常用的中文分词器
Smart Chinese Analysis: 官方提供的中文分词器,不好用。
IKAnalyzer: 免费开源的java分词器,目前比较流行的中文分词器之一,简单,稳定,想要特别好的效果,需要自行维护词库,支持自定义词典。
结巴分词: 开源的python分词器,github有对应的java版本,有自行识别新词的功能,支持自定义词典。
Ansj中文分词: 基于n-Gram+CRF+HMM的中文分词的java实现,免费开源,支持应用自然语言处理。
hanlp: 免费开源,国人自然处理语言牛人无私奉献的。
对以上分词器进行了一个粗略对比:
| 分词器 | 优势 | 劣势 |
|---|---|---|
| Smart Chinese Analysis | 官方插件 | 中文分词效果惨不忍睹 |
| IKAnalyzer | 简单易用,支持自定义词典和远程词典 | 词库需要自行维护,不支持词性识别 |
| 结巴分词 | 新词识别功能 | 不支持词性识别 |
| Ansj中文分词 | 分词精准度不错,支持词性识别 | 对标hanlp词库略少,学习成本高 |
| Hanlp | 目前词库最完善,支持的特性非常多 | 需要更优的分词效果,学习成本高 |
截止到目前为止,他们的分词准确性从高到低依次是:
hanlp> ansj >结巴>IK>Smart Chinese Analysis
结合准确性来看,选用中文分词器基于以下考虑:
官方的Smart Chinese Analysis直接可以不考虑了
对搜索要求不高的建议选用 IK 学习成本低,使用教程多,还支持远程词典
对新词识别要求高的选用结巴分词
Ansj和hanlp均基于自然处理语言,分词准确度高,活跃度来讲hanlp略胜一筹
IK Analyzer
截止目前,IK分词器插件的优势是支持自定义热更新远程词典。
安装ik分词器插件
ik的es插件地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
环境es版本是6.4.0,下载时要注意对应es版本
上传到linux环境解压
[root@elk elk]# unzip elasticsearch-analysis-ik-6.4.0.zip
去es的plugins目录下创建ik文件夹
cd your-es-root/plugins/ && mkdir ik
解压插件到ik文件夹内
unzip plugin to folder your-es-root/plugins/ik
重启elasticsearch
还可以在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.0/elasticsearch-analysis-ik-6.4.0.zip
做一个测试:
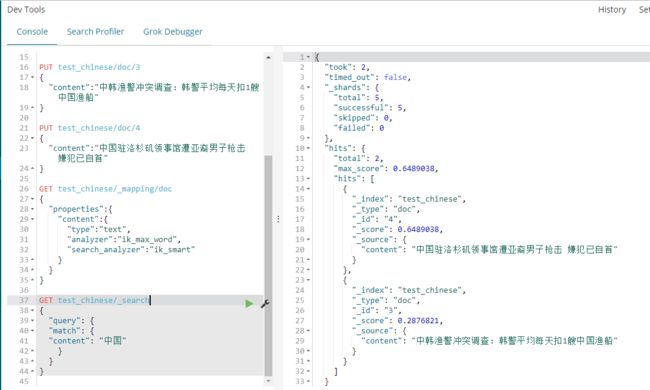
1创建一个index
PUT test_chinese
2创建一个mapping映射,设置哪个key使用ik分词
GET test_chinese/_mapping/doc
{
"properties":{
"content":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}
}
}
注意:要在put数据之间创建mapping,存在数据以后再创建会报错,若不创建mapping,es会使用默认分词器对中文进行分词。
3插入模拟数据
逐条插入语法:
PUT test_chinese/doc/1
{
"content":"美国留给伊拉克的是个烂摊子吗"
}
PUT test_chinese/doc/2
{
"content":"公安部:各地校车将享最高路权"
}
PUT test_chinese/doc/3
{
"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
}
PUT test_chinese/doc/4
{
"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
bulk批量操作语法:
POST _bulk
{ "index" : { "_index" : "test_ik", "_type" : "doc", "_id" : "1" } }
{ "content":"美国留给伊拉克的是个烂摊子吗" }
{ "index" : { "_index" : "test_ik", "_type" : "doc", "_id" : "2" } }
{ "content":"公安部:各地校车将享最高路权" }
{ "index" : { "_index" : "test_ik", "_type" : "doc", "_id" : "3" } }
{ "content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船" }
{ "index" : { "_index" : "test_ik", "_type" : "doc", "_id" : "4" } }
{ "content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首" }
4查询测试
GET test_chinese/_search
{
"query": {
"match": {
"content": "中国"
}
}
}
IK自定义词典
配置文件IKAnalyzer.cfg.xml。
如果是在线安装方式IKAnalyzer.cfg.xml的位置在{conf}/analysis-ik/IKAnalyzer.cfg.xml
离线安装在{plugins}/elasticsearch-analysis-ik-*/config/IKAnalyzer.cfg.xml
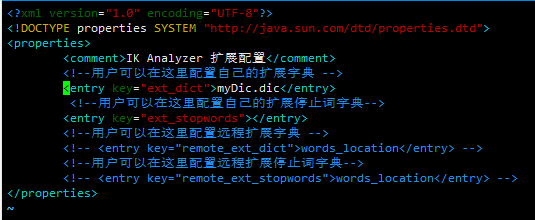
IK Analyzer 扩展配置
custom/mydict.dic;custom/single_word_low_freq.dic
custom/ext_stopword.dic
location
http://xxx.com/xxx.dic
ik文本词典均是以dic结尾,换行符作为分隔,示例如下:
[elk@elk analysis-ik]$ vim myDic.dic
修改ik配置文件,将自定义的词典添加到ik配置中
重启es,注意一定要重启es
通过前面教程中,我们发现短语"我爱中国",会被分词为, "我","爱","中国"三个词, 如果按照上面词典定义后, "我爱中国"会被当成一个词语不被分词。
常见问题
1.自定义词典为什么没有生效?
请确保你的扩展词典的文本格式为 UTF8 编码
2.ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
hanlp 中文分词器
安装hanlp中文分词器插件
hanlp的elasticsearch插件众多,这里选用了这个,这个插件支持的分词模式要多一些,截止现在此插件最新支持7.0.0,由于插件中包含很大的词典文件,建议此插件采用离线安装
- 下载安装ES对应Plugin Release版本
方式一
a. 下载对应的release安装包
b. 将相关内容解压至ES_HOME/plugins/analysis-hanlp
unzip -n elasticsearch-analysis-hanlp-6.4.0.zip -d /data01/elk/elasticsearch-6.4.0/plugins/analysis-hanlp
c. 将config目录下的文件移动至ES_HOME/config/analysis-hanlp
d. 解压出的data目录为词典目录
方式二
a. 使用elasticsearch插件脚本安装command如下:
./bin/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v6.4.0/elasticsearch-analysis-hanlp-6.4.0.zip
- 安装数据包
release包中存放的为HanLP源码中默认的分词数据,若要下载完整版数据包,请查看HanLP Release
数据包目录:ES_HOME/analysis-hanlp
注:因原版数据包自定义词典部分文件名为中文,这里的hanlp.properties中已修改为英文,请对应修改文件名
- 重启Elasticsearch
注:上述说明中的ES_HOME为自己的ES安装路径,需要绝对路径
提供的分词方式说明
hanlp: hanlp默认分词
hanlp_standard: 标准分词
hanlp_index: 索引分词
hanlp_nlp: NLP分词
hanlp_n_short: N-最短路分词
hanlp_dijkstra: 最短路分词
hanlp_crf: CRF分词(在hanlp 1.6.6已开始废弃)
hanlp_speed: 极速词典分词
样例
创建index
PUT /test_hanlp
创建mapping映射,设置哪个字段使用hanlp分词
GET test_hanlp/_mapping/doc
{
"properties":{
"text":{
"type":"text",
"analyzer":"hanlp",
"search_analyzer":"hanlp"
}
}
}
插入一条数据
PUT test_hanlp/doc/1
{
"text": "美国阿拉斯加州发生8.0级地震"
}
输入查询条件查询
GET test_hanlp/_search
{
"query": {
"match": {
"text": "美国"
}
}
}
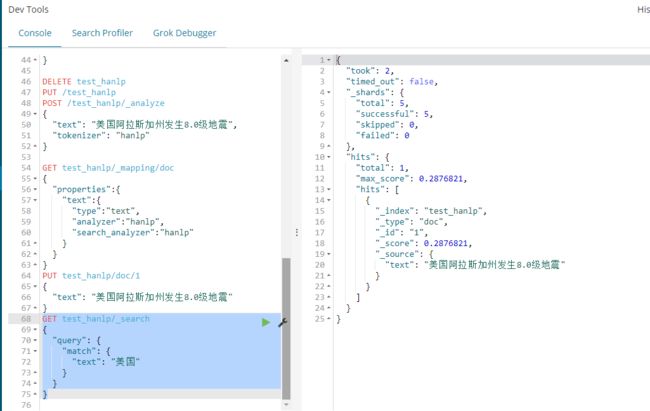
按
美国查询可以查出结果,按
国查不出结果,说明分词成功
还可以看一下hanlp对美国阿拉斯加州发生8.0级地震这句话是如何分词的
POST /test_hanlp/_analyze
{
"text": "美国阿拉斯加州发生8.0级地震",
"tokenizer": "hanlp"
}
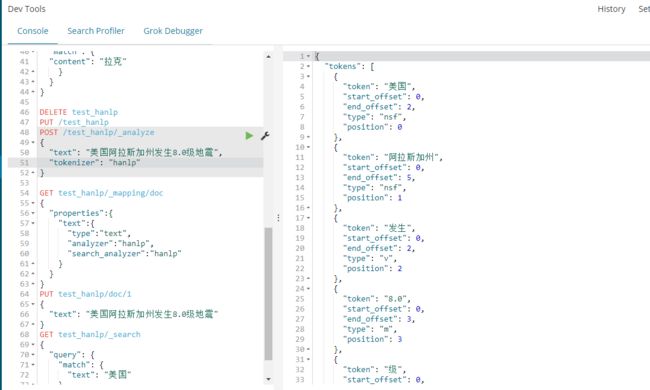
分词结果
{
"tokens": [
{
"token": "美国",
"start_offset": 0,
"end_offset": 2,
"type": "nsf",
"position": 0
},
{
"token": "阿拉斯加州",
"start_offset": 0,
"end_offset": 5,
"type": "nsf",
"position": 1
},
{
"token": "发生",
"start_offset": 0,
"end_offset": 2,
"type": "v",
"position": 2
},
{
"token": "8.0",
"start_offset": 0,
"end_offset": 3,
"type": "m",
"position": 3
},
{
"token": "级",
"start_offset": 0,
"end_offset": 1,
"type": "q",
"position": 4
},
{
"token": "地震",
"start_offset": 0,
"end_offset": 2,
"type": "n",
"position": 5
}
]
}
效果很不错了