python爬取新闻,并下载新闻中的图片
爬取篮球新闻,并下载新闻中的图片
-
- 背景
- 网页详情
- 详细代码
背景
今天一觉醒来,打开体育软件,都是安德烈-德拉蒙德加盟湖人的新闻,想起昨天的阿尔德里奇加盟篮网,现在湖人和篮网也是可以掰一掰手腕,一个篮球迷,还是希望看到势均力敌的体育竞技。
突然就想到为啥不搞一个爬取篮球新闻的爬虫,并下载新闻中的图片?
说干就干,冲!!!
网页详情
因为我平时在网上看的话习惯性用的是直播吧,所以今天就挑它下手了。
网址:https://news.zhibo8.cc/nba/2021-03-29/60619d6735e7c.htm
网页内容如下:


该新闻里面都是国内外网友的评论,因此我们今天的目的就是要把评论输出以及图片全部下载;
老规矩 F12 进入开发者选项,找到我们想要的内容对应的标签;
通过定位图片,我们可以下载那些图片的链接都是编写在 ‘img’ 中的,
photos = bs.find_all('img')
for i in photos:
photo = i.get("src")
photo = 'http:'+ photo #源码中的链接是缺失http:开头的,因此我们要自行加入
print(photo)
输出结果为:

接下来我们看看评论所在的表情,
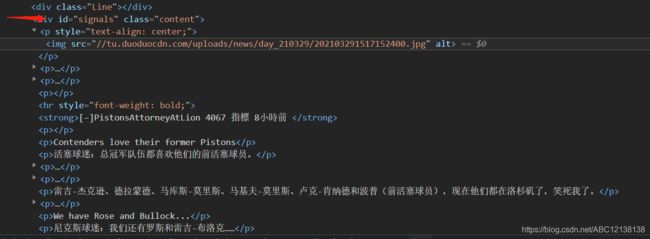
详细代码
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
html = urlopen("https://news.zhibo8.cc/nba/2021-03-29/60619d6735e7c.htm")
bs = BeautifulSoup(html,'html.parser')
# find_all()方法的attrs参数定义一个字典参数来搜索包含特殊属性的tag
ps = bs.find_all(id='signals')
print('\n'.join(p.text for p in ps))
a = 1
photos = bs.find_all('img')
for i in photos:
photo = i.get("src")
photo = 'http:'+ photo
print(photo)
r = requests.get(photo)
path = "E:/" +str(a)+ ".png" #自定义下载路径以及图片名
#使用with语句可以不用自己手动关闭已经打开的文件流
#开始写文件,wb代表写二进制文件
with open(path,"wb") as f:
f.write(r.content) #使用 r.content 来查看请求头部
print("爬取完成!")
f.close()
a = a+1
输出结果:

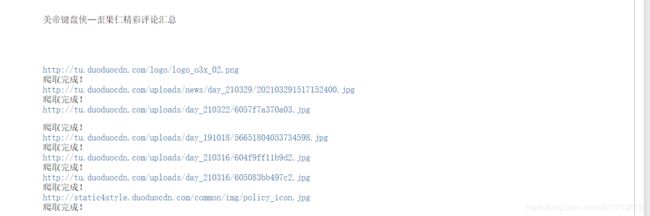
接下来我们来看看下载了的图片:





![]()

有兴趣的朋友可以直接运行一下!
结束,拜拜!