本文是对Adventure Bicycle案例的一个总结,记录了整个项目需求分析与实现的过程,主要任务是使用Hive SQL完成ETL过程,并且连接到PowerBI实现可视化,最终将整个分析成果展示出来。
一、项目背景
Adventure Works Cycle是国内一家制造公司,该公司生产和销售金属和复合材料自行车在全国各个市场。销售方式主要有线上零售和线下批发或零售。
- 产品介绍
目前公司主要有下面四个产品线:
Adventure Works Cycles生产的自行车。
自行车部件,例如车轮,踏板或制动组件。
从供应商处购买的自行车服装,用于转售给Adventure Works Cycles的客户。
从供应商处购买的自行车配件,用于转售给Adventure Works Cycles的客户。
二、项目任务
- 随着线上业务的开展,需要增强公司数据化方面的治理,让前线的业务同学能够实现自主分析,从而能实现对市场的快速判断。因此,要求数据部门和业务部门沟通需求的自主分析的数据指标,从而实现可视化看板。
- 业务需求:查看最新的销量,销售额趋势以及个商品的销售占比,获取当天,前一天,当月,当季,当年的各区域各城市销量销售额,以及同比数据。
三、分析过程
要实现用户自主分析,必须具备两点:
(1)具有可视化操作页面
(2)数据能自动更新
Power BI可以实现用户的可视化操作,只要把相关的表聚合后展示需要的信息到Power BI上即可。但聚合后的数据是固定的,所以要把聚合表的代码部署到linux服务器上,让系统自动去运行聚合表的代码,更新数据,从而实现自主分析。
整体分析流程如下图所示:
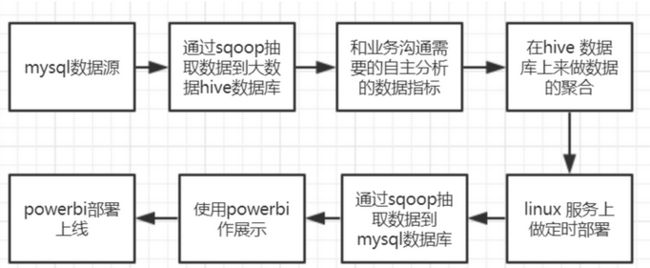
项目流程
准备工作:mysql 数据源,Hive数据库,工具:Sqoop,Power BI 服务器:linux
1.mysql数据源中观察数据
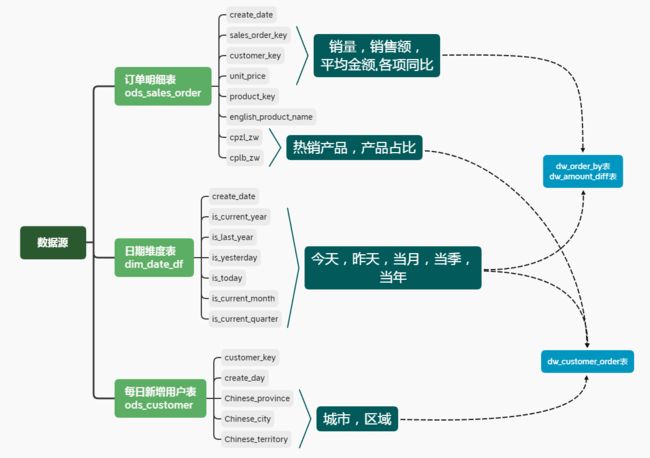
数据库中一共有26张表,根据业务需求,梳理出要使用到的三张表: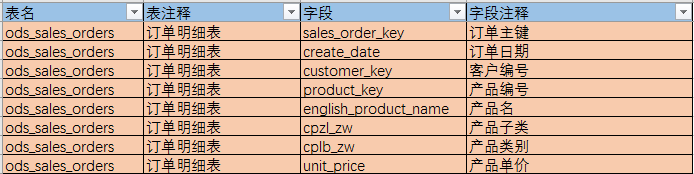
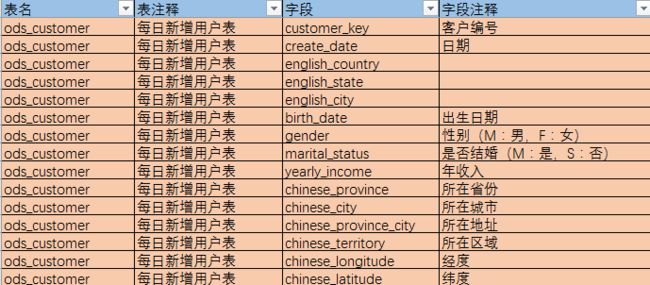

2.构建指标体系
指标维度:
时间维度:今日、昨日、当月、当季、当年
地域维度:销售大区、省份、城市
产品维度:产品类别、产品占比、热销产品
3.通过sqoop抽取数据到hive数据库
- Sqoop:SQL-to-Hadoop
- 连接 传统关系型数据库 和 Hadoop 的工具
- Sqoop是一个转换工具,用于在关系型数据库与Hive等之间进行数据转换

- 通过sqoop将日期维度表、每日新增用户表、订单明细表将数据从mysql中抽取到hive的ods层,通常将代码写在shell脚本上,在linux 系统中运行即可。
下面是部分shell脚本代码(sqoop_ods_sales_orders.sh)从订单明细表中抽取数据到hive:
hive -e "truncate table ods.ods_sales_orders" # 删除hive原有的旧表
sqoop import \
--hive-import \ # 将数据导入hive中
--connect "jdbc:mysql://106.13.128.83:3306/adventure_ods?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&dontTrackOpenResources=true&defaultFetchSize=50000&useCursorFetch=true" \
--driver com.mysql.jdbc.Driver \ # jdbc驱动类型
--username *** \ # 数据库用户名
--password *** \ #数据库连接密码
--query \
"select * from ods_sales_orders where "'$CONDITIONS'" " \ # 导入查询结果集
--fetch-size 50000 \ # 一次从数据库读取的条目数
--hive-table ods.ods_sales_orders \ # 输出表的名称
--hive-drop-import-delims \ # 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
--delete-target-dir \ # 删除导入目标目录
--target-dir /user/hadoop/sqoop/ods_sales_orders \ # 将数据导出目标文件目录(hdfs目录)
-m 1 #启动多个mapper并行执行导入
4.建立数据仓库,对数据进行聚合
聚合流程图:
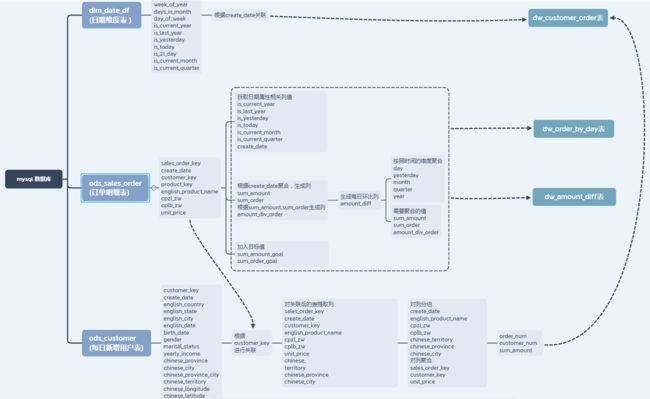
- 编写hive sql从数据仓库ods层的日期维度表、每日新增用户表、订单明细表读取数据进行数据聚合,完成当日维度表(dw_amount_diff)、时间-地区-产品聚合表(dw_customer_order),每日环比表(dw_order_by_day)的聚合操作。
下面是部分shell脚本代码(create_dw_order_by_day.sh)从ods层的订单明细表中读取数据来聚合每日环比表:
- 首先在DW层创建聚合表
## 创建聚合表
hive -e "drop table if exists ods.dw_order_by_day"
hive -e "
CREATE TABLE ods.dw_order_by_day(
create_date string,
is_current_year bigint,
is_last_year bigint,
is_yesterday bigint,
is_today bigint,
is_current_month bigint,
is_current_quarter bigint,
sum_amount double,
order_count bigint)
"
- 然后将聚合结果导入数据表中:
## 这里是hive的查询语句,因为做聚合需要关联多张表做聚合,这里使用with查询来提高查询性能
hive -e "
with dim_date as
(select create_date,
is_current_year,
is_last_year,
is_yesterday,
is_today,
is_current_month,
is_current_quarter
from ods.dim_date_df),
sum_day as
(select create_date,
sum(unit_price) as sum_amount,
count(customer_key) as order_count
from ods.ods_sales_orders
group by create_date)
insert into ods.dw_order_by_day
select b.create_date,
b.is_current_year,
b.is_last_year,
b.is_yesterday,
b.is_today,
b.is_current_month,
b.is_current_quarter,
a.sum_amount,
a.order_count
from sum_day as a
inner join dim_date as b
on a.create_date=b.create_date
"
5.Sqoop从Hive导出数据到mysql
Sqoop Export :导出
将数据从Hadoop(如hive等)导入关系型数据库导中
- 步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
- 步骤2:并行导入数据:
- 将Hadoop上文件划分成若干个split;
- 每个split由一个Map Task进行数据导入
- 现在需要通过sqoop把时间-地区-产品聚合表(dw_customer_order),每日环比表(dw_order_by_day)、当日维度表(dw_amount_diff)分别从Hive数据库迁入到mysql的数据库中。
CREATE TABLE `dw_order_by_day` (
`create_date` date DEFAULT NULL,
`sum_amount` double DEFAULT NULL,
`sum_order` bigint(20) DEFAULT NULL,
`amount_div_order` double DEFAULT NULL,
`sum_amount_goal` double DEFAULT NULL,
`sum_order_goal` double DEFAULT NULL,
`is_current_year` int(11) DEFAULT NULL,
`is_last_year` int(11) DEFAULT NULL,
`is_yesterday` int(11) DEFAULT NULL,
`is_today` int(11) DEFAULT NULL,
`is_current_month` int(11) DEFAULT NULL,
`is_current_quarter` int(11) DEFAULT NULL,
`is_21_day` int(11) DEFAULT NULL,
`amount_diff` double DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci
下面是部分shell脚本代码(export_dw_order_by_day .sh)将数据每日环比表中数据从hive迁入mysql中:
- 在数据导出之前先在mysql数据库中创建数据表(dw_order_by_day)
CREATE TABLE `dw_order_by_day` (
`create_date` date DEFAULT NULL,
`sum_amount` double DEFAULT NULL,
`sum_order` bigint(20) DEFAULT NULL,
`amount_div_order` double DEFAULT NULL,
`sum_amount_goal` double DEFAULT NULL,
`sum_order_goal` double DEFAULT NULL,
`is_current_year` int(11) DEFAULT NULL,
`is_last_year` int(11) DEFAULT NULL,
`is_yesterday` int(11) DEFAULT NULL,
`is_today` int(11) DEFAULT NULL,
`is_current_month` int(11) DEFAULT NULL,
`is_current_quarter` int(11) DEFAULT NULL,
`is_21_day` int(11) DEFAULT NULL,
`amount_diff` double DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci
- 开始进行sqoop从hive数据库抽取数据到mysql数据库
sqoop export --connect "jdbc:mysql://106.15.121.232:3306/datafrog05_adventure" \
--username *** \
--password *** \
--table dw_order_by_day \ # mysql数据库建好的表
--export-dir /user/hive/warehouse/ods.db/dw_order_by_day \ #hive数据库数据路径
--input-null-string "\\\\N" \
--input-null-non-string "\\\\N" \
--input-fields-terminated-by "\001" \
--input-lines-terminated-by "\\n" \
-m 1
6.在linux上做定时部署
- linux的定时任务使用crontab文件来实现,
(1)编写shedule.sh文件,按执行顺序添加文件
#!/bin/bash
sh /home/frog005/adventure_Bourton/sqoop_ods_sales_order.sh
sh /home/frog005/adventure_Bourton/sqoop_dim_date.sh
sh /home/frog005/adventure_Bourton/sqoop_ods_sales_orders.sh
sh /home/frog005/adventure_Bourton/create_dw_order_by_day.sh
sh /home/frog005/adventure_Bourton/create_dw_amount_diff.sh
sh /home/frog005/adventure_Bourton/create_dw_customer_order.sh
sh /home/frog005/adventure_Bourton/export_dw_order_by_day.sh
sh /home/frog005/adventure_Bourton/export_dw_amount_diff.sh
sh /home/frog005/adventure_Bourton/export_dw_customer_order.sh
(2)添加定时任务,设定每天早上6点执行
编辑crontab 文件 :vi /etc/crontab
添加定时任务:
0 6 * * * /home/frog005/adventure_sunnyxhd/schedule.sh
四、连接Power bi 部署展示
前面的步骤基本完成后,就可以把mysql与power bi 连接起来,实现bi数据的自动更新。
6.1 Power bi报表展示
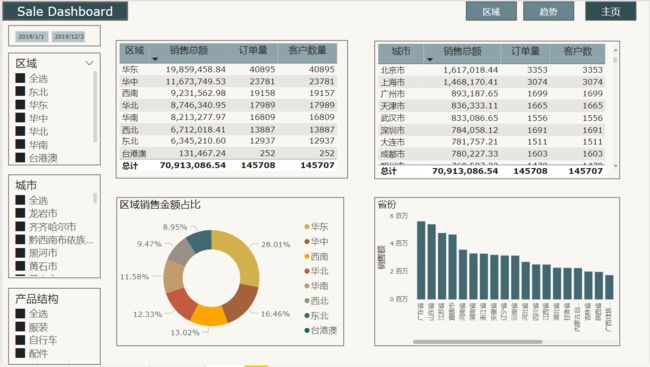
报表一共有3页,包括主页、时间趋势图、区域分布图。
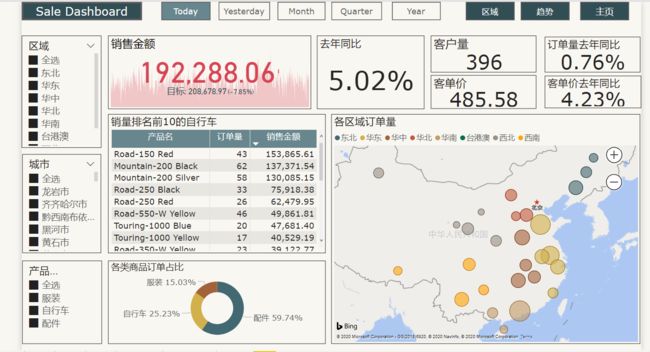
- 主页展示内容
- 基本销售指标:销售额、订单量、客户数量、客单价及相应同比指标
- 从时间维度分析年度、季度、月度、周、日销售情况
- 销售排名前10的产品
- 产品的结构
- 区域、商品类型切片器
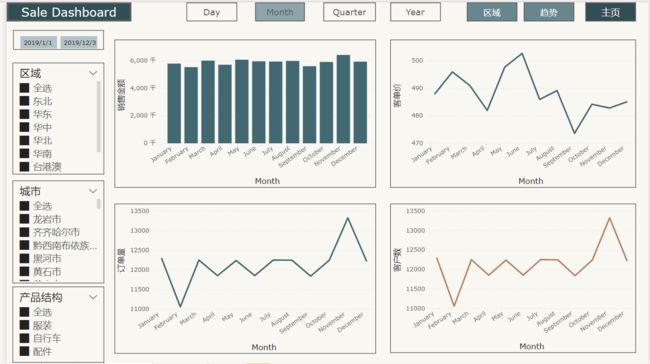
- 时间趋势图
- 展示时间维度:从日,月,季,年维度分析产品的销售额,订单量,客户数量,客单价趋势变化
-
区域,产品,时间类型切片器
- 区域分布图
1.展示各区域在一定时间段的销售金额,订单量,客户量。
2.展示各城市在一定时间段的销售金额,订单量,客户量。
3.各区域销售金额占比
4.区域,产品,时间类型切片器