七点人脸姿态估计_视线估计(Gaze Estimation)简介(四)-三维视线估计(通用方法)...
已完结:
T骨牛排:视线估计(Gaze Estimation)简介(一)-概述zhuanlan.zhihu.com目标:
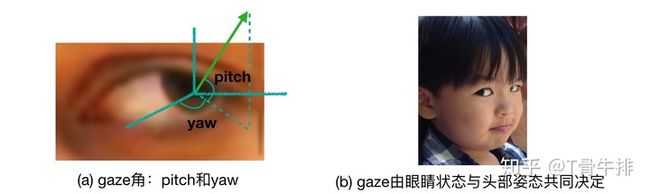
三维视线估计的目标是从眼睛图片或人脸图片中推导出人的视线方向。通常,这个视线方向是由两个角度,pitch(垂直方向)和 yaw(水平方向)来表示的,见下图a。需要注意的是,在相机坐标系下,视线的方向不仅取决于眼睛的状态(眼珠位置,眼睛开合程度等),还取决于头部姿态(见图b:虽然眼睛相对头部是斜视,但在相机坐标系下,他看的是正前方)。
评价指标:
在模型估计出pitch角和yaw角之后,可以计算出代表视线方向的三维向量,该向量与真实的方向向量(ground truth)之间的夹角即是gaze领域最常用的评价指标。
传统方法:
一般来说,视线估计方法可以分为基于几何的方法(Geometry Based Methods)和基于外观的方法(Appearance Based Methods)两大类。基于几何的方法的基本思想是检测眼睛的一些特征(例如眼角、瞳孔位置等关键点),然后根据这些特征来计算gaze。而基于外观的方法则是直接学习一个将外观映射到gaze的模型。两类方法各有长短:几何方法相对更准确,且对不同的domain表现稳定,然而这类方法对图片的质量和分辨率有很高的要求;基于外观的方法对低分辨和高噪声的图像表现更好,但模型的训练需要大量数据,并且容易对domain overfitting。随着深度学习的崛起以及大量数据集的公开,基于外观的方法越来越受到关注。
本文主要介绍近五年来利用深度学习研究gaze的工作,对之前的传统方法可能会有所提及,但不会专门介绍。在这一篇章中,我将主要介绍通用(person independent)的视线估计方法,即模型的训练数据与测试数据采集自不同的人(与之相对的是个性化视线估计,即训练数据与测试数据采集自相同的人)。按照方法所依赖的信息,我将他们分类为单眼/双眼视线估计,基于语义信息的视线估计和全脸视线估计 三类。对每一类我将会筛选两到三篇具有代表性的论文进行介绍。
单眼/双眼视线估计:
就我所知,德国马普所Xucong Zhang博士等最早尝试使用神经网络来做视线估计[1],其成果发表在CVPR 2015上。这个工作以单眼图像为输入,所使用的网络架构如下图所示。

可以看到,他们当时使用的是一个类似于LeNet的浅层架构,还称不上“深度”学习。而其中一个有启发性的贡献是,他们将头部姿态(head pose)信息与提取出的眼睛特征拼接,用以学习相机坐标系下的gaze。该工作的另一个重要贡献是提出并公开了gaze领域目前最常用的数据集之一:MPIIGaze。在MPIIGaze数据集上,该工作的误差为6.3度。
接下来,Xucong Zhang在他2017年的工作中[2],用VGG16 代替了这个浅层网络,大幅提升了模型精度,将误差缩小到了5.4度。
上面两个工作都以单眼图像为输入,没有充分利用双眼的互补信息。北航博士Yihua Cheng在ECCV 2018上提出了一个基于双眼的非对称回归方法[3]。其方法框图如下:

该工作由两个模块构成:AR-Net(非对称回归网络),以双眼为输入,经四个支路处理后得到两只眼睛的不同视线方向;E-Net(评价网络),同样以双眼为输入,输出是两个权重,用于加权AR-Net训练过程中两只眼睛视线的loss。其基本思想是,双眼中某一只眼睛可能因为一些原因(如光照原因等),更容易得到精准的视线估计,因此在AR-Net训练中应该赋予这只眼睛对应的loss更大的权重。该工作在MPIIGaze数据集上取得了5.0度的误差。
基于语义信息的视线估计:
前面提到过,基于几何的方法是通过检测眼睛特征,如关键点位置,来估计视线的。这启发了一部分工作使用额外的语义信息来帮助提升视线估计的精度。ETH博士Park等在ECCV 2018上提出了一种基于眼睛图形表示的视线估计方法[4]。

如图所示,他们通过深度网络将眼睛抽象为一个眼球图形表示来提升视线估计(这一表示相对gaze来说更具象也更易学习)。其中,眼球图形表示这一监督信号是由视线的ground truth经几何方法反推生成的。这一工作目前为止取得了在MPIIGaze上的最佳精度4.56度。另外,感兴趣的同学也可以阅读他们在ETRA 2018上的工作[5],利用眼睛关键点的heat map估计视线。方法框架如下图所示,其中眼睛关键点这一监督信息由合成数据集UnityEyes提供,这里不展开了。

我们组在2018年提出了一种基于约束模型的视线估计方法[6],其基本出发点是多任务学习的思想,即在估计gaze的同时检测眼睛关键点位置,两个任务同时学习,信息互补,可以在一定程度上得到共同提升。在我们的方法中,我们首先对眼睛关键点与视线的关系进行了统计建模。具体地,对于合成数据集UnityEyes中的一个样本,我们抽取其17个眼睛关键点与两个gaze角度,将他们展开并拼接为一个36维(17*2 + 2)的向量。然后将n个样本对应的n个向量堆叠生成一个n*36大小的矩阵,对该矩阵做PCA分解后可以得到一个mean shape和一系列deformation basis。这两个部分共同构成了一个约束模型。其中mean shape代表眼睛的平均形状以及对应的gaze平均值,而deformation basis则包含了眼睛形状与gaze的协同变化信息。约束模型的建立过程如下图所示。

对于一个输入样本,如果能学习出这个约束模型中的deformation basis系数,并与mean shape组合,就可以重建出这个样本的眼睛形状和gaze。因此我们使用的网络架构如下,网络的主要输出即约束模型的系数,用以重建眼睛的形状和gaze。另外,由于约束模型表示的眼睛形状是经过归一化操作的,网络同时学习一个缩放系数,和一个平移向量,通过几何变换(decoder)得到正确的眼睛关键点位置。网络通过优化关键点位置loss与视线loss实现end to end training。实验结果表明,我们的模型取得了比直接回归更精准的结果。

全脸视线估计:
以上视线估计方法都要求单眼/双眼图像为输入,有两个缺陷:1)需要额外的模块检测眼睛;2)需要额外的模块估计头部姿态。基于此,Xucong Zhang等于2017年提出了基于注意力机制的全脸视线估计方法[7]。

可以看到,这里注意力机制的主要思想是通过一个支路学习人脸区域各位置的权重,其目标是增大眼睛区域的权重,抑制其他与gaze无关的区域的权重。网络的输入为人脸图像并采用end to end的学习策略,直接学习出最终相机坐标系下的gaze。这一工作同时公开了全脸视线数据集MPIIFaceGaze。需要注意的是,虽然MPIIGaze与MPIIFaceGaze使用的是同一批数据,但并不是同一个数据集(许多论文把这两个数据集混淆)。首先MPIIGaze数据集并不包含全脸图片,其次MPIIFaceGaze的ground truth定义方式与MPIIGaze不同。该工作最终在MPIIFaceGaze数据集上取得了4.8度的精度。
商汤在ICCV 2017上也发表了一个全脸视线估计的工作[8]。与上面工作不同的是,除人脸输入外,该工作同时要求输入眼睛图片,如图所示。该工作主要认为工作[1]中gaze特征与head pose拼接的方式并不能准确地反映两者的的几何关系。因此,该工作提出了一个gaze的几何变换层,用于将head pose(人脸支路学习得到)与人脸坐标系下的gaze(眼睛支路学习得到)进行几何解析,得到最终相机坐标系下的gaze。该工作在自己收集的数据集上取得了4.3度的误差。

小结:
不知各位读者发现没有,在person independent(训练数据与测试数据采集自不同的人)这一设定下,上述方法的精度大都在4-5度之间徘徊,似乎很难得到进一步的提升。这个瓶颈主要是由人的眼球内部构造造成的。如果希望继续提升精度,一般要使用个性化策略。这一部分内容准备在下下一个篇章中讲解。在下一篇章中,我会简要介绍三维视线数据如何收集标注的问题,以及如何在数据集短缺的情况下,训练一个gaze模型。
[1] Zhang, X., Sugano, Y., Fritz, M., and Bulling, A. (2015). Appearance-based gaze estimation in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4511–4520
[2] Zhang, X., Sugano, Y., Fritz, M., and Bulling, A. (2017). MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), pages 1–14.
[3] Cheng, Y., Lu, F., and Zhang, X. (2018). Appearance-based gaze estimation via evaluation- guided asymmetric regression. In The European Conference on Computer Vision (ECCV).
[4] Park, S., Spurr, A., and Hilliges, O. (2018). Deep Pictorial Gaze Estimation. In European Conference on Computer Vision (ECCV), pages 741–757.
[5] Seonwook Park, Xucong Zhang, Andreas Bulling, Otmar Hilliges (2018). Learning to find eye region landmarks for remote gaze estimation in unconstrained settings. ACM Symposium on Eye Tracking Research and Applications (ETRA)
[6] Yu, Y., Liu, G., and Odobez, J.-M. (2018). Deep multitask gaze estimation with a constrained landmark-gaze model. European Conference on Computer Vision Workshop (ECCVW).
[7] Zhang, X., Sugano, Y., Fritz, M., and Bulling, A. (2016). It’s Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).
[8] Zhu, W. and Deng, H. (2017). Monocular free-head 3d gaze tracking with deep learning and geometry constraints. In The IEEE International Conference on Computer Vision (ICCV).