这篇博文我们继续去学习开发中经常用到的编码、消息摘要算法和加密算法方面的知识。作为开发者,掌握这些知识可以让我们在设计反爬虫时有更丰富的搭配。而作为爬虫工程师,掌握这些知识可以让我们在面对
奇怪 的字符串时能够更快地找到突破口。在学习和掌握了 js 加密及逆向之后,我们可以处理的爬虫问题如下:
(1) 模拟登录中密码加密和其他请求参数加密处理
(2) 动态加载且加密数据的捕获和破解
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
1. 背景介绍
微信公众平台,简称公众号。曾命名为 官号平台、媒体平台、微信公众号,最终定位为 公众平台,无疑让我们看到一个微信对后续更大的期望。
利用公众账号平台进行自媒体活动,简单来说就是进行一对多的媒体性行为活动,如商家通过申请公众微信服务号通过二次开发展示商家微官网、微会员、微推送、微支付、微活动、微报名、微分享、微名片等,已经形成了一种主流的线上线下微信互动营销方式。本文通过爬虫去模拟微信公众平台的登录。
2. 分析
点击此处进入到微信公众平台的首页面,然后鼠标单击 使用账号登录,如下图所示:

紧接着在账号和密码输入框中输入账号和密码,如下图所示:

在键盘中按下
(这里使用谷歌浏览器),然后在顶部导航条中选择 Network 选项,又由于登录一般都是使用的 ajax 请求,所以接着我们单击下方的
XHR,在这些准备工作都做好之后,我们就可以点击页面中的 登录 按钮,监听请求的 URL,如下图所示。

我们在全局当中对 pwd 进行搜索,发现 pwd 分别包含在 1个 css 文件及1个 js 文件中,经过分析判断,pwd 生成的规则最可能在 js 文件中,如下图所示:

进入到 js 源文件中之后,点击 Pretty-print 或者是 左下角的 {} 进行代码格式化,然后 ctrl + f 再次对 pwd 关键字进行搜索,如下图所示:

如果说鼠标左键单击或者是按住 ctrl + 鼠标左键单击仍然定位不到函数,我们可以采用断点的方式进入,如下图所示:

在这里我们可以定位到密码经过一定格式处理后的返回值,观察发现,返回值中有几个不同的函数,我们可以通过鼠标单击每个函数定位到函数的定义位置,一般来说,使用到的函数,都会在同一个作用域中,即在距离包含该返回值函数的上一层{}
中。找到所有的代码之后,复制到 js 调试工具中,博主在这里使用的是 发条js调试工具V1.9 ,读者可自行在网上搜索下载,如图所示:

加载成功之后,我们去调用函数,输入在网页端输入的密码,看是否能生成对应加密后的字符串,如下图所示:
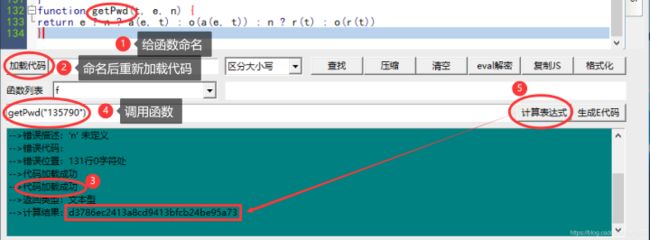
经过和网页端对比发现,两者完全一样。此时我们就完全找到了 js 加密相关的函数。
3. 代码实现
在上面的过程当中,我们找到了所有关于 js 加密的函数,接下来我们的处理方式有 2 种:
(1) 使用 Python 的语法规则去改写所有的 js 加密函数,此种方法要求编码者有足够好的 python 基础,难度较大,不建议使用。
(2) 使用 Python 中的第三方模块去执行我们找到的 js 代码。首先要进行安装:
pip install PyExecJS # 读者可以自行添加镜像源
建议大家在使用这个模块的时候,先安装好 Node.js 环境。提供该模块的学习网址,如下:
https://pypi.org/project/PyExecJS/
博主这里首先将找到的生成密码相关的 js 代码单独放到一个 js 文件中,然后通过 python 读取文件的方法将文件中的 js 代码读取出来,紧接着调用安装好的第三方模块中的方法进行执行。如下图所示:
示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:wechat.py
@time:2020/12/01
"""
import execjs
# node = execjs.get() # 实例化一个对象
ctx = execjs.compile(open("./getPwd.js", "r", encoding="utf8").read()) # 编译
funName = "getPwd({})".format("135790")
pwd = ctx.eval(funName)
print(pwd) # d3786ec2413a8cd9413bfcb24be95a73
程序运行结果如下:
4. 总结
js 调试工具 — 发条 js 调试工具
PyExecJs — 实现使用 python 执行 js 代码 环境安装:
nodejs开发环境
pip install PyExecJS
js 算法改写初探 — 打断点 (代码调试时,如果发现了相关变量的缺失,一般给其定义成空字典即可)
原文地址:Python 爬虫逆向破解案例实战 (一):微信公众平台js逆向改写
至此今天的案例就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习Python基础的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!