:8089。此时,则可通过浏览器访问机器ip:8089,看到任务测试页面。
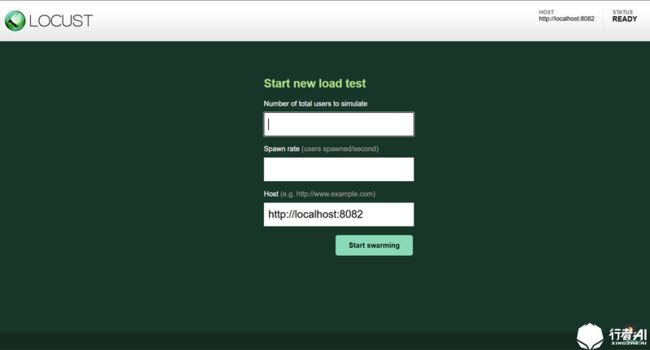
Number of total users to simulate 模拟的用户数
Spawn rate (users spawned/second) 每秒产生的用户数
5. 业务用例压测示例
下面以一个登录接口和获取id的接口为例
# #!/usr/bin/env python
# # -*- coding: utf-8 -*-
from locust import task,TaskSet,HttpUser,tag
from random import randint
import json
class UserTasks(TaskSet):
def on_start(self):
# 准备测试,请求接受的大多是字典格式
self.loginData = [{"username":"1","paswordword":"1"},
{"username":"2","paswordword":"2"},
{"username":"3","paswordword":"3"}]
print("-----------on_start----------------")
# 声明下面是一个登录任务
@task(1)
def doLogin(self):
ranIndex = randint(1,len(self.loginData))
# 发送请求并响应
response = self.client.post("/path",data = self.loginData[ranIndex],catch_response=True)
if "login-pass" in response.text:
response.success()
else:
response.failure("Can not login!")
# 声明下面是一个获取商品任务
@task
def get_goods(self):
body = {"good_name" :"apple"}
# 发送请求并响应
response = self.client.post("/path2",data = body,catch_response=True)
newText = json.loads(response.txt)
if "game_id" in newText[0].keys():
response.success()
else:
response.failure("Can not get!")
#为任务分配权重
tasks = {doLogin:1, get_goods:2}
#增加 tag 标签,在执行时,可以用 -T \ --tags 指定标签执行、-E \ --exclude-tags 排除指定标签执行
class WebUser(User):
@task
@tag("tag1", "tag2")
def my_task(self):
pass
class WebUser(HttpUser):
# 声明执行的任务集是哪个类,任务集中的任务按已分配的1:2权重执行
tasks = [UserTasks]
# 最小等待时间和最大等待时间 请求间的间隔时间
min_wait = 1000
max_wait = 2000
# locust -f locust_test.py --host=http://localhost:8082
# Number of total users to simulate 模拟的用户数
# Spawn rate (users spawned/second) 每秒产生的用户数
注:如果任务接口的请求值需要其他接口返回值中的参数,这些非任务请求也会在locust的统计面板中显示出来。若想只关注任务接口的统计数据,则依赖的请求需用原生requests库。
6. 数据监测工具推荐
(1)如果公司有搭建监测系统,可请运维协助在平台查看即可,比如Grafana;
(2)linux检测工具Nmon;
(3)windows自带perfmon;
(4)使用python的psuil库自定义检测频率与指标参数,需要对数据单独进行处理;
7. 总结
相比较jmeter等工具基于python语言locust的自由度高了很多,可以自定义特殊协议的实现方法,且locust基于协程更容易构造性能自动化测试平台,如果压测机的配置有限,又想满足足够高的并发量。用locust来实现是一个明智的选择。
我们是行者AI,我们在“AI+游戏”中不断前行。
如果你也对游戏感兴趣,对AI充满好奇,就快来加入我们吧~