Hadoop RPC Client工作原理分析
文章目录
- 前言
- Hadoop Client的内部结构组成
-
- ClientId和CallId
- Client Connection和Connection Call的组织关系
- Client RPC Call的处理流程
- 相关链接
前言
对于Hadoop内的RPC处理(比如NameNode里的RPC请求处理),我们往往关注的是实际Server端的RPC处理,但是很少提起对应Client端的行为。Hadoop内部有自己专有的RPC Client实现,本文我们就来说说这个底层RPC Client是如何工作的。这有助于方便了解底层RPC请求的处理流程。
Hadoop Client的内部结构组成
首先我们来看看Client的内部结构组成。
ClientId和CallId
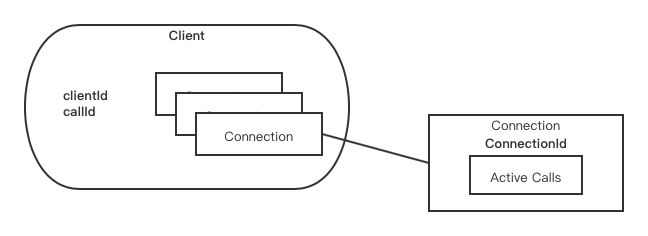
首先它有一个自己的clientId,clientId作为Client的独立标识。这个clientId在每个Client做初始化的时候根据UUID的值进行初始化生成。在后面的RPC的请求发送时,都会带有这个clientId的值。
private final byte[] clientId;
...
this.clientId = ClientId.getClientId();
/**
* Return clientId as byte[]
*/
public static byte[] getClientId() {
UUID uuid = UUID.randomUUID();
ByteBuffer buf = ByteBuffer.wrap(new byte[BYTE_LENGTH]);
buf.putLong(uuid.getMostSignificantBits());
buf.putLong(uuid.getLeastSignificantBits());
return buf.array();
}
另外还有一个关键的id,callId,callId意为当前Client发起每个RPC call的独立标识。它是一个自增的计数值。
/** A counter for generating call IDs. */
private static final AtomicInteger callIdCounter = new AtomicInteger();
private static final ThreadLocal<Integer> callId = new ThreadLocal<Integer>();
通过clientId和callId的组合,可以唯一标明一个RPC请求的来源,HDFS NameNode就是根据这2个id是做RPC请求RetryCache的处理的,以此避免请求被NameNode重复处理。
Client Connection和Connection Call的组织关系
一个Client要发起RPC请求的时候,需要与远端Server建立connection。那么Hadoop Client是如何做这块的连接呢?单一connection,connection pool?
Client用了一种connection cache的方式去尽量复用之前用过的connection,相关代码如下:
private final Cache<ConnectionId, Connection> connections =
CacheBuilder.newBuilder().build();
...
/** Get a connection from the pool, or create a new one and add it to the
* pool. Connections to a given ConnectionId are reused. */
private Connection getConnection(
final ConnectionId remoteId,
Call call, final int serviceClass, AtomicBoolean fallbackToSimpleAuth)
throws IOException {
if (!running.get()) {
// the client is stopped
throw new IOException("The client is stopped");
}
Connection connection;
/* we could avoid this allocation for each RPC by having a
* connectionsId object and with set() method. We need to manage the
* refs for keys in HashMap properly. For now its ok.
*/
while(true) {
try {
connection = connections.get(remoteId, new Callable<Connection>() {
@Override
public Connection call() throws Exception {
return new Connection(remoteId, serviceClass);
}
});
...
}
每个connection根据connectionId做区分,connectionId主要由server address+user名字+ rpc call的protocol组合来做区分。简单理解就是Client根据这3要素进行了connection的隔离使用。
public static class ConnectionId {
InetSocketAddress address;
UserGroupInformation ticket;
final Class<?> protocol;
...
private final int rpcTimeout;
private final int maxIdleTime; //connections will be culled if it was idle for
//maxIdleTime msecs
}
Client建立独立的connection去发送RPC call,但并不是说每次call发完后就立即close了connection。在实现上Client的connection是支持connection shared使用的。一个connection里维护了当前active的RPC call。
private class Connection extends Thread {
// currently active calls
private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>();
private AtomicLong lastActivity = new AtomicLong();// last I/O activity time
private AtomicBoolean shouldCloseConnection = new AtomicBoolean(); // indicate if the connection is closed
private IOException closeException; // close reason
...
Connection维护这些calls的目的是为了异步接收这些call的response返回结果,后面我们还会聊到这块的处理。
此部分的一个组织如下所示:
Client RPC Call的处理流程
下面我们来看看整个Client RPC请求的处理全过程。
首先第一步是外界调用了Client的call方法,然后参数里也传了调用者的ugi,地址等等信息。
/**
* Make a call, passing param, to the IPC server running at
* address which is servicing the protocol protocol,
* with the ticket credentials, rpcTimeout as
* timeout and conf as conf for this connection, returning the
* value. Throws exceptions if there are network problems or if the remote
* code threw an exception.
*/
public Writable call(RPC.RpcKind rpcKind, Writable param, InetSocketAddress addr,
Class<?> protocol, UserGroupInformation ticket,
int rpcTimeout, Configuration conf) throws IOException {
ConnectionId remoteId = ConnectionId.getConnectionId(addr, protocol,
ticket, rpcTimeout, conf);
return call(rpcKind, param, remoteId);
}
首先这里会进行一个ConnectionId的构建,此Id用在获取对应cache里的connection,或者需要再建一个新的connection如果在cache中没有找到的话。
以下是call操作方法的全部处理过程。
public Writable call(RPC.RpcKind rpcKind, Writable rpcRequest,
ConnectionId remoteId, int serviceClass,
AtomicBoolean fallbackToSimpleAuth) throws IOException {
// 1) 创建RPC call对象,此步骤会进行callId的自增加1
final Call call = createCall(rpcKind, rpcRequest);
// 2) 用传入的connectionId从connection cache中获取连接
final Connection connection = getConnection(remoteId, call, serviceClass,
fallbackToSimpleAuth);
try {
checkAsyncCall();
try {
// 3)通过connection发送RPC请求
connection.sendRpcRequest(call); // send the rpc request
} catch (RejectedExecutionException e) {
throw new IOException("connection has been closed", e);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
LOG.warn("interrupted waiting to send rpc request to server", e);
throw new IOException(e);
}
} catch(Exception e) {
if (isAsynchronousMode()) {
releaseAsyncCall();
}
throw e;
}
if (isAsynchronousMode()) {
...
} else {
// 4) 等待RPC call的返回结果
return getRpcResponse(call, connection, -1, null);
}
}
我们看到上面RPC请求的发送和response的接收是分开在两个步骤的,发送请求的方法只负责发送请求。
上面的是如何来做的呢,代码如下:
private Writable getRpcResponse(final Call call, final Connection connection,
final long timeout, final TimeUnit unit) throws IOException {
synchronized (call) {
while (!call.done) {
try {
final long waitTimeout = AsyncGet.Util.asyncGetTimeout2WaitTimeout(
timeout, unit);
call.wait(waitTimeout); // wait for the result
// 循环等待,判断call是否已被标记为done状态,如果是从call里取出response结果
if (waitTimeout > 0 && !call.done) {
return null;
}
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
throw new InterruptedIOException("Call interrupted");
}
}
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
} else {
// local exception
InetSocketAddress address = connection.getRemoteAddress();
throw NetUtils.wrapException(address.getHostName(),
address.getPort(),
NetUtils.getHostname(),
0,
call.error);
}
} else {
return call.getRpcResponse();
}
}
}
上面这个call的done标记状态的设置其实是由于connection来做的, connection的run方法:
@Override
public void run() {
if (LOG.isDebugEnabled())
LOG.debug(getName() + ": starting, having connections "
+ connections.size());
try {
while (waitForWork()) {
//wait here for work - read or close connection
receiveRpcResponse();
}
} catch (Throwable t) {
// This truly is unexpected, since we catch IOException in receiveResponse
// -- this is only to be really sure that we don't leave a client hanging
// forever.
LOG.warn("Unexpected error reading responses on connection " + this, t);
markClosed(new IOException("Error reading responses", t));
}
close();
if (LOG.isDebugEnabled())
LOG.debug(getName() + ": stopped, remaining connections "
+ connections.size());
}
}
....
/* Receive a response.
* Because only one receiver, so no synchronization on in.
*/
private void receiveRpcResponse() {
if (shouldCloseConnection.get()) {
return;
}
touch();
try {
int totalLen = in.readInt();
RpcResponseHeaderProto header =
RpcResponseHeaderProto.parseDelimitedFrom(in);
// 1) 检查header信息,主要检查header里面的clientId和当前clientId是否一致
checkResponse(header);
int headerLen = header.getSerializedSize();
headerLen += CodedOutputStream.computeRawVarint32Size(headerLen);
// 2) 获取收到的response里对应的callId值
int callId = header.getCallId();
if (LOG.isDebugEnabled())
LOG.debug(getName() + " got value #" + callId);
// 3) 获取此connection维护的call列表里对应的Call实例
Call call = calls.get(callId);
RpcStatusProto status = header.getStatus();
if (status == RpcStatusProto.SUCCESS) {
Writable value = ReflectionUtils.newInstance(valueClass, conf);
value.readFields(in); // read value
calls.remove(callId);
// 4) 此call请求返回状态成功,在此call里设置response值
call.setRpcResponse(value);
// verify that length was correct
// only for ProtobufEngine where len can be verified easily
if (call.getRpcResponse() instanceof ProtobufRpcEngine.RpcWrapper) {
ProtobufRpcEngine.RpcWrapper resWrapper =
(ProtobufRpcEngine.RpcWrapper) call.getRpcResponse();
if (totalLen != headerLen + resWrapper.getLength()) {
throw new RpcClientException(
"RPC response length mismatch on rpc success");
}
}
} else {
// Rpc Request failed
...
} catch (IOException e) {
markClosed(e);
}
}
Client的Connection本身是一个thread对象,它在Connection被setup好之后,就会开始触发run方法进行active call的response的异步接收。
当一个connection里面没有额外的call需要处理时并且其上次active的时间超过了max ideal time的时候,此connection就可以被关闭了。
相关判断方法如下:
/* wait till someone signals us to start reading RPC response or
* it is idle too long, it is marked as to be closed,
* or the client is marked as not running.
*
* Return true if it is time to read a response; false otherwise.
*/
private synchronized boolean waitForWork() {
// 如果Connection还在max idle时间范围内,则在进行一定时间的等待
if (calls.isEmpty() && !shouldCloseConnection.get() && running.get()) {
long timeout = maxIdleTime-
(Time.now()-lastActivity.get());
if (timeout>0) {
try {
wait(timeout);
} catch (InterruptedException e) {
}
}
}
if (!calls.isEmpty() && !shouldCloseConnection.get() && running.get()) {
return true;
} else if (shouldCloseConnection.get()) {
return false;
} else if (calls.isEmpty()) {
// idle connection closed or stopped
markClosed(null);
return false;
} else {
// get stopped but there are still pending requests
markClosed((IOException)new IOException().initCause(
new InterruptedException()));
return false;
}
}
这部分的处理流程简图如下所示:

上图横向意为方法内的深度调用,纵向意为同方法内的顺序调用。
以上就是本文所要阐述的关于Hadoop RPC Client的全部内容,里面涉及到不少关于RPC call和RPC connection之间的逻辑处理,需要更深一步了解学习的同学可参阅实际的Client类代码。
相关链接
[1]. https://github.com/apache/hadoop/blob/trunk/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/ipc/Client.java