G1 GC知识点:
Region:1M~64M,2的幂,默认为其大小为将堆分为约2048个region为宜。可以通过-XX:G1HeapRegionSize来设定region大小,但是不推荐这么做,region过少会导致G1的灵活性降低,扫描的时间增长。
free list:由空的region组成的linked list
GC 过程如下:
1.当一个对象需要分配时,首先从free list里获取一个region的TLAB(Thread Local Allocation Buffer)本地线程缓冲区,然后在这个TLAB上进行分配。
2. 以此类推,直到所有Eden的region的总量都被填满,就会触发一次young GC。这里的cumulative amount of Eden space 跟目标暂停时间有关,在堆的5%~60%之间波动,其大小跟上次young GC的表现有关。
3. 当上述young GC完成后,死亡的对象被回收,存活的对象经过疏散和压缩后拷贝到Survivor区,而年龄超过阈值(可以通过MaxTenuringThreshold设置,默认15)的则会晋升到old区。
4. 如果满足如下三种情况之一,G1收集会继续
a. occupancy higher than threshold 达到the InitiatingHeapOccupancyPercent (IHOP),old regions里分配的对象大于堆的45%(G1HeapWastePercent参数)
b. candidate old regions available 达到G1ReservePercent (G1MixedGCLiveThresholdPercent defaults to 85% in JDK8u40+ and 65% in JDK7)
c. 遇到巨型数据的分配
5. 并发标记。基于snapshot-at-the-beginning (SATB)标记算法,在GC开始时先创建一个对象快照,STAB可以在并发标记时标记所有快照中当时的存活对象。标记过程中新分配的对象也会被标记为存活对象,不会被回收。
6. 当并发标记完成后,会再触发一个young GC,然后再出发一个mixed GC。mixed GC与young GC主要有2点不同,mixed GC会回收包括Eden和old区的对象,二者触发的条件不一样。
初级标记(Mandatory):
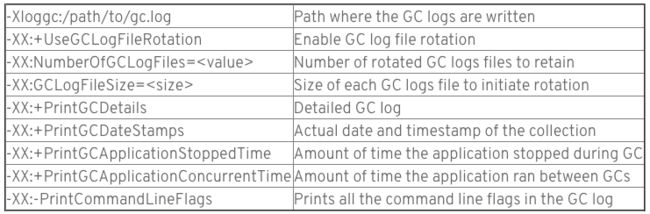
根据参数‘-XX:+PrintGCDetails’,产生如下log

1. 信息总览:
a. 通过设置 ‘-XX:+PrintGCDateStamps’ 得到GC发生的准备日期时间 - 2016-12-12T10:40:18.811-0500
b. JVM启动到当前时间的相对时间 - 29.959
c. 收集的类型 - G1 Evacuation Pause (young)
d. 垃圾收集消耗的总时长 - 0.0305171 sec
2. 并行任务:
a. Parallel Time - 并行任务STW总时长 - 26.6ms
b. GC Workers - 并行GC workers的总数量,通过 "-XX:ParallelGCThreads"设置 - 4
i. 当cpu内核数 <= 8,设置为cpu核数;>8时,设置为核数的5/8
c. GC Worker Start - GCworker开始工作时间相对于JVM启动的最大最小时间,diff就是第一个线程启动与最后一个线程启动时间之差,这个差值肯定越小越好
d. Ext Root Scanning - 外部根区(堆外区,线程栈根,JNI,全局变量,系统目录,classloader等)扫描消耗时间
e. Update RS (Remembered Set or RSet) - 在每次开始收集之前都要进行Rset更新,保证RSet是最新的。-XX:MaxGCPauseMillis参数是限制G1的暂停时间,一般RSet更新的时间小于10%的目标暂停时间是比较可取的。如果花费在RSetUpdate的时间过长,可以修改其占用总暂停时间的百分比-XX:G1RSetUpdatingPauseTimePercent。这个参数的默认值是10。
f. Scan RS - 扫描每个Region的RSet,寻找被待收集集合引用的区域
g. Code Root Scanning - 扫描被待收集集合引用的编译源码根节点
h. Object Copy - 将待收集集合中所有存活的对象拷贝到新的区域
i. Termination - 当一个GC worker结束工作后,需要等待其他线程,并尝试帮其他线程完成为完成的task. 结束时间指的就是这个线程结束收集到真正结束的时间差
j. GC Worker Other - 花在GC之外的工作线程的时间,比如因为JVM的某个活动,导致GC线程被停掉。这部分消耗的时间不是真正花在GC上,只是作为log的一部分记录
k. GC Worker Total - 每个并行回收线程的时间统计
l. GC Worker End - GC相对于JVM启动的结束时间. diff指第一个和最后一个完成的线程之间差值,越小越好
3. 串行任务:
a. Code Root Fixup - 遍历那些指向CSet的方法,修正指针
b. Code Root Purge - 清理code root table
c. Clear CT - 清除card table里的脏cards
4. 其他串行操作:
a. Choose CSet - 选取CSet
b. Ref Proc - 处理STW引用处理器发现的soft/weak/final/phantom/JNI引用
c. Ref Enq - 将引用排列到相应的reference队列里
d. Reditry Cards - 在回收过程中被修改的cards标记为脏卡
e. Humongous Register - 在youngGC的时候会收集巨型区域。这个指标是指评估巨型区域是否足够记录的时间。
f. Humongous Reclaim - 确认巨型对象死亡并清理,释放巨型对象区域,重置区域类型,将该区域放回空闲队列所用的时间
g. Free CSet - 释放CSet,其中也会清理CSet中的RSet,将其放回空闲队列
5. 各个代的变化统计
a. Eden: 1097.0M(1097.0M)->0.0B(967.0M)
i. 该次Young GC被触发是因为Eden区满了
ii. Eden区通过该次垃圾回收被清空,变为0.0B
iii. Eden区的总容量变化1097M -> 967M
b. Survivors: 13.0M->139.0M
i. Survivor space从13M增长到139M
c. Heap: 1694.4M(2048.0M)->736.3M(2048.0M)
i. 收集的时候,整个堆总量为2048M,被使用了1694M
ii. 回收完毕,整个堆总量为2048M,被使用了736.3M
6. 垃圾回收花费的时间
a. user=0.08 - 在回收过程中花费在用户代码上的CPU时间,是所有thread在所有CPU上的花费时间之和。并没有计算处理器之外花费的时间和等待时间
b. sys=0.00 - 在回收过程中花费在内核处理上的CPU时间,是所有thread在所有CPU上的花费时间之和。并没有计算处理器之外花费的时间和等待时间
c. real=0.03 - 从垃圾回收到结束的真实时间,包括其他处理器花费的时候及等待时间
并发标记的分析,并发标记可以由不同的方式触发,但是它的表现是一致的。
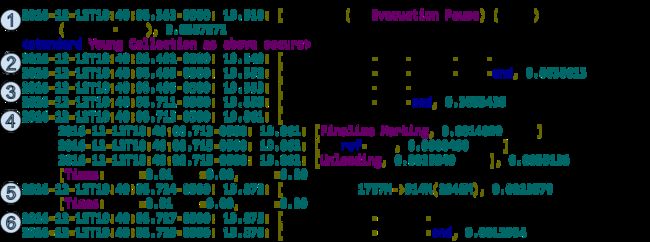
1. 标记开始:
GC pause (G1 Evacuation Pause) (young) (initial-mark)
标记GC Roots,会STW,寻找所有可达到的对象,初始标记阶段是Young GC的一部分。初始标记阶段设置2种TAMS变量来区分现存的对象和并行标记时才分配的对象。上述被标记的对象被认为是存货的对象。
2. 第一次并发事件:
GC concurrent-root-region-scan-start / GC concurrent-root-region-scan-end
根分区扫描,这个阶段GC的线程可以和应用线程并发运行。其主要扫描初始标记以及之前YoungGC对象转移到的Survivor分区,并标记Survivor区中引用的对象。
3. 并发标记
GC concurrent-mark-start / GC concurrent-mark-end
a. 跟应用线程同时运行,并发标记的线程数默认为parallel thread的25%,也可以通过”-XX:ConcGCThreads” 设置
b. 会并发标记所有非完全空闲的分区的存活对象,也即使用了SATB算法,标记各个分区
4. 最终标记
GC remark [ Finalize Marking / GC ref-proc / Unloading]
有STW,主要处理SATB缓冲区,以及并发标记阶段未标记到的漏网之鱼(存活对象)
5. 清除阶段
GC cleanup 有STW
a. 每个区域分别统计存活对象。在card bitmap标记初始标记之后分配的对象,在Region bitmap标记有存货对象的区域
b. 交换bitmaps,为下一次标记做准备
c. 释放和清理死去的老年区域和没有存货数据的巨型数据区域
d. 清除没有存活对象的区域的RSet
e. 将老年区域根据存活率进行排序
f. 并发的将无效的类从metaspace卸载
6. 并发清除
GC concurrent-cleanup-start / GC concurrent-cleanup-end
a. 清理RSet,包括card cache和code root table
b. 当区域完全清除后,添加到临时队列,当清除结束后,将临时队列合并到第二空闲区域队列,等待被添加到主空闲队列
当并发标记结束,Young GC后会跟紧一个Mixed GC。Mixed GC跟Young GC只有2点不同,如下:

1. 收集类型为混合的: GC pause (G1 Evacuation Pause) (mixed)
2. CSet会包含通过并发标记确定的老年区域
最后一种可能遇到的GC为Full GC,Full GC是一个单线程的有STW的过程。

1. GC 产生原因,(Allocation Failure)。
2. Full GC的频率
3. Full GC的消耗时间
加入‘-XX:+PrintGCApplicationStoppedTime’ and ‘-XX:+PrintGCApplicationConcurrentTime’配置产生的log
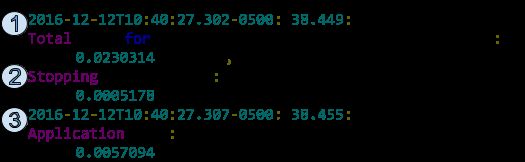
1. 业务线程在安全点停止的时间
2. 将所有线程带到安全点并暂停的耗时
3. 业务线程在两个安全点之间运行的时间
高级标记(Advanced)

‘-XX:+PrintAdaptiveSizePolicy’:增加G1 ergonomics,便于对CSet选择和暂停时间的估算有更深入的了解。
对于Young GC,新增了如下log:

1. dirty card queue 有多少cards待处理,并预估时间
2. 该次收集有多少region参与,并预估时间,并预估对象拷贝的时间
3. 最终CSet的选择,并预估总时间,其实就是前两部之和
4. 不一定出现。如果GC线程执行时间/业务线程执行时间大于某个阈值,G1会尝试增大堆。不过我们的设置都是max=min,不会出现这个
5. 如果需要并发标记会有这行log。
如果有并发阶段,会多打印如下log:

当标记结束,紧着是mixed GC,多增如下log:

开始mixed GC的原因,可回收的old区域>阈值。如果可回收的小于阈值,则不会开始。
Mixed GC开始:

1. 选择CSet和为CSet添加young region跟Young GC一样
2. 将Old Region添加到CSet。添加的old region的数量由参数XX:G1OldCSetRegionThresholdPercent=X控制,默认为10%
3. 总结CSet的情况,并预测总的暂停时间
4. 展示了Mixed GC循环的详细信息。由于释放后,任然占堆的14%,大于阈值5%,所以下一次垃圾回收还是Mixed
下一次Mixed垃圾回收跟上面的一致,但是结尾处有点区别:

1. 由于这次混合垃圾回收之后,old region的占比小于阈值,故下次垃圾回收为young gc
最后,看一下Full GC的ergonomics

1. 在主从空闲队列中均没有空闲区域了,分配请求失败,需要请求堆扩展。
2. 堆扩展请求。 但是1.2两步中的操作还没真正实施
3. 对扩展不会尝试,由于可用的未提交的regions数量为0。由于扩展失败,所以开始Full GC
4. 由于堆的最小值小于堆的最大值,G1会在Full GC之后缩小堆的总量至70%
5. 堆缩小的详细信息
-XX:+PrintTenuringDistribution 这个标签提供了survivor空间的分布
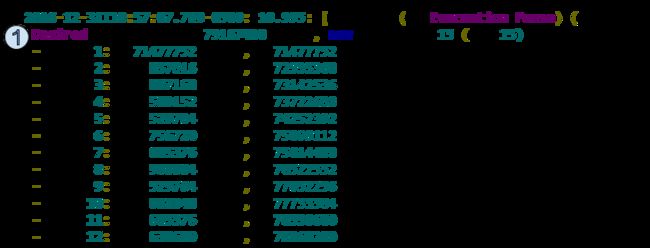
任期分布数据主要告诉我们survivor空间如下三点信息:
a. The desired survivor size 就是survivor空间总量 乘以 TargetSurvivorRatio (默认值为 50%)
b. The target threshold 就是对象在Young GC时存活的岁数。
c. 年龄的分布,包括不同年龄对象的大小及增量的总和。

问题诊断标记(Debug)
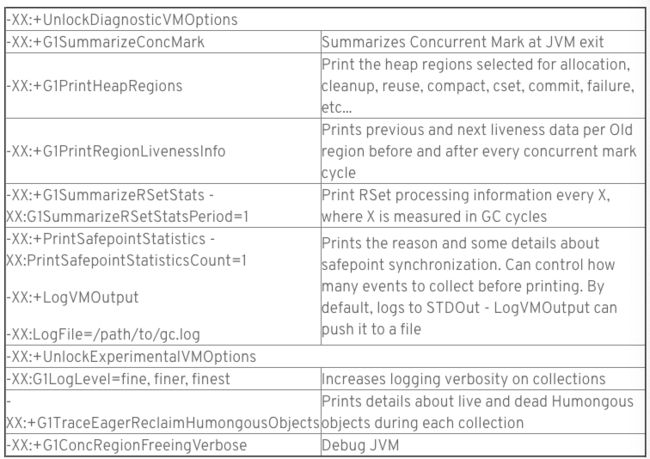
‘-XX:+G1PrintHeapRegions’:
调试如下问题时有必要打印堆区事件:
a. 调试寻找疏散失败的原因及失败区域的编号
b. 确定巨型对象的大小和出现频率
c. 跟踪和估算被规划为CSet的Eden、Survivor和Old区的数量
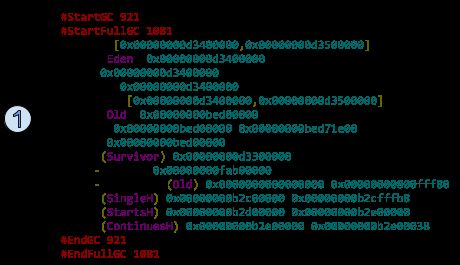
1. COMMIT
堆的初始化或扩展完成,确定区域的顶和底
2. ALLOC(Eden)
分配的Eden区域,由底的地址确定
3. CSET
CSet区域,该区域将被回收,由底的地址确定
4. CLEANUP
在并发标记的时候完全被清空的区域,由底的地址确定
5. UNCOMMIT
在Full GC后,如果堆被缩小,就会出现很多未提交的区域
6. ALLOC(Old)
分配的Old区域,由底的地址确定
7. RETIRE
在垃圾回收结束的时候,最后一个被分配的Old区会被标记为退休的
8. REUSE
下次一GC开始时,上一次退休的Old区会作为起始点
9. ALLOC(Survivor)
分配的Survivor区域,由底的地址确定
10. EVAC-FAILURE
如果分配中出现疏散失败,这里会指出失败的区域
11. POST-COMPACTION(Old)
在Full GC结束后,对有存活数据的Old和巨型数据区会进行压缩
12. ALLOC(SingleH)
分配SingleH巨型数据区域,对象只能占用一个区域
13. ALLOC(StartsH)
分配StartsH巨型数据区,对象可以放置在不止一个区域中
14. ALLOC(ContinuesH)
分配ContinuesH巨型数据区
‘-XX:+G1PrintRegionLivenessInfo’ 用于分析并发标记后old区的分布:

其实就是翻译了下这篇文章
Collecting and reading G1 garbage collector logs - part 2