它来了,Python常见面试题汇总
最近有一些小伙伴私聊我,叫我收集一些Python 面试题,所有今天这里整理的面试题,题目主要来源于网络搜集,答案根据自己实践整理修改。下面整理的面试问题是无序的。
Python 2 和 Python 3 有哪些区别?
许多Python初学者都在想应该从哪个版本的Python开始。 我对这个问题的回答通常是“仅需使用您喜欢的教程所写的版本,并在以后查看差异”。
但是,如果您要开始一个新项目并可以选择,该怎么办? 我要说的是,只要Python 2.7.x和Python 3.x都支持您计划使用的库,那么目前就没有“对”或“错”。 但是,值得一看的是这两个最受欢迎的Python版本之间的主要区别,以避免在为其中任何一个编写代码或计划移植项目时避免常见的陷阱。
可以参考篇文章https://sebastianraschka.com/Articles/2014_python_2_3_key_diff.html
Python有哪些特点和优点?
作为一门编程入门语言,Python主要有以下特点和优点:
可解释
具有动态特性
面向对象
简明简单
开源
具有强大的社区支持
当然,实际上Python的优点远不止如此。
请说一说 __ init __ 和 __ new __区别
__ init __ 只是单纯的对实例进行某些属性的初始化,以及执行一些需要在新建对象时的必要自定义操作,无返回值。
而 __ new __ 返回的是用户创建的实例,这个才是真正用来创建实例的,所以 __ new __ 是在 __ init __ 之前执行的,先创建再初始化。
列表(list)和元组(tuple)有什么区别?
1、列表是可变的。创建后可以对其进行修改。
2、元组是不可变的。元组一旦创建,就不能对其进行更改。
3、列表表示的是顺序。它们是有序序列,通常是同一类型的对象。比如说按创建日期排序的所有用户名,如[“Zhangsan”, “Lisi”, “Wangwu”]。
4、元组表示的是结构。可以用来存储不同数据类型的元素。比如内存中的数据库记录,如(2, “Lisi”, “2020–04–16”)(#id, 名称,创建日期)。
你会对你的项目写测试么?用哪些方法哪些库?
- doctest
在 Python 的官方文档中,对 doctest 的介绍是这样的,doctest 模块会搜索那些看起来像交互式会话的 Python 代码片段,然后尝试执行并验证结果
- pytest
pytest是一个成熟的全功能的Python测试工具,可以帮助你写出更好的程序。适合从简单的单元到复杂的功能测试
- unitest
unittest是 Python 自带的单元测试框架,用于编写和运行可重复的测试。
“is”和“==”有什么区别?
“is”用来检查对象的标识(id),而“==”用来检查两个对象是否相等。可以看看个例子
a = [10,20,30]
b = a
c = [10,20,30]
#检查是否相等
print(a == b)
print(a == c)
#检测是否具有相同的标识
print(a is b)
print(a is c)
#打印id
print(id(a))
print(id(b))
print(id(c))
运行结果:
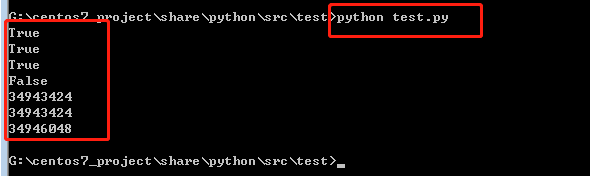
我们通过打印他们的对象标识(id)。验证了c和a和b具有不同的标识(id)。
连接字符串都有哪些方式?
格式化字符连接(%s)
format
join
+
fstring
解释range函数
range()是python内置函数它能返回一系列连续增加的整数,它的工作方式类似于分片,可以生成一个列表对象。
range函数大多数时常出现在for循环中,在for循环中可做为索引使用。其实它也可以出现在任何需要整数列表的环境中,
在python 3.0中range函数是一个迭代器。range()函数内只有一个参数,则表示会产生从0开始计数的整数列表:
函数语法:
range(start, stop[, step])
range(stop)
range(start, stop)
参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
x = 'playpython'
for i in x:
print(f'[string]={i}')
for i in range(len(x)):
print(f'{x[i]}')
运行结果:

回调函数,如何通信的?
回调函数是把函数的指针(地址)作为参数传递给另一个函数,将整个函数当作一个对象,赋值给调用的函数。
Python中的作用域
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定的。
当 Python 遇到一个变量的话他会按照这样的顺序进行搜索:
本地作用域(Local)→当前作用域被嵌入的本地作用域(Enclosing locals)→全局/模块作用域(Global)→内置作用域(Built-in)
生成器是什么?
在Python这门语言中,生成器毫无疑问是最有用的特性之一。在其他主流语言里面没有生成器的概念。
Python使用生成器对延迟操作提供了支持。所谓延迟操作,是指在需要的时候才产生结果,而不是立即产生结果。这也是生成器的主要好处。
可以参考:https://www.zhihu.com/question/2082933
字典和JSON有什么区别?
dict是Python的一种数据类型,是经过索引但无序的键和值的集合。
JSON只是一个遵循指定格式的字符串,用于传输数据。
Python中的实例方法、静态方法和类方法有什么区别?
- 实例方法
接受self参数,并且与类的特定实例相关。
- 静态方法
使用装饰器 @staticmethod,与特定实例无关,并且是自包含的(不能修改类或实例的属性)。
- 类方法
接受cls参数,并且可以修改类本身。
直接上代码:
class MyClass(object):
# 实例方法
def instance_method(self):
print('instance method called', self)
# 类方法
@classmethod
def class_method(cls):
print('class method called', cls)
# 静态方法
@staticmethod
def static_method():
print('static method called')
if __name__ == '__main__':
my_class = MyClass() # 实例化
my_class.instance_method() # 实例方法
my_class.class_method() # 类方法
my_class.static_method() # 静态方法
述MyClass类中分别定义了三种不同类型的方法:
实例方法是一个普通的函数,类方法和静态方法都是通过函数装饰器的方式实现的;
实例方法需要传入self,类方法需要传入cls参数,静态方法无需传入self参数或者是cls参数(但不等同于不能传入参数)
编写函数的4个原则
1、函数设计要尽量短小
2、函数声明要做到合理、简单、易于使用
3、函数参数设计应该考虑向下兼容
4、一个函数只做一件事情,尽量保证函数语句粒度的一致性
json数据如何提取
python中内置了json模块,提供了dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。然后再对数据用递归,正则,或者一层一层获取的方法得到数据。
动态加载的数据如何提取
模拟ajax请求,返回json形式的数据。
解释filter函数的工作原理
filter用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
tmplist = filter(is_sqr, range(1, 101))
newlist = list(tmplist)
print(newlist)
运行结果:

Python 中sorted 函数内部是什么算法?
在 官方文档 里面有提到,用的是 Timsort 算法
也可以参考这篇文章:https://www.cnblogs.com/clement-jiao/articles/9243066.html
Python值调用还是引用调用?
不可变对象(如字符串、数字和元组等)是按值调用的。请注意下面的例子,当在函数内部修改时,name的值在函数外部不会发生变化。name的值已分配给内存中该函数作用域的新块。
name = 'ming'
def add_value(s):
s += 'er'
print(s)
add_value(name)
print(name)
运行结果:

可变对象(如列表等)是通过引用调用的。来看看个例子:
value = [10,20]
def add_element(seq):
seq.append(30)
print(seq)
add_element(value)
print(value)
运行结果:

举出几个可变和不可变对象的例子?
不可变意味着创建后不能修改状态。例如:int、float、bool、string和tuple。
可变意味着可以在创建后修改状态。例如列表(list)、字典(dict)和集合(set)。
python列表(list)中的del,remove,和pop的区别
- remove
remove接受的是列表中的数,在原列表从左到右删除第一次出现的这个数,返回值为None
li = ['a','b','c','d']
li.remove('b')
print(li)
运行结果:

- pop
pop 接受的是元素的下标,在原列表中弹出这个元素
li = ['a','b','c','d']
li.pop(2)
print(li)
运行结果:

- del
del按索引删除元素
li = ['a','b','c','d']
del li[0]
print(li)
运行结果:

remove和pop视情况使用,del操作要比前两个快。
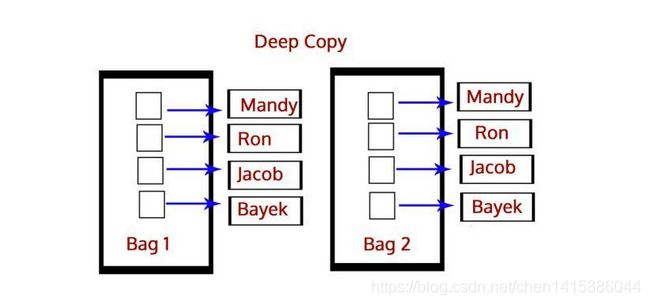
深拷贝和浅拷贝之间的区别是什么?
深拷贝就是将一个对象拷贝到另一个对象中,这意味着如果你对一个对象的拷贝做出改变时,不会影响原对象。在Python中,我们使用函数deepcopy()执行深拷贝,导入模块copy
import copy
b=copy.deepcopy(a)
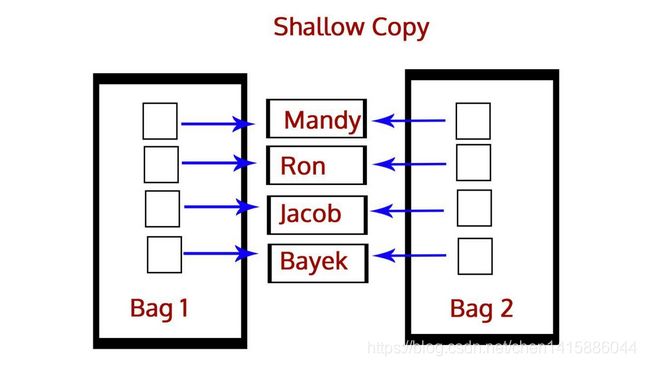
而浅拷贝则是将一个对象的引用拷贝到另一个对象上,所以如果我们在拷贝中改动,会影响到原对象。我们使用函数function()执行浅拷贝,使用如下所示:
b=copy.copy(a)
什么是lambda函数? 有什么好处?
lambda 函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数
1、lambda函数比较轻便,即用即仍,很适合需要完成一项功能,但是此功能只在此一处使用,连名字都很随意的情况下
2、匿名函数,一般用来给filter,map这样的函数式编程服务
3、作为回调函数,传递给某些应用,比如消息处理
谈谈你对多进程,多线程,以及协程的理解
- 进程
一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所有进程间数据不共享,开销大。
- 线程
cpu调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在,一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。
- 协程
是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操中栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
一个类如何继承Python的另一个类?
在下面的示例中,Audi继承自Car。继承带来了父类的实例方法。
class Car():
def drive(self):
print('vroom')
class Audi(Car):
pass
audi = Audi()
audi.drive()
运行结果:

re的match和search区别
-
match
必须字符串的开头就匹配上。
-
search
不需要字符串的开头就匹配上。匹配到结果后就返回
Python异步使用场景有那些?
异步的使用场景:
1、 不涉及共享资源,获对共享资源只读,即非互斥操作
2、 没有时序上的严格关系
3、 不需要原子操作,或可以通过其他方式控制原子性
4、 常用于IO操作等耗时操作,因为比较影响客户体验和使用性能
5、 不影响主线程逻辑
如何从列表中删除重复的元素?
可以通过将一个列表先转化为集合,然后再转化回列表来完成。
a = [1,1,1,2,3]
a = list(set(a))
print(a)
运行结果:

Python 里面怎么实现协程?
协程是一种异步执行方式。使用python yield来实现。
如果你还要深入询问,怎么实现,底层到底发生了什么,我可能就懵逼了。
参考:https://mp.weixin.qq.com/s/TKrb0i5fF0pJdRIgGC9qQQ?
类中的“self”指的是什么?
“self”引用类本身的实例。这就是我们赋予方法访问权限并且能够更新方法所属对象的能力。
下面,将self传递给__init__(),使我们能够在初始化时设置实例的颜色。
class Shirt:
def __init__(self, color):
self.color = color
s = Shirt('yellow')
print(s.color)
运行结果:

列表和数组有什么区别?
注意:Python的标准库有一个array(数组)对象,但在这里,我特指常用的Numpy数组。
列表存在于python的标准库中。数组由Numpy定义。
列表可以在每个索引处填充不同类型的数据。数组需要同构元素。
列表上的算术运算可从列表中添加或删除元素。数组上的算术运算按照线性代数方式工作。
列表还使用更少的内存,并显著具有更多的功能。
什么是多线程竞争?
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态即:数据几乎同步会被多个线程占用,造成数据混乱,即所谓的线程不安全
那么怎么解决多线程竞争问题?—锁
- 锁的好处
确保了某段关键代码(共享数据资源)只能由一个线程从头到尾完整地执行能解决多线程资源竞争下的原子操作问题。
- 锁的坏处
阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
- 锁的致命问题
死锁
什么是死锁?
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,互相干等着,程序无法执行下去,这就是死锁。
什么是负索引?
我们先创建这样一个列表:
mylist=[0,1,2,3,4,5,6,7,8]
负索引和正索引不同,它是从右边开始检索。
mylist=[0,1,2,3,4,5,6,7,8]
print(mylist[-3])
运行结果:

pass、continue和break之间有什么区别?
- pass
pass意味着什么都不做。我们之所以通常使用它,是因为Python不允许在没有代码的情况下创建类、函数或if语句。
在下面的例子中,如果在i>3中没有代码的话,就会抛出一个错误,因此我们使用pass。
a = [1,2,3,4,5]
for i in a:
if i > 3:
pass
print(i)
运行结果:

- continue
continue会继续到下一个元素并停止当前元素的执行。所以当i<3时,永远不会达到print(i)。
a = [1,2,3,4,5]
for i in a:
if i < 3:
continue
print(i)
运行结果:

- break
break会中断循环,序列不再重复下去。所以不会被打印3以后的元素。
a = [1,2,3,4,5]
for i in a:
if i == 3:
break
print(i)
运行结果:

append和extend有什么区别?
append将一个值添加到一个列表中,而extend将另一个列表的值添加到一个列表中。来看看例子:
a = [1,2,3]
b = [1,2,3]
a.append(6)
print(a)
b.extend([4,5])
print(b)
运行结果:

字典和列表的查找速度哪个更快?
在列表中查找一个值需要O(n)时间,因为需要遍历整个列表,直到找到值为止。
在字典中查找一个值只需要O(1)时间,因为它是一个哈希表。
如果有很多值,这会造成很大的时间差异,因此通常建议使用字典来提高速度。但字典也有其他限制,比如需要唯一键。
Python中的异常处理是如何进行的?
Python提供了3个关键字来处理异常,try、except和finally。
语法如下:
try:
# try to do this
except:
# if try block fails then do this
finally:
# always do this
在下面的简单示例中,try块失败,因为我们不能将字符串添加到整数中。except块设置val=10,然后finally块打印出“complete”。
try:
val = 1 + 'A'
except:
val = 10
finally:
print('complete')
print(val)
运行结果:

解释Python中的join()和split()函数
- Join()
Join()能让我们将指定字符添加至字符串中。

Split()能让我们用指定字符分割字符串。

说说下面几个概念:同步,异步,阻塞,非阻塞?
- 同步
多个任务之间有先后顺序执行,一个执行完下个才能执行。
- 异步
多个任务之间没有先后顺序,可以同时执行,有时候一个任务可能要在必要的时候获取另一个同时执行的任务的结果,这个就叫回调!
- 阻塞
如果卡住了调用者,调用者不能继续往下执行,就是说调用者阻塞了。
- 非阻塞
如果不会卡住,可以继续执行,就是说非阻塞的。同步异步相对于多任务而言,阻塞非阻塞相对于代码执行而言。
爬虫的基本流程?
1、浏览器发起请求,可能包含请求头等信息,等待服务器相应
2、获取服务器响应内容,可能是网页文本(html、json代码),图片二进制、视频二进制等
3、解析内容(正则、xpath、json解析等 )
4、 保存数据(本地文件、数据库等)
什么是爬虫,为什么要用爬虫?
用于在网络上采集数据的程序,可以用任何语言开发,python更加方便快捷高效一些。
-
爬虫的目的
采集一些需要的数据。
-
为什么python更适合写爬虫程序?
python中封装了很多爬虫库,如urllib ,re,bs,scrapy等,开发效率更高
为什么会选择redis数据库?
因为redis支持主从同步,而且数据都是缓存在内存中,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。
python * args 和 ** kwargs
用args和**kwargs只是为了方便并没有强制使用它们. 当你不确定你的函数里将要传递多少参数时你可以用args.例如,它可以传递任意数量的参数:
def print_everything(*args):
for count, thing in enumerate(args):
print('{0}. {1}'.format(count, thing))
print_everything('apple', 'banana', 'cabbage')
运行结果:

层次遍历二叉树用什么方法?
# coding: utf-8
from collections import deque
class BNode:
""" 二叉树节点 """
def __init__(self, value, left=None, right=None):
self.value = value
self.left = left
self.right = right
def level_traverse(binary_tree):
""" 层次遍历二叉树 """
stack = deque([binary_tree])
while stack:
top = stack.popleft()
print(top.value)
if top.left:
stack.append(top.left)
if top.right:
stack.append(top.right)
if __name__ == "__main__":
b_tree = BNode(1, BNode(2, BNode(4, BNode(5, BNode(7)))), BNode(3, BNode(6, right=BNode(8))))
level_traverse(b_tree)
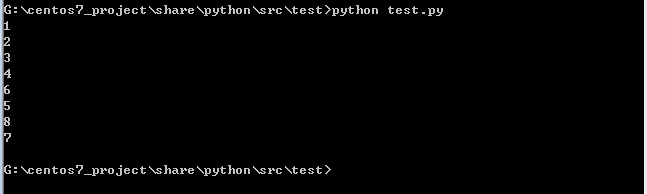
运行结果:
先,中,后序遍历二叉数。完全二叉数是什么?
完全二叉树:深度为k有n个节点的二叉树,当且仅当其中的每一节点,都可以和同样深度k的满二叉树,序号为1到n的节点一对一对应时,称为“完全二叉树”。(摘自维基百科)
先序:先根后左再右
中序:先左后中再右
后序:先左后右再根
ascii、unicode、utf-8、gbk区别
- ascii
美国信息互换标准代码
- gbk
在gb2312的基础上增加了汉字,而gb2312在ascii的基础上增加了汉字
- unicode
是字符集
- utf-8
是编码规则,是对unicode的一种实现,可以将unicode码对应再编码成1-4字节大小。
xrange和range的区别
- xrange
xrange只在Python2中有,返回的是一个可迭代对象,但并不是迭代器,因为没有实现next。
在Python3中没有xrange。
- range
在Python2中,range返回一个list。
在Python3中,range类似于Python2中的xrange,返回的是一个可迭代对象,但也并不是迭代器,因为并没有实现next。
用Python实现一个二分查找的函数
def two_search(list, value):
lindex = 0
rindex = len(list) - 1
cindex = (lindex + rindex) // 2 # / 在py3中是包括了小数部分的
res = -1
# 二分法唯一的一个问题是,当所求的数是最右边的时候,按照cindex = (lindex + rindex) / 2的方式,当cindex = lindex的时候会死循环
if list[-1] == value:
res = rindex
else:
while lindex != cindex or cindex == 0:
if value == list[cindex]:
res = cindex
break
elif value > list[cindex]:
lindex = cindex
cindex = (lindex + rindex) // 2
else:
rindex = cindex
cindex = (lindex + rindex) // 2
return res
if __name__ == '__main__':
l = [1, 2, 3, 4, 5, 6, 9, 19, 40]
print(two_search(l, 5))
运行结果:

python实现一个快排
def qsort(seq):
if seq==[]:
return []
else:
pivot=seq[0]
lesser=qsort([x for x in seq[1:] if x<pivot])
greater=qsort([x for x in seq[1:] if x>=pivot])
return lesser+[pivot]+greater
if __name__=='__main__':
seq=[5,6,78,9,0,-1,2,3,-65,12]
print(qsort(seq))
运行结果:

post 和 get的区别?
1、get是从服务器上获取数据,post是向服务器传送数据
2、在客户端,get方式在通过URL提交数据,数据在URL中可以看到,post方式,数据放置在HTML——HEADER内提交
3、对于get方式,服务器端用Request.QueryString获取变量的值,对于post方式,服务器端用Request.Form获取提交的数据
python函数重载机制?
函数重载主要是为了解决两个问题:
1、可变参数类型。
2、可变参数个数。
另外,一个基本的设计原则是,仅仅当两个函数除了参数类型和参数个数不同以外,其功能是完全相同的,此时才使用函数重载,如果两个函数的功能其实不同,那么不应当使用重载,而应当使用一个名字不同的函数。
什么是装饰器
-
特点:
不改变原函数的源代码
不改变原函数的调用 -
实现:
利用闭包、高阶函数、语法糖实现。
def wrapper(f):
def inner(*args, **kwargs):
print("before")
f()
print("after")
return inner
@wrapper
def func():
print(1)
if __name__ == '__main__':
func()
运行结果:

- 带参数的装饰器:
在wrapper外面再套一层函数来接受参数,并将wrapper方法返回。在语法糖调用的时候加上括号,并填入参数,就相当于在执行到@语法糖对应的语句之前先执行了outer(a="…")函数,而outer函数返回wrapper函数,这样在把参数通过outer(a="…")函数传递进去之后,又变成了@wrapper的形式。
def outer(a):
def wrapper(f):
def inner(*args, **kwargs):
print("before")
print("print outer's args: ", a)
f()
print("after")
return inner
return wrapper
if __name__ == '__main__':
@outer(a="outer")
def func():
print(1)
列举您使用过的python网络爬虫所用到的网络数据包
requests、urllib、urllib2、httplib
- requests
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。 - urllib
urllib库是Python中的一个功能强大、用于操作URL,并在做爬虫的时候经常要用到的库。 - urllib2
urllib2可以接受一个Request对象,并以此可以来设置一个URL的headers,但是urllib只接收一个URL。这意味着,你不能伪装你的用户代理字符串等。 - httplib
httplib 是一个使用 Python 写的支持的非常全面的 HTTP 特性的库。模拟http客户端发送get和post请求,主要用httplib模块的功能。
urllib和urllib2的区别
- urllib
urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
- urllib2
urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以伪装你的User Agent字符串等。
metaclass作用,以及应用场
- 作用:
metaclass直译为元类
metaclasss可以作为类声明时候的一个参数,可以传入我们自定义的元类
元类相当于是类的类,Python中内置的元类是type
所以所有自定义的元类都需要继承自type
- 应用场景:
可以控制类的调用,比方说当类中没有注释(doc)的时候,抛出异常之类,当类的名称命名规则不对的时候,抛出异常之类。
内存泄露是什么?如何避免?
内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
有__del__()函数的对象间的循环引用是导致内存泄露的主凶。不使用一个对象时使用: del object 来删除一个对象的引用计数就可以有效防止内存泄露问题。
通过Python扩展模块gc 来查看不能回收的对象的详细信息。
可以通过 sys.getrefcount(obj) 来获取对象的引用计数,并根据返回值是否为0来判断是否内存泄露
scrapy和scrapy-redis的区别?
- scrapy
scrapy是一个爬虫通用框架,但不支持分布式。
- scrapy-redis
scrapy-redis是为了更方便的实现scrapy分布式爬虫,而提供了一些以redis为基础的组件。
为什么 requests 请求需要带上 header?
原因是:模拟浏览器,欺骗服务器,获取和浏览器一致的内容
header 的形式:字典
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法: requests.get(url,headers=headers)
CGI和WSGI
CGI是通用网关接口,是连接web服务器和应用程序的接口,用户通过CGI来获取动态数据或文件等。 CGI程序是一个独立的程序,它可以用几乎所有语言来写,包括perl,c,lua,python等等。
WSGI, Web Server Gateway Interface,是Python应用程序或框架和Web服务器之间的一种接口,WSGI的其中一个目的就是让用户可以用统一的语言(Python)编写前后端。
总结
这里简单介绍关于Python的面试题汇总了,给出了自认为合理的答案,有些题目不错,可以从中学到点什么,答案如不妥,请指正…
还有可能我收集的这些面试题,在面试中不会出现,但是最好的准备就是平常多练习编写代码,对基本知识要牢固,肯定会有不少收获。

欢迎关注微信公众号【程序猿编码】,添加本人微信号(17865354792),回复:领取学习资料。或者回复:进入技术交流群。网盘资料有如下:
