Linux 基础IO(系统调用/文件描述符/重定向)
目录
Linux 系统 . 文件IO
Linux 系统调用与C库函数对比记忆
fopen & open fclose & close
fwrite & write fread & read
fleek & leek
stdin & stdout & strerr
文件描述符fd
struct file(file结构体)
struct files_struct
0 & 1 & 2
文件流指针与文件描述符
文件描述符的分配规则
重定向
在Shell中的使用
输出重定向(常用)
>>(追加重定向) & >(清空重定向)
输入重定向
dup2()系统调用
引言
Linux 的基础IO接口和C语言中IO相关的库函数用法相似, 先简单回顾一下C中是怎样操作的.
#include
#include
int main(){
FILE* fp = fopen("myfile.txt", "w+");
if(fp == NULL){
printf("打开失败\n");
}
const char* str = "hello world!\n";
int count = 5;
int len = strlen(str);
while(count--){
fwrite(str, len, 1, fp);
}
fseek(fp, 0 , 0);
char buf[1024] = { 0 };
count = 5;
size_t n;
while(count--){
n = fread(buf, 1, len, fp);
if(n > 0){
printf("%s", buf);
}
if(feof(fp)){
break;
}
}
fclose(fp);
return 0;
}


C语言将hello world 打印到屏幕, 有什么方法呢? 回顾一下
#include
#include
int main(){
const char* str = "hello world\n";
int len = strlen(str);
printf(str);
puts("hello world");
fwrite(str, 1, len, stdout);
fprintf(stdout, str);
fputs(str, stdout);
for(int i = 0; i < len; ++i) {
putchar(*(str + i));
}
for(int i = 0; i < len; ++i) {
fputc(*(str + i), stdout);
}
for(int i = 0; i < len; ++i) {
putc(*(str + i), stdout);
}
return 0;
} 
回顾了C语言的IO操作, 接下来就该Linux操作系统内核中提供的IO接口了.
Linux 系统 . 文件IO
当然, 除了上面列举的C语言IO相关的库函数接口, C++等其他语言也有. 不过除了语言本身, Linux还提供了系统调用接口, 不借
助语言本身的库函数接口, 也能实现基础的IO操作. 如下, 我们用Linux中的系统调用接口来重复一下上面的第一个代码.
#include
#include
#include
#include
#include
int main(){
umask(0);
int fd = open("myfile2.txt", O_RDWR | O_CREAT, 0644);
if(fd < 0){
printf("打开失败\n");
return 0;
}
const char* str = "hello world!\n";
int count = 5;
int len = strlen(str);
while(count--){
write(fd, str, len);
}
lseek(fd, SEEK_SET, 0);
char buf[1024] = { 0 };
count = 5;
size_t n;
while(count--){
n = read(fd, buf, len);
if(n > 0){
printf("%s", buf);
}
else{
break;
}
}
close(fd);
return 0;
}

可以发现, Linux中的系统调用不仅仅是名字长的和C库中的函数长的相似, 用起来也是很相似 .
Linux 系统调用与C库函数对比记忆
C库函数 |
Linux系统调用 |
|
fopen & open |
||
| 接口名 | fopen() | open() |
| 原型 | FILE* fopen( const char* filename, const char* mode ) |
int open(const char *pathname, int flags) int open(const char *pathname, int flags, mode_t mode) |
| 参数含义 | filename: 需要打开的文件名(也可以带路径) mode : 打开方式 "w"(只写), "r"(只读), "a"(追加) "w+"(读写), 若文件已存在, 会清空原文件 "r+"(读写)若文件已存在, 不会清空原文件 "a+"(读写)打开一个文件, 在文件末尾进行读写 |
filename: 带路径的文件名文件 flags : 文件打开方式 flags选项: 必选项 : O_RDRW(读写), O_RDONLY(只读), O_WDONLY(只写) (必选项必须且只能选一个, 可以可选项搭配使用, 用 | 连接) 常用可选项: O_APPEND(若文件存在, 以追加模式打开) O_TRUNC(若以可写方式打开一个已存在的普通文件, 则将其清空) O_EXCL: 若和O_CREAT同时使用, 若文件不存在则创建, 若已经存在则报错 mode: 用于设置新建文件权限 mode只有当选用O_CREAT时才有效, 否则会被忽略, 此时用于设置新创建文件的预设权限, 预设权限 = mode&(~umask) |
| 功能/ 返回值 |
打开指定的文件, 将一个文件流与它关联, 返回这个文件流指针. 若失败返回NULL | 打开指定的文件, 若文件存在, 则返回这个文件的文件描述符fd, 若文件不存在但open创建了则返回新创建的文件的文件描述符fd. 成功时的fd是一个正的小整数. 若失败, 返回值小于 0 |
fclose & close |
||
| 接口名 | fclose() | close() |
| 原型 | int fclose( FILE* stream ) | int close(int fd) |
| 参数含义 | FILE* stream : 需要关闭的文件的文件流指针 |
int fd :需要关闭的文件的文件描述符 |
| 功能/ 返回值 |
关闭与stream这个文件流关联的文件, 并取消文件与stream这个文件流的关联 成功返回0, 失败返回EOF(-1) |
关闭一个文件描述符, 使它不再指向任何文件. 成功返回0, 失败返回-1 |
fwrite & write |
||
| 接口名 | fwrite() | write() |
| 原型 | size_t fwrite( const void *buffer, size_t size, size_t count, FILE *stream ) |
ssize_t write(int fd, const void *buf, size_t count) |
| 参数含义 | buffer :所写数据的地址 conut : 数据个数 size : 数据大小(几字节) stream:文件流指针, (需要往哪儿写入) |
fd: 文件描述符 buf: 要写入文件的数据的地址 count :需要读取的字节个数 |
| 功能/ 返回值 |
从buffer(首地址处)开始向后读取count个size字节数的数据,写入stream所指向文件位置处. 返回成功写入的元素总数, 如果该数字与count参数不同,则写入错误, 在这种情况下,将为流设置错误指示符(ferror). 成功几个返回几, 返回值最小为0 |
向文件描述符fd所引用的文件中写入从buf开始的缓冲区中count字节的数据. ssize_t 可以理解为是有符号的size_t , 即signed size_t 调用成功时返回所写入的字节数(若为零则表示没有写入数据).错误时返回-1,并置errno为相应值. 若count为零,对于普通文件无任何影响,但对特殊文件 将产生不可预料的后果. |
fread & read |
||
| 接口名 | fread() | read() |
| 原型 | size_t fread(void * ptr,size_t size, size_t count,FILE * stream) | ssize_t read(int fd, void *buf, size_t count) |
| 参数含义 | ptr:指向大小至少为(size乘count)个字节的内存块的指针,该内存块被转换为void * size:要读取的每个元素的大小(以字节为单位) count: 元素个数 stream: 指向指定输入流的FILE对象的指针 |
fd: 文件描述符 buf: 指向大小至少为count个字节的内存块的指针, 该内存块被转换为void * count :需要读取的字节个数 |
| 功能/ 返回值 |
从stream所指向的文件位置处,读取count个size字节数的数据,从ptr所指内存位置处开始向后存放. 返回成功读取的元素总数. 如果此数字与count参数不同, 则在读取时发生读取错误或到达文件末尾. 在这两种情况下,都设置了适当的指示符, 可以分别使用ferror和feof进行检查. |
从文件描述符fd中读取count字节的数据并放入从buf开始的缓冲区中.如果 count为零,read()返回0,不执行其他任何操作.如果 count 大于SSIZE_MAX(ssize_t的最大值), 那么结果将不可预料. 成功时返回读取到的字节数, 此返回值受文件剩余字节数限制.当返回值小于指定的字节数时并不意味着错误;这可能是因为当前可读取的字节数小于指定的字节数(比如已经接近文件结尾,或者正在从管道或者终端读取数据,或者 read()被信号中断). 发生错误时返回-1,并置errno 为相应值.在这种情况下无法得知文件偏移位置是否有变化 . |
fleek & leek |
||
| 接口名 | fseek() | lseek() |
| 原型 | int fseek ( FILE * stream, long int offset, int origin ) | off_t lseek(int fd, off_t offset, int whence) |
| 参数含义 | stream:文件流指针 offset :偏移量 origin :起始位置 |
fd: 文件描述符 offset: 偏移量 whence :起始位置 |
| 功能/ 返回值 |
将与流关联的位置指示器设置为新位置 具体为, 从起始点origin开始往前或往后偏移offset个字节 |
将与文件描述符fd相关联的打开文件的偏移量重新定位 |
| 起始点 | 名字 | 用数字代表 |
|---|---|---|
| 文件开始位置 | SEEK_SET | 0 |
| 文件当前位置 | SEEK_CUR | 1 |
| 文件末尾位置 | SEEK_END | 2 |
| 示例 | fseek(fp,100L,0)(或fseek(fp,100L,SEEK_SET)) 表示将文件位置标记从文件开头往文件末尾方向移动100个字节 fseek(fp,50L,1); (或fseek(fp,50L,SEEK_CUR)) 表示将文件位置标记从当前位置往文件末尾方向移动50个字节 fseek(fp,-10L,2); (或fseek(fp,-10L,SEEK_END)) 表示将文件位置标记从文件末尾往文件开头方向移动10个字节 |
lseek(fd,100L,0)(或lseek(fd,100L,SEEK_SET)) 表示将文件位置标记从文件开头往文件末尾方向移动100个字节 lseek(fd,50L,1); (或lseek(fd,50L,SEEK_CUR)) 表示将文件位置标记从当前位置往文件末尾方向移动50个字节 lseek(fd,-10L,2); (或lseek(fd,-10L,SEEK_END)) 表示将文件位置标记从文件末尾往文件开头方向移动10个字节 |
stdin & stdout & strerr
C中每个被使用的文件(打开的文件)都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件
状态及文件当前的位置等 ). 这些信息是保存在一个结构体变量中的. 这个结构体类型是在C库中声明的,取名FILE.
C中默认会打开三个标准输入输出流, 分别是标准输入, 标准输出, 标准错误(也就是三个FILE结构体). 各自都对应一个流指针, 分别
是stdin(标准输入流指针), stdout(标准输出流指针), strerr(标准错误流指针) . 其类型都是FILE*
这是对于语言层面的对文件的管理描述, 其底层仍然是利用系统内核对文件的管理 .
更多C语言IO操作另一篇有写, 戳链接 ( ̄︶ ̄)↗https://blog.csdn.net/qq_41071068/article/details/92579777
但我们可以发现, C的库函数中我们用文件流指针来操作控制文件, 但Linux下的系统调用接口用的却是int 型的变量, 我们将Linux
下的这个整型变量称之为文件描述符
文件描述符fd
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数. 打开现存文件或新建文件时,内核
会返回一个文件描述符. 读写文件也需要使用文件描述符来指定待读写的文件 .
文件描述符具体就是, 内核中的 files_struct* file这个数组指针所指向的数组的下标(也解释了为什么文件描述符是非负数), 进
程通过这个下标找到具体的struct file.
struct file(file结构体)
struct file描述的是一个打开的文件, 系统中每个打开的文件在内核空间都有一个与之关联的 struct file .它由内核在打开文件
时创建,并传递给在文件上进行操作的函数. 在文件的所有实例都关闭后,内核释放这个数据结构.
struct file在include/linux/fs.h中定义如下
struct file {
struct list_head f_list; /*所有打开的文件形成一个链表*/
struct dentry *f_dentry; /*指向相关目录项的指针*/
struct vfsmount *f_vfsmnt; /*指向VFS安装点的指针*/
struct file_operations *f_op; /*指向文件操作表的指针*/
mode_t f_mode; /*文件的打开模式*/
loff_t f_pos; /*文件的当前位置*/
unsigned short f_flags; /*打开文件时所指定的标志*/
unsigned short f_count; /*使用该结构的进程数*/
unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin;
/*预读标志、要预读的最多页面数、上次预读后的文件指针、预读的字节数以及预读的页面数*/
int f_owner; /* 通过信号进行异步I/O数据的传送*/
unsigned int f_uid, f_gid; /*用户的UID和GID*/
int f_error; /*网络写操作的错误码*/
unsigned long f_version; /*版本号*/
void* private_data; /* tty驱动程序所需 */
};struct file中主要保存了文件位置, 此外, 还把指向该文件索引节点的指针也放在其中. struct file结构形成一个双链表,
称为系统打开文件表,其最大长度是NR_FILE,在fs.h中定义为8192 .
struct file总是存在于下面两个双向循环链表的某一个中 :
“未使用”文件对象的链表 : 该链表既可以用做struct file的内存高速缓存,又可以当作root用户的备用存储器,也就是说,即使系统的动态内存用完,也允许超级用户打开文件. 由于该链表是未使用的,它们的f_count 为 0,该链表首元素的地址存放在变量free_list中,内核必须确认该链表总是至少包含NR_RESERVED_FILES个对象,通常该值设为10。
“正在使用”文件对的象链表:该链表中的每个元素至少由一个进程使用,因此,各个元素的f_count不会为0,该链表中第一个元素的地址存放在变量anon_list中.
一个进程打开一个文件或创建一个文件, 内核会创建一个struct file, 将其地址存放在task_struct(PCB)中的成员files_struct结构体
中的成员struct file* fd_array[ ] 这个数组中, 并返回存放位置的下标 (, 有点绕口, 如下图所示)
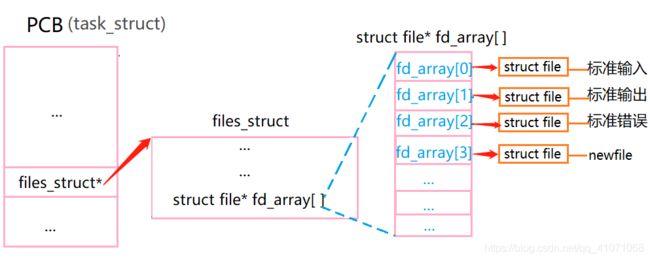
open()返回的就是struct file* fd_array数组的下标, 内核新创建的struct file地址放在fd_array数组的哪个位置, 就返回这个元素的下
标. 其他的系统调用接口也都是用这个fd(文件描述符)找到文件对应的struct file, 然后再操作或管理文件.
struct files_struct
每个进程用一个files_struct结构来记录文件描述符的使用情况, 这个files_struct结构称为用户打开文件表,它是进程的私有
数据, 是task_struct中的一员.
files_struct在include/linux/sched.h中定义如下
struct files_struct {
atomic_t count; /* 共享该表的进程数 */
rwlock_t file_lock; /* 保护以下的所有域,以免在tsk->alloc_lock中的嵌套*/
int max_fds; /*当前文件对象的最大数*/
int max_fdset; /*当前文件描述符的最大数*/
int next_fd; /*已分配的文件描述符加1*/
struct file ** fd; /* 指向文件对象指针数组的指针 */
fd_set *close_on_exec; /*指向执行exec( )时需要关闭的文件描述符*/
fd_set *open_fds; /*指向打开文件描述符的指针*/
fd_set close_on_exec_init;/* 执行exec( )时需要关闭的文件描述符的初 值集合*/
fd_set open_fds_init; /*文件描述符的初值集合*/
struct file * fd_array[32];/* 文件对象指针的初始化数组*/
};fd是用来获取struct file* fd_array[ ]元素的. 该数组的长度存放在max_fds中. 通常fd_array[ ]包括32个元素. 如果进程打开的
文件数目多于32, 内核就分配一个新的, 更大的数组. 内核同时也更新max_fds域的值 .
0 & 1 & 2
对于在fd_array数组中的每个元素来说, 数组的下标就是文件描述符fd. 通常,数组的第一个元素(下标为0)是进程的标准输
入文件. 数组的第二个元素(下标为1), 是进程的标准输出文件. 数组的第三个元素(下标为2), 是进程的标准错误文件.
Linux中进程默认会有3个缺省打开的文件描述符, 也就是上面刚说的, 各自对应的文件描述符为, 标准输入0, 标准输出1, 标准错误2 .
注意 : 借助于dup() 等系统调用(后面说),可以让两个文件描述符指向同一个打开的文件, 也就是说, fd_array[ ]数组的两个元素可能指向同一个struct file . 当用户在Shell中输入(如2>&1)(重定向, 后面说)时, 可以将标准错误文件重定向到标准输出文件上, 用户错误信息就可以直接打印到屏幕上
文件流指针与文件描述符
C语言中用FILE结构体来描述管理文件, 在Linux下的FILE其实是对文件描述符的进一步封装, 每个FILE里都有一个文件描述
符, FILE中还新加了一块I/O缓冲区.
为什么要对文件描述符进行封装了 ?
一. 不是每一种操作系统管理文件都是用文件描述符来操作的, 所以FILE在不同系统下的实现不同, 但库函数对外接口与功能
要保持一致, FILE就只能在不同系统中实现对不同方式"文件管理方式"的不同的封装.
二. 增加IO效率, Linux下的系统调用本身是没有I/O缓冲区的, 有能带来什么好处呢. 答案是可以尽可能减少使用read和write
系统调用的次数,从而提高I/O效率. (打个比方, 总共有100个数据, 来一个数据读一次, 和每来十个数据一次读十个, 两种方
式调用read的次数为100次和10次, 效率可想而知)
通过下面代码就可以看到
#include
#include
#include
int main(){
fwrite("fwrite() ", 1, 10, stdout);
write(2, "write() ", 9);
exit(0);
}

可以看到, 输出顺序竟然反了, 这是怎么回事呢, 这是因为, fwrite()要输出的"fwrite() "写入了缓冲区, 在缓冲区没有刷新之前是不会写入标准输出文件中的, 也就是不会打印到屏幕上, 直到运行到exit(), 进程退出, exit()会刷新缓冲区, 此时才打印"fwrite() " .
而write() 并不会将数据写入缓冲区, 而是会直接写入到标准输出文件中, 直接打印到屏幕. 所以write() 在前, fwrite(), 在后.
#include
#include
#include
int main(){
fwrite("fwrite() ", 1, 10, stdout);
write(2, "write() ", 9);
_exit(0);
}

而当代码中的exit()换成_exit()后, 没有打印"fwrite() ", 这是因为_exit()在退出时不会刷新缓冲区, 所以"fwrite() "并没有写入标准输出中, 也就无法打印到屏幕.
这样就可以看到, Linux中的C库中的FILE封装文件描述符后, 为了IO效率, 新增了一块缓冲区.
文件描述符的分配规则
当某个进程打开或创建一个文件时, 内核会创建一个struct file, 在其files_struct数组当中,找到当前没有被使用的最小的下
标,作为新的文件描述符, 并在这个位置存放新的struct file的地址.
以下面代码为例
#include
#include
#include
int main(){
int fd1 = open("myfile.txt", O_RDONLY);
int fd2 = open("myfile2.txt", O_RDONLY);
if(fd1 < 0 && fd2 < 0){
perror("open");
return -1;
}
printf("fd1:%d\n", fd1);
printf("fd2:%d\n", fd2);
close(fd1);
close(fd2);
return 0;
} 
因为, Linux下进程会默认打开标准输入, 标准输出, 标准错误, 下标为0, 1, 2位置已经存这三个文件的struct file的地址 .所以最小未
使用的依次为3, 4 .
再用下面代码进一步验证.
#include
#include
#include
int main(){
close(0);
close(2);
int fd1 = open("myfile.txt", O_RDONLY);
int fd2 = open("myfile2.txt", O_RDONLY);
if(fd1 < 0 && fd2 < 0){
perror("open");
return -1;
}
printf("fd1:%d\n", fd1);
printf("fd2:%d\n", fd2);
close(fd1);
close(fd2);
return 0;
} 
当程序一开始就关闭了标准输入和标准错误, 所以最小未使用两个的下标成了刚开始就关闭的0和2 .
重定向
来看下面代码
#include
#include
#include
int main(){
close(1);
int fd = open("redirect.txt", O_WRONLY | O_CREAT, 0644);
if(fd < 0){
perror("open");
return -1;
}
printf("fd:%d\n", fd);
return 0;
} 
可以看到, printf()本该将 fd:1 打印到屏幕上, 结果却没有打印到屏幕, 而是写入了redirect.txt 文件 . 原因就是前面刚说的文件描述
符分配规则, 这样就有了重定向的概念.
什么是重定向 ? 这里所说的重定向指的是输入输出重定向.
输入输出重定向, 顾名思义, 就是把输入输出重新指定方向.
即, 不使用linux默认的标准输入输出设备 获取 或 显示 信息,而是指定某个文件做为 数据来源 或者 输出对象.
在Shell中的使用
在Shell中, 直接可以命令来实现
输出重定向(常用)
其实, 上面的代码就是输出重定向 . 当close(1)关闭了标准输出后, open()将redirect.txt替补到了原来标准输出的位置出, 所以本该
打印到屏幕的东西却输出到了redirect.txt文件中.
>>(追加重定向) & >(清空重定向)
在Shell中可以直接用>> 或 >实现输出重定向, 如下 :

ench "hello" 原本是将hello打印到屏幕上, 但事实上, 输入到了hello.txt , 使用>> ,如果hello.txt不存在, 则会尝试创建, 并且>>是追
加输入, 每次都是从文件末尾输入.

>与>>的区别是> 不会追加, 而是直接覆盖输入 .
>> 和 > 默认是重定向的是标准输出,等效于 1>> 和 1> .
那么如何将标准错误重定向呢? 很简单, 在Shell中只需要2>> 和 2>

输入重定向
<< & <


输入重定向基本用不到, 因为这样做的意义不大.
那么Shell中是如何实现用<< ,< ,>>,>就实现输入输出的重定向的?
实际上Shell先把我们输入的命令, 也就是字符串进行拆分, 然后根据命令创建子进程, 在子进程中调用dup2()来实现的重定向.
dup2()系统调用
头文件 : unistd.h
原型 : int dup2(int oldfd, int newfd)
dup2()使newfd成为oldfd的副本, 必要时会先关闭newfd,但请注意以下内容:
如果oldfd不是有效的文件描述符,则调用失败,并且newfd未关闭.
如果oldfd是有效的文件描述符,并且newfd的值与oldfd相同,则dup2()不执行任何操作,并且返回newfd。
具体使用使用如下 :
open()打开时是追加打开, 则dup2()重定向后也是追加重定向, 若不是则是清空重定向. 如下
#include
#include
#include
int main(){
int fd = open("testdup2", O_CREAT | O_RDWR, 0664);//清空
//int fd = open("testdup2", O_CREAT | O_RDWR | O_APPEND, 0664);//追加
if(fd < 0){
perror("open");
return -1;
}
dup2(fd, 1);
printf("我被重定向了\n");
return 0;
} 