Python 多线程入门,这一篇文章足够了。万字长文带你学习 Python 多线程
Python 和多线程
提及 Python 啊,我想你首先想到的就是「人生苦短,我用 Python」了。现在 Python 的热度可谓是非常的高,感觉程序员要是不学 Python 的话,就有一种 out 了的感觉,虽然现在工业界使用 Python 的人数远没有 Java 的人多, 但 Python 是未来的趋势是非常明显的,因此呢,学习 Python 自然就是一件很有必要的事情了,今天呢,我就带你一起聊聊 Python 多线程相关的那些事。
关于多线程啊,我想你肯定不陌生,无论是高级语言的鼻祖 C 语言、还是 C++、Java,都支持多线程、多进程,而且这部分知识无论是在求职面试还是在日常的工作开发中,都会涉及到,不巧的是呢,这部分知识在老师讲课过程中是很少涉及的,甚至是直接不讲,我记得我当时老师就没有讲,这不是说老师不合格,偷懒了,而是一门语言涉及到的知识太多了,老师只能把一些基础的东西交给你,带你入门,剩下的就需要自己去摸索、自学了。
线程与进程
既然提到多线程,多进程了,那就有必要先了解下线程和进程的相关概念了。要不然的话后面的内容理解起来也是有点费劲的。
提到进程啊,我想你肯定是不陌生的,我们在电脑上打开一个软件,就是开启了一个进程,更具体的来说,Windows 系统你可以通过资源管理器进行查看当前电脑启动的进程数。

用比较正式的话来说,进程就是处于运行中的程序,并且具有一定独立的功能。进程是操作系统进行资源分配和调度的一个独立单位。
然后就是线程,它是进程的组成部分,一个线程可以包含多个线程,多个线程可以共用这个进程的资源,相比于进程,线程更加轻量级。
举个例子来说明下:我们的生活都是以家单位的,每家每户每天都有自己的计划安排、互不影响,这时候,每家就相当于一个进程,但是呢,需要受到国家的管制,比如说,买房限购、户口问题啊等等需要国家统一出台政策进行管理,这时候国家就相当于操作系统,而房子、户口就相当于资源。但是对于每一家来说,又有不同的人,这时候,每个人就相当于一个线程,多个线程之间共用家里的一些资源,就是家里的人共用家里的一些东西。虽然例子不是很恰当,但对于理解线程和进程还是有很大帮助的。
线程的几种状态
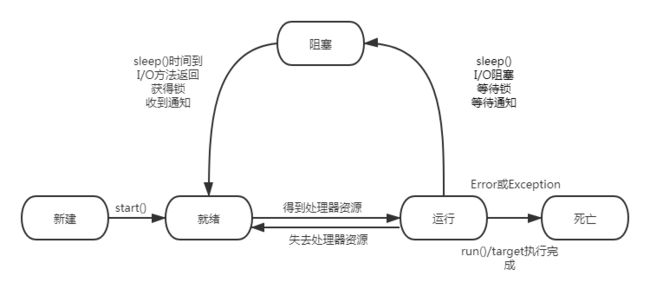
线程状态一共有五种,包括如下:
- 新建
- 就绪
- 运行
- 阻塞
- 死亡
它们之间的关系如下图所示:
实现方式
接下来,我们就来看看如何在 Python 里面实现多线程。总的来说,如果你了解过其他语言实现多线程的方式,比如说 Java的话,那对于理解 Python 实现多线程是非常有帮助的。 Python 实现多线程有两种方式:
- 使用 threading 模块的 Thread 类的构造器创建线程
- 继承 threading 模块的 Thread 类创造线程类
看到这,你是不是发现这和 Java 实现多线程的方式很相类,不错,确实就是这样,所以再次印证了那句话,只要学好了一门语言,学习其他语言都会起到事半功倍的效果。
使用 threading 模块的 Thread 类的构造器创建线程
我们先用第一只方法来编写一个多线程程序
#!/usr/bin/python
# -*- coding: utf-8 -*-
import threading
# 定义一个简单的方法,用于多线程的执行体
def action(number):
for i in range(number):
# 调用 threading 模块的 current_thread() 函数来获取当前线程
# 调用当前线程的 getName() 函数来获取线程名
print("{},{}".format(threading.current_thread().getName(), i))
number = 5
for i in range(5):
print("{},{}".format(threading.current_thread().getName(), i))
if i == 3:
# 创建并启动第一个线程
t1 = threading.Thread(target=action, args=(number, ))
t1.start()
# 创建并启动第二个线程
t2 = threading.Thread(target=action, args=(number, ))
t2.start()
看起来是不是很简单,很我们平常写的 Python 程序并没有特别大的不同,但是还是有很一些情况是需要注意的,其中最重要的就是 threading.Thread(),我在这里重点介绍下。
首先它是一个类,我们可以通过 type(threading.Thread) 来进行查看,它的构造函数如下所示:
__init__(self, group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
group 应该为None,这个我们不用管,它是为了日后扩展 ThreadGroup 类实现而保留的一个参数
target 是我们需要重视的一个参数, 我们想让哪个函数多个线程同时执行,这个函数就是 target 的参数值,注意只写函数名,不需要写 ()
name 是线程名称,默认情况下,由"Thread-N"的格式构成一个唯一的名称,其中 N 是小的十进制数
args 是用于调用目标函数的参数元祖, 注意是元祖, 如果你只想传一个参数的话,也应该这样写 (args1,), 而不是 (args)
kwargs 是用于调用目标函数的关键字参数字典。默认是 {}
daemon 用于设置该线程是否为守护模式,如果是 None, 线程默认将继承当前线程的守护模式属性。
一般来说,我们需要注意的就是 target 参数、args 参数,其他的参数用到的时候可以再查。
另一点需要我们需要注意的一点就是启动线程的方法是 start 方法,可能你也知道线程也有 run 方法,这一块也会在第二种方法中进行介绍,但是启动线程的方法是 start 方法,要不然就变成了单线程程序。
继承 threading 模块的 Thread 类创造线程类
接下来我们来看下如何使用第二种方法实现多线程
#! /usr/bin/python
# -*- coding:utf-8 -*-
import threading
from threading import Thread
# 继承 threading.Thread
class MyThread(Thread):
def __init__(self, number):
super().__init__()
self.number = number
# 重载 run() 方法
def run(self):
for i in range(self.number):
print("{}, {}".format(threading.current_thread().getName(), i))
number = 5
for i in range(5):
print("{}, {}".format(threading.current_thread().getName(), i))
if i == 3:
t1 = MyThread(number=number)
t1.start()
t2 = MyThread(number=number)
t2.start()
第二种方法就是继承 Threading.Thread 类。然后重载 run() 方法。
其实早我看来的话,感觉第二种方法更适合在项目中使用,因为它更加模块化,比较清晰。
另外还有一个方法需要注意的就是 join() 方法,它的作用就是协调主线程和子线程的,调用 join() 后,当前线程就会阻塞,或者来说,暂停运行,执行子线程,等子线程执行完成后,主线程再接着运行。
生产者、消费者模型
提到多线程,最著名的就是生产者、消费者模型了,那应该如何实现呢?
说实话,我当初最开始学习生产者、消费者模型的时候,心里是有点犯嘀咕的,感觉涉及到线程间的通信,太好解决。但是查阅了一些资料后,发现还是可以理解的。
生产者、消费者二者不属于竞争关系,更多的是一种捕食关系,生产者生产资源,消费者进行消费,就像圣湖中的牛吃草一样。
不知道这时候你有没有想到一种数据结构,那就是队列,队列呢是一种操作受限的线性表,它只允许在队尾入队,在队头
出队,也就是先进先出 (FIFO) 策略。
生产者、消费者模型,不就是生产者生产元素,放到队尾,然后消费者从队头消费元素嘛。
只不过有时候会出现特殊的情况
- 队列空了,消费者还要消费数据
- 队列满了,生产者还要生产数据
这是我们需要重点考虑了,解决了以上两点,这个模型也就实现了。
接下来我们就来看看 Python 如何实现吧!
#!/usr/bin/python
# -*- coding:utf-8
from threading import Thread, current_thread
import time
import random
from queue import Queue
queue = Queue(5)
class ProducerThread(Thread):
def run(self):
name = current_thread().getName()
nums = range(100)
global queue
while True:
num = random.choice(nums)
queue.put(num)
print("生产者 {} 生产了数据 {}".format(name, num))
t = random.randint(1, 3)
time.sleep(t)
print("生产者 {} 睡眠了 {} 秒".format(name, t))
class ConsumerThread(Thread):
def run(self):
name = current_thread().getName()
global queue
while True:
num = queue.get()
queue.task_done()
print("消费者 {} 消耗了数据 {}".format(name, num))
t = random.randint(1, 5)
time.sleep(t)
print("消费者 {} 睡眠了 {} 秒".format(name, t))
p1 = ProducerThread(name="producer1")
p1.start()
c1 = ConsumerThread(name="consumer1")
c1.start()
c2 = ConsumerThread(name="consumer2")
c2.start()
看了上面的代码,不知道你有没有一种错觉,你不是说要考虑上面的两种情况,但是你并没有考虑啊。
确实,我没有考虑,那是因为 Queue 在设计实现的时候已经替我们考虑好了,我们直接使用就好了。
具体就是 task_done() 函数,它在队列为空时会自动阻塞当前线程
而队列在满的时候再添加元素也会阻塞当前线程,这就实现了上面我们提到的那两种情况。
接下来呢,我再给你讲解一个例子,带你看看如何使用锁。
银行取钱问题
从银行取钱的基本流程大致可以分为以下几个步骤:
- 用户输入账户、密码,系统判断当前的账户、密码是否匹配。
- 用户输入取款金额
- 系统判断账户余额是否大于取款金额
- 如果余额大于取款金额,则取款成功;如果余额小于取款金额,则取款失败。
乍一看,这就是日常生活中的取款操作啊,但是把它放到多线程并发的情况下,就可能会出现问题。不信的话,你可以试着写下多线程的程序,然后再看下我的程序。
#!/usr/bin/python
# -*- coding:utf-8 -*-
import threading
import time
class Account:
def __init__(self, account_no, balance):
self.account_no = account_no
self._balance = balance
# 定义一个锁
self.lock = threading.RLock()
def get_balance(self):
return self._balance
def draw(self, draw_amount):
# 对 RLock 对象进行加锁
self.lock.acquire()
try:
if self._balance >= draw_amount:
print(threading.current_thread().getName() + "取钱成功,吐出钞票:" + str(draw_amount))
time.sleep(0.001)
self._balance -= draw_amount
print("\t余额为:" + str(self._balance))
else:
print(threading.current_thread().getName() + "取钱失败,余额不足!")
finally:
# 释放锁
self.lock.release()
# 定义一个函数来模拟取钱操作
def draw(account, draw_count):
account.draw(draw_count)
acct = Account("1234567", 1000)
threading.Thread(name="甲", target=draw, args=(acct, 800)).start()
threading.Thread(name="乙", target=draw, args=(acct, 800)).start()
如果你想尝试下不加锁的情况下是否会出现问题,你可以把我的程序进行修改,把加锁的那部分去掉,然后尝试运行下。
这里呢,不是说每次运行都会出现问题,可能你运行了十次也都没有出现问题,但是呢,这个安全隐患是确确实实存在的,不容忽视。
好了,今天的内容就先分享到这里了,不知道你对多线程的内容理解了多少,不理解的话也没关系,多看几遍,然后很重要的就是自己好好写一遍实践一下,这样对于理解是有很大帮助的。如果遇到问题,也可以在我的微&&信&&公&&众&&号&&「与你一起学算法」底部找到我的微信联系方式,联系我。
多线程的内容有很多,今天只是分享了一些比较基础的内容,后面会再更新,欢迎关注我,一起加油进步。