python xpath定位打印元素_Python+selenium web自动化

Python+Selenium自动化
以下内容都是是我的学习笔记,为方便自己查询就整理出来了,内容会精简很多,比如配置和安装插件,请自行查询操作。默认大家是有一定基础。
注:Python3版本请自行查询配置方法,以下都是在Python2版本上操作的。
好好学习,天天向上
老猪
Python版本:2.7.12
selenium版本:2.53.6
Firefox版本:45
IDE:Pycharm
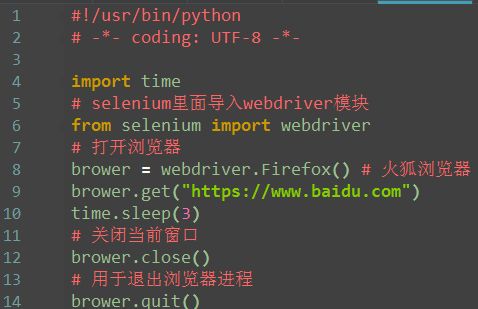
一、浏览器基本操作
打开网站
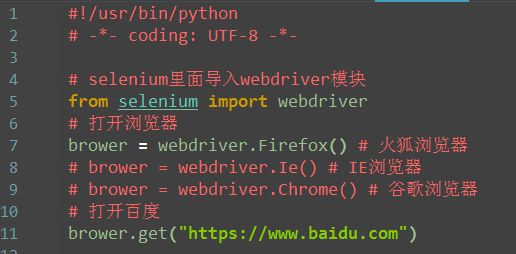
1.第一步:从selenium里面导入webdriver模块
2.打开Firefox浏览器(Ie和Chrome对应下面的)
3.打开百度网址
设置休眠
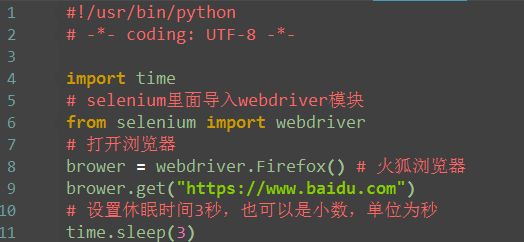
1.由于打开百度网址后,页面加载需要几秒钟,所以最好等到页面加载完成后再继续下一步操作
2.导入time模块,time模块是Python自带的,所以无需下载
3.设置等待时间,单位是秒(s),时间值可以是小数也可以是整数
页面刷新
1.有时候页面操作后,数据可能没及时同步,需要重新刷新
2.这里可以模拟刷新页面操作,相当于浏览器输入框后面的刷新按钮

前进和后退
1.当在一个浏览器打开两个页面后,想返回上一页面,相当于浏览器左上角的左箭头按钮
2.返回到上一页面后,也可以切换到下一页,相当于浏览器左上角的右箭头按钮

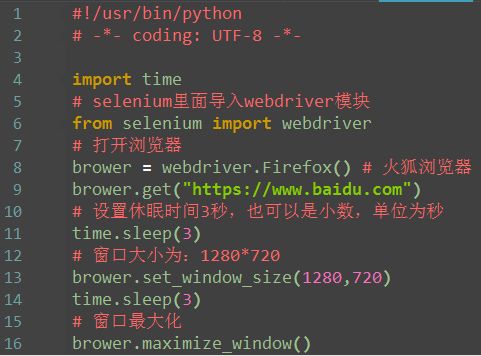
设置窗口大小
1.可以设置浏览器窗口大小,如设置窗口大小为手机分辨率540*960
2.也可以最大化窗口
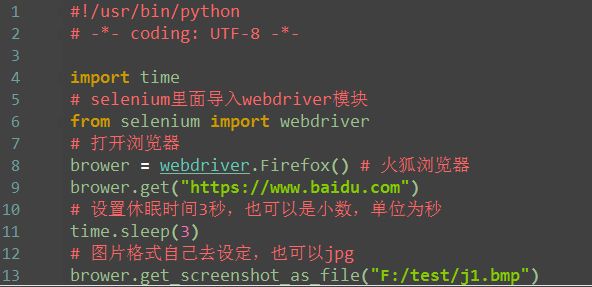
截屏
1.打开网站之后,也可以对屏幕截屏
2.截屏后设置制定的保存路径+文件名称+后缀
退出
1.退出有两种方式,一种是close;另外一种是quit
2.close用于关闭当前窗口,当打开的窗口较多时,就可以用close关闭部分窗口
3.quit用于结束进程,关闭所有的窗口
4.最后结束测试,要用quit。quit可以回收c盘的临时文件
二、元素定位
自动化只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告。本篇主要讲如何用firefox辅助工具进行元素定位。
元素定位在这四个环节中是至关重要的,如果说按学习精力分配的话,元素定位占70%;操作元素10%,获取返回结果10%;断言10%。如果一个页面上的元素不能被定位到,那后面的操作就无法继续了。接下来就来讲webdriver提供的八种基本元素定位方法。
一、环境准备:
1.浏览器选择:Firefox
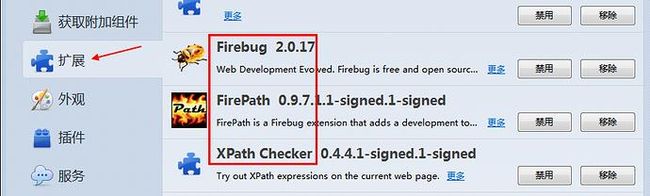
2.安装插件:Firebug和FirePath(设置》附加组件》搜索:输入插件名称》下载安装后重启浏览器)
3.安装完成后,页面右上角有个小爬虫图标
4.快速查看xpath插件:XPath Checker这个可下载,也可以不用下载
5.插件安装完成后,点开附加组件》扩展,如下图所示
selenium的webdriver提供了八种基本的元素定位方法,前面六种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。
二、查看页面元素:
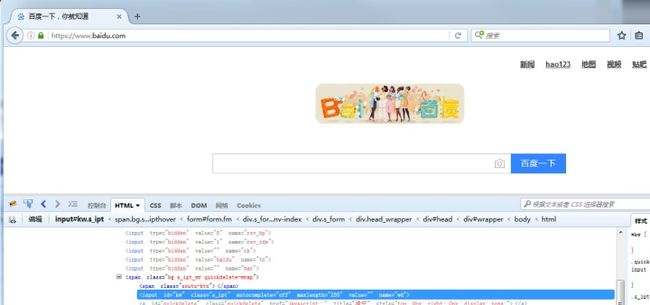
以百度搜索框为例,先打开百度网页
1.点右上角爬虫按钮
2.点左下角箭头
3.讲箭头移动到百度搜索输入框上,输入框高亮状态
4.下方蓝色区域就是单位到输入框的属性:
8种基础定位方法
id--find_element_by_id()
1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性单位到这个元素。
2.定位到搜索框后,用send_keys()方法

name--:find_element_by_name()
1.从上面定位到的元素属性中,可以看到有个name属性:name="wd",这里可以通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框

class--find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class="s_ipt",这里可以通过它的class属性定位到这个元素。
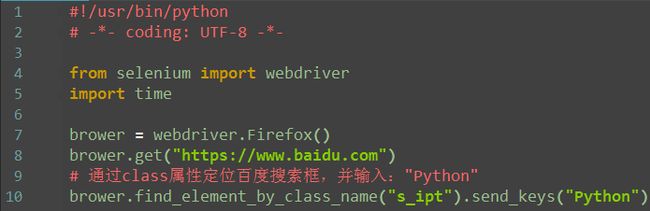
注:send_keys()是向输入框内输入字符
tag--find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错

注:send_keys()是向输入框内输入字符
link--find_element_by_link_text()
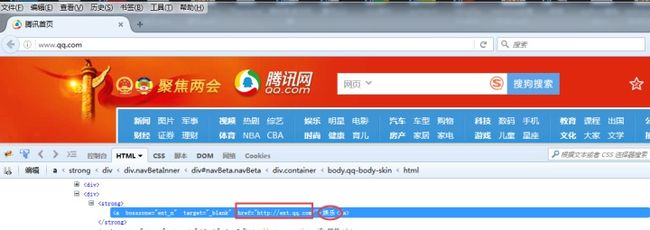
红框中为超链接,这种为文字链接,对于这种元素,我们就可以这种方法

partial_link--find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao12”也可以定位到
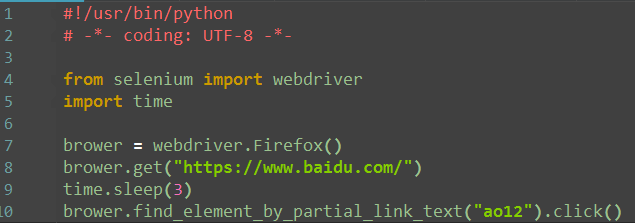
注:鼠标左键点击为:click()
xpath--find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会用工具查看一个元素的xpath

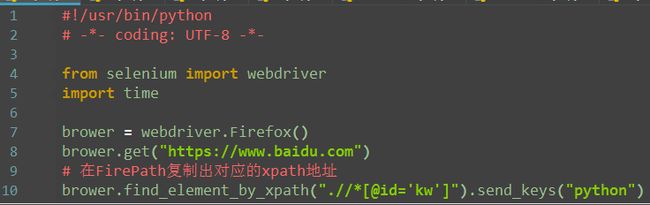
注:当前xpath定位方法是通过工具定位,更多xpath定位方法
其中kw要用单引号,避免双引号之间相互影响
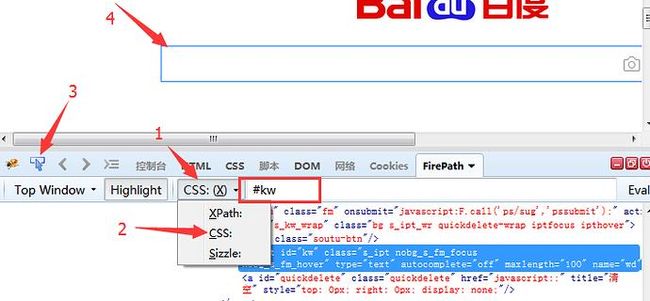
css--find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解
2.打开FirePath插件选择css
3.定位到后如下图红色区域显示

三、xptah定位

1.xpath:属性定位(id,name,class)
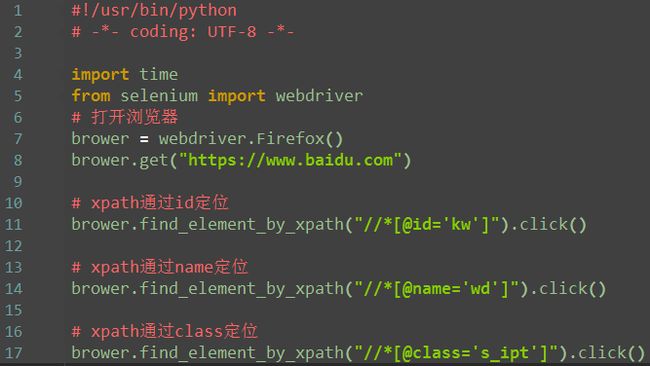
其中kw要用单引号,避免双引号之间相互影响
2.xpath:其它属性
如果一个元素id、name、class属性都没有,这时候也可以通过其它属性定位到
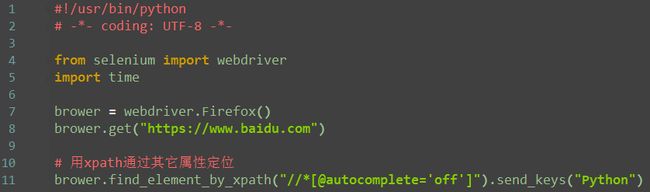
注:上面的写位总会发现*这个符号,解释往下看
3.xpath:标签
1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
2.如果不想制定标签名称,可以用*号表示任意标签
3.如果想制定具体某个标签,就可以直接写标签名称

注:就是将*替换成了input标签名
对比下图
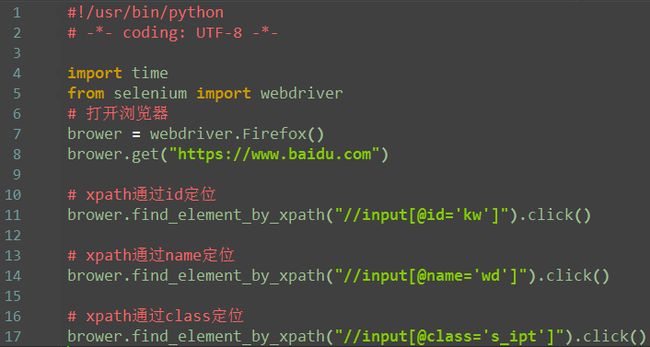
4.xpath层级
1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(图中数字1)
2.找到它老爸后,再找下个层级就能定位到了
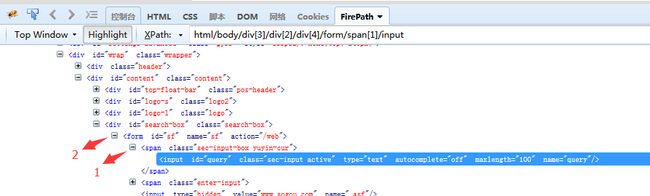
3.如上图所示,要定位的是input这个标签,它的老爸的 class="sec-input-box yuyin-cur"
4.要是它老爸的属性也不是很明显,就找它爷爷id=form(图中数字2)
5.于是就可以通过层级关系定位到

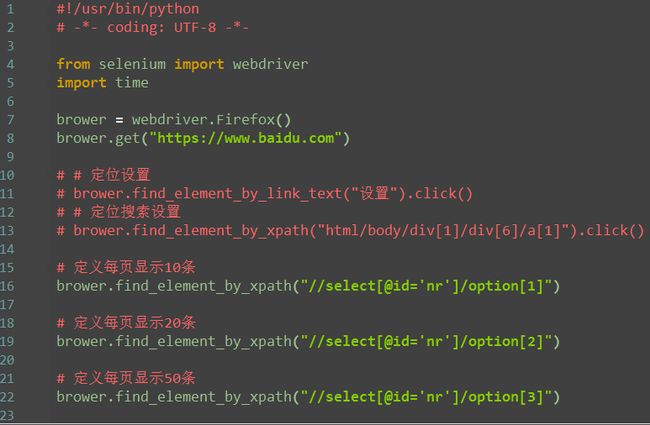
xpath索引
百度主页--设置--搜索设置
1.如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
3.如下图三胞胎兄弟

4.用xpath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)
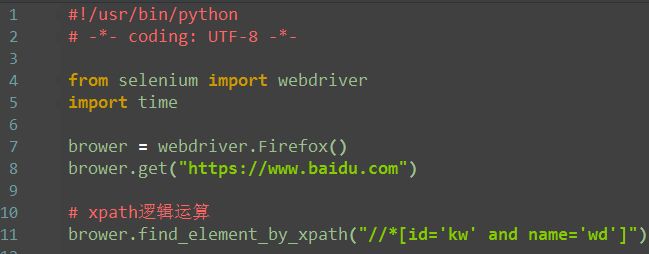
xpath逻辑
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
2.一般用的比较多的是and运算,同时满足两个属性
xpath模糊匹配
定位方法总结:18种定位方法
前8种是大家都熟悉的,经常会用到的
定位单个元素方法
- id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
# 下面两种要重点掌握其中一种,两者都会是更好的。现在我比较喜欢用xpath定位
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
具体请查看8种基础定位方法
定位一组元素方法
1.id复数定位find_elements_by_id(self, id_)
2.name复数定位find_elements_by_name(self, name)
3.class复数定位find_elements_by_class_name(self, name)
4.tag复数定位find_elements_by_tag_name(self, name)
5.link复数定位find_elements_by_link_text(self, text)
6.partial_link复数定位find_elements_by_partial_link_text(self, link_text)
7.xpath复数定位find_elements_by_xpath(self, xpath)
8.css复数定位find_elements_by_css_selector(self, css_selector)
多元素定位场景
从上面定位的元素会发现,每次都是定位一个元素,如果有多个元素它的属性是一样的,难 道要进行多次定位吗?当然不是。请看下图示例

定位多个元素
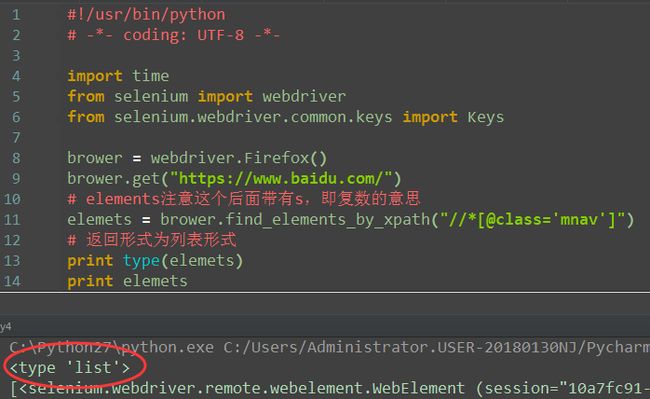
注:elements有s
对元素进行操作
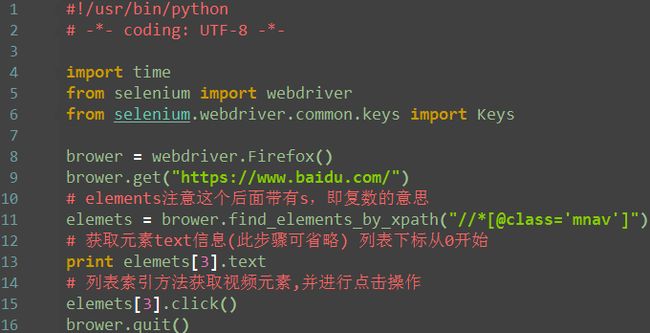
元素参数化
小伙伴可能会发现,每一种定位都有不同的写法,觉的不好太记。那有没有一种写法把这些综合成一种,即:定位方式参数化,只需维护里边的参数就可以
1.find_element(self, by='id', value=None)

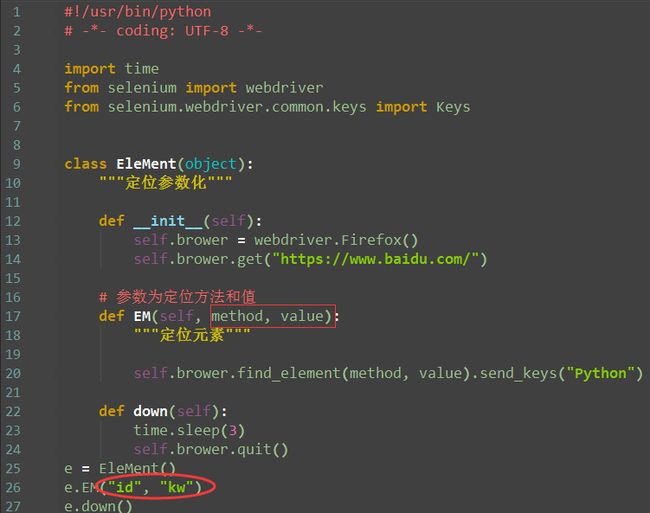
注:此时要定位元素,就不用再写各种定位方法了。只需修改红圈里边的参数值就可以了,爽不爽
2.find_elements(self, by='id', value=None)
写上同法
红圈括号内的填写规则(字符串中间是空格需注意)
by_id= "id"
by_xpath = "xpath"
by_link_text = "link text"
by_partial_text = "partial link text"
by_name = "name"
by_tag_name = "tag name" # 标签名
by_class_name = "class name"
by_css_selector = "css selector"
上图为举例说明
数据驱动
我个人的理解就是说,把自动化测试中需要用到的数据和代码分开。当我们需要用到这个数据时,直接读取里边的数据就可以。工作中常用到的文本格式有:txt、csv。假设我要搜索一组数据,进行一个简单的登录操作
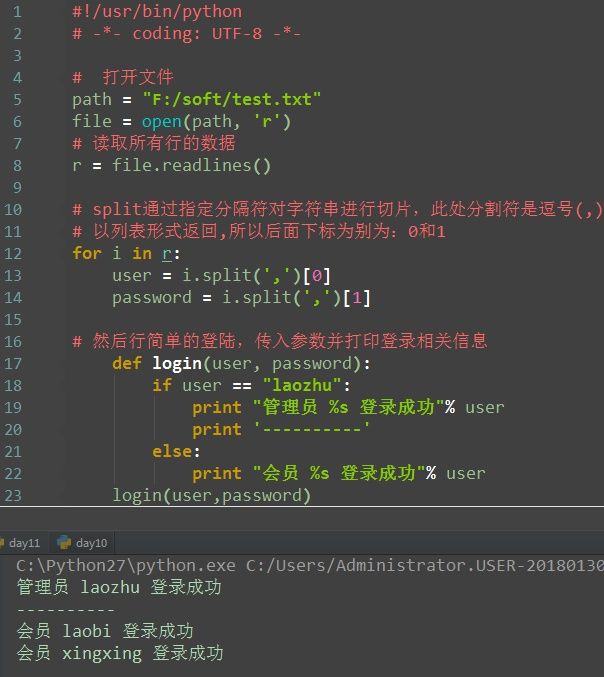
读取txt文件
txt文件内容如下
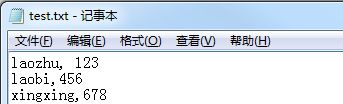
代码:
读取csv
通过wps表格或Excel创建表格,然后另存为CSV格式。注意不是直接修改文件后缀名来创建CSV文件,这样创建并非真正的CSV类型文件。
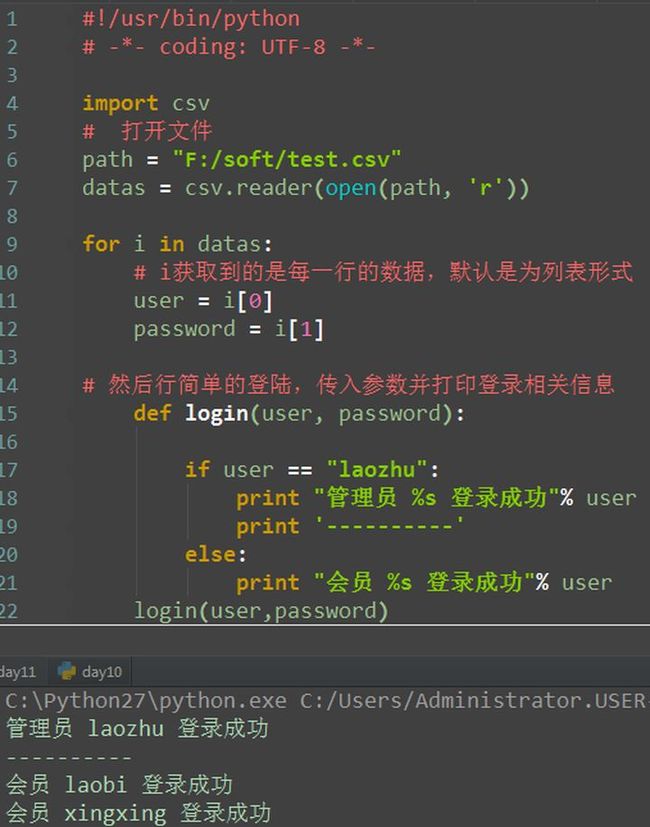
操作元素
在前面的几篇中重点介绍了一些元素的到位方法,到位到元素后,接下来就是需要操作元素了。本篇总结了web页面常用的一些操作元素方法,可以统称为行为事件。
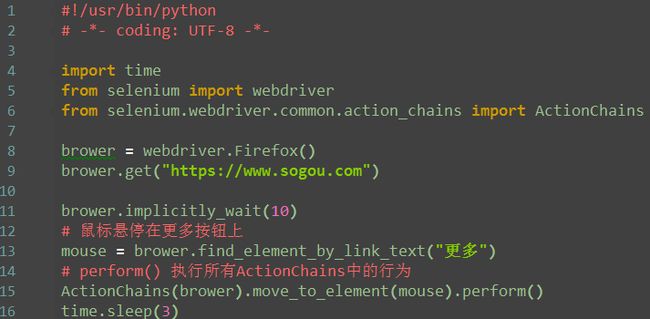
有些web界面的选项菜单需要鼠标悬停在某个元素上才能显示出来(如百度页面的设置按钮)。
1.鼠标
1.鼠标不仅仅可以点击(click),鼠标还有其它的操作,如:鼠标悬停在某个元素上,鼠标右击,鼠标按住某个按钮拖到
2.鼠标事件需要先导入模块:from selenium.webdriver.common.action_chains import ActionChains
perform() 执行所有ActionChains中的行为
鼠标悬停: move_to_element()
右击鼠标:context_click()
双击鼠标:double_click()
键盘
clear 清空
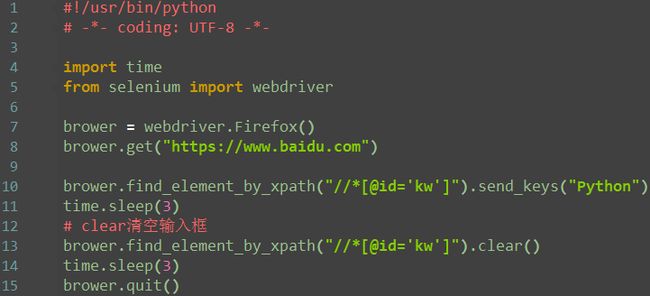
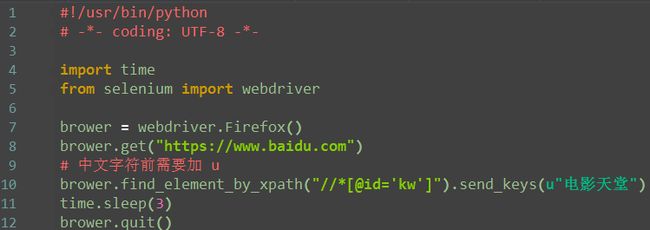
send_keys 输入文本
submit回车
百度搜索框,点击键盘上的回车键(Enter键)同样可以进行搜索的操作,和click操作是一样的效果

等待时间
强制等待 time.sleep()
最简单粗暴的一种办法就是强制等待sleep(x),导入time模块
注:x单位为秒,数字可以为小数
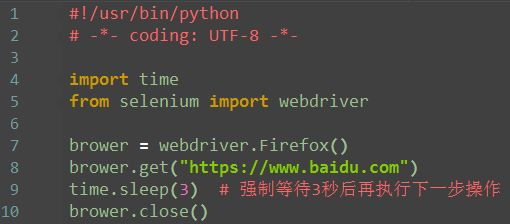
注:这种叫强制等待,不管你浏览器是否加载完了,程序都得等待3秒,3秒一到,继续执行下面的代码,作为调试很有用,有时候也可以在代码里这样等待,不过不建议总用这种等待方式,太死板,严重影响程序执行速度。
隐式等待 implicitly_wait()

注:隐形等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。注意这里有一个弊端,那就是程序会一直等待整个页面加载完成,也就是一般情况下你看到浏览器标签栏那个小圈不再转,才会执行下一步,但有时候页面想要的元素早就在加载完成了,但是因为个别js之类的东西特别慢,我仍得等到页面全部完成才能执行下一步,我想等我要的元素出来之后就下一步怎么办?有办法,这就要看selenium提供的另一种等待方式——显性等待wait了。
需要特别说明的是:隐性等待对整个driver的周期都起作用,所以只要设置一次即可,我曾看到有人把隐性等待当成了sleep在用,走哪儿都来一下…
显示等待
多窗口/句柄
有些页面的链接打开后,会重新打开一个窗口,对于这种情况,想在新页面上操作,就得先切换窗口了。获取窗口的唯一标识用句柄表示,所以只需要切换句柄,我们就能在多个页面上灵活自如的操作了。
1.认识多窗口
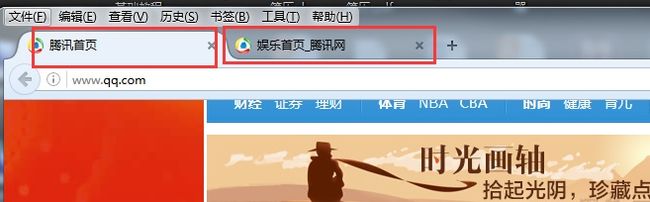
2.获取当前窗口句柄
1.元素有属性,浏览器的窗口其实也有属性的,只是你看不到,浏览器窗口的属性用句柄(handle)来识别。
2.人为操作的话,可以通过眼睛看,识别不同的窗口点击切换。但是脚本没长眼睛,它不知道你要操作哪个窗口,这时候只能句柄来判断了。
3.获取当前页面的句柄:driver.current_window_handle

3.获取所有句柄
1.定位赶集网招聘求职按钮,并点击
2.点击后,获取当前所以的句柄:window_handles
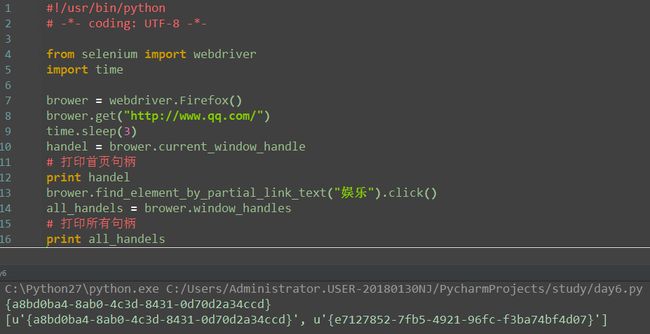
注:
获取多个句柄是列表类型,所以要切换到相应的句柄就用列表方法进行操作
4.切换句柄
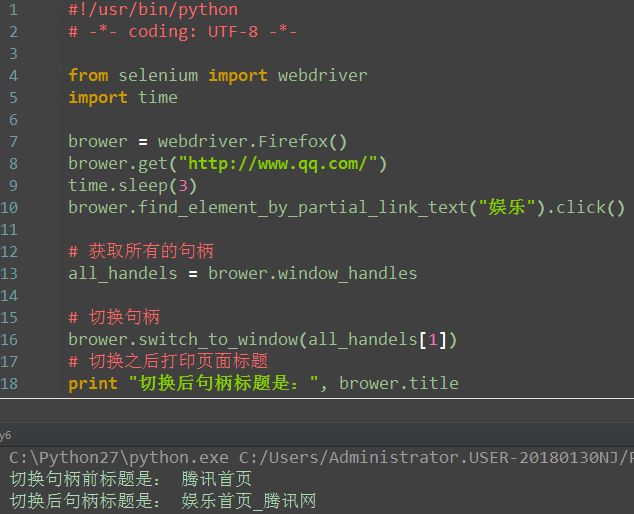
注:
- 如果要操作其它的窗口,就必须先切换窗口
- 为什么要打印title呢?请继续看下一章节打印信息
获取元素属性
当我们要设计功能测试用例时,一般会有预期结果,有些预期结果测试人员无法通过肉眼进行判断的。
因为自动化测试运行过程是无人值守,一般情况下,脚本运行成功,没有异样信息就标识用户执行成功。
那怎么才能知道我打开这个网页,是不是我想要打开的这个网页呢?
通常我们可以通过获得页面的 title 、URL 地址,页面上的标识性信息(如,登录成功的“欢迎,xxx”信息)来判断用例执行成功。
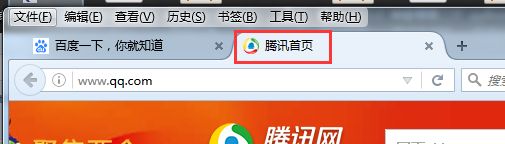
实例:登录腾讯主页
获取title
红框所示为title
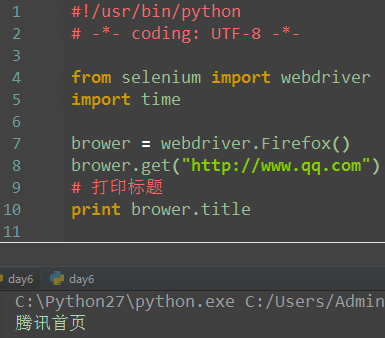
2.获取URL
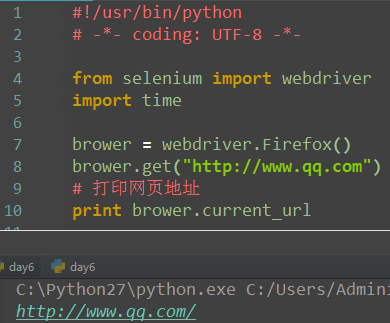
3.获取元素标签

获取输入框文本值

5.获取元素的其它属性
1.获取其它属性方法:get_attribute("属性"),这里的参数可以是class、name,value等任意属性
2.如获取百度一下按钮的value属性

获取文本超链接text
1.如下图这种显示在页面上的文本信息,可以直接获取到
2.查看元素属性:把百度设为主页

注:用于获取文字超链接的text,即有a标签的
7.浏览器名称
# 获取浏览器名称
print brower.name
联想词定位
如图所示,输入框内输入:Python,会自动弹出下面的信息。红圈中的词就叫联想词,那如何定位呢?
第一步:输入框内输入关键字
第二步:进行定位,即可看到以下图片内容

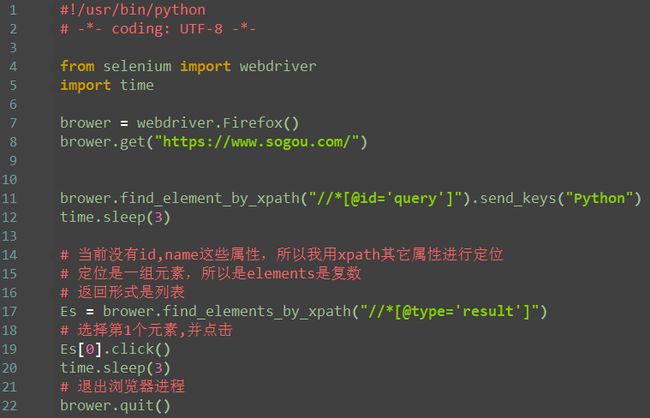
注:此处class属性是动态的,所以我没用class属性定位
文件上传
文件上传是web页面上很常见的一个功能,自动化成功中操作起来却不是那么简单。
一般分两个场景:一种是input标签,这种可以用selenium提供的send_keys()方法轻松解决;
另外一种非input标签实现起来比较困难,可以借助autoit工具或者SendKeys第三方库。
本篇以博客园的上传图片为案例,通过send_keys()方法解决文件上传问题
一、识别上传按钮
1.点开博客园编辑器里的图片上传按钮,弹出”上传本地图片”框。
2.用firebug查看按钮属性,这种上传图片按钮有个很明显的标识,它是一个input标签,并且type属性的值为file。
只要找到这两个标识,我们就可以直接用send_keys()方法上传文件了。

二、定位iframe
1.这里定位图片上传按钮情况有点复杂,首先它是在iframe上(不懂iframe的看这篇:iframe
2.这个iframe的id是动态的,且没有name属性,其它属性也不是很明显
3.通过搜索发现,这个页面上有两个iframe,需要定位的这个iframe是处于第二个位置

注:先登录博客且网页不要关掉(否则脚本打开网站后去点击“新随笔”元素时会提示你登录,这样测试起来就会很麻烦)
定位iframe的标签是第2个,所以为[1],坐标是0开始的。怎么才知道是第2个呢?我用的Chrome,ctrl+F搜索:iframe,如图所示
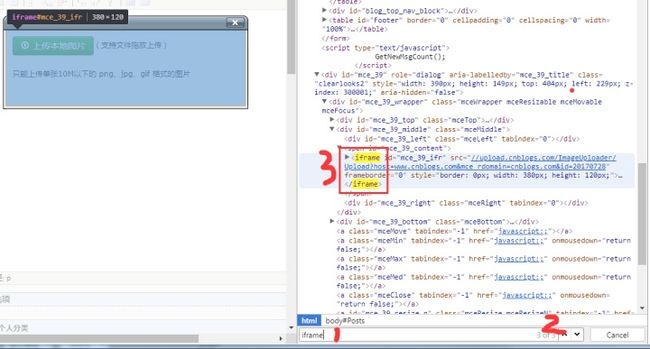
将红色字2处的数字切换到3,然后鼠标移至红色字3的位置。左边的iframe就会亮起这个就是要我们要定位的。
将红色字2外的数切换到1时,会发现iframe只是一个单词里的关键字。如图:

这个iframe是用不到的。记住:tag标签名为:iframe才是我们所需要的
所以实际只有两个iframe
所以我们要定位的iframe是在第2个,即下标为1
如果还不能理解。自己慢慢再想想
文件下载(SendKeys)
文件下载时候会弹出一个下载选项框,这个弹框是定位不到的,有些元素注定定位不到也没关系,就当没有鼠标,我们可以通过键盘的快捷键完成操作。
SendKeys库是专业的处理键盘事件的,所以这里需要用SendKeys解决
第一步:pip在线安装模块:pip install SendKeys
第二步:导入模块:import SendKeys
1.下载场景:

2.如果想点“保存文件”按钮,解决问题思路:
- 先按TAB键,移动光标聚焦到保存按钮上
- 再按下ENTER键,这样就能保存了

注:博客上发送回车键要用两次,原因是说第一次按回车键会失效但我实际代码中只运行一次也是正常的。如果你们遇到这种情况,就多发送一次回车键
iframe
frame是整个页面的框架,iframe是内嵌的网页元素,也可以说是内嵌的框架.
简单理解就是:frame是一个大框,iframe是里面的一个小框,当你要用到iframe这个小框时,首先得移至这个小框上去才可以操作它界面上的元素。
iframe属性