NTU自2014年就设立“数据管理馆员”一职,跟踪数据管理领域的进展。
2016年4月,SCG联合NTU的行政部门出台“研究数据管理政策”。SCG为此编写了“NTU研究数据管理模板”,设计了十个问题供老师填写,每个问题后面都有指南和样本,并嵌入NTU的科研管理平台RIMS,指导教师在线填写。
除此之外,SCG每月举行一次Data Management Workshop,手把手教老师和研究生如何撰写项目的数据管理计划。SCG在2016年去北大和哈佛大学考察,最终确定Dataverse为数据管理的平台,计划明年初正式推出。
这段时间留在SCG,空闲的时间就当个小白鼠,测试一下Dataverse平台。伟耀老师向我详细介绍了Dataverse的结构:典型的套娃结构,很好理解。

数据结构总共分三层:Dataverse(北大翻译成“数据空间”)、Dataset(数据集)和File(文档)。Dataverse下面可以套好多层的Dataverse,无限延展下去。最小的那个套娃就是Dataset数据集,数据集就是由很多种格式的File组成。Dataverse可以是个人主页、研究小组、研究项目。
页面呈现也非常简洁。进入NTU的Dataverse就可以看到该机构highlight的几个Dataverse,比如3D Printers Dataverse, Photography and Design Dataverse, Nanyang University Graduates Name List Dataverse等(我建议正式推出后,可以根据下载量展示项目。当然,也可以根据机构的需要highlight某几个项目)。左上角是该机构所有的Dataverse被下载的总次数。左边的分面浏览部分有Dataverse、Datasets和Files的总数。勾选后,右侧页面就会呈现出相应类别的内容列表。
特别神奇的是,我的电脑里大部分文字是中文,而伟耀老师的界面全是英文。不知道这部分是不是Dataverse做的汉化,然后根据电脑系统自动给出不同语言的界面。
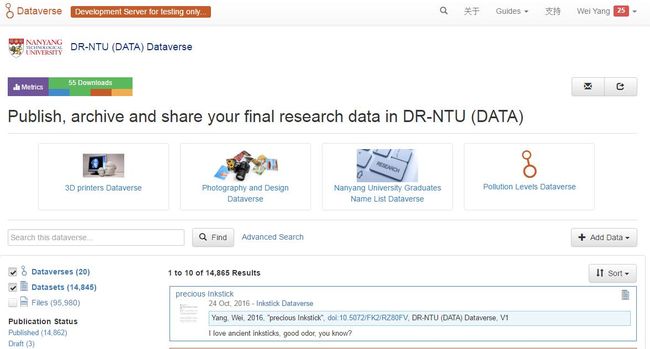
左侧分面浏览的参数是可以设定的,比如出版状态、数据空间的种类(研究项目、课题组、研究者、组织或机构)、元数据来源(从外部收割来的,还是NTU本身的,或从IR收割来的)、出版时间、作者姓名、学科、关键词、存储日期、主题分类等。师生可以自己勾选想要的参数,如果不想看那么多参数,就用系统默认参数即可。
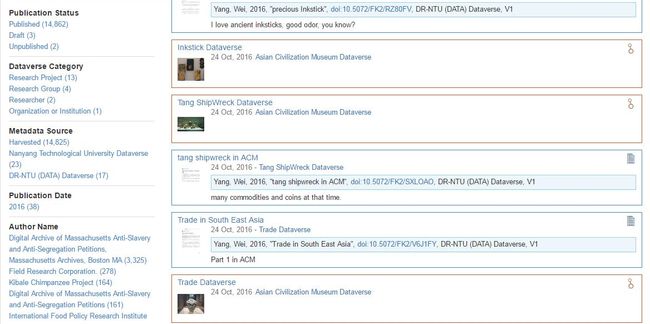

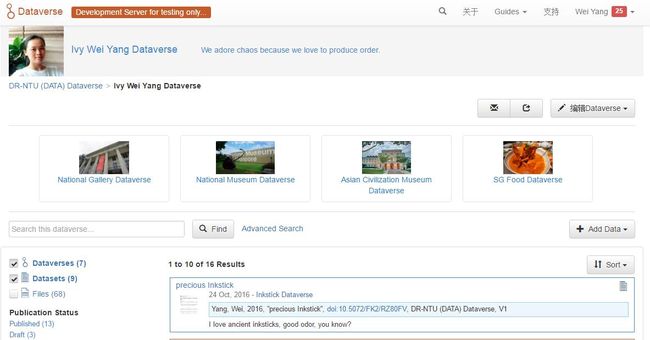
我注册后,在总的NTU Dataverse下建立了自己的Dataverse,叫Ivy Wei Yang Dataverse。这就是教师的研究数据总库了。然后我打算根据不同的研究项目建立单独的Dataverse,于是,在Ivy Wei Yang Dataverse下分别建立了National Gallery Dataverse, National Museum Dataverse, Asian Civilization Museum Dataverse和SG Food Dataverse四个数据空间。
数据空间的首页图片在页面右侧“编辑Dataverse”中的“主题+小工具”里添加。
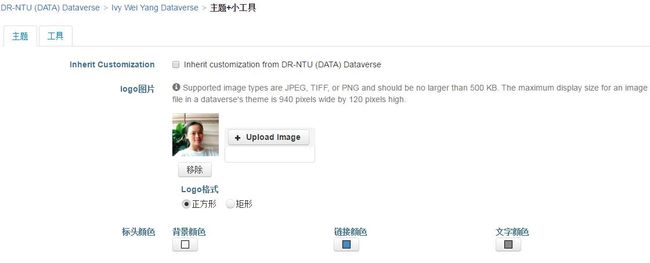
可以为你的主页设计一个标语,以及该标语的链接,我选择连到了自己的ORCID。
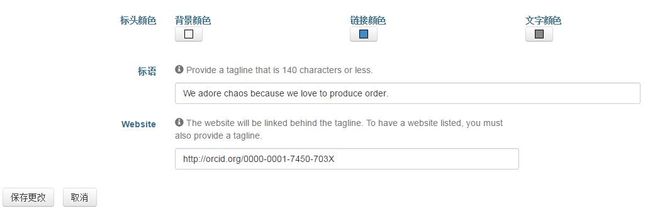
下面的四个Dataverse则在“编辑Dataverse”中的“特色Dataverse”中勾选需要显示的Dataverse。

为了测试Dataverse的套娃结构,我又选择Asian Civilization Museum Dataverse建立了三个Sub Dataverse,分别为Trade Dataverse, Tang Shipwreck Dataverse和Inkstick Dataverse。
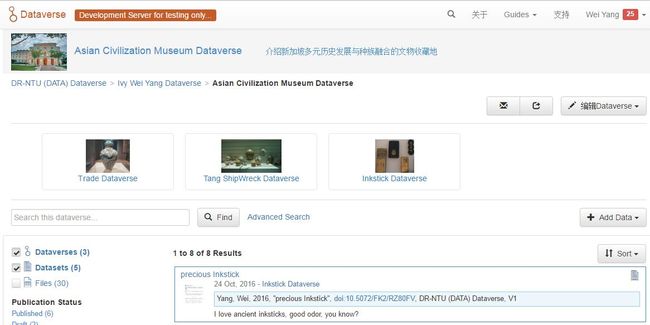
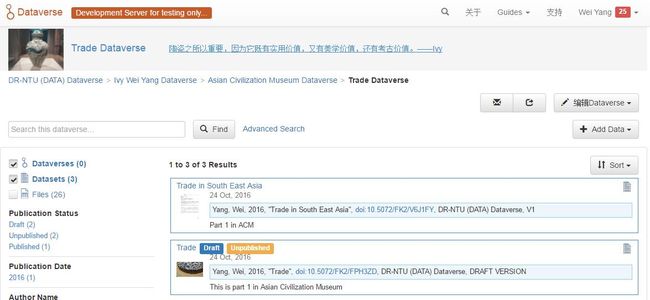
Trade Dataverse上的slogan是我最近的逛展心得:陶瓷之所以重要,因为它既有实用价值,又有美学价值,还有考古价值。然后很臭美的冠名——Ivy。
在Trade Dataverse的Banner下面,已经清楚地展示出了我所建立的四层结构:第一层为NTU总Dataverse,第二层为我的Dataverse,第三层为Asian Civilization Museum的Dataverse,第四层为Trade Dataverse。这样下去可以套无数个Dataverse。就此打住,我在Trade Dataverse下直接建立了Dataset,取名“Trade in South East Aisa”,该数据集下有三个Files。
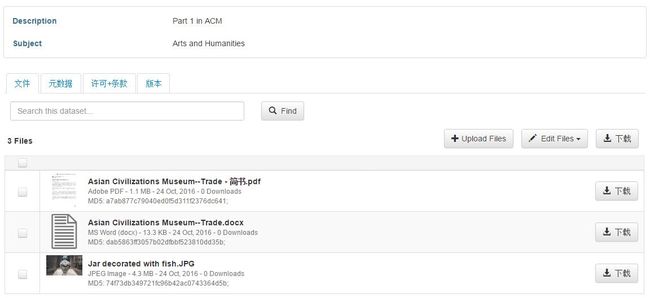
每个File下面都可以写描述性文字,还可以加标签。在上传files的过程中,就可以直接加description和tags了。但一个个输入description和tag真的很麻烦,我后来发现,先把所有files上传之后,点击多选files,然后在Edit Files下批量加tags非常方便,批量Restrict,批量Delete都很方便。
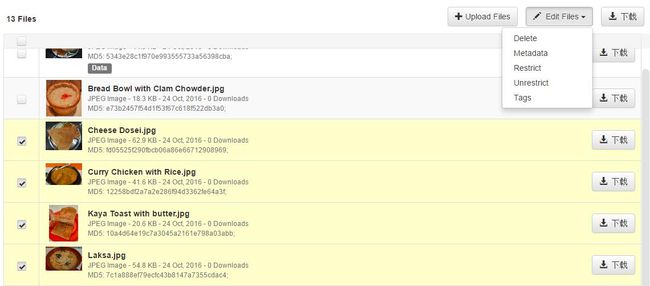
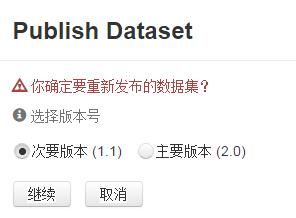
修改完数据后,如果不发布,就保存为草稿。如果发布,系统会自动根据修改的量来确定是Version 1.1呢还是Version 2.0。如果新增或删除files,就是大修改,系统会自动发布成Version 2.0,如果修改个tag或权限,则是小修改,系统会询问你是选择小修改呢Version1.1还是大修改Version 2.0.
如果你上传的文档不是像word,excel,pdf,jpeg那样的通用文档,最好写个说明,也就是Documentation,告诉使用数据的人,如何读取你的数据。比如我从有道云笔记中导出了一个.ynt的文件,不熟悉的人并不知知道该如何读取。于是我在files里加了一个Documentation.txt的说明文档,并tag为Documentation。我的Documentation很简单,就写了一句话:The file type of .ynt can be viewed by the software of Youdao Note(有道云笔记)which can be downloaded from: https://note.youdao.com/。所以,数据管理这种看起来超级高大上、无法仰视、无法企及的东西,操作起来并不困难。很多困难都是纸老虎paper tiger,自己设置的心理障碍比困难本身更难以逾越。
我可以把自己的files设为不公开,并设定如果别人要下载我的非公开数据需要提供什么信息。像我这么nice的人一般只要求别人陈述下载原因,所以我自己设计的表格就需要别人提供:姓名、电邮、机构、职位(这四个一般系统默认),再加上“Please specify your reason”,这是我自己写的。访问者填写好这些信息后就可以直接下载了,不需要我同意。因为Dataverse本来就是鼓励公开的。
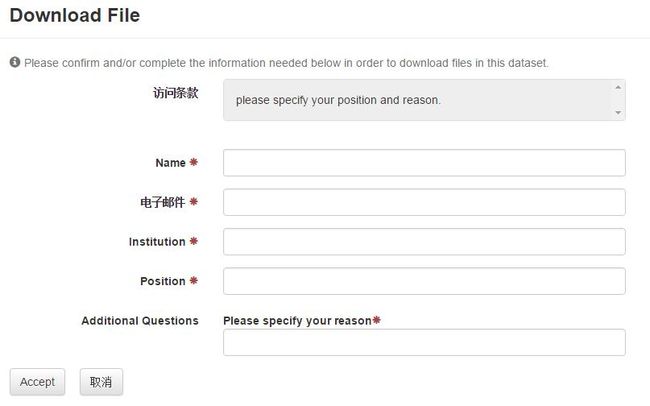
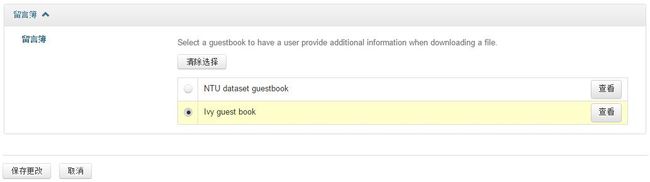
我刚才用的是Guest book的目的就是设定读者在下载我的数据时,需要提供什么信息。上周五我测试时,伟耀需要先向我提交请求,我grant之后,他在下载前才需要填这个guest book,但今天发现是先填guest book然后就可以直接下载了,不需要我grant,看来Venki可能在设置上做了些改动。
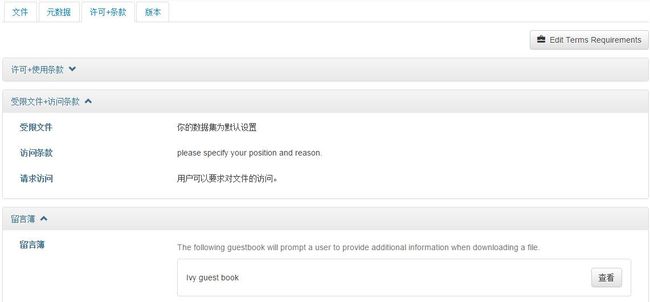
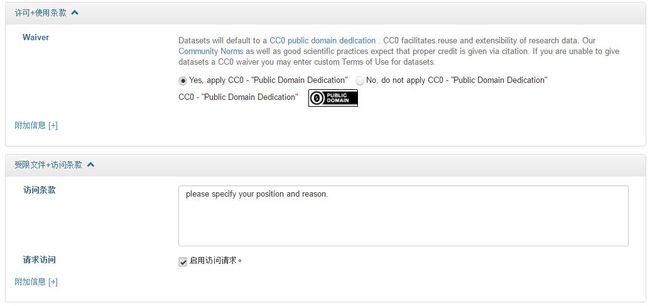
选中数据后,点击“许可+条款”就可以设置了。下图是我设好的,可以点击“Edit Terms Requirements”重新设定。
使用条款一般是默认CC0,也就是署名+非商业用途,当然,也可以自己设计使用条款。比如保密声明、特殊权限、引文要求、存放要求、放弃权利等。
可以设置访问条款。比如告诉读者,我的数据为什么不能够下载,或下载后要怎么合理使用等。也可以详细设置访问地点、原始存档、可用状态等信息。
可以选择NTU默认的guest book,也可以设置自己的Ivy guest book。
只有两个层级的Dataverse会显示下载记录,一个是NTU总的Dataverse,显示的是总下载量。还有一个就是你自己的Dataverse总最底层的那个Dataverse。比如我的下载次数并不显示在Ivy Wei Yang Dataverse这一层,而是显示在National Gallery Dataverse这一层。因为这个dataverse以下就没有sub dataverse了,而是数据集dataset了。
我觉得这样有点不太合理。作为一个研究者,我当然希望看到自己的每个研究项目被下载了多少次,也希望看到自己的所有研究项目被下载的总次数。所以如果能在第二层Dataverse,也就是Ivy Wei Yang Dataverse那个地方显示我四个子项目的总下载次数是最好的。最好首页还能有个排行榜,列出Top 10的研究团队的下载次数。

以上就是我使用Dataverse的心得。
其实做数据管理最大的难处,就是让老师们理解规范数据的好处。像我这样写个blog的行为就是在做数据存档了,也相当于为自己的数据做个Documentation。以后有人要学Dataverse时,可以参考我这篇一步步做下去。但,我写篇blog需要花上一两个小时,需要梳理思路、需要重新截图、需要整理文字。这就是routine work之外的工作了。如何让老师了解到:花一两个小时或更多的时间来整理和存档数据是相当有意义的、投资回报率高的行为,这是一个困难且长期的工作。就像我写完这篇blog,也不知道这些文字将来能为我省下多少时间。
还有很大的一块没有测试,就是研究组各成员之间的权限分配、互动,以及研究人员离开后,之前的编辑历史是否能有效保存下来,都还没有测试。