本文将从以下几个方面介绍单点登录问题,和单点登录的解决方案:
- http 协议的特性
- 集群环境下的 session 共享问题
- 关于负载均衡算法分析
- session 共享问题的解决办法
http 协议
无状态性
Http 协议本身是无状态的,客户端只需简单的向服务器发送请求,获取结果。无论是客户端还是服务器都没必要记录彼此过去的行为,每一次请求之间都是独立的。
然而我们发现如果能够提供一些按照需要生成的动态信息会使web访问变得更加便捷。比如我们做了一个需要登录授权才能执行的动作,但是因为 http 协议没办法保存这个登录的用户的状态,因此当下一次再执行一个需要授权操作时,还需要再次登录,这将导致用户体验非常差。因此需要一种能够识别每次用户的请求的机制,来实现会话保存的目的。
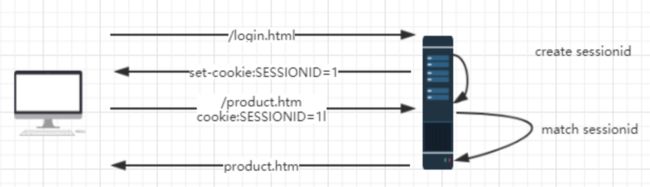
Session
服务端提供了一种叫 Session 的机制,对于每个用户的请求,会生成一个唯一的标识。当程序需要为某个客户端的请求创建一个 session 的时候,服务器首先检查这个客户端的请求是否包含了一个 session 标识(session id)。如果已包含一个 session id 则说明以前已经为客户端创建过 session,服务器就按照 session id 把这个 session 检索出来使用。
如果客户端请求不包含 session id,则为此客户端创建一个session 并且生成一个与此 session 相关联的 session id,session id 的值是一个既不会重复,又不容易被找到规律的字符串。
Cookie
浏览器提供了一种叫 cookie 的机制,保存当前会话的唯一标识。每次 HTTP 请求,客户端都会发送相应的 cookie 信息到服务端。客户端第一次请求,由于 cookie 中并没有携带 session id,服务端会创建一个session id,并写入到客户端的 cookie 中。以后每次请求,客户端都会携带这个 id 发给服务器端。这样一来,便解决了无状态的问题。
集群环境下的 session 共享问题
如果网站请求流量较大,那么单台服务器是无法承接这些流量的,这个时候就需要开始对服务器做集群。
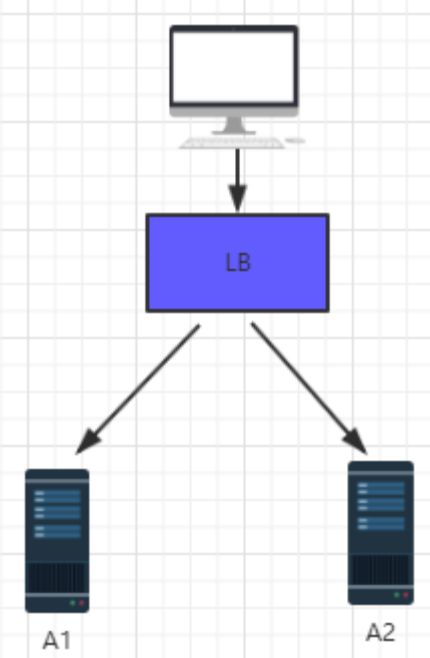
采用了多台机器做集群以后,就势必要通过一种机制来实现请求的路由。因为对于用户来说,访问的是一个域名,至于后端应该请求到哪一台,用户并不需要关心,所以这里会使用负载均衡设备。
关于负载均衡
负载均衡的主要目的是:把用户的请求分发到多台后端的设备上,用以均衡服务器的负载。我们可以把负载均衡器划分为两大类:硬件负载均衡器和软件负载均衡器。
硬件负载
最常用的硬件负载设备有 F5 和 netscaler、redware。其中F5是基于4层负载,netscaler是7层负载。所谓的四到七层负载均衡,就是在对后台的服务器进行负载均衡时,依据四层的信息或七层的信息来决定怎么样转发流量。
四层的负载均衡,就是通过发布三层的 IP 地址,然后加四层的端口号,来决定哪些流量需要做负载均衡,转发至后台服务器,并记录下这个 TCP 或者 UDP 的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理。同理,还有基于MAC地址的二层负载均衡和基于IP地址的三层负载均衡。
七层的负载均衡,就是在四层的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个 Web 服务器的负载均衡,除了根据IP加端口辨别是否需要处理的流量,还可根据七层的 URL、浏览器类别、语言等信息来决定是否要进行负载均衡。举个例子,如果你的 Web 服务器分成两组,一组是中文语言的,一组是英文语言的,那么七层负载均衡就可以当用户来访问你的域名时,自动辨别用户语言,然后选择对应的语言服务器组进行负载均衡处理。
硬件负载均衡设备的优点是稳定性高、同时有专门的技术服务团队支撑。但是价格比较贵,一般的都要几十万起。对于一些大的企业,如果没有专业的运维团队,可以采用这种方式。
软件负载
比较主流的开源软件负载技术有: lvs、HAProxy、Nginx 等。对于小公司来说或者大型的互联网企业,基本都采用软件负载均衡技术来实现流量均衡。不同的负载均衡技术有不同的特点,比如 LVS 是基于 4 层的负载负载技术,抗负载能力比较强。HAProxy 和 Nginx 是基于 7 层的负载均衡技术,可以根据请求的 url 进行分流。
负载均衡算法
引入负载均衡器以后,就需要负载均衡算法对请求进行转发,常见的负载均衡算法有以下几种:
轮询算法及加权轮询算法
轮询算法是指负载均衡服务器将客户端请求按顺序轮流分配到后端服务器上,以达到负载均衡的目的。由于后端服务器的性能差异,可以对处理能力较好的服务器增加权重。这样,性能好的服务器能处理更多的任务,性能较差的服务器处理较少的任务。
最小连接数
由于不同的客户端请求的操作对于后端来说复杂度是不同的,也就会导致服务端的处理时间不一样。最小连接数算法根据后端服务器当前的连接数情况,动态地选取其中积压连接数最小的一台服务器来处理当前的请求,尽可能提高后端服务器的利用效率,合理地将请求分流到每一台服务器。
随机算法
随机算法是指随机选择一台后端服务器进行请求的处理。由于每次服务器被挑中的概率都一样,客户端的请求可以被均匀地分派到所有的后端服务器上。
哈希算法
获取客户端的 IP 地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
Session 共享问题的解决方案
Session 共享问题,已经有非常多的解决方案,主流的方案有以下几种。
session sticky
session sticky(粘性) , 保证同一个会话的请求都在同一个web 服务器上处理,这样的话,就完全不需要考虑会话的问题。比如前面说的负载均衡算法中,哈希算法就是一个典型的实现手段。
这种实现方式会有些问题:
1、如果 web 服务器宕机或者重启,那么这台机器上保存的会话数据都会丢失,会造成用户暂时无法访问的问题,或者用户之前的授权操作需要再执行一次。
2、 通过这种方式实现保持session,没有办法进行4层网络转发,只能在7层网络上进行解析并转发。
session replication
session复制,通过相关技术实现 session 复制,使得集群中的各个服务器相互保存各自节点存储的 session 数据。tomcat 本身就可以基于 IP 组播的方式,实现 session 复制的功能,
这种实现方式的问题:
- 同步 session 数据会造成网络开销,随着集群规模越大,同步 session 带来的带宽影响也越大。
- 每个节点都需要保存集群中所有节点的 session 数据,对内存的开销大。
session 统一存储
集群中的各个节点的session 数据,统一存储到一个存储设备中。每个节点去拿session 的时候,都从相应的第三方存储中去拿。对于这个方案来说,无论是哪个节点新增或者修改了session 数据,最终都会发生在这个集中存储的地方。这个存储设备可以是redis、也可以是mysql。
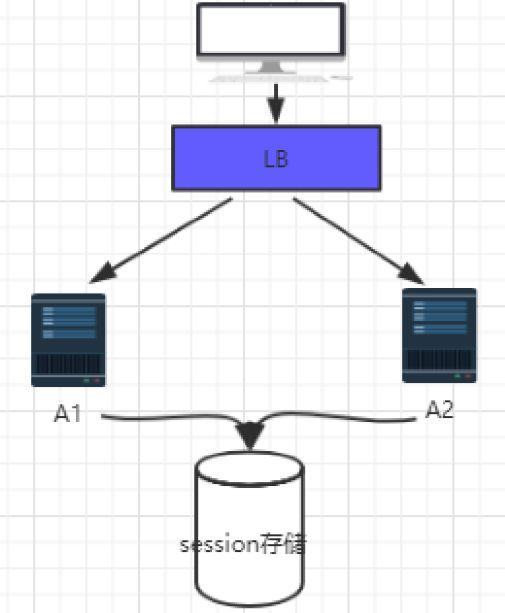
这种实现方式的问题:
1、读写session 数据需要进行网络操作,存在不稳定性和延迟性
2、如果存储session 的服务器出现故障,将大规模的影响到应用
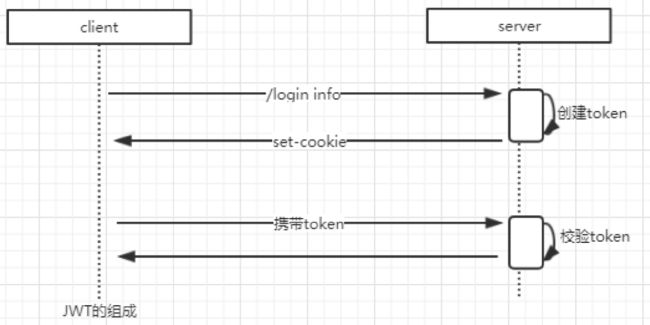
Cookie Based
Cookie Based 方法,简单来说,就是不依赖容器本身的Session 机制。而是服务端基于一定的算法,生成一个token 给到客户端,客户端每次请求,都会携带这个token。当服务端收到token 以后,先验证token 是否有效,再解密这个token 获取关键数据进行处理。
Cookie Based 实现方式
基于纯Cookie 的方式,也就是客户端每次请求都携带身份信息给到服务端。比较典型的方式是JWT,全称是JSON Web Tokens。是一种简洁的并且在两个计算机之间安全传递信息的表述性声明规范。JWT 的声明一般被用来在客户端和服务端之间传递被认证的用户身份信息,以便于从资源服务器获取资源。比如用在用户登录上。
JWT 强调的是服务端不对token进行存储,而是直接通过签名算法验证并解密token 得到相应数据进行处理。