WBF:优化目标检测,融合过滤预测框
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
因公众号更改了推送规则,记得读完点“在看”~下次AI公园的新文章就能及时出现在您的订阅列表中
作者:Mostafa Ibrahim
编译:ronghuaiyang
导读
WBF已经成为优化目标检测的SOTA了。

目标检测是计算机视觉中最常见、最有趣的任务之一。最近的SOTA模型,如YOLOv5和EfficientDet,令人印象深刻。本文将介绍一种新的SOTA新技术,称为加权框融合,它优化了一个很大的目标检测问题。这是一种先进的目标检测技术,我是在当前的VinBigData Kaggle比赛中遇到它的。
如果你熟悉目标检测的工作原理,你可能知道总有一个主干CNN来提取特征。还有另一个阶段,要么生成区域建议(可能的边界框),要么过滤已经提出的建议区域。这里的主要问题是,这根本不是一个简单的任务,它实际上相当困难。这就是为什么物体检测模型要么生成很多框,要么生成的边框不够,最终导致平均精度较低的原因。已经提出了几种算法来处理这个问题,我会首先讨论一下。
如果你不感兴趣理论解释,你可以跳到最后编码教程中,我将展示如何将这种技术应用到一个非常具有挑战性的数据集上,我一直在努力的VinBigData。
给大家介绍一下背景,这个比赛是关于用x光检查肺部疾病的。你的模型必须能够区分14种不同的疾病,并且对每种疾病预测出疾病所在的边界框。这变得更加困难,因为每个图像可能有不止一种疾病(因此你必须预测多个不同的边界框)。
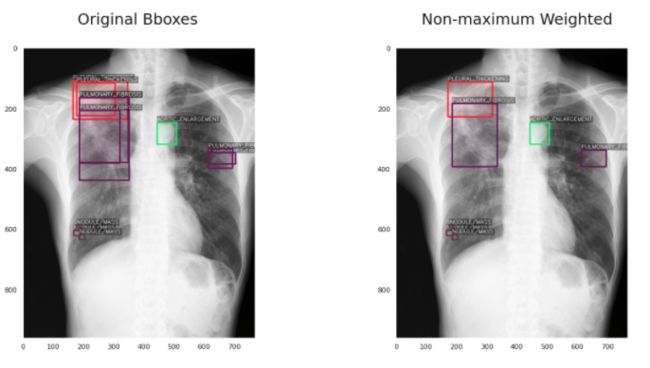
第一个问题是,这些疾病是由多个不同的放射科医生标记的,对于同一种异常可能有多个不同的边界框。所以我们必须过滤这些(或者在本例中“融合”它们),以避免混淆我们的模型。
第二个问题是一些密集疾病区域包含多个标签,这意味着一个小的包围框可以有多个疾病标签。如果我们使用像NMS这样的东西,会很困难,因为我们是根据IoU过滤框。因此,像NMS这样的方法很可能会删除有用的框。
注意,所有这些技术都可以以两种方式使用。要么对数据进行预处理,以过滤掉不精确标记的边界框(这就是我在这里将要做的),要么过滤掉你为提高准确性而训练的模型预测的边界框(或两者兼用)。
我将讨论每一种技术,包括使用该技术之前和之后的边界框的可视化。
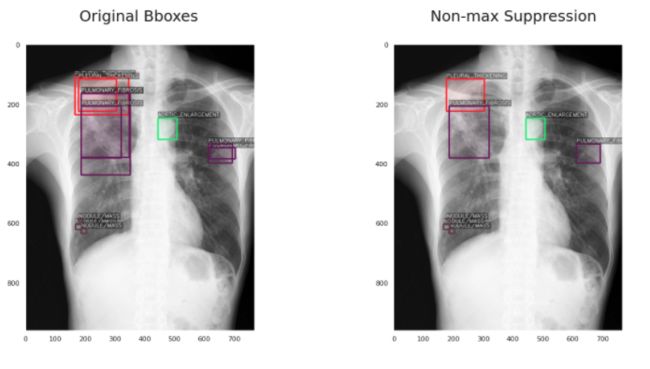
1、非极大值抑制(NMS)
如果你熟悉目标检测,那么你可能听说过NMS。考虑到目标检测模型的每次预测都由包围框坐标、类标签和置信分数组成,NMS的工作如下:
如果框与框的IoU高于指定的阈值参数,则这些框将被过滤为1个框。IoU本质上是两个框之间的重叠量。
这里的主要挑战是,如果这些物体靠的很近,其中一个将被过滤掉(因为IoU将相当高)。

2、Soft-NMS
第二种方法试图通过一种更“soft”的方法来解决NMS的主要问题。它不会完全移除那些IoU高于阈值的框,而是根据IoU的值降低它们的置信度分数。
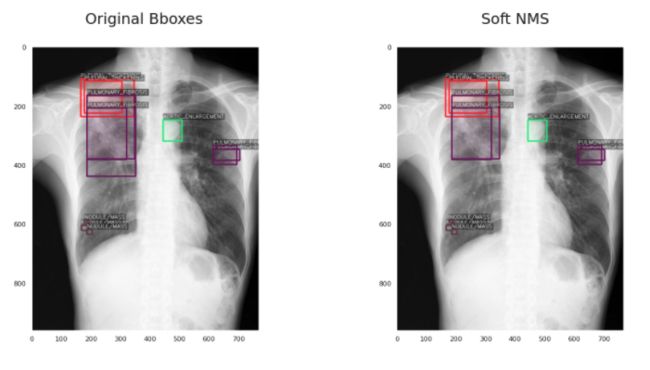
“Soft”方法导致过滤掉更少的框(这就是为什么与NMS相比,右边的框更多)。
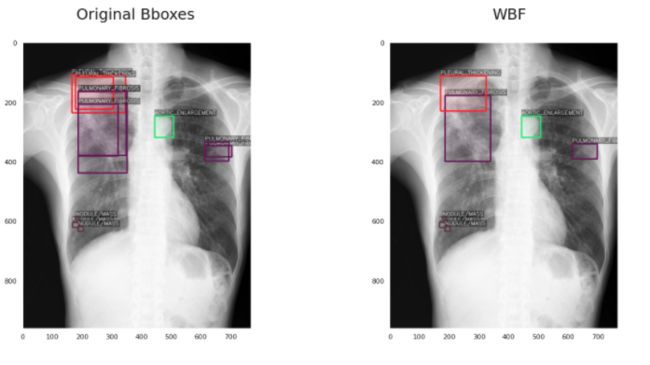
3、加权框融合 (WBF)
WBF算法的工作方式与NMS不同。它有点长,而且确实涉及到很多数学方程,但我将尽我最大的努力给你一个简单的概述,而不是让你厌烦的细节。
首先,它将所有边界框按照置信度分数的递减顺序进行排序。然后,它生成另一个可能的框“融合”(组合)列表,并尝试检查这些融合是否与原始框匹配。它通过检查IoU是否大于指定的阈值(hyperparameter)来实现这一点。
然后,它使用一个公式来调整坐标和框列表中所有框的置信度分数。新的置信度仅仅是它被融合的所有框的平均置信度。新坐标以类似的方式融合(平均),除了坐标是加权的(意味着不是每个框在最终融合的框中都有相同的贡献)。权重的值由置信度决定,这是有意义的,因为较低的置信度可能表明预测不正确。
当然,这是高层次的,如果你想深入研究数学和低层次的细节,我建议你查看这篇论文:https://arxiv.org/abs/1910.13302。然而,公平地说,当我理解某些东西如何在高层次上工作,实现它,测试它,然后只有在需要时才回到底层细节时,我通常会获得最大的价值。如果你总是钻研低层次的细节,你最终会了解到理论是如何工作的,但却无法真正实现其中的大部分。
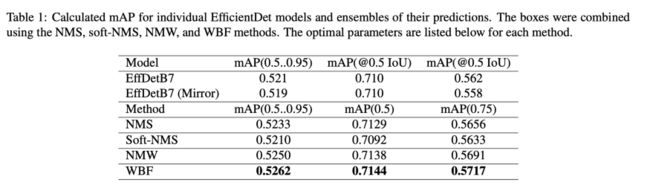
值得一提的是,还有第四种方法称为非最大加权融合,它的工作方式与WBF类似,但性能不如WBF。这是因为它不会改变方框的置信值,而是使用IoU值来衡量方框,而不是更精确的度量,即置信值。他们的表现相当接近:
代码部分
理论部分已经讲够了,让我们开始写代码吧,衡量这篇论文是否真的好,最好的方法之一就是看看他们是否发布了高质量的代码,在这种情况下,他们确实发布了。你可以在https://github.com/ZFTurbo/Weighted-Boxes-Fusion上查看它。
它们提供了一个易于使用的库。下面是一个例子:
boxes, scores, labels = weighted_boxes_fusion(boxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
如果你想尝试其他方法,你可以将“weighted_boxes_fusion”替换为“nms”或“soft_nms”,或“non_maxmimum_weighted”,它会工作得很好。我发现这个库/技术的最初原因是,在Kaggle的VinBigData竞赛中,数据集存在两个主要问题,导致物体检测模型性能不佳。
原来的数据包括边界框,每个图像的标签。所以这些将是上面WBF函数输入的一部分
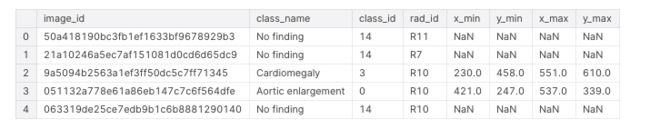
因为我们将在这里使用它进行预处理,所以我们可以将“权重”和“得分”设置为1,这样每个框都将被平等对待(因为我们还没有预测)。这个库非常简单,只需要一行代码,传入一个边界框和分数列表,然后返回一个更干净的列表。
![]()
—END—
英文原文:https://towardsdatascience.com/wbf-optimizing-object-detection-fusing-filtering-predicted-boxes-7dc5c02ca6d3

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!