本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于青灯编程 ,作者:清风
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
基本开发环境
- Python 3.6
- Pycharm
相关模块使用
- 爬虫模块
import requests
import re
import parsel
import csv
- 词云模块
import jieba
import wordcloud
目标网页分析

通过开发者工具可以看到,获取返回数据之后,数据是
在 window.SEARCH_RESULT 里面,可以使用正则匹配数据。
如下图所示
'https://jobs.51job.com/beijing-ftq/127676506.html?s=01&t=0'
每一个招聘信息的详情页都是有对应的ID,只需要正则匹配提取ID值,通过拼接URL,然后再去招聘详情页提取招聘数据即可。
response = requests.get(url=url, headers=headers)
lis = re.findall('"jobid":"(\d+)"', response.text)
for li in lis:
page_url = 'https://jobs.51job.com/beijing-hdq/{}.html?s=01&t=0'.format(li)

虽然网站是静态网页,但是网页编码是乱码,在爬取的过程中需要转码。
f = open('招聘.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '地区', '工作经验', '学历', '薪资', '福利', '招聘人数', '发布日期'])
csv_writer.writeheader()
response = requests.get(url=page_url, headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
title = selector.css('.cn h1::text').get() # 标题
salary = selector.css('div.cn strong::text').get() # 薪资
welfare = selector.css('.jtag div.t1 span::text').getall() # 福利
welfare_info = '|'.join(welfare)
data_info = selector.css('.cn p.msg.ltype::attr(title)').get().split(' | ')
area = data_info[0] # 地区
work_experience = data_info[1] # 工作经验
educational_background = data_info[2] # 学历
number_of_people = data_info[3] # 招聘人数
release_date = data_info[-1].replace('发布', '') # 发布日期
all_info_list = selector.css('div.tCompany_main > div:nth-child(1) > div p span::text').getall()
all_info = '\n'.join(all_info_list)
dit = {
'标题': title,
'地区': area,
'工作经验': work_experience,
'学历': educational_background,
'薪资': salary,
'福利': welfare_info,
'招聘人数': number_of_people,
'发布日期': release_date,
}
csv_writer.writerow(dit)
with open('招聘信息.txt', mode='a', encoding='utf-8') as f:
f.write(all_info)


以上步骤即可完成关于招聘的相关数据爬取。
简单粗略的数据清洗
- 薪资待遇
content = pd.read_csv(r'D:\python\demo\数据分析\招聘\招聘.csv', encoding='utf-8')
salary = content['薪资']
salary_1 = salary[salary.notnull()]
salary_count = pd.value_counts(salary_1)
- 学历要求
content = pd.read_csv(r'D:\python\demo\数据分析\招聘\招聘.csv', encoding='utf-8')
educational_background = content['学历']
educational_background_1 = educational_background[educational_background.notnull()]
educational_background_count = pd.value_counts(educational_background_1).head()
print(educational_background_count)
bar = Bar()
bar.add_xaxis(educational_background_count.index.tolist())
bar.add_yaxis("学历", educational_background_count.values.tolist())
bar.render('bar.html')
显示招聘人数为无要求
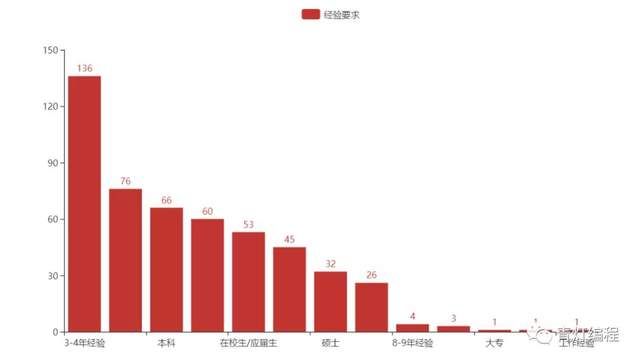
- 工作经验
content = pd.read_csv(r'D:\python\demo\数据分析\招聘\招聘.csv', encoding='utf-8')
work_experience = content['工作经验']
work_experience_count = pd.value_counts(work_experience)
print(work_experience_count)
bar = Bar()
bar.add_xaxis(work_experience_count.index.tolist())
bar.add_yaxis("经验要求", work_experience_count.values.tolist())
bar.render('bar.html')
词云分析,技术点要求
py = imageio.imread("python.png")
f = open('python招聘信息.txt', encoding='utf-8')
re_txt = f.read()
result = re.findall(r'[a-zA-Z]+', re_txt)
txt = ' '.join(result)
# jiabe 分词 分割词汇
txt_list = jieba.lcut(txt)
string = ' '.join(txt_list)
# 词云图设置
wc = wordcloud.WordCloud(
width=1000, # 图片的宽
height=700, # 图片的高
background_color='white', # 图片背景颜色
font_path='msyh.ttc', # 词云字体
mask=py, # 所使用的词云图片
scale=15,
stopwords={' '},
# contour_width=5,
# contour_color='red' # 轮廓颜色
)
# 给词云输入文字
wc.generate(string)
# 词云图保存图片地址
wc.to_file(r'python招聘信息.png')

总结:
数据分析是真的粗糙,属实辣眼睛~