第三部分 图论算法 (第一章 并查集)例题
例题一:【模板】并查集 link


#include 例题二:程序自动分析 link



思路:
这道题我们考虑用并查集来做。
关心 x=y,那只用将其合并到同一个集合中
x≠y反之亦然。
再来考虑一下判定是否满足怎么做?
想必大家都知道:
- 如果判断为x=y,但是两数不在同一集合,No
- 如果判断为x≠y,但是两数在同一集合,No
- 其他情况则为Yes
但是数据不是很友好,编号最大有 1 9 1^9 19,数组这样开一定会爆。
于是我们最后考虑用一下离散化缩小绝对大小变成相对大小。
#include例题三:银河英雄传说 link
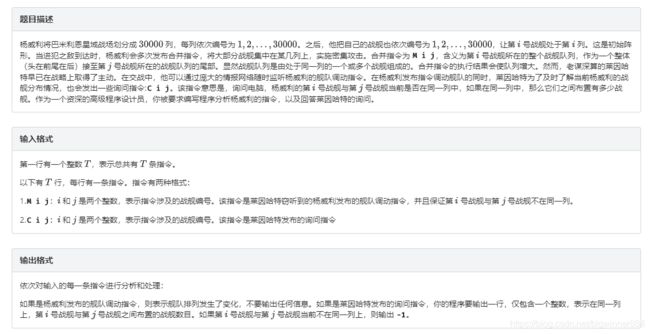

思路:
先来分析一下这些指令的特点,很容易发现对于每个M指令,只可能一次移动整个队列,并且是把两个队列首尾相接合并成一个队列,不会出现把一个队列分开的情况,因此,我们必须要找到一个可以一次操作合并两个队列的方法。
再来看下C指令:判断飞船i和飞船j是否在同一列,若在,则输出它们中间隔了多少艘飞船。我们先只看判断是否在同一列,由于每列一开始都只有一艘飞船,之后开始合并,结合刚刚分析过的M指令,很容易就想到要用并查集来实现。
定义一个数组fa,fa[i]表示飞船i的祖先节点,即其所在列的队头。再定义一个用于查找飞船祖先的函数find,在每次递归找祖先的同时更新fa,压缩路径,大大减小以后的时间消耗。初始时对于每个fa[i]都赋值为i,合并时就先分别查找飞船i和飞船j的祖先,然后将飞船i的祖先的祖先(即fa[飞船i的祖先])赋值为飞船j的祖先。最后每次判断时只需要找到飞船i和飞船j的祖先,判断是否是同一艘飞船,若是,则在同一列,反之,则不在。
现在,判断是否在同一列以及如何一次操作合并两个队列的问题已经解决,但还有问题需要解决:如何在以上方法的基础上,进一步得到两艘飞船之间的飞船数量呢?
我们先来分析一下:两艘飞船之间的飞船数量,其实就是艘飞船之间的距离,那么,这就转换为了一个求距离的问题。两艘飞船都是在队列里的,最简单的求距离的方法就是前后一个一个查找,但这个方法太低效,会超时。看见多次求两个点的距离的问题,便想到用前缀和来实现:开一个front数组,front[i]表示飞船i到其所在队列队头的距离,然后飞船i和飞船j之间的飞船数量即为它们到队头的距离之差减一,就是abs(front[i]-front[j])-1。
解决了如何高效得到两艘飞船之间飞船数量的问题,便又发现了新的问题:如何在之前方法的基础上,得到每艘飞船和队头的距离呢?
来分析一下现在已经使用的算法——并查集,它的特点就是不是直接把一个队列里的所有飞船移到另一个队列后面,而是通过将要移动的队列的队头连接到另一个队列的队头上,从而间接连接两个队列。因此,我们在这个算法的基础上,每次只能更新一列中一艘飞船到队头的距离(如果更新多艘的话并查集就没有意义了)。
那么,该更新哪艘飞船呢?现在我们已经知道,使用并查集合并两个队列时只改变队头的祖先,而这个队列里其它飞船的祖先还是它原来的队头,并没有更新,所以这个队列里的其它飞船在队列合并之后,仍然可以找到它原来的队头,也就可以使用它原来队头的数据,因此,在每次合并的时候,只要更新合并前队头到目前队头的距离就可以了,之后其它的就可以利用它来算出自己到队头的距离。
理清了思路,但又有问题出现:该怎样更新呢?该怎么计算呢?
更新很容易,我们来分析一下:对于原来的队头,它到队头的距离为0,当将它所在的队列移到另一个队列后面时,它到队头的距离就是排在它前面的飞船数,也就是合并前另一个队列的飞船数量。因此,就知道该怎样实现了,我们再建一个数组num,num[i]表示以i为队头的队列的飞船数量,初始时都是1,在每次合并的时候,fx为合并前飞船i的队头,fy为合并前飞船j的队头,每次合并时,先更新front[fx],即给它加上num[fy],然后开始合并,即fa[fx]=fy,最后更新num, num[fy]+= num[fx];num[fx]=0。
现在就差最后一步了:如何计算每个飞船到队头的距离。再来分析一下:对于任意一个飞船,我们都知道它的祖先(不一定是队头,但一定间接或直接指向队头),还知道距离它祖先的距离。对于每一个飞船,它到队头的距离,就等于它到它祖先的距离加上它祖先到队头的距离,而它的祖先到队头的距离,也可以变成类似的。可以递归实现,由于每一次更新都要用到已经更新完成的祖先到队头的距离,所以要先递归找到队头,然后在回溯的时候更新(front[i]+=front[fa[i]]),可以把这个过程和查找队头的函数放在一起。
#include 例题四:食物链 link


思路:
用3倍的并查集的存各种动物的关系
一倍存本身,二倍存猎物,三倍存天敌
唯一容易忽略的点就是:一的猎物的猎物 就是一的天敌
那么我们每次只要维护三个并查积的关系就可以了
#include 例题五:超市购物 link

思路:
这道题可以用贪心配上并查集来做。
我们把商品按收益从大到小排序,然后一个一个枚举,
用过期时间来并查集,如果卖,
那么当前时间就不能卖其他的商品了,就只能在前一秒卖了。
#include 例题六:逐个击破 link


思路:
并查集做不到最小代价删边(貌似相似有个分治线段树的东西)。
根据容斥原理,用最小代价刪边,
就等价于用最大代价建边,那剩下的就是最小代价所要刪的边。
现在我们来考虑一下怎么建边。
下面的图中,红色代表敌人节点,绿色代表我方节点.
显然一定不会将两个敌方军团放在一个集合中。

还有,如果我们已经将敌人包围建出下面这样的图这时,还有一个敌人节点.↓

如果我们连接某一个我方节点,不连接敌方节点,那敌人也会互相连接(翻过屋后的山
所以说我们需要考虑一下如何解决这种情况.
如果,我方节点已经连接了敌方节点,则需要标记我方节点,
使得敌方节点无法通过我方节点连接敌方节点.
因此说,我们可以把连接到敌人节点的我方节点变成敌人节点.
从而使得其他敌人节点与其无法连接.
那我们上面的图就变成这样↓

这样我们的程序就可以实现我们所想了.
最后我们会将边权大的边加入到并查集中.
则最后没有加入到并查集中的点,就会是被孤立的敌方节点.
所以我们把总边权减去我们加入到图中的边权就是我们的ans啦!
#include