背景
当我们谈论稳定性的时候,通常指的是crash,android有java crash & native crash,iOS有NSException & BSD signal & Mach EXC,业内通用的指标主要是session crash率(crash次数 / 启动数)和设备crash率(crash设备数 / 总设备数)。
对于上述指标,业界有多个成熟的监控平台,提供埋点、上报、展示到报警一站式服务,如Bugly、Fabric等。也有专业捕获crash的SDK,方便我们在此基础上按需定制监控平台,如KSCrash、Breakpad等,有这么完善的基础设施,稳定性的拼图似乎已经很完整了,果真如此么?很遗憾并不是,接下来我们开始讨论本文第一部分,退出率,请看下面这个案例。
退出率
从Wakeups说起
某日,多个大V主播反馈频繁崩溃(iOS),无法开播,要知道,大V的一次开播事故,影响的是百万级用户的用户体验,比一次普通的崩溃严重的多。相关同学立刻开始调查,结果没有一例crash上报,通过这次事件,我们意识到现有的crash监控系统是有漏洞的,正在无计可施之时,运营同学非常给力的拿到了主播的系统日志,其中关键的信息如下: Wakeups: 45001 wakeups over the last 142 seconds (316 wakeups per second average), exceeding limit of 150 wakeups per second over 300 seconds
这里的Wakeups是什么意思呢?查阅苹果官方文档[1],可以看到如下解释:
Resource Limit [EXC_RESOURCE]
The process exceeded a resource consumption limit. This is a notification from the OS that the process is using too many resources. The exact resource is listed in the Exception Subtype field. If the Exception Note field contains NON-FATAL CONDITION, then the process was not killed even though a crash report was generated.The exception subtype WAKEUPS indicates that threads in the process are being woken up too many times per second, which forces the CPU to wake up very often and consumes battery life.
Typically, this is caused by thread-to-thread communication (generally using peformSelector:onThread: or dispatch_async) that is unwittingly happening far more often than it should be. Because the sort of communication that triggers this exception is happening so frequently, there will usually be multiple background threads with very similar Backtraces - indicating where the communication is originating.
简单概括如下:Wakeups是“资源异常”下的一个子类,指的是频繁唤醒线程,消耗CPU资源并增加功耗,在超过阈值并处于FATAL CONDITION的条件下会触发崩溃,通常见于线程间频繁交互的场景。
了解了原理,接下来就好办了,通过分析系统日志中记录的触发唤醒backtrace,定位到问题发生的原因是粉丝们频繁的给大V发私信,导致高频的线程交互以及磁盘读写,这两个操作都会触发线程唤醒,最终使wakeups超出阈值。我们通过优化这两个操作,降低了线程唤醒频率,大V开播恢复了正常。至此,wakeups似乎圆满解决了,但作为有追求的程序员,不能满足于只解决眼前问题,如果用户不给我们反馈,或者不肯上传系统日志怎么办?我们需要能在线上监控到wakeups问题,要做到这一点,我们需要深入源码,了解操作系统是怎么做的。
Wakeups是怎么触发的

图1
图1是通过阅读XNU源码总结的系统监控wakeups的流程图,task_ledgers是内核维护的当前进程的”账本“,保存了各种系统资源的使用情况。当发生频繁唤醒时,会通过init_task_ledgers注册的回调函数task_wakeups_rate_exceeded进行处理,若参数warning的值为1,说明wakeups超出警戒线,开启遥测收集唤醒线程的堆栈,若warning的值为2,说明wakeups回落到警戒线以下,关闭遥测,若warning的值为0,说明wakeups超出阈值,调用SENDING_NOTIFICATION__THIS_PROCESS_IS_CAUSING_TOO_MANY_WAKEUPS触发EXC_RESOURCE,当满足fatal条件时,调用task_terminate_internal终止进程。
void init_task_ledgers(void) {
// ...
// 注册wakeups回调
ledger_set_callback(t, task_ledgers.interrupt_wakeups,
task_wakeups_rate_exceeded, NULL, NULL);
}
Wakeups的阈值定义由以下几个部分组成
#define TASK_WAKEUPS_MONITOR_DEFAULT_LIMIT 150 /* wakeups per second */
#define TASK_WAKEUPS_MONITOR_DEFAULT_INTERVAL 300 /* in seconds. */
/*
* Level (in terms of percentage of the limit) at which the wakeups monitor triggers telemetry.
*
* (ie when the task's wakeups rate exceeds 70% of the limit, start taking user
* stacktraces, aka micro-stackshots)
*/
#define TASK_WAKEUPS_MONITOR_DEFAULT_USTACKSHOTS_TRIGGER 70
如果300秒内的总wakeup数超过45000(300 * 150),则判断为超出阈值,若超出阈值的70%,则判定为超出警戒线,开启遥测。
/*
* Types of warnings that trigger a callback.
*/
#define LEDGER_WARNING_ROSE_ABOVE 1
#define LEDGER_WARNING_DIPPED_BELOW 2
void task_wakeups_rate_exceeded(int warning, __unused const void *param0, __unused const void *param1) {
if (warning == LEDGER_WARNING_ROSE_ABOVE) {
#if CONFIG_TELEMETRY
/*
* This task is in danger of violating the wakeups monitor. Enable telemetry on this task
* so there are micro-stackshots available if and when EXC_RESOURCE is triggered.
*/
telemetry_task_ctl(current_task(), TF_WAKEMON_WARNING, 1);
#endif
return;
}
#if CONFIG_TELEMETRY
/*
* If the balance has dipped below the warning level (LEDGER_WARNING_DIPPED_BELOW) or
* exceeded the limit, turn telemetry off for the task.
*/
telemetry_task_ctl(current_task(), TF_WAKEMON_WARNING, 0);
#endif
if (warning == 0) { SENDING_NOTIFICATION__THIS_PROCESS_IS_CAUSING_TOO_MANY_WAKEUPS();
}
}
SENDING_NOTIFICATION__THIS_PROCESS_IS_CAUSING_TOO_MANY_WAKEUPS的核心逻辑如下:
// 获取wakeup信息
ledger_get_entry_info(task->ledger, task_ledgers.interrupt_wakeups, &lei);
// fatal判定
fatal = task->rusage_cpu_flags & TASK_RUSECPU_FLAGS_FATAL_WAKEUPSMON;
// 写日志
// 触发EXC_RESOURCE异常
// 终止进程
if (fatal) {
task_terminate_internal(task);
}
从中可以得出一个重要结论: 只有fatal的EXC_RESOURCE才会触发崩溃,否则只会生成相关日志。
我们来看fatal flag的定义:
/* flags for rusage_cpu_flags */
#define TASK_RUSECPU_FLAGS_FATAL_WAKEUPSMON 0x10 /* wakeups monitor violations are fatal */
flag的相关赋值在task_wakeups_monitor_ctl函数中:
if (task->rusage_cpu_flags & TASK_RUSECPU_FLAGS_FATAL_WAKEUPSMON) {
*flags |= WAKEMON_MAKE_FATAL;
}
// ...
if (*flags & WAKEMON_MAKE_FATAL) {
task->rusage_cpu_flags |= TASK_RUSECPU_FLAGS_FATAL_WAKEUPSMON;
}
可以看到TASK_RUSECPU_FLAGS_FATAL_WAKEUPSMON和WAKEMON_MAKE_FATAL陷入了“鸡生蛋、蛋生鸡”的死循环中,源码中其他地方也没有这两个标志位的相关赋值,猜测可能是通过未公开代码或其他硬编码方式进行了置位,如果有了解的同学欢迎联系我们,感激不尽。
怎么监控wakeups

图2
图2是线程唤醒的流程图,可以看到,每次唤醒线程并对wakeup计数,都会调用ulock_wake,只要hook这个函数,计数并获取backtrace,就可以监控wakeups。如果我们只关心wakeup数,有更简便的方法,通过task_info获取task_power_info_v2_t结构体里的task_interrupt_wakeups字段,即为当前进程的wakeup总数,定期查询计算增量即可,为了验证上述方案的准确性,我们本地模拟线程唤醒触发wakeup异常,并将自己统计的wakeup数和系统生成的WAKEUPS日志文件中的wakeup数进行对比,误差不到千分之一。
抓取堆栈

图3
图3是hook ulock_wake获取backtrace的流程图,通过记录ulock_wake调用时的wakeup数和时间戳,在超出阈值时抓取backtrace并记录到文件中。ulock_wake是内核代码,不能通过常规的Method Swizzling或者fishhook来hook,需要通过Tweak在越狱机上hook。因此,wakeup相关堆栈目前只支持在越狱手机上进行抓取。至此,wakeups问题圆满解决,但我们并没有满足,而是进一步想到,除了wakeups,还有其他监控不到的稳定性问题么?
退出率定义
经过认真思考,我们认识到从前忽略了一个重要的基本事实,即应用的启动数和应用的退出数是守恒的。每次启动必然会有对应的退出,只要将所有的退出类型都枚举出来并监控上报,且总数能和启动数吻合,就能覆盖所有的稳定性问题。 基于以上思想,我们提出了退出率的概念,将退出分为以下十大类,每一类的退出率定义为 退出次数 / 启动次数。

图4
其中前五种退出类型是显著影响用户体验的问题,需要重点关注,crash(不含OOM)和OOM对应的是开头提到的通用指标;前台系统强杀指的是设备总内存紧张,应用在前台被系统强杀,比如iOS的jetsam,android的low memory killer,也包括其他一些资源问题,比如上文讲的wakeups;watchdog指的是卡顿引起的系统强杀,典型的即为iOS的watchdog和android的ANR;exit指的是我们主动在代码中自杀,通常情况下不应该有这样的逻辑存在。后五种退出类型绝大多数情况下是正常的退出行为,对用户体验无影响,我们只关注其中异常的情况,比如UI错乱导致的用户强杀,危险代码导致的系统重启等。
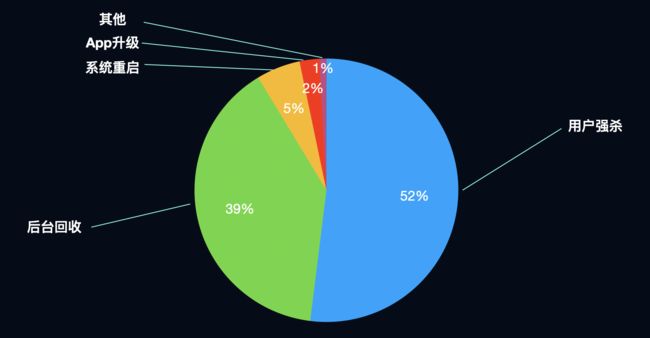
图5
图5是退出率占比的饼图,用户强杀和后台回收占据了绝对主导,重点关注问题已经全部归类到”其他“里,总占比不足1%,这和我们万分位的crash率也是吻合的。

图6
再来看下重点关注问题的退出占比(图6),可以看到前台系统强杀远远高于crash和OOM,颠覆了我们的认知。 那么非重点关注部分,是否都是正常退出的行为呢,看图7和图8:

图7

图8
俗话说,细节是魔鬼,如果我们分页面去看退出率(注意此处定义和前文不同,是退出次数 / PV)的分布,会发现一个很有意思的现象,不同页面的分布差异很大,比如LIVE_PUSH这个页面,用户退出率高达63.2%,说明这个页面用户体验较差,经调查是卡顿过高导致的,PASSWORD页面全部的退出都是由crash导致的,说明这个页面存在严重的bug。至此,我们的稳定性监控体系通过引入退出率统计而获得了完善。 接下来以一个比较重要的退出类型OOM为例,详细展开讨论我们是如何做优化的,即本文的第二部分,Android OOM治理。
Android OOM治理
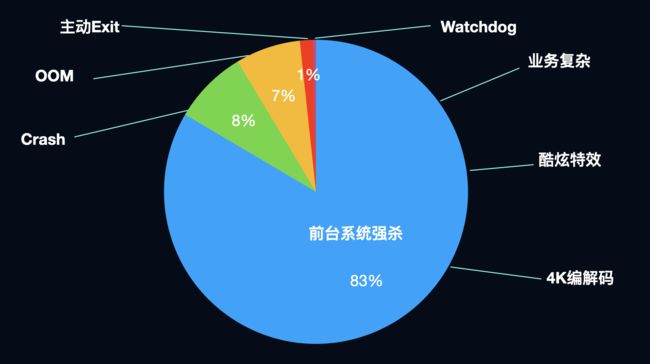
图9
回顾前文,OOM在稳定性重点关注问题中的占比非常高,和占比最高的前台系统强杀也有很高的相关性,而OOM问题的定位又特别困难,通常需要投入大量的人力和时间,进行人工复现,灰度收集数据,提交记录二分法暴力验证等等。占比高又定位困难,可以说OOM治理是稳定性治理皇冠上的明珠。 提到OOM,肯定绕不开神器LeakCanary,其原理也是面试题中的常客,作为Android内存泄漏监控的开创者,多年来一直为广大app保驾护航,解决了OOM治理从0到1的问题。那么直接接入LeakCanary上线不香么?还真不行,LeakCanary虽然非常优秀,但也存在以下几点硬伤:
-
无法线上部署
- 主动触发GC,造成卡顿
- Dump内存镜像造成app冻结
- 解析镜像成功率低
- 不具备上报能力
-
适用范围有限
- 只能定位Activity&Fragment泄漏
- 无法定位大对象、频繁分配等问题
-
自动化程度低
需要人工埋点
无法对问题聚类
既然没有现成的轮子可用,只能自己动手,丰衣足食,经过一番努力,我们打造了一套可以线上部署、兼顾线下、配置灵活、适用范围广泛、高度自动化,埋点、监控、解析、上报、分发、跟进、报警一站式服务的闭环监控系统。
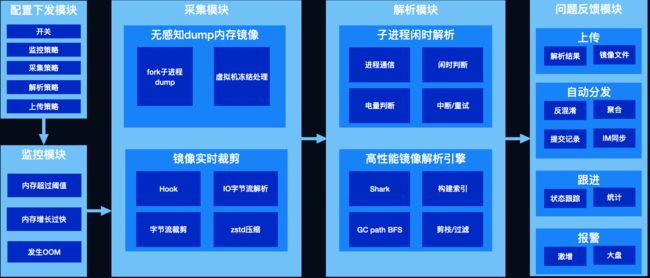
图10
其核心流程为三部分:
- 监控OOM,发生问题时触发内存镜像的采集,以便进一步分析问题
- 采集内存镜像,学名堆转储,将内存数据拷贝到文件中,以下简称dump hprof
- 解析镜像文件,对泄漏、超大对象等我们关注的对象进行可达性分析,解析出其到GC root的引用链以解决问题
为完成这样一套监控系统,我们攻克了以下技术难题
-
监控
- 主动触发GC,会造成卡顿
-
采集
- Dump hprof,会造成app冻结
- Hprof文件过大
-
解析
- 解析耗时过长
- 解析本身有OOM风险
接下来我们一一展开分析。
解决GC卡顿
为什么LeakCanary需要主动触发GC呢?LeakCanary监控泄漏利用了弱引用的特性,为Activity创建弱引用,当Activity对象变成弱可达时(没有强引用),弱引用会被加入到引用队列中,通过在Activity.onDestroy()后连续触发两次GC,并检查引用队列,可以判定Activity是否发生了泄漏。但频繁的GC会造成用户可感知的卡顿,为解决这一问题,我们设计了全新的监控模块,通过无性能损耗的内存阈值监控来触发镜像采集,具体策略如下:
- Java堆内存/线程数/文件描述符数突破阈值触发采集
- Java堆上涨速度突破阈值触发采集
- 发生OOM时如果策略1、2未命中 触发采集
- 泄漏判定延迟至解析时
阈值监控只要在子线程定期获取关注的几个内存指标即可,性能损耗可以忽略不计;内存快速上涨用来定位对象频繁分配的问题;OOM作为最后兜底的策略,走到这里说明我们的阈值设计有漏洞,没有拦截住所有可能触发OOM的场景;最后,我们将对象是否泄漏的判断延迟到了解析时。还是以Activity为例,我们并不需要在运行时判定其是否泄漏,Activity有一个成员变mDestroyed,在onDestory时会被置为true,只要解析时发现有可达且mDestroyed为true的Activity,即可判定为泄漏(由于时序问题,这里可能有极小概率会发生误判,但不影响我们解决问题),其他关注的对象可以根据其特点设计规则。用一张图总结:
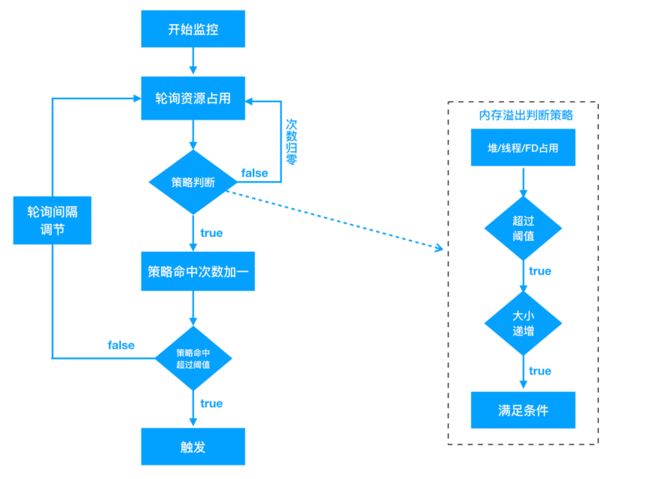
图11
解决Dump hprof冻结app
Dump hprof是通过虚拟机提供的API dumpHprofData实现的,这个过程会“冻结”整个应用进程,造成数秒甚至数十秒内用户无法操作,这也是LeakCanary无法线上部署的最主要原因,如果能将这一过程优化至用户无感知,将会给OOM治理带来很大的想象空间。
面对这样一个问题,我们将其拆解,自然而然产生2个疑问: 1.为什么dumpHprofData会冻结app,虚拟机的实现原理是什么? 2.这个过程能异步吗? 我们来看dumpHprofData的虚拟机内部实现 art/runtime/hprof/hprof.cc
// If "direct_to_ddms" is true, the other arguments are ignored, and data is
// sent directly to DDMS.
// If "fd" is >= 0, the output will be written to that file descriptor.
// Otherwise, "filename" is used to create an output file.
void DumpHeap(const char* filename, int fd, bool direct_to_ddms) {
CHECK(filename != nullptr);
Thread* self = Thread::Current();
// Need to take a heap dump while GC isn't running. See the comment in Heap::VisitObjects().
// Also we need the critical section to avoid visiting the same object twice. See b/34967844
gc::ScopedGCCriticalSection gcs(self,
gc::kGcCauseHprof,
gc::kCollectorTypeHprof);
ScopedSuspendAll ssa(__FUNCTION__, true /* long suspend */);
Hprof hprof(filename, fd, direct_to_ddms);
hprof.Dump();
}
可以看到在dump前,通过ScopedSuspendAll(构造函数中执行SuspendAll)执行了暂停所有java线程的操作,以防止在dump的过程中java堆发生变化,当dump结束后通过ScopedSuspendAll析构函数进行ResumeAll。
解决了第一个问题,接下来看第二个问题,既然要冻结所有线程,子线程异步处理是没有意义的,那么在子进程中处理呢?Android的内核是定制过的Linux, 而Linux fork子进程有一个著名的COW(Copy-on-write,写时复制)机制,即为了节省fork子进程的内存消耗和耗时,fork出的子进程并不会copy父进程的内存,而是和父进程共享内存空间。那么如何做到进程隔离呢,父子进程只在发生内存写入操作时,系统才会分配新的内存为写入方保留单独的拷贝,这就相当于子进程保留了fork瞬间时父进程的内存镜像,且后续父进程对内存的修改不会影响子进程,想到这里我们豁然开朗。说干就干,我们写了一个demo来验证这个思路,很快就遇到了棘手的新问题:dump前需要暂停所有java线程,而子进程只保留父进程执行fork操作的线程,在子进程中执行SuspendAll触发暂停是永远等不到其他线程返回结果的(详见thread_list.cc中行SuspendAll的实现,这里不展开讲了),经过仔细分析SuspendAll的过程,我们发现,可以先在主进程执行SuspendAll,使ThreadList中保存的所有线程状态为suspend,之后fork,子进程共享父进程的ThreadList全局变量,可以欺骗虚拟机,使其以为全部线程已经完成了暂停操作,接下来子进程就可以愉快的dump hprof了,而父进程可以立刻执行ResumeAll恢复运行。
这里有一个小技巧,SuspendAll没有对外暴露Java层的API,我们可以通过C层间接暴露的art::Dbg::SuspendVM来调用,dlsym拿到“_ZN3art3Dbg9SuspendVMEv”的地址调用即可,ResumeAll同理,注意这个函数在android 11以后已经被去除了,需要另行适配。Android 7之后对linker做了限制(即dlopen系统库失效),快手自研了kwai-linker组件,通过caller address替换和dl_iterate_phdr解析绕过了这一限制。 至此,我们完美解决了dump hprof冻结app的问题,用一张图总结:
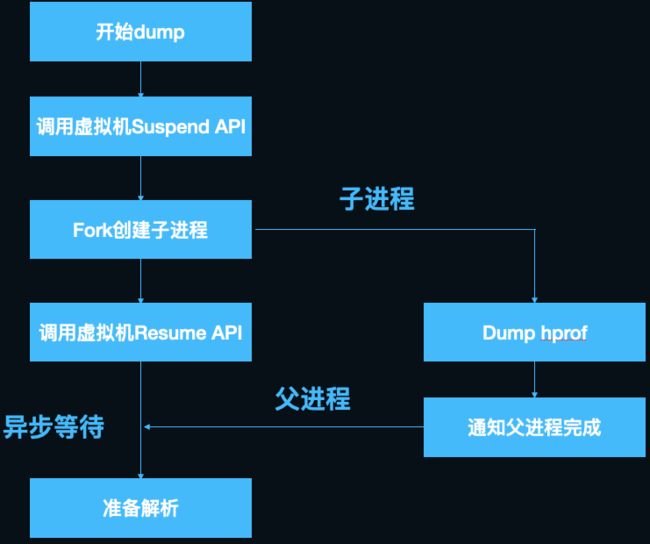
图12
解决hprof文件过大
Hprof文件通常比较大,分析OOM时遇到500M以上的hprof文件并不稀奇,文件的大小,与dump成功率、dump速度、上传成功率负相关,且大文件额外浪费用户大量的磁盘空间和流量。我们因此想到了对hprof进行裁剪,只保留分析OOM必须的数据,另外,裁剪还有数据脱敏的好处,只上传内存中类与对象的组织结构,并不上传真实的业务数据(诸如字符串、byte数组等含有具体数据的内容),保护用户隐私。
开发镜像裁剪,有两个衡量指标:一是裁剪率,即在不影响问题分析的前提下,裁剪掉的内容要足够多;二是裁剪性能损耗,如果性能不达标引发耗电、成功率低引入新的问题,就会使得内存镜像获取得不偿失。
照例,我们将问题拆解:
- hprof存的内容都是些什么?数据如何组织的?哪些可以裁掉?
- 内存中的数据结构和hprof文件二进制协议的映射关系?
- 如何裁剪?
想要了解hprof的数据组织方式,推荐阅读openjdk官方文档[2],Android在此基础上做了一些扩展,这里简要介绍一下核心内容:
- 文件按byte by byte顺序存储,u1,u2,u4分别代表1字节,2字节,4字节。
- 总体分为两部分,
Header和Record,Header记录hprof的元信息,Record分很多条目,每一条有一个单独的TAG代表类型。
我们关注的Record类型主要是HEAP DUMP,其中又分五个子类,分别为GC ROOT、CLASS DUMP、INSTANCE DUMP、OBJECT ARRAY DUMP、PRIMITIVE ARRAY DUMP。图13以PRIMITIVE ARRAY DUMP(基本类型数组)为例展示Record中包含的信息,其他类型请查阅官方文档。内存中绝大部分数据是PRIMITIVE ARRAY DUMP,通常占据80%以上,而我们分析OOM只关系对象的大小和引用关系,并不关心内容,因此这部分是我们裁剪的突破口。

图13
Android对数据类型做了扩展,增加了一些GC ROOT
// Android.
HPROF_HEAP_DUMP_INFO = 0xfe,
HPROF_ROOT_INTERNED_STRING = 0x89,
HPROF_ROOT_FINALIZING = 0x8a, // Obsolete.
HPROF_ROOT_DEBUGGER = 0x8b,
HPROF_ROOT_REFERENCE_CLEANUP = 0x8c, // Obsolete.
HPROF_ROOT_VM_INTERNAL = 0x8d,
HPROF_ROOT_JNI_MONITOR = 0x8e,
HPROF_UNREACHABLE = 0x90, // Obsolete.
HPROF_PRIMITIVE_ARRAY_NODATA_DUMP = 0xc3, // Obsolete.
还有一个HEAP_DUMP_INFO,这里面保存的是堆空间(heap space)的类型,Android对堆空间做了划分,我们只关注HPROF_HEAP_APP即可,其余也是可以裁剪掉的,可以参考Android Studio中Memory Profiler的处理[3]。
enum HprofHeapId {
HPROF_HEAP_DEFAULT = 0,
HPROF_HEAP_ZYGOTE = 'Z',
HPROF_HEAP_APP = 'A',
HPROF_HEAP_IMAGE = 'I',
};
接下来讨论如何裁剪,裁剪有两种办法,第一种是在dump完成后的hprof文件基础上裁剪,性能比较差,对磁盘空间要求也比较高,第二种是在dump的过程中实时裁剪,我们自然想要实现第二种。看一下Record写入的过程,先执行StartNewRecord,然后通过AddU1/U4/U8写入内存buffer,最后执行EndRecord将buffer写入文件。
void StartNewRecord(uint8_t tag, uint32_t time) {
if (length_ > 0) {
EndRecord();
}
DCHECK_EQ(length_, 0U);
AddU1(tag);
AddU4(time);
AddU4(0xdeaddead); // Length, replaced on flush.
started_ = true;
}
void EndRecord() {
// Replace length in header.
if (started_) {
UpdateU4(sizeof(uint8_t) + sizeof(uint32_t),
length_ - sizeof(uint8_t) - 2 * sizeof(uint32_t));
}
HandleEndRecord();
sum_length_ += length_;
max_length_ = std::max(max_length_, length_);
length_ = 0;
started_ = false;
}
void HandleFlush(const uint8_t* buffer, size_t length) override {
if (!errors_) {
errors_ = !fp_->WriteFully(buffer, length);
}
}
这个过程中有两个hook点可以选择,一是hook AddUx,在写入buffer的过程中裁剪,二是hook write,在写入文件过程中裁剪。最终我们选择了方案二,理由是AddUx调用比较频繁,判断逻辑复杂容易出现兼容性问题,而write是public API,且只在Record写入文件的时候调用一次,厂商不会魔改相关实现,从hook原理上来讲,hook外部调用的PLT/GOT hook也比hook内部调用的inline hook要稳定得多。
用一张图总结裁剪的流程:

图14
解决hprof解析的耗时与OOM
解析hprof文件,对关键对象进行可达性分析,得到引用链,是我们解决OOM最核心的一步,之前的监控和dump都是为解析做铺垫。解析分两种,一种是上传hprof文件由server解析,另一种是在客户端解析后上传报告(通常只有几KB)。最终我们选择了端上解析,这样做有两个好处:
- 节省用户流量
- 利用用户闲时算力,降低server压力,这样也符合分布式计算理念。
照例,我们依然将问题拆解:
- 哪些对象需要分析,全部分析性能开销太大,很难在端上完成,并且问题没有重点也不利于解决。
- 性能优化,作为一个debug组件,要在不影响用户体验的情况下完成解析,对性能有非常高的要求。
关键对象判定
回顾前文,我们只解析关键对象的引用链,并写入分析报告中上传,判定的准确性和覆盖度决定了分析的质量。
我们将关键对象分为两类,一类是根据规则可以判断出对象已经泄露,且持有大量资源的,另外一类是对象shallow / retained size 超过阈值。
Activity/fragment泄露判定即为第一种: 对于强可达的activity对象,其mDestroyed值为true时(onDestroy时赋值),判定已经泄露。类似的,对于fragment,当mCalled值为true且mFragmentManager为null时,判定已经泄露 。 我们可以用同样的思路合理制定规则,来处理我们核心的业务组件,比如无处不在的presenter。
Bitmap/window/array/sufacetexture判定为第二种 检查bitmap/texture的数量、宽高、window数量、array长度等等是否超过阈值,再结合hprof中的相关业务信息,比如屏幕大小,view大小等进行判定。
性能优化
一开始我们尝试了LeakCanary的解析引擎HAHA(Android Studio解析引擎perlib的Android移植版),解析过程中非常容易OOM,且解析速度极慢,500M的hprof文件,内存峰值达到2G,绝大多数Andriod设备的Java堆内存上限只有512M,即使顶配的macbook解析耗时都在3分钟以上,如此性能,在端上解析成功率低到发指。一度使我们想放弃现有的轮子,用C重写解析库,恰好此时LeakCanary发布了新的解析引擎shark[4],号称内存峰值可以降低10倍,解析速度可以提升6倍。我们实验了一下,发现小的demo hprof基本能达到其宣称的性能,线上真实环境拿到的包含百万级对象hprof文件,性能会急剧下降,分析时间突破10分钟。因此,我们需要进一步优化,优化之前,先来研究一下HAHA和shark的原理。
为什么HAHA内存峰值高,速度慢呢,概括起来主要是以下几点:
- 没做懒加载,hprof内容全部load到内存里。
-
domanitor tree[5]全量计算,实际上我们只关心关键对象的retained size。 - 频繁触发GC,java的集合类没有针对计算密集型任务做优化,含有大量冗余的装箱、拆箱、扩容、拷贝等操作,大量创建对象,频繁触发GC,GC反过来进一步降低对象分配速度,陷入恶性循环。
Shark是如何优化的呢? Shark是LeakCanary 2.0推出的全新解析组件,其设计思想详见作者的介绍[6],主要做了以下几项优化:
- 索引,
shark低内存开销的最根本原因就是通过索引做到了内存懒加载,遍历hprof时存储对象在hprof中的位置,并为其建立索引方便按需解析。 - 数据结构上做了深度优化,主要是使用了更高效的
map,有2个:第一是对于key和value都是基础类型或字符串的使用hppc做map,第二是对于value不是基本类型的,使用SortedBytesMap存储内容。
具体的索引有:实例索引、类索引、字符串索引、类名索引、数组索引:
/**
* This class is not thread safe, should be used from a single thread.
*/
internal class HprofInMemoryIndex private constructor(
private val positionSize: Int,
private val hprofStringCache: LongObjectScatterMap,
private val classNames: LongLongScatterMap,
private val classIndex: SortedBytesMap,
private val instanceIndex: SortedBytesMap,
private val objectArrayIndex: SortedBytesMap,
private val primitiveArrayIndex: SortedBytesMap,
private val gcRoots: List,
private val proguardMapping: ProguardMapping?,
val primitiveWrapperTypes: Set
) {
/**
* Code from com.carrotsearch.hppc.LongLongScatterMap copy pasted, inlined and converted to Kotlin.
*
* See https://github.com/carrotsearch/hppc .
*/
class LongLongScatterMap constructor(expectedElements: Int = 4) {
/**
* A read only map of `id` => `byte array` sorted by id, where `id` is a long if [longIdentifiers]
* is true and an int otherwise. Each entry has a value byte array of size [bytesPerValue].
*
* Instances are created by [UnsortedByteEntries]
*
* [get] and [contains] perform a binary search to locate a specific entry by key.
*/
internal class SortedBytesMap(
private val longIdentifiers: Boolean,
private val bytesPerValue: Int,
private val sortedEntries: ByteArray
) {
所谓hppc是High Performance Primitive Collection[7]的缩写,shark使用kotlin将其重写了。hppc只支持基本类型,所以没有了装、拆箱的性能损耗,相关集合操作也做了大量优化,其benchmark可以参考[8]。
再来看一下一个普通的对象在虚拟机中的内存开销有多大(ps:这还只是截图了一部分,一个int4个字节,1个long8个字节):

图15
前文提到,基于shark在解析大hprof时,性能依然不够理想,需要做进一步的优化。 先来分析一下shark的使用场景和我们解析需求的差异:
-
LeakCanary中shark只用于解析单一泄漏对象的引用链,而我们要分析大量对象的引用链。 -
Shark对于结果的要求非常精准,而我们是线上大数据分析,允许丢弃个别对象的引用链。 -
Shark对于镜像中的对象所有字段都进行解析,用于查询字段的值,而我们并不关心基础类型的值。
经过一番探索与实践,中途还去研究了MAT的源码,我们对其主要做了以下几点优化:
- GC root剪枝,由于我们搜索Path to GC Root时,是从GC Root自顶向下BFS,如
JavaFrame、MonitorUsed等此类GC Root可以直接剪枝。 - 基本类型、基本类型数组不搜索、不解析。
- 同类对象超过阈值时不再搜索。
- 增加预处理,缓存每个类的所有递归super class,减少重复计算。
- 将object ID的类型从
long修改为int,Android虚拟机的object ID大小只有32位,目前shark里使用的都是long来存储的,OOM时百万级对象的情况下,可以节省10M内存。
另外,还有几项实验中的调优项:
- 将
shark改用c++重写,从GC日志来看,大hprof解析时,GC还是十分频繁的,改用c++会降低这部分开销。 - 扩大okio segment池的大小,空间换时间,用更多的内存、来提升高频访问解析对象的性能。
经过以上优化,将解析时间在shark的基础上优化了2倍以上,内存峰值控制在100M以内。 用一张图总结解析的流程:
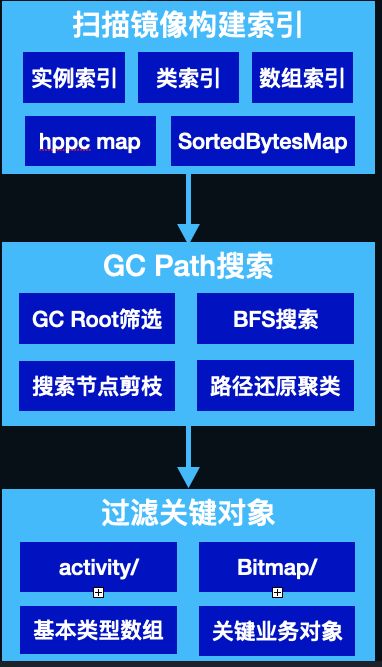
图16
分发与跟进
解析结果上传到server以后,还要做反混淆,聚类等工作。通过关键对象以及引用链,将问题聚合后自动分发给研发同学,分发的原则是引用链中最近提交代码的owner。图17&18摘录了跟进系统的关键信息:

图17
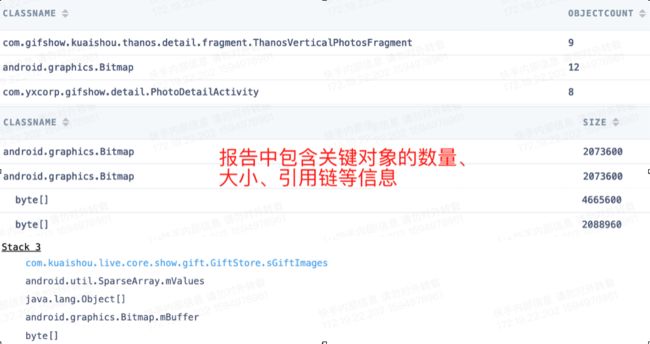
图18
收获与展望
总结下我们在以上两个项目中的收获以及未来的展望:
成果
- 通过退出率完善了稳定性体系
- 大幅降低OOM率
- 大幅提高解决OOM问题效率,减少人力投入
- 内存优化专项沉淀出开源项目KOOM
收获
- 遇到未知问题刨根问底,从wakeups异常问题,我们想到了监控所有未知的稳定性问题,提出了退出率的概念,并通过分页面监控进一步完善了监控体系。
- 抓头部问题,在我们的实践中,入口页面的泄漏对OOM的影响是最大的,一旦发生crash率会翻倍上涨。
- 大需求合入前做对比灰度,OOM问题很难定位到是哪个需求引入的,这方面我们有过惨痛教训,而在需求合入前通过对比灰度数据(base分支 vs base+需求),可以很精确的预估出实际上线后对大盘的影响,屡试不爽,因此我们要求大需求合入前必须有对比灰度数据验证过程。
- 从根源上解析问题,在此安利一下64位,谷歌已经于去年要求app升级64位,32位的地址空间只有4G,进程刚启动就要占2~3G,即使没有泄露问题并小心使用内存,在很多重度场景中依然容易触发OOM,快手升级64位以后crash率降低了一半左右。
- 方案选型做好可用性和性能的平衡。
- 问题难以解决时思考是否能绕过,比如GC的耗时我们很难优化,但是我们的目标是监控OOM,用阈值的方式也可以实现。
Roadmap
- 退出率进一步完善,还有极小部分的退出我们没有合理分类,还有一部分退出类型我们上报的信息不足,难以区分是用户正常行为还是体验问题,需要继续完善。
- 引用链解析性能优化。
- 完善问题判定规则,目前我们还会采样上报一部分hprof文件人工分析,用于完善我们的规则。
- Native OOM监控。
参考文献
- developer.apple.com/library/arc…
- hg.openjdk.java.net/jdk6/jdk6/j…
- github.com/aosp-mirror…
- square.github.io/leakcanary/…
- help.eclipse.org/2020-06/ind…
- www.droidcon.com/media-detai…
- github.com/carrotsearc…
- cloud.tencent.com/developer/a…
本文在开源项目:https://github.com/Android-Alvin/Android-LearningNotes 中已收录,里面包含不同方向的自学编程路线、面试题集合/面经、及系列技术文章等,资源持续更新中...
作者:快手技术团队
链接:https://juejin.cn/post/6860014199973871624