问题
朋友最近的几次面试中,都被问了是否了解HashMap在并发使用时可能发生死循环,导致cpu100%,结果让我很意外,他都表示不知道有这样的问题,让我意外的是他的工作年限还不短。
由于HashMap并非是线程安全的,所以在高并发的情况下必然会出现问题,这是一个普遍的问题,虽然网上分析的文章很多,还是觉得有必须写一篇文章,让关注我的同学能够意识到这个问题,并了解这个死循环是如何产生的。
如果是在单线程下使用HashMap,自然是没有问题的,如果后期由于代码优化,这段逻辑引入了多线程并发执行,在一个未知的时间点,会发现CPU占用100%,居高不下,通过查看堆栈,你会惊讶的发现,线程都Hang在hashMap的get()方法上,服务重启之后,问题消失,过段时间可能又复现了。
这是为什么?
原因分析
在了解来龙去脉之前,我们先看看HashMap的数据结构。
在内部,HashMap使用一个Entry数组保存key、value数据,当一对key、value被加入时,会通过一个hash算法得到数组的下标index,算法很简单,根据key的hash值,对数组的大小取模 hash & (length-1),并把结果插入数组该位置,如果该位置上已经有元素了,就说明存在hash冲突,这样会在index位置生成链表。
如果存在hash冲突,最惨的情况,就是所有元素都定位到同一个位置,形成一个长长的链表,这样get一个值时,最坏情况需要遍历所有节点,性能变成了O(n),所以元素的hash值算法和HashMap的初始化大小很重要。
当插入一个新的节点时,如果不存在相同的key,则会判断当前内部元素是否已经达到阈值(默认是数组大小的0.75),如果已经达到阈值,会对数组进行扩容,也会对链表中的元素进行rehash。
实现
HashMap的put方法实现:
1、判断key是否已经存在
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
// 如果key已经存在,则替换value,并返回旧值
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// key不存在,则插入新的元素
addEntry(hash, key, value, i);
return null;
}
2、检查容量是否达到阈值threshold
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
如果元素个数已经达到阈值,则扩容,并把原来的元素移动过去。
3、扩容实现
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
...
Entry[] newTable = new Entry[newCapacity];
...
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
这里会新建一个更大的数组,并通过transfer方法,移动元素。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
移动的逻辑也很清晰,遍历原来table中每个位置的链表,并对每个元素进行重新hash,在新的newTable找到归宿,并插入。
案例分析
假设HashMap初始化大小为4,插入个3节点,不巧的是,这3个节点都hash到同一个位置,如果按照默认的负载因子的话,插入第3个节点就会扩容,为了验证效果,假设负载因子是1.
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
以上是节点移动的相关逻辑。
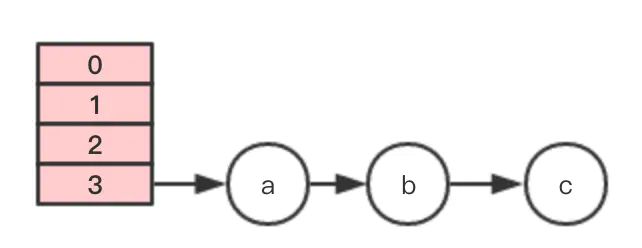
插入第4个节点时,发生rehash,假设现在有两个线程同时进行,线程1和线程2,两个线程都会新建新的数组。
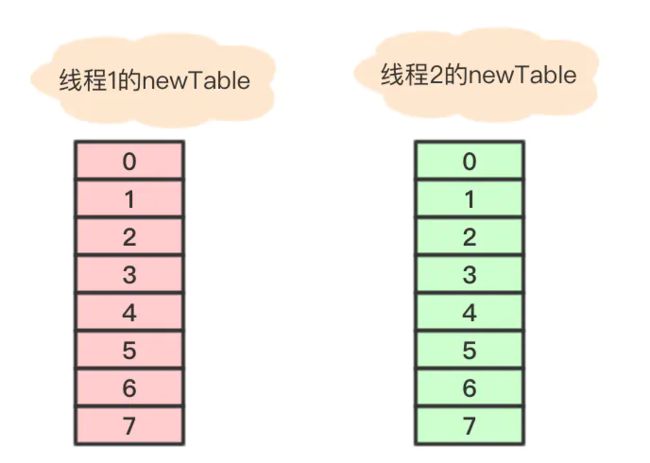
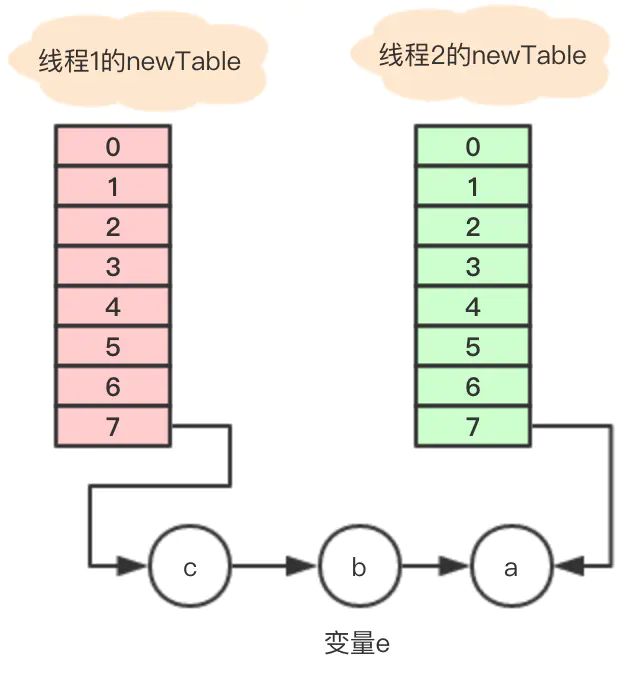
假设 线程2 在执行到Entry之后,cpu时间片用完了,这时变量e指向节点a,变量next指向节点b。
线程1继续执行,很不巧,a、b、c节点rehash之后又是在同一个位置7,开始移动节点
第一步,移动节点a
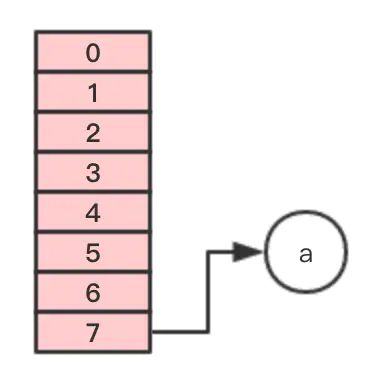
第二步,移动节点b

注意,这里的顺序是反过来的,继续移动节点c
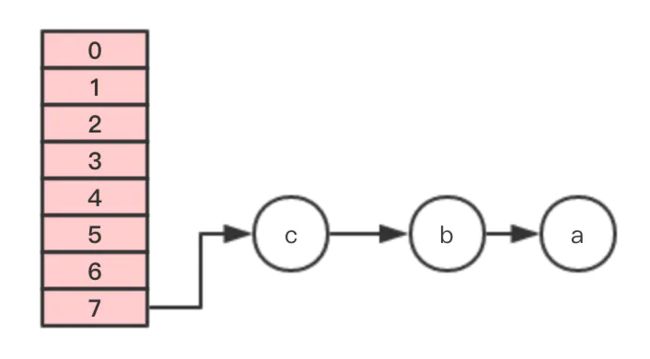
这个时候 线程1 的时间片用完,内部的table还没有设置成新的newTable, 线程2 开始执行,这时内部的引用关系如下:

这时,在 线程2 中,变量e指向节点a,变量next指向节点b,开始执行循环体的剩余逻辑。
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
执行之后的引用关系如下图
执行后,变量e指向节点b,因为e不是null,则继续执行循环体,执行后的引用关系
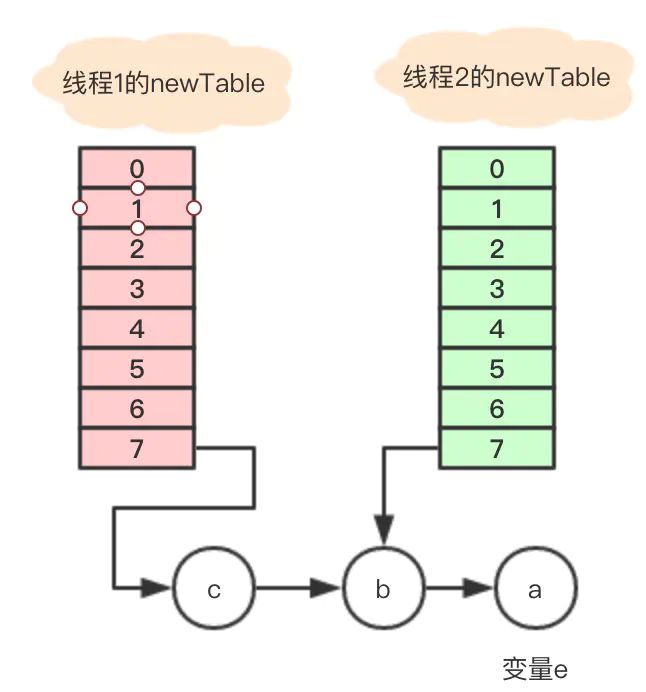
变量e又重新指回节点a,只能继续执行循环体,这里仔细分析下: 1、执行完Entry,目前节点a没有next,所以变量next指向null; 2、e.next = newTable[i]; 其中 newTable[i] 指向节点b,那就是把a的next指向了节点b,这样a和b就相互引用了,形成了一个环; 3、newTable[i] = e 把节点a放到了数组i位置; 4、e = next; 把变量e赋值为null,因为第一步中变量next就是指向null;
所以最终的引用关系是这样的:

节点a和b互相引用,形成了一个环,当在数组该位置get寻找对应的key时,就发生了死循环。
另外,如果线程2把newTable设置成到内部的table,节点c的数据就丢了,看来还有数据遗失的问题。
总结
所以在并发的情况,发生扩容时,可能会产生循环链表,在执行get的时候,会触发死循环,引起CPU的100%问题,所以一定要避免在并发环境下使用HashMap。
曾经有人把这个问题报给了Sun,不过Sun不认为这是一个bug,因为在HashMap本来就不支持多线程使用,要并发就用ConcurrentHashmap。