哈喽,我是小张,大家好久不见啊~
最近呢,对链家平台上的北京二手房数据做了个可视化分析,对目前北京的二手房交易情况有了个大致了解,最终得到一个很实在的结论:奋斗一辈子也买不到一个厕所这句话不是骗人的,是真的;关于具体分析内容客官请看下文
1,工具说明
本文用到的 Python 库有
pandas
re
requests
json
pyecharts
folium
random
stylecloud
jieba
pyquery
fake_useragent
time
外加 百度地图 API
2,数据采集
所有数据来源于链家二手房交易平台,上面每页排列 30 条二手房数据,本文采集了前 100 页 数据,每条二手房交易数据中提取 标题、单价、价格、地址、年份、房间样式 等字段作为可视化分析的数据来源
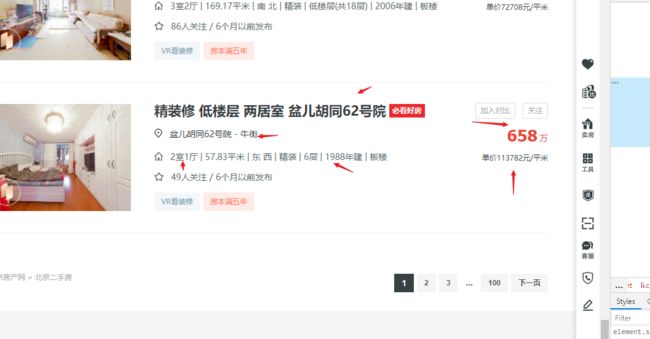
网站没有设置很强的反爬机制, 爬取时用的是 requests + Cookies+ PyQuery 组合即可,最好在爬取时加条 time.sleep() 命令,隔几秒休眠一次,代码如下:
import requests
from pyquery import PyQuery as pq
from fake_useragent import UserAgent
import time
import random
import pandas as pd
UA = UserAgent()
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cookie': '你的Cookie',
'Host': 'bj.lianjia.com',
'Referer': 'https://bj.lianjia.com/ershoufang/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
}
num_page = 2
class Lianjia_Crawer:
def __init__(self,txt_path):
super(Lianjia_Crawer,self).__init__()
self.file = str(txt_path)
self.df = pd.DataFrame(columns = ['title','community','citydirct','houseinfo','dateinfo','taglist','totalprice','unitprice'])
def run(self):
'''启动脚本'''
for i in range(100):
url = "https://bj.lianjia.com/ershoufang/pg{}/".format(str(i))
self.parse_url(url)
time.sleep(random.randint(2,5))
print('正在爬取的 url 为 {}'.format(url))
print('爬取完毕!!!!!!!!!!!!!!')
self.df.to_csv(self.file,encoding='utf-8')
def parse_url(self,url):
headers['User-Agent'] = UA.chrome
res = requests.get(url, headers=headers)
doc = pq(res.text)
for i in doc('.clear.LOGCLICKDATA .info.clear'):
try:
pq_i = pq(i)
title = pq_i('.title').text().replace('必看好房', '')
Community = pq_i('.flood .positionInfo a').text()
HouseInfo = pq_i('.address .houseInfo').text()
DateInfo = pq_i('.followInfo').text()
TagList = pq_i('.tag').text()
TotalPrice = pq_i('.priceInfo .totalPrice').text()
UnitPrice = pq_i('.priceInfo .unitPrice').text()
CityDirct = str(Community).split(' ')[-1]
Community = str(Community).split(' ')[0]
data_dict ={
'title':title,
'community':Community,
'citydirct':CityDirct,
'houseinfo':HouseInfo,
'dateinfo':DateInfo,
'taglist':TagList,
'totalprice':TotalPrice,
'unitprice':UnitPrice
}
print(Community,CityDirct)
self.df = self.df.append(data_dict,ignore_index=True)
#self.file.write(','.join([title, Community, CityDirct, HouseInfo, DateInfo, TagList, TotalPrice, UnitPrice]))
print([title, Community, CityDirct, HouseInfo, DateInfo, TagList, TotalPrice, UnitPrice])
except Exception as e:
print(e)
print("索引提取失败,请重试!!!!!!!!!!!!!")
if __name__ =="__main__":
txt_path = "ershoufang_lianjia.csv"
Crawer = Lianjia_Crawer(txt_path)
Crawer.run() # 启动爬虫脚本最终一共采集到 3000 条数据:

3,地址经纬度坐标转换
获取到的数据是地址是字符串形式(例如梵谷水郡*酒仙桥),后面地图位置标记时需要经纬度数据,需要把所有地址转化为经纬度坐标,这里借助了百度地图 API 完成这步操作
3.1 百度地图 AK 申请
API 的使用需要在 百度地图开放平台 申请一个 AK 效验码,网址:https://lbsyun.baidu.com/apiconsole/center#/home,登录自己的百度账号,在控制台创建一个应用,
控制台面板-> 我的应用-> 创建应用
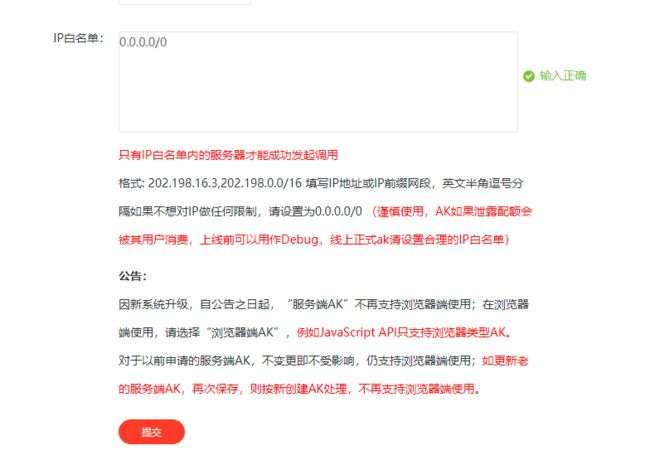
其他参数默认,应用名称自定义命名即可,IP 白名单填入 0.0.0.0/0,点击提交
以上步骤操作完之后,控制台面板会多出一个应用,就是刚刚我们建立的,

3.2 地址经纬度坐标转换
获取到你的 AK 参数之后,把 AK 和 address(中文地址) 作为参数传入下面函数中,就能获取到对应的经纬度坐标
def get_location(address,AK):
#根据地址转化为经纬度
try:
url = 'http://api.map.baidu.com/geocoding/v3/?address={}&output=json&ak={}&callback=showLocation'.format(address,AK)
res_test = requests.get(url).text
res = re.search('\((.*?)\)', res_test).group(0).strip('(').strip(')')
lng = json.loads(res)['result']['location']['lng']
lat = json.loads(res)['result']['location']['lat']
print(lng, lat)
return lng, lat
except Exception as e:
print('error ---------\n')
return None
百度地图 API 的 地址经纬度转换 功能 定位不仅仅局限于省、市,还能定位到门牌号,只要你提供的地址越详细,获取的经纬度信息越准确
4,可视化分析
这一部分进入可视化分析内容,城市毕竟是北京么所以首要的就是关注房价问题,在抓取的数据中,最高的将近19万+/每平方,最低的仅有 1.5 万/每平方

我看到 1.5 万每平方就不淡定了,这数据肯定有猫腻(北京房价按常理不可能这么低);为了验证想法,首先做了房产地段标记(经纬度地图标记借助百度地图地址 相关 Demo )
先看一下排名前十的:
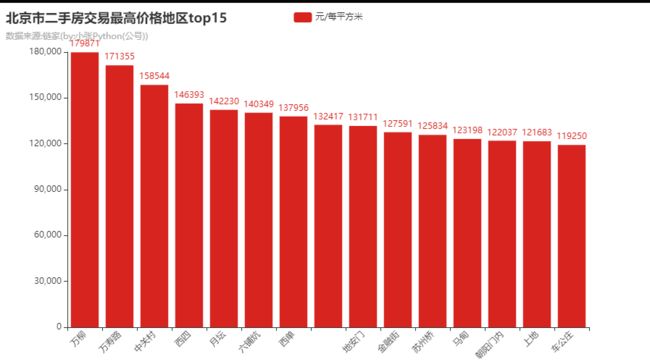

上面是房价最高 Top10 的地段位置,看起来地理位置还行,都是在三环四环之内、分布在市中心附件,如果单看这张图的地图的话得不到有用的信息,可以对比一下 房价最低 Top10
下面是排名倒数前十的


上面是北京二手房房价排名后十 地段分布,房价在 1.5万-3万 不等,没看到这个分布图之前仅仅认为上面价格是卖家标错了,看完这个图后才发现卖家是 挂着羊头卖狗肉,挂着北京的名号,卖着北京以外的房子(有的房子已经位于河北境内),这可能就是卖房的套路之一吧
事出反常必有妖,无论买房还是买其他商品也好,卖家不会平白无故地给我们优惠,当价格远低于市场价之前交易需慎重、慎重、再慎重!
房价我分为 5 个区间,分别为 0-3万、3-8万、8-12万、12-15万,15万+ 五段,看一下各自的占比分布
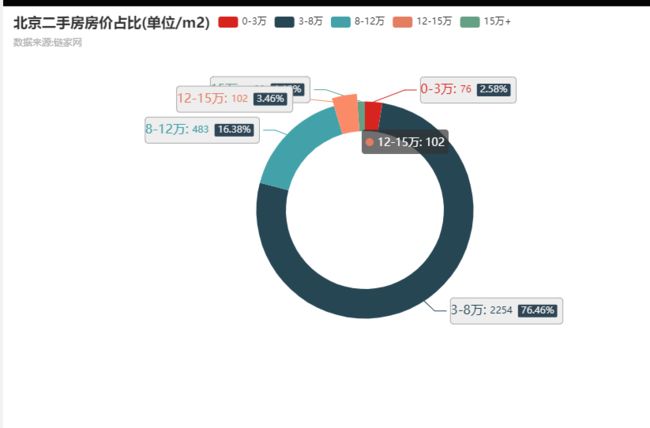
其中房价位于 3-8万 占比最大达 76 %占比,次之就是8-12万、12-15万,依次占比为16.38%、3.46%,而房价位于 15 万 + 占比最少,仅有1.12% 左右;
接下来我们再看一下,不同价位二手房在北京的分布
15万+的
12-15万
8-12万
3-8万
从地段分布来看北京房价以8万作为分水岭,8万+和8万以内房产分布明显变化,价格越高,越靠市中心以外;从地图信息来看,想在北京买一套地段不错的房子,预期房价最低也要在8万+,8 万是什么概念,也就说如果你想在北京买一套50平米的房子,最低也要 400万!
关于15万+ 的房产,大致都分布两个区域,一个是高校区(周围是人大、北航、清华等高校),另一个位于右下角,也就是北京朝阳区
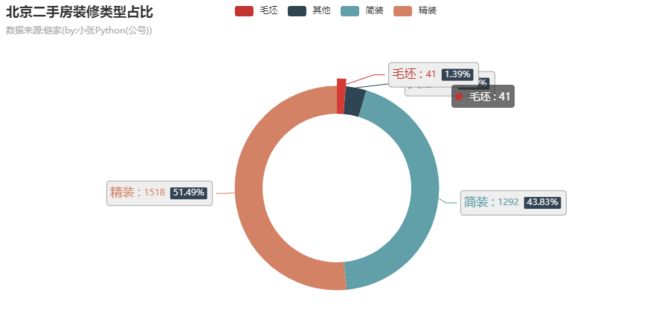
北京卖的二手房不一定都是装修之后的,有可能也是毛坯(刚建造交付之后,未进行任何装修);参考下图,北京二手房中毛坯占比约1.39%共41套,户主买来这些房子大概率用于资产增值而不是作为刚需;
借助 Treemap 图再看一下北京二手房建筑时间分布,大部分都集中于2002-2010 这 9 年,北京房产也是在这段期间迅速发展, 到 2015 年之后明显收缓,源于可建筑地段已经达到饱和再加上国家相关政策的施压

最后贴张词云图作为本文的结束,选取的文本信息为3000条房产信息的标题,从图中来看,标题中高频词汇有 南北通透、高楼层、精装修、采光好 等,也可以说这几个特点也是大多数房源的最大卖点(抛去价格、地段等因素)

5,小总结
本文针对北京二手房的分析角度并不全面,仅仅围绕着房价、地段、修建年份等几个维度做了简单分析,分析结果仅供学习,其数据真实性有考察
好了以上就是本文的全部内容,最后感谢大家的阅读,我们下期见~
6,源码获取
关于本文中涉及的全部源码和数据 获取方式,在微信公号:小张Python ,后台回复关键字 210303 即可~