论文原文:

论文地址:https://arxiv.org/abs/1804.07931
论文题目:《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate 》
一 、背景
在广告领域里面有几个名字先解释一下:
impression:用户观察到曝光的产品
click:用户对impression的点击行为
conversion:用户点击之后对物品的购买行为
CTR:从impression到click的比例
CVR:从click到conversion的比例
CTCVR:从impression到conversion的比例
pCTR:p(click=1 | impression)
pCVR: p(conversion=1 | click=1, impression)
pCTCVR: p(conversion=1, click=1 |impression) = p(click=1 | impression) * p(conversion=1|click=1,impression)
在前面的文章里面主要介绍对CTR的预估,这篇文章主要介绍阿里巴巴怎么通过多任务学习模型将ctr预估和cvr预估结合起来。
在推荐和广告等工业应用中的排序系统,准确估算点击后转化率(CVR)至关重要,常规的CVR建模应用了流行的深度学习方法,并实现了最新的性能。但是,它在实践中遇到了几个特定于任务的问题,这使CVR建模具有挑战性。例如,传统的CVR模型是使用点击曝光的样本进行训练的,同时利用所有曝光的样本对整个空间进行推断。这导致样本选择偏差问题。此外,还有一个极端的数据稀疏性问题,使得模型拟合相当困难。
以电子商务平台为例,用户的购买行为一般遵循以下的顺序决策模式:impression-click-conversion,即用户先观察到系统推荐的产品,然后会对自己感兴趣的商品进行点击,进而产生购买行为。从点击到购买的转化我们称为post-click Conversion rate(以下简称CVR),CVR的预估在信息检索、推荐系统、在线广告投放等工业级应用中是至关重要的。这个毕竟是关乎的部门的营收状况。
上面提到了数据稀疏和样本选择偏差的问题,可以用下面的图进行解释:

我们把给用户曝光过的物品看作是整个样本空间X的话,用户点击过的产品仅是中间灰色的部分,我们定义为Xc,而用户购买过的产品仅是图中黑色的部分。
样本选择偏差(sample selection bias,SSB):传统的推荐系统仅用Xc中的样本来训练CVR预估模型,但训练好的模型是在整个样本空间X去做推断的。由于点击事件相对于曝光事件来说要少很多,因此只是样本空间X的一个很小的子集,从Xc上提取的特征相对于从X中提取的特征而言是有偏的,甚至是很不相同。在机器学习中,我们知道训练集的样本跟测试集的样本要服从同一个分布,否则训练出来的模型会有很大的偏差,使得模型的泛化性能很差。这种训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。
数据稀疏(data sparsity,DS): 推荐系统展现给用户的商品数量要远远大于被用户点击的商品数量,同时有点击行为的用户也仅仅只占所有用户的一小部分,因此有点击行为的样本空间Xc相对于整个样本空间X来说是很小的,通常来讲,量级要少1~3个数量级。这就是所谓的训练数据稀疏的问题,高度稀疏的训练数据使得模型的学习变得相当困难。
为了解决上面的两个问题,阿里巴巴提出了多任务模型ESMM。
二、ESMM模型结构和训练
2.1 模型总览
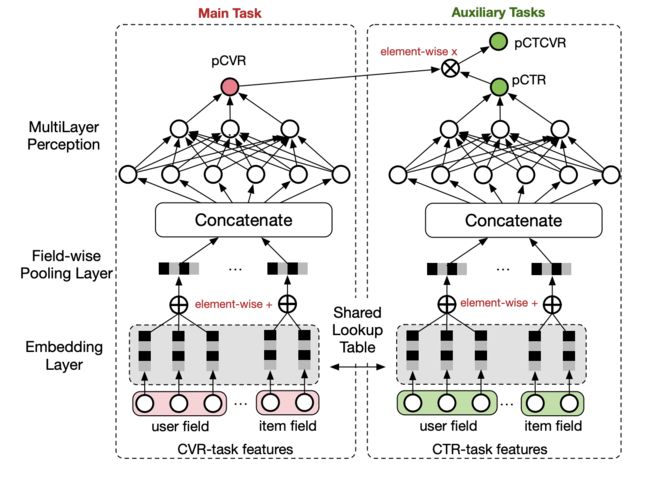
可以从上面的图简单的看出这个多任务模型中的两个子任务分别是pCTCVR和pCTR的预估,而整个模型预估的是pCVR,在文章的开篇已经说了这三个指标的计算关系了:
pCTCVR: p(conversion=1, click=1 |impression) = p(click=1 | impression) * p(conversion=1|click=1,impression)
假设我们用x表示feature(即impression),y表示点击,z表示转化,那么根据pCTCVR = pCTR * pCVR,可以得到:

虽然我们子任务模型预估的是pCTCVR,但是我们实际上要的是pCVR,有了上面这个公式,我们就可以求得pCVR了:

2.2 多任务模型的训练集
我们先看pCTR这个子任务,由于ctr预估的是从impression到click的概率,所以我们可以将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本,来做CTR预估的任务。
然后看pCTCVR这个任务,我们将有点击行为和购买行为的曝光事件作为正样本,其他作为负样本来训练CTCVR的预估部分。
可以看到,训练两个子任务的输入x是相同的,但是label是不同的。CTR任务预估的是点击y,CTCVR预估的是转化z。因此,我们将(x,y)输入到CTR任务中,得到CTR的预估值,将(x,z)输入到CVR任务中,得到CVR的预估值,CTR和CVR的预估值相乘,便得到了CTCVR的预估值。因此,模型的损失函数可以定义为:

这就是ESMM的第一个特点:在整个样本空间里面建模
由上面提到的等式可以看出,pCVR是可以通过pCTR和pCTCVR的预估推导出来的。因此,模型只需要关注pCTR和pCTCVR两个子任务即可。这也就消除了样本选择偏差,因为CVR是从click到conversion,而CTCVR是从impression到conversion,CTR是从impression到click,所以CTR和CTCVR都可以从整个样本空间进行训练,一定程度上消除了样本选择偏差。
ESMM还有另一个特点:权值共享
我们在看看ESMM的模型结构,我们可以看到上面的模型结构图里面有这样一个描述:share lookup table,什么是lookup table呢,就是embedding矩阵嘛其实,所以这两部分是共享Embedding的,这不仅降低的模型的规模,还让模型对特征的embedding进行充分的学习。
网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
三、实验结果
3.1 公开数据集的实验结果

可以看到模型的离线AUC得到了一定的提升,上面的对比模型分别是:
base:ESMM左边的那个子模型
division: 分别训练ctr 和 ctcvr两个模型,用两个相除的结果作为cvr
ESMM-NS: 就是not share的embedding的意思
ESMM: 完整的模型
3.2 淘宝生产环境数据集的实验结果
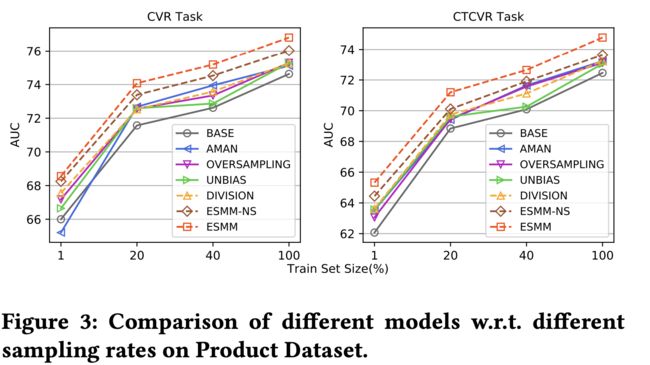
可以看到在生产环境中,ESMM在减缓了数据稀疏和样本偏差问题后,AUC较其他模型有很大的增长。