匹配估计的思想:假如你要研究企业的R&D投入对performance的影响,匹配思想是这样的:假如有两家企业,其R&D投入明显不同,但是其他各方面都高度相同,例如公司规模,杠杆率,所属行业,公司治理结构等,那么在其他各方面都高度相同的情况下,这时就可以把公司performance的差异归因到R&D投入的差异。这种找到一个控制组的个体,使得该个体与处理组的个体在除自变量外其他各因素都相似(也就是匹配),在通过自变量的差异解释因变量差异的行为,就是匹配的思想。
一般来说,每个样本有多个属性,例如一家公司,属性有公司规模,公司年龄,杠杆率,增长率,市场占有率,治理结构相关变量,行业等,这就意味着匹配时要考虑诸多属性,也就是进行高维度匹配。一个比较好的思路是定义高维空间的距离,然后计算两个样本在高维空间的距离。
倾向得分的定义是一个个体进入处理组的概率,为什么要引入这个概念?因为如果针对多个可观察特征X进行对比匹配非常困难,所以,可将多维协变量X用一个一维变量——倾向得分P(x)来代替,这样,研究者就只需要对单一的倾向得分变量进行匹配,从而大大减少了匹配的困难。这个方法最早由Rosenbaum and Rubin(1983)提出。
PSM在stata的实现过程。
首先,如果自变量是连续变量,需要转换为二元离散变量,比如自变量是企业R&D投入,你需要找到一个临界值,把R&D投入分为高R&D投入组和低R&D投入组,临界值包括:平均数,上下三分位数,及其他分位数等,没有明确规定。在具体做时,可找一篇类似topic的好点的期刊,看看他们是怎么分的,这样在分组时也有依据。如果自变量本身就是二元离散变量,更简单,都不用分组了,直接按0-1分组。在stata上代码如下
对于离散变量:
gen dv_dum=2 //dv是指变量,dv_dum是指生成自变量的二元变量。
replace dv_dum=0 if dv=0
replace dv_dum=1 if dv=1
如果你的自变量本身就是标为0和1,这一步可以不用,但是如果标为1和2或者其他符号,一定要转换为0和1.
对于连续变量:
quantities dv, gen (dv_dum) nq(3)//根据分位数产生三个虚拟变量,也就是决定选择一个三分位数(上三分位或者下三分位数)为临界值。
replace dv_dum=0 if dv_dum==1
replace dv_dum=0 if dv_dum==2
replace dv_dum=1 if dv_dum==3//意思是把自变量从小到大排列,最大的1/3作为较高的组,标为1,剩余较小的2/3作为较低的组,标为0.
在这一部完成后,就可以开始匹配了。
set seed 10101
gen ranorder=runiform()
sort ranorder
psmatch2 dv_dum 匹配变量1 匹配变量2 匹配变量3......, outcome (因变量) 匹配方法 ate ties logit common
对上一条代码的解释:
psmatch2是stata里的匹配命令,如果没有安装需要先安装:ssc install psmatch2;
匹配变量1 匹配变量2 匹配变量3......是指你认为应该让两者一致的变量,比如,你要研究R&D对performance的影响,你就要想想应该让这两家公司的哪些特征一致然后再来比较两家公司R&D对performance的影响。这里的匹配变量可以是控制变量,也可以不仅仅是控制变量,看你能想到什么特征,能得到什么数据。具体在选择匹配变量时,还是要看看类似topic的好点的期刊怎么选的。
匹配方法:陈强书上介绍了8种方法,你可以每一种都试试,一般来说集中方法匹配的最终结果差异不大。
ate:同时汇报ATE,ATU与ATT的结果
ties :包括所有倾向得分相同的个体
logit: 这次匹配用到的回归方法是logit回归。
common:仅对共同取值范围内的个体匹配,默认对所有个体进行匹配。
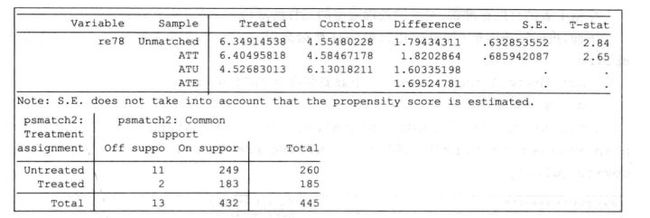
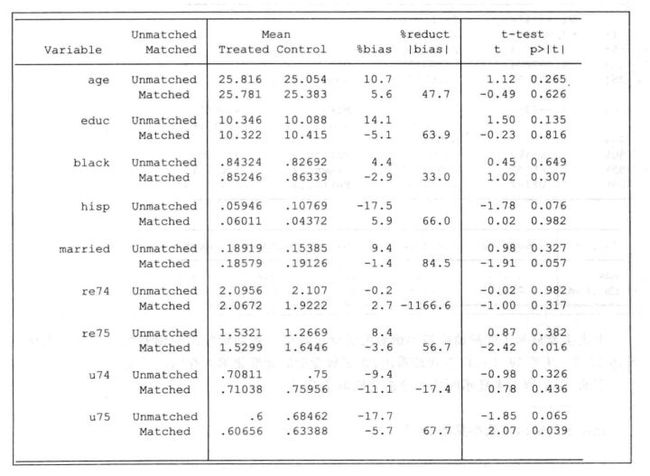
对匹配结果的解读,以陈强书为例:

这是陈强书548页的一个匹配结果,这张表关注的点不是上面变量的系数符号与显著性,关注的是ATT的difference值及其T值(实际上这个T值也可不关注)。ATT是个体在干预状态下的平均干预效应,也就是在控制其他匹配变量不变的情况下,自变量从0变为1,因变量的变化。
这里ATT的difference是1.41,意思是在其他匹配变量一致的情况下,自变量是1与自变量是0导致的因变量的差异是1.41个单位,这就是我们要求的系数。接下来根据T值确定p值,这里的T值就是个T检验,T值1.96对应的p值是0.05,一半要求大于1.96,具体可查看T检验统计表。不过Note提示了,这个表格的标准误差有两个问题,就是没有考虑倾向得分为估计所得的事实,即假设倾向得分为真实值,然后求标准误,并且该标准误假设同方差,也可能不成立。为此,考虑使用自助法求标准误,尽管自助标准误差也未必正确。
set seed 10101
bootstrap r(att) r(atu) r(ate), reps(500): psmatch2 dv_dum controls , outcome (Y) ties ate logit common
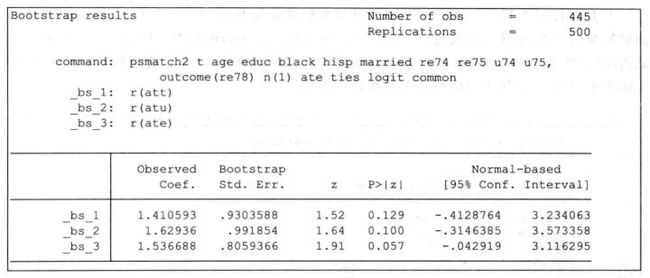
p值求出来了,大于0.1,不显著。这不能说明PSM得到了一个不显著的结果。刚才用的匹配法是一对一匹配,一般来说要把几种常见匹配都试试。陈强书中就把8种匹配法都试了,其中有几种得到了显著的结果。例如用核匹配得到的结果,T值大于1.96,不过这里也应该用自助法求出控制异方差的p值。
用PSM求系数的步骤已经完成了,还有一步是检验匹配结果是否平衡。
pstest Y 匹配变量1 匹配变量2 匹配变量3......, both
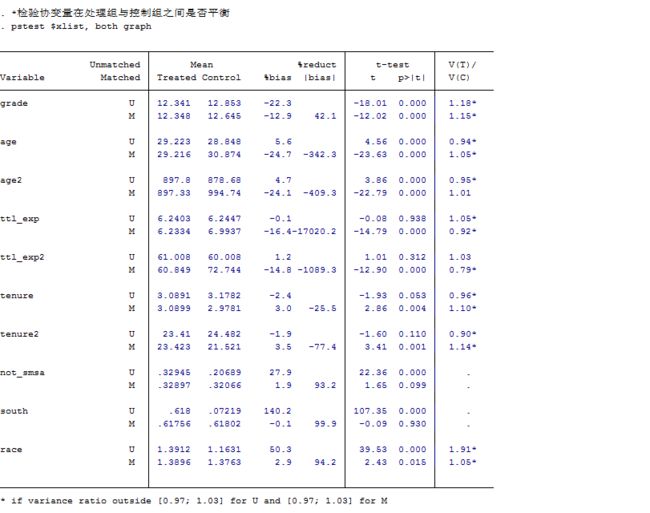
还是以陈强书为例,这张表格,要得到的结果是每个匹配变量在匹配后,各匹配变量的均值不存在显著差异,其标准化误差小于10%,以age为例,5.6就是匹配后样本组与控制组的age的标准化差异,小于10%。只有一个变量u74的标准化误差大于10% ,但是也不大很多,并且只有一个变量,因此这个匹配的平衡性可以接受。平衡性检验了可以在匹配前进行,也可以在匹配后进行,只要检验结果可接受。
PSM的过程在这里就可以结束了,不过有的文章还会用匹配后的数据做个回归,你主分析用的什么回归,这里就用什么回归,只不过样本变了。
匹配后的多元回归,首先要把不参与匹配的样本删除,代码:
drop if _weight==. //_weight是指样本是否参与了匹配,参与了则标为数字,没参与则标为点.,因此这一步是把没参与匹配的样本去掉。
xtset firm year
xtreg Y dv_dum controls, fe r
PSM的使用有一些条件:
1.样本量尽量大,如果样本太小,会导致处理组许多样本在控制组中找不到能匹配的样本,或者能匹配,但是距离很远,也就是控制组的这个样本与处理组的这个样本相对是最匹配的,但是绝对匹配度依然不高。
2.处理组与控制组的倾向得分有较大共同取值范围,否则会丢失较多样本,导致匹配的样本不具备代表性。
需要注意的是,PSM 只能缓解由可观测变量带来的内生性问题,无法处理最为关键的由不可观测变量带来的内生性问题。以上面的例子为例,如果影响企业是否披露R&D投资的因素是不可观测的,那么PSM就不适用了。
参考文献:
Hamilton, B. H., & Nickerson, J. A. (2003). Correcting for endogeneity in strategic management research.Strategic Organization,1(1), 51-78.
Rosenbaum, P. R., & Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects.Biometrika,70(1), 41-55.
PSM原理复习
首先来温习下“倾向值匹配”在说些什么?
使用匹配估计量的条件:假设个体根据可观测变量来选择是否可参与项目
以一个就业培训项目为例,在对项目进行效应评估时,我们除了能观测到人们是否参与了该项目Di和项目实施前后的收入Yi,还可以观测到参与者一些个体特征,比如年龄、受教育程度、肤色、性别等等协变量。
如果个体是否参与项目完全是由某些协变量X决定的,那么我们就可以使用匹配估计方法来估计处理效应。
匹配估计的思想简单易懂:实践中,个体i参与了培训(处理组),这人就不可能再穿越回去选择不参加培训。此时,我们就需要在没有参加培训的人中(控制组)找到某个或某些人j,如何找到这些人呢?
前面说,参与项目Di完全取决于可观测变量Xi,那么自然就是找那些与参与者i有相近X的未参与人j。我们选择到的Xj与Xi越接近,j参与培训的概率就越接近i。那么,我们就可以把j的收入Yj近似当作i在没有参与培训情形下的收入,然后将i的实际收入Yi减去近似收入Yj,得到培训的处理效应,即匹配估计量。
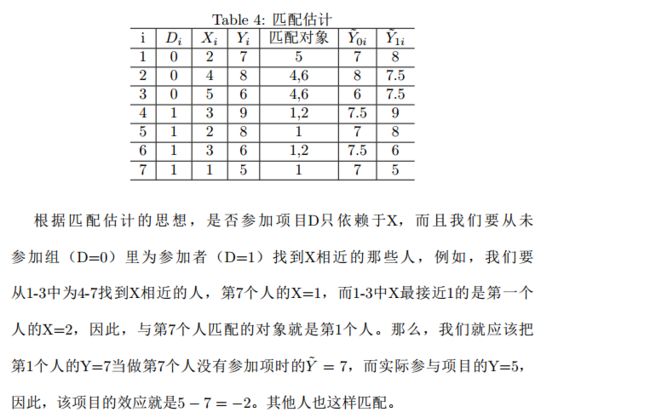
匹配估计

技术细节
一般来说,匹配估计量会存在偏出,因为Xi不可能和Xj完全相同。那么在非精确匹配的情形下:
一对一匹配,偏差较大,方差较小
一对多匹配,偏差较小,方差加大
经验法则:最好进行一堆四匹配,这样能使均方误差MSE最小。

实践
PSM的思想即,将多个X转换成一个指标,即通过某种函数f(X),把多维变量变成一维变量。这个一维变量就是倾向得分。然后,我们就可以根据这个倾向得分进行上述匹配。
PSM计算处理效应的步骤
选择协变量X。尽量将影响D和Y的相关变量都包括在协变量中。如果协变量选择不当或太少,就会引起效应估计偏误;
计算倾向得分,一般用logit回归;
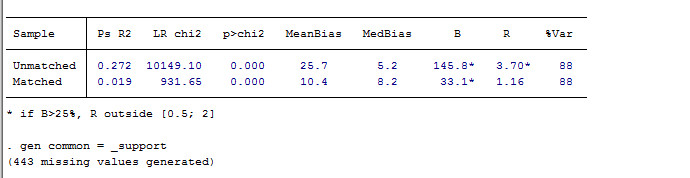
进行倾向得分匹配。如果倾向得分估计较为精确,那么,X在匹配后的处理组和控制组之间均匀分布,这就是数据平衡。那么我们检验得分是否准确就需要计算X中每个分量的“标准化偏差”。经验法则:一般来说,标准化偏差不能超过10%,如果超过10%,就需要返回第2步重新计算,甚至第1步重新选择匹配协变量,或者改变匹配方法。
根据匹配后的样本计算处理效应
在第三部中,得分匹配效果不好,可能要改变匹配方法
k邻近匹配
卡尺匹配或半径匹配
卡尺内最近邻匹配
核匹配
局部线性回归匹配
样条匹配
在实践中,并没有明确的规则来限定使用哪种匹配方法,但有一些经验法则可以来参考:
如果控制个体不多,应选择又放回匹配
如果控制组有较多个体,应选择核匹配
最常用的方法:尝试不同的匹配方法,然后比较它们的结果,结果相似说明很稳健。结果差异较大,就要深挖其中的原因。
但PSM也有局限性:
大样本
要求处理组和控制组有较大的共同取值范围
只控制了可观测的变量,如果存在不可观测的协变量,就会引起“隐性偏差”
PSM实操stata命令
数据准备
*使用美国国家调查数据
webuse nlswork
*设置面板
xtset idcode year
*面板数据描述
xtdes
*生成平方项
gen age2 = age^2
gen ttl_exp2 = ttl_exp^2
gen tenure2 = tenure^2
*定义全局变量
global xlist "grade age age2 ttl_exp ttl_exp2 tenure tenure2 not_smsa south race"
*描述性统计
sum ln_wage $xlist
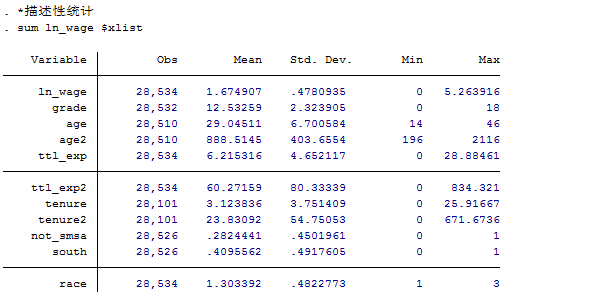
1
*定义种子
set seed 0001
*生成随机数
gen tmp = runiform()
*将数据库随机整理
sort tmp
倾向值匹配
*设置idcode大于2000的地方执行政策
gen treated = (idcode > 2000) &! missing(idcode)
首次使用需要安装外部命令*
ssc install psmatch2,replace
*使用二值选择模型 logit 回归估计倾向值,并基于近邻匹配(默认 K=1)实现一对一匹配;
*其它匹配方法,例如半径匹配、核匹配、样条匹配等,选项格式见psmatch2 命令的帮助文档
psmatch2 treated $xlist,out(ln_wage) logit ate neighbor(1) common caliper(.05) ties
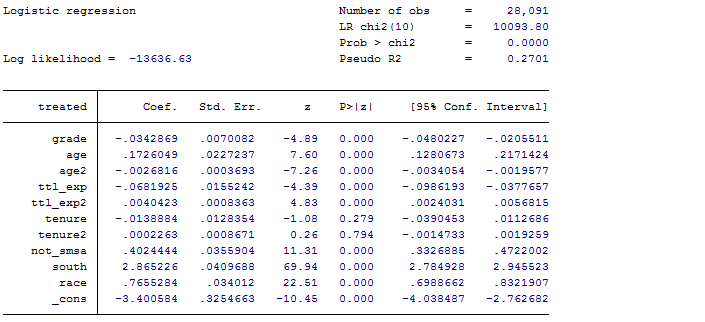
Logit回归结果
模型拟合结果,此处无太多实际意义。
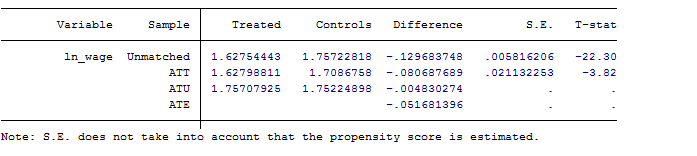
ATT估计值
ATT估计值

观测值是否在共同取值范围中
试验组可匹配的观测概览,按照命令中设定的匹配规则,试验组有22组未能匹配到合适对照。
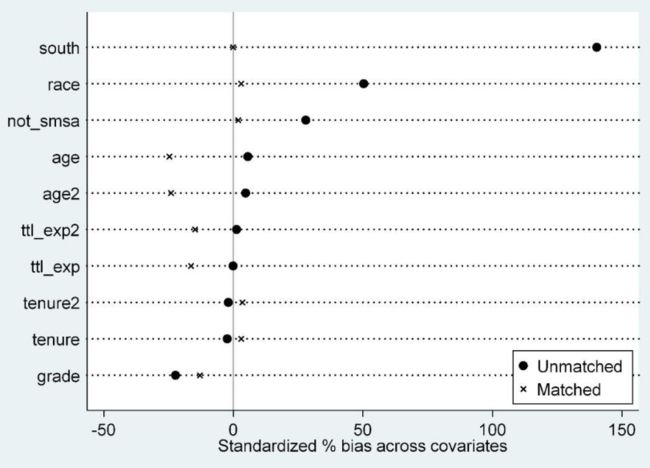
*检验协变量在处理组与控制组之间是否平衡
pstest $xlist, both graph
gen common = _support
2
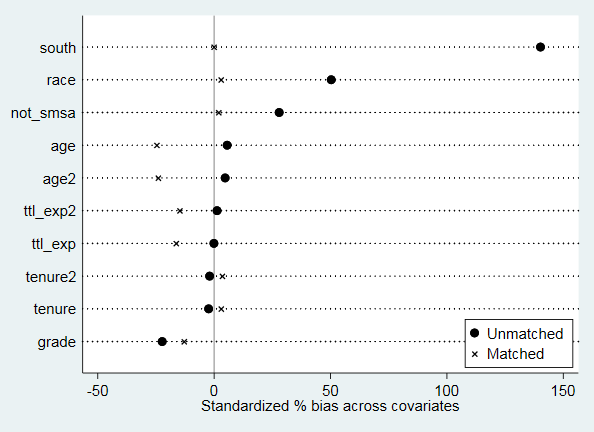
均衡性检验结果
3
4
pstest, both做匹配后均衡性检验,理论上说此处只能对连续变量做均衡性检验,对分类变量的均衡性检验应该重新整理数据后运用χ2检验或者秩和检验。但此处对于分类变量也有一定的参考价值。
*去掉不满足共同区域假定的观测值
drop if common == 0
*绘图显示倾向值的共同取值范围
psgraph
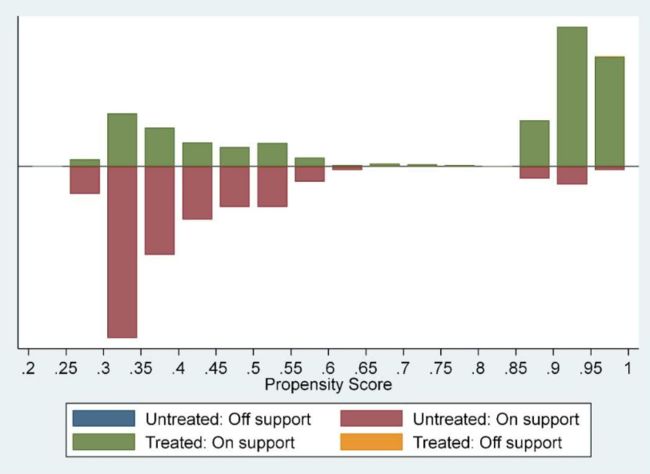
psgraph对匹配的结果进行图示。
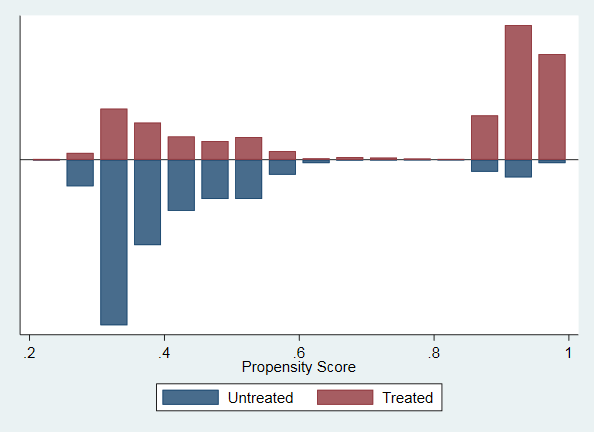
5
匹配结果的图示化
关于PSM语法命令
以下是帮助菜单的中psmatch2语法格式:
psmatch2 depvar [indepvars] [if exp] [in range] [, outcome(varlist) pscore(varname) neighbor(integer) radius caliper(real) mahalanobis(varlist) ai(integer) population altvariance kernel llr kerneltype(type) bwidth(real) spline nknots(integer) common trim(real) noreplacement descending odds index logit ties quietly w(matrix) ate]
简单说就是:psmatch2 因变量 协变量,[选择项]。
以文中为例:
psmatch2 treated $xlist,out(ln_wage) logit ate neighbor(1) common caliper(.05) ties
重点解读命令语句中选择项的含义。本例中选择“nearest neighbor matching within caliper”匹配方法。
out(ln_wage)指明结局变量
logit指定使用logit模型进行拟合,默认的是probit模型
neighbor(1)指定按照1:1进行匹配,如果要按照1:3进行匹配,则设定为neighbor(3)
common强制排除试验组中倾向值大于对照组最大倾向值或低于对照组最小倾向值
caliper(.05)试验组与匹配对照所允许的最大距离为0.05
ties强制当试验组观测有不止一个最优匹配时同时记录
ate 求平均处理效应即求ATT估计值
作者:凡有言说
链接:https://www.jianshu.com/p/216c0beb6fb0
来源:
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
PSM-DID在Stata中的实现过程代码
webuse nlswork //使用系统自带数据库
xtset idcode year, delta(1) //设置面板
xtdescribe //描述一下这个面板数据情况
gen age2= age^2
gen ttl_exp2=ttl_exp^2
gen tenure2=tenure^2
global xlist "grade age age2 ttl_exp ttl_exp2 tenure tenure2 not_smsa south race"
sum ln_w $xlist //统计描述相关变量
——————————————————————
**DID方法
gen time = (year >= 77) & !missing(year) //政策执行时间为1977年
gen treated = (idcode >2000)&!missing(idcode) //政策执行地方为idcode大于2000的地方
gen did = time*treated //这就是需要估计的DID,也就所交叉项
reg ln_w did time treated $xlist //这就是一个OLS回归,也可以用diff命令
xtreg ln_w did time treated $xlist i.year, fe //也可以这去做,会省略掉一个虚拟变量
——————————————————————
**PSM-DID方法
** PSM的部分
set seed 0001 //定义种子
gen tmp = runiform() //生成随机数
sort tmp //把数据库随机整理
psmatch2 treated $xlist, out(ln_w) logit ate neighbor(1) common caliper(.05) ties //通过近邻匹配,这里可以要outcome,也可以不要它
pstest $xlist, both graph //检验协变量在处理组与控制组之间是否平衡
gen common=_support
drop if common == 0 //去掉不满足共同区域假定的观测值
*drop _weight ==0 //也有情况是把没有匹配的直接删除
**DID的部分,根据上面匹配好的数据
reg ln_w did time treated $xlist
xtreg ln_w did time treated $xlist i.year, fe
**PSM-DID部分结束--------------------------------------
————————————————————
**DID方法需要满足的五个条件检验
**1.共同趋势假设检验
tab year, gen(yrdum) //产生year dummy,即每一年一个dummy变量
forval v=1/7
//这个相当于产生了政策实行前的那些年份与处理虚拟变量的交互项
xtreg ln_w did treated* i.year ,fe //这个没有加控制变量
xtreg ln_w did treated* $xlist i.year ,fe //如果did依然显著,且treated*这些政策施行前年份交互项并不显著,那就好
xtreg ln_w did treated* $xlist i.year if union!=1 ,fe //我们认为工会会影响这个处理组和控制组的共同趋势,因此我们看看union=0的情形
**2.政策干预时间的随机性
gen time1 = (year >= 75) & !missing(year) //政策执行时间提前到1975年
gen treated1= (idcode >2000)&!missing(idcode) //政策执行地方为idcode大于2000的地方
gen did1 = time1*treated1 //这就是需要估计的DID,也就所交叉项
gen time2 = (year >= 76) & !missing(year) //政策执行时间提前到1976年
gen treated2= (idcode >2000)&!missing(idcode) //政策执行地方为idcode大于2000的地方
gen did2 = time2*treated2 //这就是需要估计的DID,也就所交叉项
xtreg ln_w did1 $xlist i.year,fe
xtreg ln_w did2 $xlist i.year,fe //看看这两式子里did1和did2显著不
**3.控制组将不受到政策的影响
gen time = (year >= 77) & !missing(year)
gen treated3= (idcode1000)&!missing(idcode) //我们考虑一个并没有受政策影响地方假设其受到政策影响
gen did3 = time*treated3
xtreg ln_w did3 $xlist i.year,fe //最好的情况是did3不显著,证明控制组不受政策影响
**4.政策实施的唯一性,至少证明这个政策才是主要影响因素
gen time = (year >= 77) & !missing(year)
gen treated4= (idcode2300)&!missing(idcode) //我们寻找某些受到其他政策影响的地方
gen did4 = time*treated4
xtreg ln_w did4 $xlist i.year,fe //did4可能依然显著,但是系数变小,证明还受到其他政策影响
**5.控制组和政策影响组的分组是随机的
xi:xtivreg2 ln_w (did=hours tenure) $xlist i.year,fe first
//用工具变量来替代政策变量,解决因为分组非随机导致的内生性问题
—————————————————————
**附加的,一般而言,我们需要看看这个政策的动态影响
forval v=8/15
//注意,这里yrdum8就相当于year=78
reg ln_w treated*
xtreg ln_w treated*, fe
xtreg ln_w treated* i.year,fe
xtreg ln_w treated* $xlist i.year,fe //一般而言上面这些式子里的treated*应该至少部分显著
来源:微信公众号计量经济圈,版权归作者所有
发表于: 2018-11-21
原文链接:https://kuaibao.qq.com/s/20181121B0DH8R00?refer=cp_1026
腾讯「云+社区」是腾讯内容开放平台帐号(企鹅号)传播渠道之一,根据《腾讯内容开放平台服务协议》转载发布内容。
如有侵权,请联系 [email protected] 删除。