姓名:韩宜真
学号:17020120095
转载自:https://mp.weixin.qq.com/s?__biz=MzU5Mjc4MjIzOA==&mid=2247496702&idx=1&sn=bf3937a883a37adb856c47aa1725d2a7&chksm=fe18c50fc96f4c193590858fe7145c5016ee164ecd3a9ba65d03e6133932d8096609f8ddb82a&mpshare=1&scene=23&srcid=1216LHss9wsi3OANLqcdx6h2&sharer_sharetime=1608098272793&sharer_shareid=3f1a3081900d54d7638a82ca5b9e8a0d#rd
【嵌牛导读】本文介绍了用Pytorch实现Transformer一种方法。
【嵌牛鼻子】Transformer 平滑标签
【嵌牛提问】如何用Pytorch实现Transformer?
【嵌牛正文】
01 什么是Transformer?
Transformer最初是由Vaswani等人在一篇名为《Attention is All You Need》的开创性论文中提出。
其主要思想是,它们表明您不必使用循环或卷积层,并且简单的体系结构与注意力结合非常强大。它带来了更好的远程依赖关系建模,并且架构本身是非常可并行的,从而提高了计算效率!
简单架构如图:
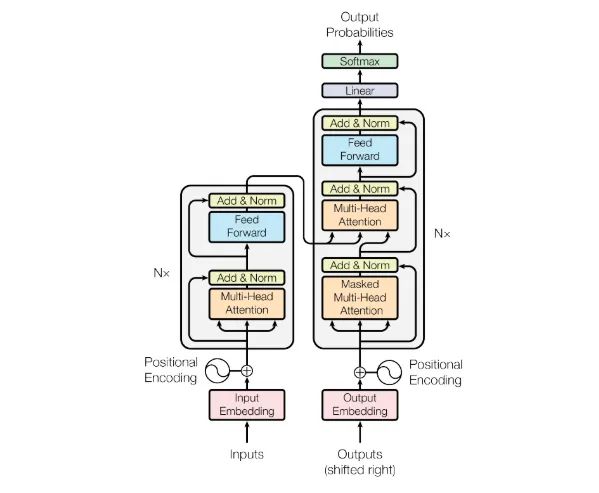
02 理解Transformer
此文发表在Github上,对代码进行了很好的注释,并在playground.py中包括了一些可视化的概念,这些概念很难用单词来解释,但一旦可视化就非常简单。所以我们开始吧!
关注本公众号回复“transformer",获取完整代码。
以下是文章具体内容:
位置编码
一眼就能解析出这个吗?

我也不能。
从playground.py我们运行visualize_positional_encodings()函数可以得到以下信息:
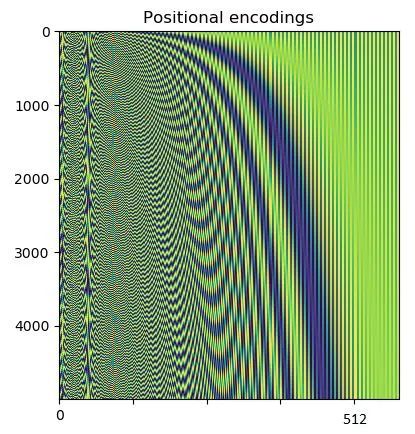
根据源/目标令牌的位置,您“pick one row of this image”,然后将其添加到嵌入向量中,就是这样。
他们也可以被学习,但是这样做显然更花哨!
定制学习率表
同样,您可以解析其中一个O(1)吗?
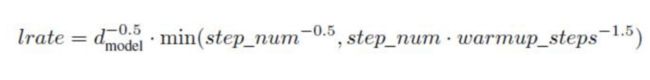
不行吗?所以我想,这里是可视化的:
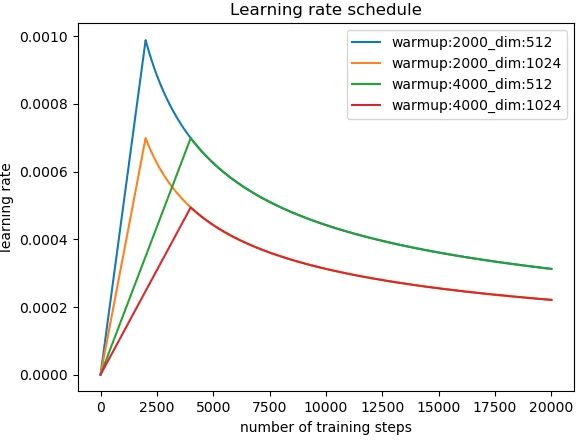
现在超级容易理解。现在,这部分对于Transformer的成功是否至关重要?我对此表示怀疑。但这很酷,并使事情变得更复杂。(.set_sarcasm(True))
标签平滑
第一次听到标签平滑理解起来很困难,但事实并非如此。通常,您将目标词汇分布设置为one-hot。表示30k中的1个位置设置为1,概率设置为0。
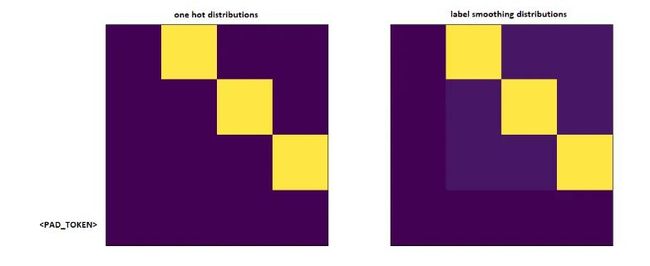
在标签平滑处理中,将0.9放到另一个位置上,而不是在该特定位置上放置1,然后将其余的“概率量”均匀地分布在其他位置上(在上面虚构的vocab中,图像上显示为不同的紫色阴影,大小4-因此是4列)
注意:Pad令牌的分布设置为全零,因为我们不希望模型预测这些零!
03 机器翻译
最初针对WMT-14数据集上的NMT(神经机器翻译)任务对Transformer进行了训练,以用于:
英语到德语的翻译任务(达到28.4 BLEU分数)
英语到法语的翻译任务(达到41.8 BLEU分数)
我现在做的是在IWSLT数据集上训练我的模型,该数据集对于英语-德语语言对来说要小得多,因为我会讲这些语言,因此调试更加容易。
我还将很快在WMT-14上训练我的模型。
讲了什么是Transformer,现在让我们开始运行这个东西!请执行以下步骤:
1.git clone https://github.com/gordicaleksa/pytorch-original-transformer
2.打开Anaconda控制台并导航到项目目录 cd path_to_repo
3.从项目目录运行conda env create(这将创建一个全新的conda环境)。
4.运行activate pytorch-transformer(用于从控制台运行脚本或在IDE中设置解释器)
就这些而已!它应该可以开箱即用地执行environment.yml文件来处理依赖项。我可能会花一些时间,因为我会自动下载英语和德语的SpaCy统计模型。
PyTorch pip软件包将与某些版本的CUDA / cuDNN捆绑在一起,但是强烈建议您事先安装系统范围的CUDA,主要是因为GPU驱动程序。我还建议使用Miniconda安装程序作为在系统上获取conda的方法。
04 用法
训练
要进行训练,请从开始training_script.py,这里有几个设置需要指定:
--batch_size
-这对于将最大值设置为不会导致CUDA内存不足的最大值很重要
--dataset_name
-在IWSLT和WMT14之间选择(在添加多GPU支持之前,不建议WMT14 )
--language_direction
-在E2G和G2E之间选择
因此(从控制台)运行的示例如下所示:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
该代码的注释很好,因此您可以了解训练本身的工作方式。
该脚本将:
将检查点* .pth模型转储到 models/checkpoints/
将最终的* .pth模型转储到 models/binaries/
下载IWSLT / WMT-14(首次运行并将其放在data/下)
将tensorboard数据转储到runs/中,只需从Anaconda运行tensorboard --logdir=runs
定期将一些训练元数据写入控制台
注意:torch text中的数据加载速度很慢,因此我实现了一个自定义包装器,该包装器添加了缓存机制,并使处理速度提高了约30倍!(第一次运行东西会很慢)
推论(翻译)
第二部分是关于使用模型并查看它们如何转换的全部内容!要获得一些翻译,请启动translation_script.py,您需要设置一些设置:
--source_sentence
-根据您指定的型号,该名称应为英语/德语句子
--model_name
-预训练的模型名称之一:iwslt_e2g,iwslt_g2e或模型(*)
--dataset_name
-IWSLT如果模型是在IWSLT上训练的,则使其与模型保持同步
--language_direction
-如果模型经过训练可以将英语翻译成德语,请保持E2G同步
注意:训练模型后,会将其转储到其中,以models/binaries查看其名称,--model_name如果要出于转换目的使用它,则可以通过参数指定它。如果您指定了一些预训练的模型,则在您第一次运行翻译脚本时会自动下载它们。
评估NMT模型
训练时我追踪了3条曲线:
训练损失(KL偏差,批量平均值)
验证损失(KL差异,批量均值)
BLEU-4
BLEU是基于n-gram的度量标准,用于定量评估机器翻译模型的质量。我使用了很棒的nltkPython模块提供的BLEU-4指标。
目前的结果是,对模型进行了20个时期的训练(DE代表Deutch,即德语):
模型BLEU分数数据集
27.8IWSLT值
33.2IWSLT值
Baseline Transformer(EN-DE)XWMT-14 VAL
Baseline Transformer(DE-EN)XWMT-14 VAL
我使用贪心解码得到了这些,所以这是一个悲观的估计。
重要说明:初始化对于变压器非常重要!最初,我认为使用Xavier初始化的其他实现又是那些任意启发式方法之一,并且PyTorch默认初始化将起作用-我错了:
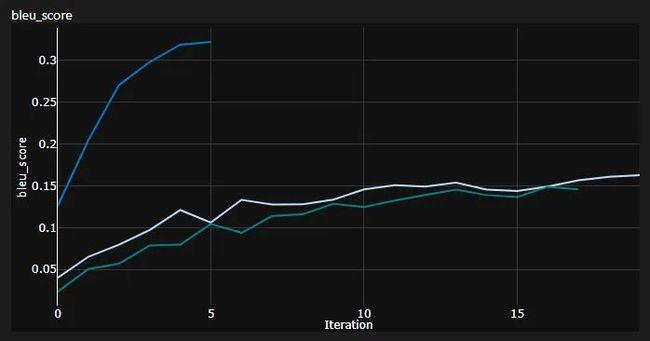
您可以在这里看到3次运行,其中较低的2次使用PyTorch默认初始化(一次用于meanKL散度损失,更好的一次使用batchmean),而较高的一次使用Xavier统一初始化!
想法:您可能还可能会定期转储翻译,以供参考句子的源句子使用。这将使您对Transformer的运行情况有定性的了解,尽管我没有这样做。当您像GAN和NST领域那样难以定量评估模型时,也会执行类似的操作。
使用Tensorboard进行跟踪
上图是我的Azure ML运行的一个片段,但是当我在本地运行东西时,我使用Tensorboard。
只需tensorboard --logdir=runs从Anaconda控制台运行,您就可以在训练期间跟踪指标。
可视化注意力
您可以使用translation_script.py并将其设置--visualize_attention为True,以进一步了解源句和目标句中模型“paying attention to”的内容。
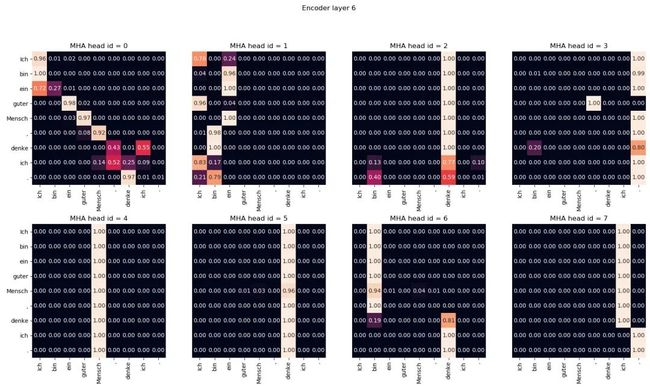
这是我对输入句子的注意力 Ich bin ein guter Mensch, denke ich.
这些属于编码器的第6层。您可以看到所有8个多头注意力头。
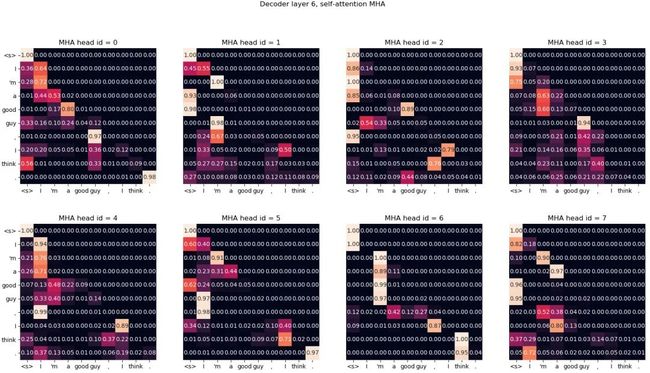
这个属于自动注意力解码器MHA(多头注意力)模块的解码器第6层。您会注意到一个有趣的三角形图案,它来自目标令牌不能向前看的事实!
MHA模块的第三种类型是源代码,它看起来与您看到的编码器图相似。随意按照自己的节奏玩!
注意:此模型显然存在一些偏差问题,但在这里我不会进行分析