maftools_2
clp
02 June, 2020
maftools : 总结、分析、可视化 MAF文件maftools : 总结、分析、可视化 MAF文件
1 简介
随着肿瘤基因组学的发展,突变注释格式(MAF)正被广泛接受并用于存储检测到的体细胞变异。癌症基因组图谱项目已经对30多种不同的癌症进行了排序,每种癌症的样本量超过200。由体细胞变体组成的结果数据以突变注释格式存储。只要数据为MAF格式,此R包将尝试以高效的方式汇总、分析、注释和可视化来自TCGA来源或任何内部研究的MAF文件。
1.1 引用
如果你觉得这个软件有帮助到你,请用如下方法引用:
Mayakonda A, Lin DC, Assenov Y, Plass C, Koeffler HP. 2018. Maftools: efficient and comprehensive analysis of somatic variants in cancer. Genome Resarch PMID: 30341162
2 构建MAF文件
- 对于VCF文件或简单的表格文件,简单的选择是使用vcf2maf软件,该软件将对VCF进行注释,确定记录的优先顺序,并生成MAF。
- 如果您使用ANNOVAR 进行变异注释,
maftools有一个很方便的函数annovarToMaf,用于将注释输出转换为MAF格式。
3 MAF field 要求
MAF文件包含从染色体名称到cosmic注释的许多字段。然而,maftools中的大多数分析使用以下字段。 - 必填字段: Hugo_Symbol, Chromosome, Start_Position, End_Position, Reference_Allele, Tumor_Seq_Allele2, Variant_Classification, Variant_Type and Tumor_Sample_Barcode. - 推荐的可选字段:包含VAF(变异等位基因频率)和氨基酸变化信息的非MAF特定字段。
有关MAF文件的完整规范,请参阅NCI GDC文档页面。 本教程在TCGA LAML队列1中的一个示例MAF文件上演示了maftools的用法和应用。
4 安装
# if (!require("BiocManager"))
# install.packages("BiocManager")
# BiocManager::install("maftools")
5 该R包概览
maftools功能主要分为可视化模块和分析模块。下面总结了这些功能和简短的描述,如下所示。使用方法很简单,只需使用read.maf读取MAF文件(如果可用,还会附带copy-number数据),然后将生成的MAF对象传递给所需的函数进行绘图或分析。

6 读取并初步探索maf文件
6.1 Required input files
- MAF文件-可以
.gz压缩文件,必需输入文件。 - 与MAF中的
每个样本/Tumor_Sample_Barcode相关的可选但推荐的临床数据。 - 可选的copy number数据(如果可用)。可以是
GISTIC输出格式,也可以是包含sample names, gene names 和 copy-number status (AmporDel)。
6.2 Reading MAF files
read.maf函数读取MAF文件,以各种方式对其进行汇总,并将其存储为MAF对象。尽管MAF文件足够独立,建议您在MAF中提供与示例相关联的注释文件。如果可用,还可以集成拷贝数(copy number data)数据。
library(maftools)
#path to TCGA LAML MAF file
laml.maf = system.file('extdata', 'tcga_laml.maf.gz', package = 'maftools')
#clinical information containing survival information and histology. This is optional
laml.clin = system.file('extdata', 'tcga_laml_annot.tsv', package = 'maftools')
laml = read.maf(maf = laml.maf, clinicalData = laml.clin)
#> -Reading
#> -Validating
#> -Silent variants: 475
#> -Summarizing
#> -Processing clinical data
#> -Finished in 0.243s elapsed (0.869s cpu)
6.3 MAF 对象
汇总MAF文件存储为MAF对象。MAF对象包含主MAF文件、汇总数据和任何关联的示例注释。 有一些访问器方法可以从MAF对象访问有用的slots。
#Typing laml shows basic summary of MAF file.
laml
#> An object of class MAF
#> ID summary Mean Median
#> 1: NCBI_Build 37 NA NA
#> 2: Center genome.wustl.edu NA NA
#> 3: Samples 193 NA NA
#> 4: nGenes 1241 NA NA
#> 5: Frame_Shift_Del 52 0.271 0
#> 6: Frame_Shift_Ins 91 0.474 0
#> 7: In_Frame_Del 10 0.052 0
#> 8: In_Frame_Ins 42 0.219 0
#> 9: Missense_Mutation 1342 6.990 7
#> 10: Nonsense_Mutation 103 0.536 0
#> 11: Splice_Site 92 0.479 0
#> 12: total 1732 9.021 9
# #Shows sample summry.
# getSampleSummary(laml)
# #Shows gene summary.
# getGeneSummary(laml)
# #shows clinical data associated with samples
# getClinicalData(laml)
# #Shows all fields in MAF
# getFields(laml)
# #Writes maf summary to an output file with basename laml.
# write.mafSummary(maf = laml, basename = 'laml')
7 可视化
7.1 Plotting MAF summary
我们可以使用plotmafSummary来绘制maf文件的摘要,该文件将每个样本中的变体数量显示为堆叠的条形图,将变量类型显示为由Variant_Classification分类汇总的箱形图。我们可以将平均值或中值线添加到堆叠条形图中,以显示队列中的平均/中位数变量。
plotmafSummary(maf = laml, rmOutlier = TRUE, addStat = 'median', dashboard = TRUE, titvRaw = FALSE)

7.2 Oncoplots瀑布图
7.2.1 Drawing oncoplots
可以将maf文件更好地表示为附图,也称为瀑布图。侧方条形图和顶部条形图可以分别由draRowBar和draColBar参数控制。
#oncoplot for top ten mutated genes.
oncoplot(maf = laml, top = 10)

注:标记为
Multi_Hit的变异是指在同一样本中发生多次突变的基因。 有关自定义的更多详细信息,请参阅自定义专题图小节。
7.3 Oncostrip
我们可以使用oncostrip函数可视化任何一组基因,该函数在每个样本中绘制突变,类似于cBioPortal上的OncoPrinter工具。oncostrip可用于使用top或gene参数绘制任意数量的基因。
oncostrip(maf = laml, genes = c('DNMT3A','NPM1', 'RUNX1'))

7.4转换和颠倒
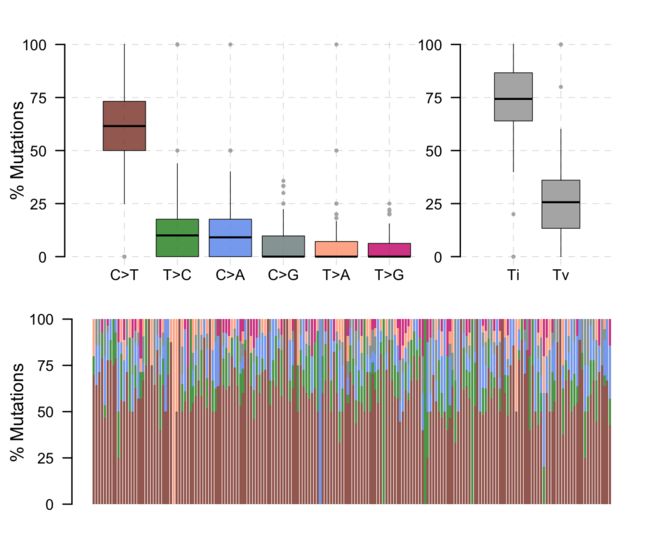
titv 函数将SNP分类为 Transitions and Transversions ,并以各种方式返回汇总表的列表。汇总的数据还可以可视化为显示六个不同转换的总体分布的boxplot图,以及显示每个样本中的转换分数的堆叠条形图。
laml.titv = titv(maf = laml, plot = FALSE, useSyn = TRUE)
#plot titv summary
plotTiTv(res = laml.titv)
7.5 Lollipop plots for amino acid changes
棒糖图是显示蛋白质结构突变点的简单有效的方法。许多癌基因都有一个优先位点,其突变频率比其他任何位点都要高。这些点被认为是突变热点,棒棒糖曲线图可以用来显示它们和其他突变。我们可以使用函数lollipopPlot绘制这样的曲线图。这个函数要求我们在maf文件中有氨基酸变化信息。然而,MAF文件对氨基酸变化的字段命名没有明确的指导方针,不同的研究对氨基酸变化有不同的字段(或列)名称。默认情况下,lollipopPlot查找列AAChange,如果在MAF文件中找不到,则打印所有可用字段并显示一条警告消息。例如,MAF文件在字段/列名为‘Protein_Change’下包含氨基酸变化。我们将使用参数AACol手动指定此参数。此函数还将绘图作为ggplot对象返回,用户稍后可以根据需要对其进行修改。
#lollipop plot for DNMT3A, which is one of the most frequent mutated gene in Leukemia.
lollipopPlot(maf = laml, gene = 'DNMT3A', AACol = 'Protein_Change', showMutationRate = TRUE)
#> HGNC refseq.ID protein.ID aa.length
#> 1: DNMT3A NM_175629 NP_783328 912
#> 2: DNMT3A NM_022552 NP_072046 912
#> 3: DNMT3A NM_153759 NP_715640 723

请注意,
lollipopPlot警告用户针对给定基因的不同转录本的可用性。如果我们事先知道转录本ID,我们可以将其指定为refSeqID或protein ID。默认情况下,lollipopPlot使用较长的转录本。
7.5.1 Labelling points
我们还可以使用参数labelPos标记lollipopPlot上的点。如果labelPos设置为all,则所有点都会高亮显示。
lollipopPlot(maf = laml, gene = 'DNMT3A', showDomainLabel = FALSE, labelPos = 882)
#> HGNC refseq.ID protein.ID aa.length
#> 1: DNMT3A NM_175629 NP_783328 912
#> 2: DNMT3A NM_022552 NP_072046 912
#> 3: DNMT3A NM_153759 NP_715640 723

7.6 Rainfall plots
肿瘤基因组,特别是实体瘤的特征是基因组位点具有局部性的超突变 5.这种超突变的基因组区域可以通过在线性基因组尺度上绘制变异间距离图来可视化。这些地块通常被称为rainfallPlot,我们可以使用rainfallPlot来绘制这样的地块。如果detectChangePoints设置为TRUE,则rainfall plot还会亮显事件间距离的潜在更改所在的区域。
brca <- system.file("extdata", "brca.maf.gz", package = "maftools")
brca = read.maf(maf = brca, verbose = FALSE)
rainfallPlot(maf = brca, detectChangePoints = TRUE, pointSize = 0.6)
#> Chromosome Start_Position End_Position nMuts Avg_intermutation_dist
#> 1: 8 98129391 98133560 6 833.8000
#> 2: 8 98398603 98403536 8 704.7143
#> 3: 8 98453111 98456466 8 479.2857
#> 4: 8 124090506 124096810 21 315.2000
#> 5: 12 97437934 97439705 6 354.2000
#> 6: 17 29332130 29336153 7 670.5000
#> Size Tumor_Sample_Barcode C>G C>T
#> 1: 4169 TCGA-A8-A08B 4 2
#> 2: 4933 TCGA-A8-A08B 1 7
#> 3: 3355 TCGA-A8-A08B NA 8
#> 4: 6304 TCGA-A8-A08B 1 20
#> 5: 1771 TCGA-A8-A08B 3 3
#> 6: 4023 TCGA-A8-A08B 4 3
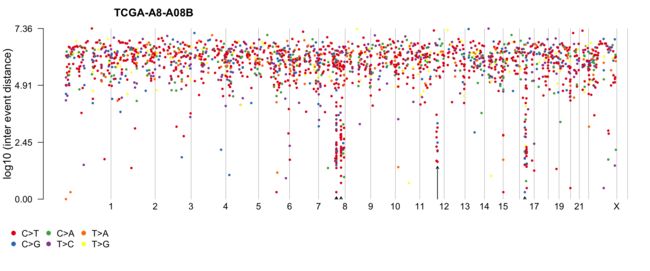
“Kataegis”被定义为包含6个或更多连续突变、平均突变间距离小于或等于100bp的基因组片段5。
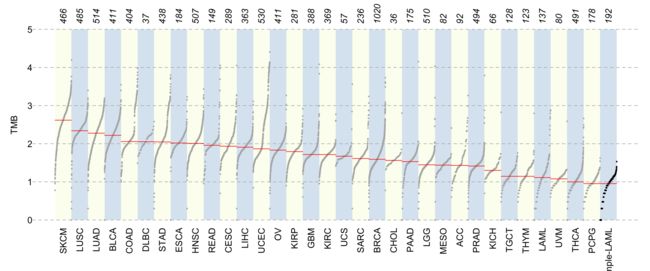
7.7将突变载量与TCGA队列进行比较
TCGA包含30多个不同的癌症队列,它们之间的中位突变载量从低至7个外显子(嗜铬细胞瘤和肾上腺副神经节瘤)到高达315个外显子(皮肤黑色素瘤)不等。看看给定MAF中的突变负荷如何与TCGA队列相抗衡,这是很有意义的。这可以通过函数tcgaComapre来实现,该函数绘制从33个TCGA地标队列中的10000多个WXS样本编译而成的变异的分布。生成的图类似于Alexandrov等人5的描述。
laml.mutload = tcgaCompare(maf = laml, cohortName = 'Example-LAML')
7.8 Plotting VAF
此函数将不同的等位基因频率绘制为箱式图,这有助于快速估计顶级突变基因的克隆状态(假设纯样本,克隆基因的平均等位基因频率通常在~50%左右)。
plotVaf(maf = laml, vafCol = 'i_TumorVAF_WU')

7.9 Genecloud
我们可以用geneCloud函数绘制突变基因的文字云图。每个基因的大小与其突变/变异的样本总数成正比。
geneCloud(input = laml, minMut = 3)

8 处理拷贝数数据
8.1.读取并汇总gistic输出文件
我们可以汇总GISTIC程序生成的输出文件。如前所述,我们需要GISTIC生成的四个文件,即all_lesions.conf_XX.txt、amp_genes.conf_XX.txt、del_genes.conf_XX.txt和scores.gistic,其中XX为置信度。详情见GISTIC documentation]。
all.lesions <- system.file("extdata", "all_lesions.conf_99.txt", package = "maftools")
amp.genes <- system.file("extdata", "amp_genes.conf_99.txt", package = "maftools")
del.genes <- system.file("extdata", "del_genes.conf_99.txt", package = "maftools")
scores.gis <- system.file("extdata", "scores.gistic", package = "maftools")
laml.gistic = readGistic(gisticAllLesionsFile = all.lesions, gisticAmpGenesFile = amp.genes, gisticDelGenesFile = del.genes, gisticScoresFile = scores.gis, isTCGA = TRUE)
#> -Processing Gistic files..
#> --Processing amp_genes.conf_99.txt
#> --Processing del_genes.conf_99.txt
#> --Processing scores.gistic
#> --Summarizing by samples
#GISTIC object
laml.gistic
#> An object of class GISTIC
#> ID summary
#> 1: Samples 191
#> 2: nGenes 2622
#> 3: cytoBands 16
#> 4: Amp 388
#> 5: Del 26481
#> 6: total 26869
与MAF对象类似,访问GISTIC对象slots的方法有getSampleSummary、getGeneSummary和getCytoBandSummary。可以使用write.Gistic Summary函数将汇总结果写入输出文件。 ### 8.2可视化GISTIC结果。 有三种类型的曲线图可用于可视化GISTIC结果。
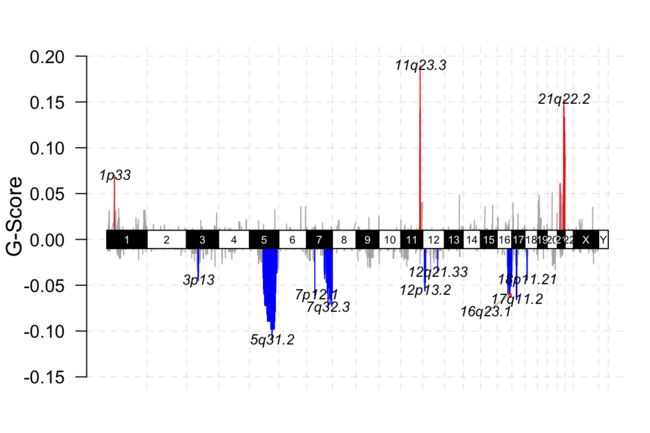
8.2.1基因组图
gisticChromPlot(gistic = laml.gistic, markBands = "all")
8.2.2 Bubble plot
gisticBubblePlot(gistic = laml.gistic)

8.2.3 oncoplot
除了拷贝数数据外,与oncoplots类似。如果有注释,可以再次根据注释对矩阵进行排序。下图是LAML的GISTIC结果,根据FAB分类排序。结果表明,7q缺失在M4亚型中几乎不存在,而在其他亚型中普遍存在。
gisticOncoPlot(gistic = laml.gistic, clinicalData = getClinicalData(x = laml), clinicalFeatures = 'FAB_classification', sortByAnnotation = TRUE, top = 10)

8.2.4 Visualizing CBS segments
tcga.ab.009.seg <- system.file("extdata", "TCGA.AB.3009.hg19.seg.txt", package = "maftools")
plotCBSsegments(cbsFile = tcga.ab.009.seg)
#> NULL

9 数据分析
9.1 体细胞突变互动
许多癌症致病基因在其突变模式中是共生的或表现出很强的排他性。这种互斥或共现的基因组可以使用somaticInteractions函数来检测,该函数执行成对的费舍尔精确测试来检测这种重要的基因对。somaticInteractions函数还使用cometExactTest来识别涉及6中>2 个基因的潜在改变的基因组。
#exclusive/co-occurance event analysis on top 10 mutated genes.
somaticInteractions(maf = laml, top = 25, pvalue = c(0.05, 0.1))

#> gene1 gene2 pValue oddsRatio 00 11 01 10 Event
#> 1: ASXL1 RUNX1 0.0001541586 55.215541 176 4 12 1 Co_Occurence
#> 2: IDH2 RUNX1 0.0002809928 9.590877 164 7 9 13 Co_Occurence
#> 3: IDH2 ASXL1 0.0004030636 41.077327 172 4 1 16 Co_Occurence
#> 4: FLT3 NPM1 0.0009929836 3.763161 125 17 16 35 Co_Occurence
#> 5: SMC3 DNMT3A 0.0010451985 20.177713 144 6 42 1 Co_Occurence
#> ---
#> 296: PLCE1 ASXL1 1.0000000000 0.000000 184 0 5 4 Mutually_Exclusive
#> 297: RAD21 FAM5C 1.0000000000 0.000000 183 0 5 5 Mutually_Exclusive
#> 298: PLCE1 FAM5C 1.0000000000 0.000000 184 0 5 4 Mutually_Exclusive
#> 299: PLCE1 RAD21 1.0000000000 0.000000 184 0 5 4 Mutually_Exclusive
#> 300: EZH2 PLCE1 1.0000000000 0.000000 186 0 4 3 Mutually_Exclusive
#> pair event_ratio
#> 1: ASXL1, RUNX1 4/13
#> 2: IDH2, RUNX1 7/22
#> 3: ASXL1, IDH2 4/17
#> 4: FLT3, NPM1 17/51
#> 5: DNMT3A, SMC3 6/43
#> ---
#> 296: ASXL1, PLCE1 0/9
#> 297: FAM5C, RAD21 0/10
#> 298: FAM5C, PLCE1 0/9
#> 299: PLCE1, RAD21 0/9
#> 300: EZH2, PLCE1 0/7
9.2 基于位置聚类的癌症驱动基因检测
maftools有一个名为oncodrive的函数,它可以从给定的MAF中识别癌症基因(driver gene)。oncodrive是一个基于oncodriveCLUST算法的函数,最初是用Python语言实现的。这一概念是基于这样一个事实,即致癌基因中的大多数变异在少数几个特定的位点(也就是热点)上富集。这种方法利用这些位置来识别癌症基因。如果您使用此函数,请注明OncodriveCLUST article 7引用。
laml.sig = oncodrive(maf = laml, AACol = 'Protein_Change', minMut = 5, pvalMethod = 'zscore')
head(laml.sig)
#> Hugo_Symbol Frame_Shift_Del Frame_Shift_Ins In_Frame_Del In_Frame_Ins
#> 1: IDH1 0 0 0 0
#> 2: IDH2 0 0 0 0
#> 3: NPM1 0 33 0 0
#> 4: NRAS 0 0 0 0
#> 5: U2AF1 0 0 0 0
#> 6: KIT 1 1 0 1
#> Missense_Mutation Nonsense_Mutation Splice_Site total MutatedSamples
#> 1: 18 0 0 18 18
#> 2: 20 0 0 20 20
#> 3: 1 0 0 34 33
#> 4: 15 0 0 15 15
#> 5: 8 0 0 8 8
#> 6: 7 0 0 10 8
#> AlteredSamples clusters muts_in_clusters clusterScores protLen zscore
#> 1: 18 1 18 1.0000000 414 5.546154
#> 2: 20 2 20 1.0000000 452 5.546154
#> 3: 33 2 32 0.9411765 294 5.093665
#> 4: 15 2 15 0.9218951 189 4.945347
#> 5: 8 1 7 0.8750000 240 4.584615
#> 6: 8 2 9 0.8500000 976 4.392308
#> pval fdr fract_muts_in_clusters
#> 1: 1.460110e-08 1.022077e-07 1.0000000
#> 2: 1.460110e-08 1.022077e-07 1.0000000
#> 3: 1.756034e-07 8.194826e-07 0.9411765
#> 4: 3.800413e-07 1.330144e-06 1.0000000
#> 5: 2.274114e-06 6.367520e-06 0.8750000
#> 6: 5.607691e-06 1.308461e-05 0.9000000
可以用plotOncodrive来绘制这些结果.
plotOncodrive(res = laml.sig, fdrCutOff = 0.1, useFraction = TRUE)

9.3 Adding and summarizing pfam domains
maftools附带了函数pfamDomains,该函数将pfam结构域信息添加到氨基酸变化中。pnamDomain还根据受影响的结构域汇总氨基酸变化。这是为了知道在给定的癌症队列中,哪个结构域最容易受到影响。该函数的灵感来自于MuSic tool 8中的PFAM注释模块。
laml.pfam = pfamDomains(maf = laml, AACol = 'Protein_Change', top = 10)
#> Warning in pfamDomains(maf = laml, AACol = "Protein_Change", top = 10):
#> Removed 50 mutations for which AA position was not available

#Protein summary (Printing first 7 columns for display convenience)
laml.pfam$proteinSummary[,1:7, with = FALSE]
#> HGNC AAPos Variant_Classification N total fraction DomainLabel
#> 1: DNMT3A 882 Missense_Mutation 27 54 0.5000000 AdoMet_MTases
#> 2: IDH1 132 Missense_Mutation 18 18 1.0000000 PTZ00435
#> 3: IDH2 140 Missense_Mutation 17 20 0.8500000 PTZ00435
#> 4: FLT3 835 Missense_Mutation 14 52 0.2692308 PKc_like
#> 5: FLT3 599 In_Frame_Ins 10 52 0.1923077 PKc_like
#> ---
#> 1512: ZNF646 875 Missense_Mutation 1 1 1.0000000
#> 1513: ZNF687 554 Missense_Mutation 1 2 0.5000000
#> 1514: ZNF687 363 Missense_Mutation 1 2 0.5000000
#> 1515: ZNF75D 5 Missense_Mutation 1 1 1.0000000
#> 1516: ZNF827 427 Frame_Shift_Del 1 1 1.0000000
#Domain summary (Printing first 3 columns for display convenience)
laml.pfam$domainSummary[,1:3, with = FALSE]
#> DomainLabel nMuts nGenes
#> 1: PKc_like 55 5
#> 2: PTZ00435 38 2
#> 3: AdoMet_MTases 33 1
#> 4: 7tm_1 24 24
#> 5: COG5048 17 17
#> ---
#> 499: ribokinase 1 1
#> 500: rim_protein 1 1
#> 501: sigpep_I_bact 1 1
#> 502: trp 1 1
#> 503: zf-BED 1 1
上面的图和结果表明,AdoMet_MTases结构域经常发生突变,但与7tm_1结构域等其他结构域相比,含有该结构域的基因只有一个(DNMT3A),后者在24个不同的基因中发生了突变。这表明了甲基转移结构域突变在白血病中的重要性。
9.4 Pan-Cancer comparison
Lawrence等人对21个癌症队列进行了MutSigCV分析,确定了200多个显著突变的基因,其中包括以前未订阅的新基因9。他们的结果表明,只有少数基因在多个队列中发生突变,而其中许多基因是组织/队列特异性的。我们可以将mutSig结果与这个泛癌显著突变基因列表进行比较,以查看特定队列中特定突变的基因。此函数需要MutSigCV结果(通常名为sig_genes.txt)作为输入。
#MutsigCV results for TCGA-AML
laml.mutsig <- system.file("extdata", "LAML_sig_genes.txt.gz", package = "maftools")
pancanComparison(mutsigResults = laml.mutsig, qval = 0.1, cohortName = 'LAML', inputSampleSize = 200, label = 1)
#> gene pancan q nMut log_q_pancan log_q
#> 1: CEBPA 1.000 3.500301e-12 13 0.00000000 11.455895
#> 2: EZH2 1.000 7.463546e-05 3 0.00000000 4.127055
#> 3: GIGYF2 1.000 6.378338e-03 2 0.00000000 2.195292
#> 4: KIT 0.509 1.137517e-05 8 0.29328222 4.944042
#> 5: PHF6 0.783 6.457555e-09 6 0.10623824 8.189932
#> 6: PTPN11 0.286 7.664584e-03 9 0.54363397 2.115511
#> 7: RAD21 0.929 1.137517e-05 5 0.03198429 4.944042
#> 8: SMC1A 0.801 2.961696e-03 6 0.09636748 2.528460
#> 9: TET2 0.907 2.281625e-13 17 0.04239271 12.641756
#> 10: WT1 1.000 2.281625e-13 12 0.00000000 12.641756

#> gene pancan q nMut log_q_pancan log_q
#> 1: ACVR1B 6.11e-02 1.000000e+00 0 1.213959 0.00000
#> 2: AKT1 2.68e-10 1.000000e+00 0 9.571865 0.00000
#> 3: APC 1.36e-13 1.000000e+00 0 12.866461 0.00000
#> 4: APOL2 7.96e-03 1.000000e+00 0 2.099087 0.00000
#> 5: ARHGAP35 2.32e-12 1.000000e+00 1 11.634512 0.00000
#> ---
#> 120: U2AF1 4.07e-08 4.503311e-13 8 7.390406 12.34647
#> 121: VHL 2.32e-12 1.000000e+00 0 11.634512 0.00000
#> 122: WT1 1.00e+00 2.281625e-13 12 0.000000 12.64176
#> 123: ZNF180 8.60e-02 1.000000e+00 0 1.065502 0.00000
#> 124: ZNF483 2.37e-02 1.000000e+00 0 1.625252 0.00000
9.5生存分析
生存分析是基于队列的测序项目的重要组成部分。函数mafSurvive根据用户定义基因的突变状态或手动提供的组成一组的样本进行分组,进行生存分析并绘制Kaplan Meier曲线。此函数要求输入数据包含TOMOR_SAMPLE_BARCODE(请确保与MAF文件中的匹配)、二进制事件(1/0)和到达事件的时间。 我们的注释数据已经包含生存信息,如果您将生存数据存储在单独的表中,请通过参数clinicalData
9.5.1在任何给定基因中突变来提供这些数据
#Survival analysis based on grouping of DNMT3A mutation status
mafSurvival(maf = laml, genes = 'DNMT3A', time = 'days_to_last_followup', Status = 'Overall_Survival_Status', isTCGA = TRUE)
#> DNMT3A
#> 48
#> Group medianTime N
#> 1: Mutant 245 45
#> 2: WT 396 137

9.5.2 Predict genesets associated with survival
确定导致生存不良的一组基因
#Using top 20 mutated genes to identify a set of genes (of size 2) to predict poor prognostic groups
prog_geneset = survGroup(maf = laml, top = 20, geneSetSize = 2, time = "days_to_last_followup", Status = "Overall_Survival_Status", verbose = FALSE)
print(prog_geneset)
#> Gene_combination P_value hr WT Mutant
#> 1: FLT3_DNMT3A 0.00104 2.510 164 18
#> 2: DNMT3A_SMC3 0.04880 2.220 176 6
#> 3: DNMT3A_NPM1 0.07190 1.720 166 16
#> 4: DNMT3A_TET2 0.19600 1.780 176 6
#> 5: FLT3_TET2 0.20700 1.860 177 5
#> 6: NPM1_IDH1 0.21900 0.495 176 6
#> 7: DNMT3A_IDH1 0.29300 1.500 173 9
#> 8: IDH2_RUNX1 0.31800 1.580 176 6
#> 9: FLT3_NPM1 0.53600 1.210 165 17
#> 10: DNMT3A_IDH2 0.68000 0.747 178 4
#> 11: DNMT3A_NRAS 0.99200 0.986 178 4
以上结果显示与生存不良相关的基因组合(N=2)(P < 0.05)。利用函数mafSurvGroup可以绘制上述结果的KM曲线
mafSurvGroup(maf = laml, geneSet = c("DNMT3A", "FLT3"), time = "days_to_last_followup", Status = "Overall_Survival_Status")
#> Group medianTime N
#> 1: Mutant 242.5 18
#> 2: WT 379.5 164

9.6.对比两个队列(MAF)。
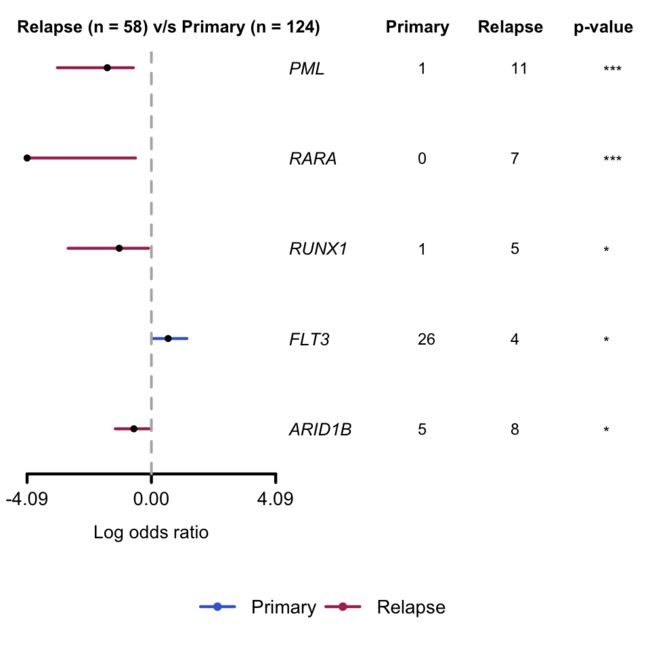
癌症在突变模式方面各不相同。我们可以比较两个不同的队列来检测这种差异突变的基因。例如,Madan et. al 9的研究表明,复发的急性早幼粒细胞白血病(APL)患者往往存在PML和RAR基因突变,而这两种基因在疾病的初发期是不存在的。可以使用函数mafComapre来检测两个队列(在这种情况下是原发性和复发性APL)之间的这种差异,该函数对两个队列之间的所有基因执行Fisher测试,以检测差异突变的基因。
#Primary APL MAF
primary.apl = system.file("extdata", "APL_primary.maf.gz", package = "maftools")
primary.apl = read.maf(maf = primary.apl)
#Relapse APL MAF
relapse.apl = system.file("extdata", "APL_relapse.maf.gz", package = "maftools")
relapse.apl = read.maf(maf = relapse.apl)
9.6.1 Forest plots 森林图
以上结果显示两个基因PML和RARA在复发性APL中较原发性APL高度突变。我们可以将这些结果可视化为 forestplot森林图。
#Considering only genes which are mutated in at-least in 5 samples in one of the cohort to avoid bias due to genes mutated in single sample.
pt.vs.rt <- mafCompare(m1 = primary.apl, m2 = relapse.apl, m1Name = 'Primary', m2Name = 'Relapse', minMut = 5)
print(pt.vs.rt)
#> $results
#> Hugo_Symbol Primary Relapse pval or ci.up
#> 1: PML 1 11 1.529935e-05 0.03537381 0.2552937
#> 2: RARA 0 7 2.574810e-04 0.00000000 0.3006159
#> 3: RUNX1 1 5 1.310500e-02 0.08740567 0.8076265
#> 4: FLT3 26 4 1.812779e-02 3.56086275 14.7701728
#> 5: ARID1B 5 8 2.758396e-02 0.26480490 0.9698686
#> 6: WT1 20 14 2.229087e-01 0.60619329 1.4223101
#> 7: KRAS 6 1 4.334067e-01 2.88486293 135.5393108
#> 8: NRAS 15 4 4.353567e-01 1.85209500 8.0373994
#> 9: ARID1A 7 4 7.457274e-01 0.80869223 3.9297309
#> ci.low adjPval
#> 1: 0.000806034 0.0001376942
#> 2: 0.000000000 0.0011586643
#> 3: 0.001813280 0.0393149868
#> 4: 1.149009169 0.0407875250
#> 5: 0.064804160 0.0496511201
#> 6: 0.263440988 0.3343630535
#> 7: 0.337679367 0.4897762916
#> 8: 0.553883512 0.4897762916
#> 9: 0.195710173 0.7457273717
#>
#> $SampleSummary
#> Cohort SampleSize
#> 1: Primary 124
#> 2: Relapse 58
forestPlot(mafCompareRes = pt.vs.rt, pVal = 0.1, color = c('royalblue', 'maroon'), geneFontSize = 0.8)
9.6.2 Co-onco plots
显示上述结果的另一种替代方式是并排绘制两个oncoplots。coOncoplot函数获取两个maf对象并并排打印,以便更好地进行比较。
genes = c("PML", "RARA", "RUNX1", "ARID1B", "FLT3")
coOncoplot(m1 = primary.apl, m2 = relapse.apl, m1Name = 'PrimaryAPL', m2Name = 'RelapseAPL', genes = genes, removeNonMutated = TRUE)

#coBarplot(m1 = primary.apl, m2 = relapse.apl, m1Name = "Primary", m2Name = "Relapse")
9.6.3 Lollipop plot-2棒棒糖图
以及显示队列差异的曲线图,也可以用lollipopPlot2函数显示基因差异。
lollipopPlot2(m1 = primary.apl, m2 = relapse.apl, gene = "PML", AACol1 = "amino_acid_change", AACol2 = "amino_acid_change", m1_name = "Primary", m2_name = "Relapse")

9.7 临床富集分析
clinicalEnrichment是另一个函数,它提取与样本相关的任何临床特征并进行富集分析。它执行各种groupwise和pairwise成对比较,以确定临床特征中每个类别的丰富突变。下面是一个识别与FAB_classfication相关的突变的示例。
fab.ce = clinicalEnrichment(maf = laml, clinicalFeature = 'FAB_classification')
#>
#> M0 M1 M2 M3 M4 M5 M6 M7
#> 19 44 44 21 39 19 3 3
#Results are returned as a list. Significant associations p-value < 0.05
fab.ce$groupwise_comparision[p_value < 0.05]
#> Hugo_Symbol Group1 Group2 n_mutated_group1 n_mutated_group2
#> 1: IDH1 M1 Rest 11 of 44 7 of 149
#> 2: TP53 M7 Rest 3 of 3 12 of 190
#> 3: DNMT3A M5 Rest 10 of 19 38 of 174
#> 4: CEBPA M2 Rest 7 of 44 6 of 149
#> 5: RUNX1 M0 Rest 5 of 19 11 of 174
#> 6: NPM1 M5 Rest 7 of 19 26 of 174
#> 7: CEBPA M1 Rest 6 of 44 7 of 149
#> p_value OR_low OR_high fdr
#> 1: 0.0002597371 0 0.3926994 0.0308575
#> 2: 0.0003857187 0 0.1315271 0.0308575
#> 3: 0.0057610493 0 0.6406007 0.3072560
#> 4: 0.0117352110 0 0.6874270 0.3757978
#> 5: 0.0117436825 0 0.6466787 0.3757978
#> 6: 0.0248582372 0 0.8342897 0.6628863
#> 7: 0.0478737468 0 0.9869971 1.0000000
以上结果表明,与队列的其余部分相比,IDH1突变在M1亚型白血病中富集。同样,DNMT3A在M5中,RUNX1在M0中,依此类推。这些都是众所周知的结果,此函数有效地重新捕获了它们。可以使用任何类型的临床特征来执行这样的分析。还有一个小函数-plotEnrichmentResults,可用于绘制这些结果。
plotEnrichmentResults(enrich_res = fab.ce, pVal = 0.05)

9.8 药物与基因的相互作用
从药物基因相互作用数据库汇编而来的药物-基因相互作用和基因和药性信息可用drugInteractions函数查询
dgi = drugInteractions(maf = laml, fontSize = 0.75)

上图显示了潜在的可用药基因类别,以及与之相关的最多5个基因。人们还可以提取关于药物与基因相互作用的信息。例如,下面是已知/报告的药物与DNMT3A相互作用的结果。
dnmt3a.dgi = drugInteractions(genes = "DNMT3A", drugs = TRUE)
#> Number of claimed drugs for given genes:
#> Gene N
#> 1: DNMT3A 7
#Printing selected columns.
dnmt3a.dgi[,.(Gene, interaction_types, drug_name, drug_claim_name)]
#> Gene interaction_types drug_name drug_claim_name
#> 1: DNMT3A N/A
#> 2: DNMT3A DAUNORUBICIN Daunorubicin
#> 3: DNMT3A DECITABINE Decitabine
#> 4: DNMT3A IDARUBICIN IDARUBICIN
#> 5: DNMT3A DECITABINE DECITABINE
#> 6: DNMT3A inhibitor DECITABINE CHEMBL1201129
#> 7: DNMT3A inhibitor AZACITIDINE CHEMBL1489
如果您认为此函数对你有用 10,请引用DGIdb article。 免责声明:此功能中使用的资源仅用于研究目的。它不应用于紧急情况或医疗或专业建议。。
9.9致癌信号通路
OncogenicPathways函数查看TCGA队列中已知的致癌信号通路的富集情况 11。
OncogenicPathways(maf = laml)
#> Pathway N n_affected_genes fraction_affected
#> 1: RTK-RAS 85 18 0.21176471
#> 2: Hippo 38 7 0.18421053
#> 3: NOTCH 71 6 0.08450704
#> 4: MYC 13 3 0.23076923
#> 5: WNT 68 3 0.04411765
#> 6: TP53 6 2 0.33333333
#> 7: NRF2 3 1 0.33333333
#> 8: PI3K 29 1 0.03448276
#> 9: Cell_Cycle 15 0 0.00000000
#> 10: TGF-Beta 7 0 0.00000000

也有可能将完整的通路可视化。
PlotOncogenicPathways(maf = laml, pathways = "RTK-RAS")

抑癌基因用红色表示,癌基因用蓝色字体表示。
9.10 肿瘤异质性与数学成绩
9.10.1 肿瘤样本的异质性
肿瘤一般是异质性的,即由多个克隆组成。这种异质性可以通过聚类不同的等位基因频率来推断。inserHetereneity函数使用VAF信息对变量进行聚类(使用mclust),从而推断出克隆性。默认情况下,inserverHetereneity函数查找包含VAF信息的t_vaf列。但是,如果字段名称与t_vaf不同,我们可以使用参数vafCol手动指定。例如,在本例中,研究vaf存储在字段名i_TumorVAF_WU下。
#Heterogeneity in sample TCGA.AB.2972
tcga.ab.2972.het = inferHeterogeneity(maf = laml, tsb = 'TCGA-AB-2972', vafCol = 'i_TumorVAF_WU')
print(tcga.ab.2972.het$clusterMeans)
#> Tumor_Sample_Barcode cluster meanVaf
#> 1: TCGA-AB-2972 2 0.4496571
#> 2: TCGA-AB-2972 1 0.2454750
#> 3: TCGA-AB-2972 outlier 0.3695000
#Visualizing results
plotClusters(clusters = tcga.ab.2972.het)
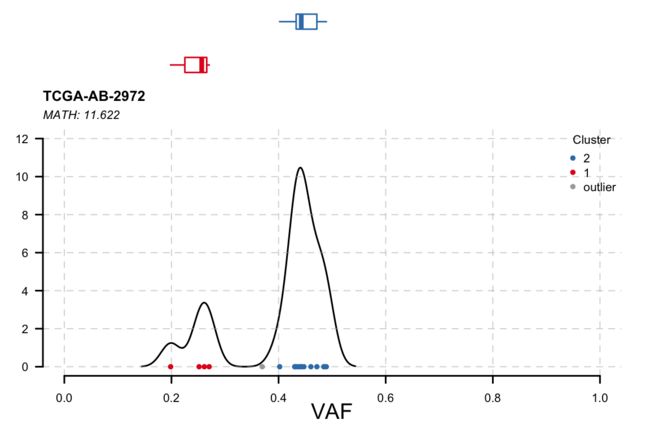
上图清楚地显示了两个平均变异等位基因频率为45%的克隆(主克隆)和另一个次要克隆的变异等位基因频率为25%。 虽然变异等位基因频率的聚类使我们对异质性有了一个很好的认识,但也可以用数值来衡量异质性的程度。MATH score(上图中的副标题)是肿瘤内异质性的一种简单的定量测量,它计算出VAF分布的宽度。研究发现,较高的MATH scores 与较差的结果有关。MATH score也可以作为生存分析的代理变量-11.
9.10.2 忽略拷贝数更改区域的变异。
我们可以使用拷贝数信息来忽略位于拷贝数改变区域的变异。拷贝数改变会导致变异等位基因频率异常高/低,这往往会影响聚类。去除这些变异可以改进聚类和密度估计,同时保留有生物学意义的结果。拷贝数信息可以作为从分割程序生成的分割文件来提供,例如来自“DNACopy” Bioconductor package的圆形二进制分割的R包6
seg = system.file('extdata', 'TCGA.AB.3009.hg19.seg.txt', package = 'maftools')
tcga.ab.3009.het = inferHeterogeneity(maf = laml, tsb = 'TCGA-AB-3009', segFile = seg, vafCol = 'i_TumorVAF_WU')
#> Hugo_Symbol Chromosome Start_Position End_Position Tumor_Sample_Barcode
#> 1: PHF6 23 133551224 133551224 TCGA-AB-3009
#> t_vaf Segment_Start Segment_End Segment_Mean CN
#> 1: 0.9349112 NA NA NA NA
#> Hugo_Symbol Chromosome Start_Position End_Position Tumor_Sample_Barcode
#> 1: NF1 17 29562981 29562981 TCGA-AB-3009
#> 2: SUZ12 17 30293198 30293198 TCGA-AB-3009
#> t_vaf Segment_Start Segment_End Segment_Mean CN cluster
#> 1: 0.8419000 29054355 30363868 -0.9157 1.060173 CN_altered
#> 2: 0.8958333 29054355 30363868 -0.9157 1.060173 CN_altered
#Visualizing results. Highlighting those variants on copynumber altered variants.
plotClusters(clusters = tcga.ab.3009.het, genes = 'CN_altered', showCNvars = TRUE)

上图显示了两个VAF高的基因NF1和SUZ12,这是由于拷贝数变异(缺失)所致。这两个基因在分析中被忽略了。
9.11 突变Signatures
每一种癌症,在进展过程中都会留下一个Signatures,其Signatures是特定的核苷酸替换模式。 Alexandrov et.al已经显示出这样的突变signatures,源自5的7,000多个癌症样本。这样的signatures可以通过分解核苷酸替换矩阵来提取,基于突变碱基周围的直接碱基将其分类为96个替换类别。还可以将提取的signatures与那些signatures进行比较validated signatures。 signatures分析的第一步是获得突变碱基周围的相邻碱基,并形成突变矩阵。
注意:早期版本的maftools需要一个
fasta文件作为输入。但是从1.8.0开始,BSgenome对象被用于更快的序列提取。
#Requires BSgenome object
library(BSgenome.Hsapiens.UCSC.hg19, quietly = TRUE)
laml.tnm = trinucleotideMatrix(maf = laml, prefix = 'chr', add = TRUE, ref_genome = "BSgenome.Hsapiens.UCSC.hg19")
#> Warning in trinucleotideMatrix(maf = laml, prefix = "chr", add = TRUE, ref_genome = "BSgenome.Hsapiens.UCSC.hg19"): Chromosome names in MAF must match chromosome names in reference genome.
#> Ignorinig 101 single nucleotide variants from missing chromosomes chr23
#> -Extracting 5' and 3' adjacent bases
#> -Extracting +/- 20bp around mutated bases for background C>T estimation
#> -Estimating APOBEC enrichment scores
#> --Performing one-way Fisher's test for APOBEC enrichment
#> ---APOBEC related mutations are enriched in 3.315 % of samples (APOBEC enrichment score > 2 ; 6 of 181 samples)
#> -Creating mutation matrix
#> --matrix of dimension 188x96
上述功能执行两个步骤: * 估计APOBEC富集分数 * 为signature分析准备突变矩阵。
9.11.1 APOBEC Enrichment estimation.
APOBEC诱导的突变在实体瘤中更为常见,并且主要与TCW基序中发生的C>T转换事件有关。上述命令中的APOBEC富集分数是使用Roberts et al 13描述的方法估计的。简而言之,将发生在TCW基序内的C>T突变富集在给定样本中的所有C>T突变上,并将其与背景胞嘧啶和发生在突变碱基20bp内的TCW进行比较。

如Roberts等人的原始研究中所描述的,还执行单侧fishers精确测试以统计地评估富集分数。
9.11.2 APOBEC富集与非富集的区别。
我们还可以分析APOBEC富集型和非APOBEC富集型的突变模式的差异,plotApobecDiff是一个函数,它取trinucleotideMatrix估计的APOBEC富集值,将样本分为APOBEC富集型和非APOBEC富集型。一旦分层,它就会比较这两组人,以确定差异改变的基因。 请注意,没有APOBEC富集的LAML不是此类分析的理想队列,因此下面的图表仅用于演示目的。
plotApobecDiff(tnm = laml.tnm, maf = laml, pVal = 0.2)

#> $results
#> Hugo_Symbol Enriched nonEnriched pval or ci.up
#> 1: TP53 2 13 0.08175632 5.9976455 46.608861
#> 2: TET2 1 16 0.45739351 1.9407002 18.983979
#> 3: FLT3 2 45 0.65523131 1.4081851 10.211621
#> 4: DNMT3A 1 47 1.00000000 0.5335362 4.949499
#> 5: ADAM11 0 2 1.00000000 0.0000000 164.191472
#> ---
#> 132: WAC 0 2 1.00000000 0.0000000 164.191472
#> 133: WT1 0 12 1.00000000 0.0000000 12.690862
#> 134: ZBTB33 0 2 1.00000000 0.0000000 164.191472
#> 135: ZC3H18 0 2 1.00000000 0.0000000 164.191472
#> 136: ZNF687 0 2 1.00000000 0.0000000 164.191472
#> ci.low adjPval
#> 1: 0.49875432 1
#> 2: 0.03882963 1
#> 3: 0.12341748 1
#> 4: 0.01101929 1
#> 5: 0.00000000 1
#> ---
#> 132: 0.00000000 1
#> 133: 0.00000000 1
#> 134: 0.00000000 1
#> 135: 0.00000000 1
#> 136: 0.00000000 1
#>
#> $SampleSummary
#> Cohort SampleSize Mean Median
#> 1: Enriched 6 7.167 6.5
#> 2: nonEnriched 172 9.715 9.0
9.11.3 Signature分析。
Signature分析包括以下步骤。 - 1.estimateSignatures -在一系列值上运行NMF,并衡量拟合的好坏-以时间为单位Cophenetic correlation。 - 2.plotCophenetic-绘制elblow图,帮助您确定最佳Signature数量。最佳可能的Signature是共生相关性显著下降的值。 - 3.ExtractSignaturesSignature-使用非负矩阵分解将矩阵分解为三个N个Signature,根据上述两个步骤选择N个Signature。如果您已经对N‘有了很好的估计,您可以跳过以上两步。 - 4.将上述步骤中提取的SignaturecompareSignatures与signatures[11](http://127.0.0.1:25995/library/maftools/doc/maftools.html#references)数据库中已知的[COSMIC](https://cancer.sanger.ac.uk/cosmic/signatures/SBS/)签名进行比对,并计算余弦相似度,确定最佳匹配。 - 5.plotSignatures`-plots signatures
注意:在以前的版本中,上述步骤都是由ExtractSignatures自动完成的。在2.2.0版本之后,Main函数被拆分成不超过5个stpe,以方便用户灵活使用。

# library('NMF')
# laml.sign = estimateSignatures(mat = laml.tnm, nTry = 6)
绘制elbow曲线图,根据上述结果可视化并确定最佳signatures数量。
plotCophenetic(res = laml.sign)

# laml.sig = extractSignatures(mat = laml.tnm, n = 3)
最佳可能值是y轴上的相关值显著下降的值。在这种情况下,它看起来是在n = 3。LAML的突变率较低,不是特征分析的理想例子,但对于突变负担较高的实体肿瘤,只要有足够数量的样本,就可以期待更多的特征。 一旦估计了n,我们就可以运行main函数了。
将检测到的signatures与COSMIC数据库中的已知signatures进行比较。
#Compate against original 30 signatures
laml.og30.cosm = compareSignatures(nmfRes = laml.sig, sig_db = "legacy")
#Compate against updated version3 60 signatures
laml.v3.cosm = compareSignatures(nmfRes = laml.sig, sig_db = "SBS")
compareSignatures返回COSMICsignatures余弦相似度的完整表,可以进一步分析。下图显示了检测到的signatures与验证过的signatures的相似性比较。
library('pheatmap')
pheatmap::pheatmap(mat = laml.og30.cosm$cosine_similarities, cluster_rows = FALSE, main = "cosine similarity against validated signatures")

Finally plot signatures
maftools::plotSignatures(nmfRes = laml.sig, title_size = 0.8, sig_db = "SBS")

注: - 1.如果您在运行extractSignatures时收到none of the packages are loaded的错误,请手动加载NMF库并重新运行。 - 2.如果extractSignatures或estimateSignatures在两者之间停止,则可能是因为矩阵中的突变计数较低。在这种情况下,重新运行pConstant参数设置为小正值(例如0.1)的函数。
9.11.4 Signature enrichment analysis
Signature可以进一步赋值给样本,并使用signatureEnrichment函数进行富集分析,该函数识别每个识别出的Signature中富集的突变。
# library("barplot3d")
# #Visualize first signature
# sig1 = laml.sig$signatures[,1]
# barplot3d::legoplot3d(contextdata = sig1, labels = FALSE, scalexy = 0.01, sixcolors = "sanger", alpha = 0.5)
laml.se = signatureEnrichment(maf = laml, sig_res = laml.sig)
#>
#> Signature_1 Signature_2 Signature_3
#> 60 65 63
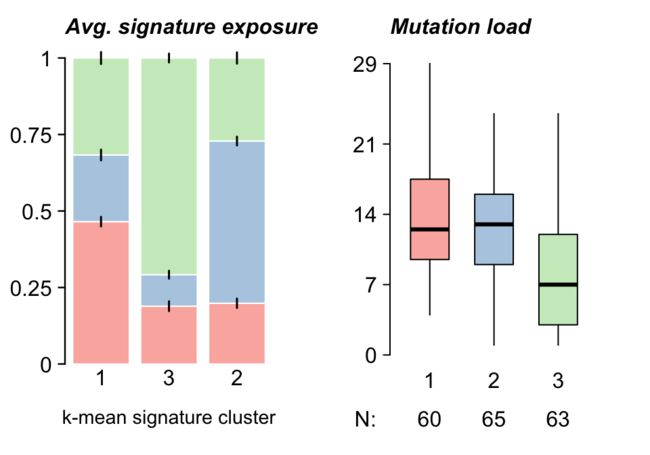
上述结果可进行和临床结果相似的可视化操作。
plotEnrichmentResults(enrich_res = laml.se, pVal = 0.05)

10 变异的注释
10.1 将annovar注释结果转换为MAF
ANNOVAR是基因组学17中使用最广泛的变异注释工具之一。ANNOVAR输出通常是具有各种注释列的表格格式。此函数用于将此类注解输出文件转换为MAF。此函数要求在包含任何基于过滤或区域的注释之前,将基于基因的注释作为第一个操作来运行注解。 例如,
table_annovar.pl example/ex1.avinput humandb/ -buildver hg19 -out myanno -remove -protocol (refGene),cytoBand,dbnsfp30a -operation (g),r,f -nastring NA
annovarToMaf主要使用基于基因的注释进行处理,输入文件中的其余注释列将附加到生成的MAF的末尾。 作为示例,我们将注释上面用来运行oncotate函数的同一文件。我们将使用以下命令使用Annovar对其进行注释。为简单起见,这里我们只包含基于基因的注释,但是可以根据需要包含任意多的注释。但是要确保第一个操作始终是基于基因的注释。
$perl table_annovar.pl variants.tsv ~/path/to/humandb/ -buildver hg19
-out variants --otherinfo -remove -protocol ensGene -operation g -nastring NA
生成的输出作为此包的一部分存储。我们可以使用annovarToMaf将这个注释输出转换成MAF。
var.annovar = system.file("extdata", "variants.hg19_multianno.txt", package = "maftools")
var.annovar.maf = annovarToMaf(annovar = var.annovar, Center = 'CSI-NUS', refBuild = 'hg19', tsbCol = 'Tumor_Sample_Barcode', table = 'ensGene')
#> -Reading annovar files
#> -Processing Exonic variants
#> --Adding Variant_Classification
#> --Parsing aa-change
#> -Processing Non-exonic variants
#> --Adding Variant_Classification
#> -Adding Variant_Type
#> -Converting Ensemble Gene IDs into HGNC gene symbols
#> --Done. Original ensemble gene IDs are preserved under field name ens_id
#> Finished in 0.204s elapsed (0.778s cpu)
Annovar在用Ensemble作基因注释源时,使用ensemble gene IDs作为基因名称。在这种情况下,使用带有参数table的annovarToMaf,该参数设置为ensGene将ensemble gene IDs转换为HGNC symbols。
10.2 将ICGC简单体细胞突变格式转换为MAF。
就像TCGA一样,国际癌症基因组联盟ICGC也将其数据公之于众。但数据存储在结构上与MAF格式相似的简单体细胞突变Format](http://docs.icgc.org/submission/guide/icgc-simple-somatic-mutation-format/)中。但是变量的字段名称和分类与MAF不同%E4%B8%AD%E3%80%82%E4%BD%86%E6%98%AF%E5%8F%98%E9%87%8F%E7%9A%84%E5%AD%97%E6%AE%B5%E5%90%8D%E7%A7%B0%E5%92%8C%E5%88%86%E7%B1%BB%E4%B8%8EMAF%E4%B8%8D%E5%90%8C),icgcSimpleMutationToMAF是一个读取ICGC数据并将其转换成MAF的函数。
#Read sample ICGC data for ESCA
esca.icgc <- system.file("extdata", "simple_somatic_mutation.open.ESCA-CN.sample.tsv.gz", package = "maftools")
esca.maf <- icgcSimpleMutationToMAF(icgc = esca.icgc, addHugoSymbol = TRUE)
#> --Removed 427 duplicated variants
#Printing first 16 columns for display convenience.
print(esca.maf[1:5,1:16, with = FALSE])
#> Hugo_Symbol Entrez_Gene_Id Center NCBI_Build Chromosome Start_Position
#> 1: AC005237.4 NA NA GRCh37 2 241987787
#> 2: AC061992.1 786 NA GRCh37 17 76425382
#> 3: AC097467.2 NA NA GRCh37 4 156294567
#> 4: ADAMTS12 NA NA GRCh37 5 33684019
#> 5: AL589642.1 54801 NA GRCh37 9 32630154
#> End_Position Strand Variant_Classification Variant_Type
#> 1: 241987787 + Intron SNP
#> 2: 76425382 + 3'Flank SNP
#> 3: 156294567 + Intron SNP
#> 4: 33684019 + Missense_Mutation SNP
#> 5: 32630154 + RNA SNP
#> Reference_Allele Tumor_Seq_Allele1 Tumor_Seq_Allele2 dbSNP_RS
#> 1: C C T NA
#> 2: C C T NA
#> 3: A A G NA
#> 4: A A C NA
#> 5: T T C NA
#> dbSNP_Val_Status Tumor_Sample_Barcode
#> 1: NA SA514619
#> 2: NA SA514619
#> 3: NA SA514619
#> 4: NA SA514619
#> 5: NA SA514619
请注意,默认情况下,简单体细胞突变格式包含一个变异的所有受影响的转录本,从而导致同一样本中有多个相同变异位点的条目。仅根据注释很难选择单个受影响的转录本,并且默认情况下,该软件会删除重复的变异作为重复条目。如果希望全部保留,请将removeDuplicatedVariants设置为FALSE。另一种选择是通过删除重复项将输入文件转换为MAF,然后使用诸如vcf2maf之类的脚本重新注释受影响的脚本并确定优先顺序。
10.3 准备MAF文件进行MutSigCV分析。
MutSig/MutSigCV是18中应用最广泛的驱动基因检测方法。然而,我们观察到与MutSig捆绑在一起的协变量文件(gene.covariates.txt和exome_full192.coverage.txt)具有非标准的基因名称(非Hugo_Symbol)。MAF中的Hugo_Symbol和协变量文件中的非Hugo_Symbol之间的这种差异导致MutSig程序忽略这些基因。例如,KMT2D-一个众所周知的食管癌驱动基因,在MutSig协变量中被表示为MLL2。这会导致KMT2D在分析中被忽略,并在MutSig结果中表示为一个无关紧要的基因。此函数尝试使用与MutSig协变量列表兼容的手动管理的基因名称列表更正此类基因符号。
# laml.mutsig.corrected = prepareMutSig(maf = laml)
# # Converting gene names for 1 variants from 1 genes
# # Hugo_Symbol MutSig_Synonym N
# # 1: ARHGAP35 GRLF1 1
# # Original symbols are preserved under column OG_Hugo_Symbol.
11 设置操作
11.1 子集MAF
我们也可以使用subsetMaf函数来取MAF子集
#Extract data for samples 'TCGA.AB.3009' and 'TCGA.AB.2933' (Printing just 5 rows for display convenience)
subsetMaf(maf = laml, tsb = c('TCGA-AB-3009', 'TCGA-AB-2933'), mafObj = FALSE)[1:5]
#> Hugo_Symbol Entrez_Gene_Id Center NCBI_Build Chromosome
#> 1: ABCB11 8647 genome.wustl.edu 37 2
#> 2: ACSS3 79611 genome.wustl.edu 37 12
#> 3: ANK3 288 genome.wustl.edu 37 10
#> 4: AP1G2 8906 genome.wustl.edu 37 14
#> 5: ARC 23237 genome.wustl.edu 37 8
#> Start_Position End_Position Strand Variant_Classification Variant_Type
#> 1: 169780250 169780250 + Missense_Mutation SNP
#> 2: 81536902 81536902 + Missense_Mutation SNP
#> 3: 61926581 61926581 + Splice_Site SNP
#> 4: 24033309 24033309 + Missense_Mutation SNP
#> 5: 143694874 143694874 + Missense_Mutation SNP
#> Reference_Allele Tumor_Seq_Allele1 Tumor_Seq_Allele2
#> 1: G G A
#> 2: C C T
#> 3: C C A
#> 4: C C T
#> 5: C C G
#> Tumor_Sample_Barcode Protein_Change i_TumorVAF_WU i_transcript_name
#> 1: TCGA-AB-3009 p.A1283V 46.97218 NM_003742.2
#> 2: TCGA-AB-3009 p.A266V 47.32510 NM_024560.2
#> 3: TCGA-AB-3009 43.99478 NM_020987.2
#> 4: TCGA-AB-3009 p.R346Q 47.08000 NM_003917.2
#> 5: TCGA-AB-3009 p.W253C 42.96435 NM_015193.3
##Same as above but return output as an MAF object (Default behaviour)
subsetMaf(maf = laml, tsb = c('TCGA-AB-3009', 'TCGA-AB-2933'))
#> An object of class MAF
#> ID summary Mean Median
#> 1: NCBI_Build 37 NA NA
#> 2: Center genome.wustl.edu NA NA
#> 3: Samples 2 NA NA
#> 4: nGenes 34 NA NA
#> 5: Frame_Shift_Ins 5 2.5 2.5
#> 6: In_Frame_Ins 1 0.5 0.5
#> 7: Missense_Mutation 26 13.0 13.0
#> 8: Nonsense_Mutation 2 1.0 1.0
#> 9: Splice_Site 1 0.5 0.5
#> 10: total 35 17.5 17.5
11.1.1指定查询和控制输出字段。
#Select all Splice_Site mutations from DNMT3A and NPM1
subsetMaf(maf = laml, genes = c('DNMT3A', 'NPM1'), mafObj = FALSE,query = "Variant_Classification == 'Splice_Site'")
#> Hugo_Symbol Entrez_Gene_Id Center NCBI_Build Chromosome
#> 1: DNMT3A 1788 genome.wustl.edu 37 2
#> 2: DNMT3A 1788 genome.wustl.edu 37 2
#> 3: DNMT3A 1788 genome.wustl.edu 37 2
#> 4: DNMT3A 1788 genome.wustl.edu 37 2
#> 5: DNMT3A 1788 genome.wustl.edu 37 2
#> 6: DNMT3A 1788 genome.wustl.edu 37 2
#> Start_Position End_Position Strand Variant_Classification Variant_Type
#> 1: 25459874 25459874 + Splice_Site SNP
#> 2: 25467208 25467208 + Splice_Site SNP
#> 3: 25467022 25467022 + Splice_Site SNP
#> 4: 25459803 25459803 + Splice_Site SNP
#> 5: 25464576 25464576 + Splice_Site SNP
#> 6: 25469029 25469029 + Splice_Site SNP
#> Reference_Allele Tumor_Seq_Allele1 Tumor_Seq_Allele2
#> 1: C C G
#> 2: C C T
#> 3: A A G
#> 4: A A C
#> 5: C C A
#> 6: C C A
#> Tumor_Sample_Barcode Protein_Change i_TumorVAF_WU i_transcript_name
#> 1: TCGA-AB-2818 p.R803S 36.84 NM_022552.3
#> 2: TCGA-AB-2822 62.96 NM_022552.3
#> 3: TCGA-AB-2891 34.78 NM_022552.3
#> 4: TCGA-AB-2898 46.43 NM_022552.3
#> 5: TCGA-AB-2934 p.G646V 37.50 NM_022552.3
#> 6: TCGA-AB-2968 p.E477* 40.00 NM_022552.3
#Same as above but include only 'i_transcript_name' column in the output
subsetMaf(maf = laml, genes = c('DNMT3A', 'NPM1'), mafObj = FALSE, query = "Variant_Classification == 'Splice_Site'", fields = 'i_transcript_name')
#> Hugo_Symbol Chromosome Start_Position End_Position Reference_Allele
#> 1: DNMT3A 2 25459874 25459874 C
#> 2: DNMT3A 2 25467208 25467208 C
#> 3: DNMT3A 2 25467022 25467022 A
#> 4: DNMT3A 2 25459803 25459803 A
#> 5: DNMT3A 2 25464576 25464576 C
#> 6: DNMT3A 2 25469029 25469029 C
#> Tumor_Seq_Allele2 Variant_Classification Variant_Type
#> 1: G Splice_Site SNP
#> 2: T Splice_Site SNP
#> 3: G Splice_Site SNP
#> 4: C Splice_Site SNP
#> 5: A Splice_Site SNP
#> 6: A Splice_Site SNP
#> Tumor_Sample_Barcode i_transcript_name
#> 1: TCGA-AB-2818 NM_022552.3
#> 2: TCGA-AB-2822 NM_022552.3
#> 3: TCGA-AB-2891 NM_022552.3
#> 4: TCGA-AB-2898 NM_022552.3
#> 5: TCGA-AB-2934 NM_022552.3
#> 6: TCGA-AB-2968 NM_022552.3
11.1.2 Subsetting by clinical data
使用subsetMaf函数中的clinQuery参数根据临床症状挑选合适的感兴趣的样本。
#Select all samples with FAB clasification M4 in clinical data
laml_m4 = subsetMaf(maf = laml, clinQuery = "FAB_classification %in% 'M4'")
12 预编译的TCGA MAF对象
还有一个R数据包,其中包含来自TCGA Firehose和TCGA-MC3项目的预编译TCGA MAF对象,对那些使用TCGA突变数据的人特别有帮助。每个数据集都存储为包含体细胞突变和临床信息的MAF对象。由于Bioconductor包装尺寸的限制和其他困难,这份报告没有提交给Bioconductor。不过,你仍然可以从GitHub下载TCGAmutations包。
# devtools::install_github(repo = "PoisonAlien/TCGAmutations")
13 References
- Cancer Genome Atlas Research, N. Genomic and epigenomic landscapes of adult de novo acute myeloid leukemia. N Engl J Med 368, 2059-74 (2013).
- Mermel, C.H. et al. GISTIC2.0 facilitates sensitive and confident localization of the targets of focal somatic copy-number alteration in human cancers. Genome Biol 12, R41 (2011).
- Olshen, A.B., Venkatraman, E.S., Lucito, R. & Wigler, M. Circular binary segmentation for the analysis of array-based DNA copy number data. Biostatistics 5, 557-72 (2004).
- Alexandrov, L.B. et al. Signatures of mutational processes in human cancer. Nature 500, 415-21 (2013).
- Tamborero, D., Gonzalez-Perez, A. & Lopez-Bigas, N. OncodriveCLUST: exploiting the positional clustering of somatic mutations to identify cancer genes. Bioinformatics 29, 2238-44 (2013).
- Dees, N.D. et al. MuSiC: identifying mutational significance in cancer genomes. Genome Res 22, 1589-98 (2012).
- Lawrence MS, Stojanov P, Mermel CH, Robinson JT, Garraway LA, Golub TR, Meyerson M, Gabriel SB, Lander ES, Getz G: Discovery and saturation analysis of cancer genes across 21 tumour types. Nature 2014, 505:495-501.
- Griffith, M., Griffith, O. L., Coffman, A. C., Weible, J. V., McMichael, J. F., Spies, N. C., … Wilson, R. K. (2013). DGIdb - Mining the druggable genome. Nature Methods, 10(12), 1209–1210. http://doi.org/10.1038/nmeth.2689
- Sanchez-Vega F, Mina M, Armenia J, Chatila WK, Luna A, La KC, Dimitriadoy S, Liu DL, Kantheti HS, Saghafinia S et al. 2018. Oncogenic Signaling Pathways in The Cancer Genome Atlas. Cell 173: 321-337 e310
- Madan, V. et al. Comprehensive mutational analysis of primary and relapse acute promyelocytic leukemia. Leukemia 30, 1672-81 (2016).
- Mroz, E.A. & Rocco, J.W. MATH, a novel measure of intratumor genetic heterogeneity, is high in poor-outcome classes of head and neck squamous cell carcinoma. Oral Oncol 49, 211-5 (2013).
- Roberts SA, Lawrence MS, Klimczak LJ, et al. An APOBEC Cytidine Deaminase Mutagenesis Pattern is Widespread in Human Cancers. Nature genetics. 2013;45(9):970-976.
- Gaujoux, R. & Seoighe, C. A flexible R package for nonnegative matrix factorization. BMC Bioinformatics 11, 367 (2010).
- Welch, J.S. et al. The origin and evolution of mutations in acute myeloid leukemia. Cell 150, 264-78 (2012).
- Ramos, A.H. et al. Oncotator: cancer variant annotation tool. Hum Mutat 36, E2423-9 (2015).
- Wang, K., Li, M. & Hakonarson, H. ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res 38, e164 (2010).
- Lawrence MS, Stojanov P, Polak P, Kryukov GV, Cibulskis K, Sivachenko A, Carter SL, Stewart C, Mermel CH, Roberts SA, et al: Mutational heterogeneity in cancer and the search for new cancer-associated genes. Nature 2013, 499:214-218.
14 Session Info
sessionInfo()
#> R version 3.6.1 (2019-07-05)
#> Platform: x86_64-apple-darwin15.6.0 (64-bit)
#> Running under: macOS High Sierra 10.13.6
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats4 parallel stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] pheatmap_1.0.12 doParallel_1.0.15
#> [3] iterators_1.0.12 foreach_1.4.7
#> [5] NMF_0.22.0 Biobase_2.46.0
#> [7] cluster_2.1.0 rngtools_1.4
#> [9] pkgmaker_0.27 registry_0.5-1
#> [11] BSgenome.Hsapiens.UCSC.hg19_1.4.0 BSgenome_1.54.0
#> [13] rtracklayer_1.46.0 Biostrings_2.54.0
#> [15] XVector_0.26.0 GenomicRanges_1.38.0
#> [17] GenomeInfoDb_1.22.0 IRanges_2.20.1
#> [19] S4Vectors_0.24.0 BiocGenerics_0.32.0
#> [21] maftools_2.2.10
#>
#> loaded via a namespace (and not attached):
#> [1] splines_3.6.1 R.utils_2.9.0
#> [3] assertthat_0.2.1 GenomeInfoDbData_1.2.2
#> [5] Rsamtools_2.2.3 yaml_2.2.0
#> [7] pillar_1.4.2 lattice_0.20-38
#> [9] glue_1.3.1 digest_0.6.23
#> [11] RColorBrewer_1.1-2 colorspace_1.4-1
#> [13] R.oo_1.23.0 htmltools_0.4.0
#> [15] Matrix_1.2-17 plyr_1.8.5
#> [17] XML_3.98-1.20 pkgconfig_2.0.3
#> [19] bibtex_0.4.2 zlibbioc_1.32.0
#> [21] purrr_0.3.3 xtable_1.8-4
#> [23] scales_1.1.0 BiocParallel_1.20.0
#> [25] tibble_2.1.3 ggplot2_3.3.0
#> [27] withr_2.1.2 SummarizedExperiment_1.16.0
#> [29] survival_2.44-1.1 magrittr_1.5
#> [31] crayon_1.3.4 mclust_5.4.5
#> [33] evaluate_0.14 R.methodsS3_1.7.1
#> [35] tools_3.6.1 data.table_1.12.6
#> [37] lifecycle_0.1.0 matrixStats_0.55.0
#> [39] gridBase_0.4-7 stringr_1.4.0
#> [41] munsell_0.5.0 DelayedArray_0.12.0
#> [43] compiler_3.6.1 rlang_0.4.5
#> [45] grid_3.6.1 RCurl_1.95-4.12
#> [47] bitops_1.0-6 rmarkdown_2.1
#> [49] gtable_0.3.0 codetools_0.2-16
#> [51] reshape2_1.4.3 R6_2.4.1
#> [53] GenomicAlignments_1.22.0 knitr_1.25
#> [55] dplyr_0.8.5 stringi_1.4.3
#> [57] Rcpp_1.0.3 wordcloud_2.6
#> [59] tidyselect_0.2.5 xfun_0.10
参考学习资料:http://www.bioconductor.org/packages/release/bioc/vignettes/maftools/inst/doc/maftools.html