准备三台机器,我目前是在我本机通过VirtualBox创建了三台centos 7.4的虚拟机,将他们加入到每台机器的/etc/hosts文件中
# master节点:内存2g,cpu2核
192.168.99.103 node1
# work结点:内存1g,cup1核
192.168.99.104 node2
# work结点:内存1g,cup1核
192.168.99.105 node3
1、首先安装 docker-ce
1.1、安装一些工具包
yum install -y yum-utils device-mapper-persistent-data lvm2
1.2、设置docker-ce的下载源为阿里的下载源
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 查看docker-ce数据源信息可以看到有一个 `docker-ce.repo` 的文件
ls /etc/yum.repos.d
docker-ce yum源
1.3、安装docker-ce
# 安装最新的docker-ce
yum install -y docker-ce
# 也可以安装指定的版本
# 先查看版本列表
yum list docker-ce --showduplicates | sort -r
# 安装指定版本 比如 18.03.1.ce-1.el7.centos
yum install -y docker-ce-18.03.1.ce-1.el7.centos

docker-ce 最新列表
1.4、启动docker 且设置docker为开机自启动
systemctl start docker && \
systemctl enable docker &&\
systemctl status docker
# 看到下图 状态说明docker-ce启动成功
# 也可以通过 docker --version 查看当前安装的docker 版本
docker --version

docker-ce启动成功示意图

查看docker版本信息
docker 安装完成
2、安装 kubeadm、kubelet、kubectl
2.1、设置kubeadm、kubectl、kubelet下载源
cd /etc/yum.repos.d/
# 添加 kubernetes 源
vi kubernetes.repo
# 加入下面信息然后保存
[kubernetes]
name=Kubernetes Repository
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
2.2、检查添加的源中是否包含我们需要的软件
yum list all |grep "^kube"

图片.png
2.3、安装kubeadm 、kubectl、kubelet
yum install kubeadm kubectl kubelet
#也可以指定版本安装
yum install -y kubeadm-1.18.3-0 kubelet-1.18.3-0 kubectl-1.18.3-0
2.4、检查是否安装完成
rpm -ql kubelet
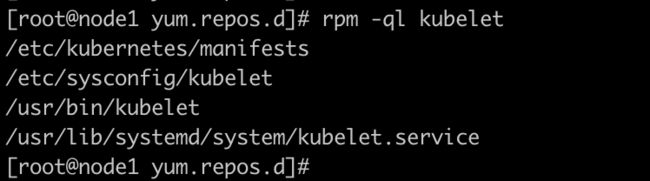
kubectl安装成功检测
2.5、启动kubelet且设置为开机自启动
systemctl start kubelet &&\
systemctl enable kubelet && \
systemctl status kubelet
# 这时候会如下图所示显示启动失败,因为这时候还没有生成相应的配置文件导致,此时可以先不用管它
# 等kubeadm生成对应的配置文件之后再查看
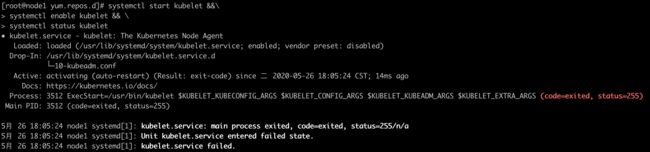
kubectl运行状态
kubeadm、kubelet、kubectl 安装成功
3、集群搭建前的准备工作
3.1、关闭防火墙服务跟开机自启动
systemctl stop firewalld.service || \
systemctl stop iptables.service|| \
systemctl disable firewalld.service || \
systemctl disable iptables.service
3.2、禁用SELINUX
#临时关闭:
setenforce 0
#永久关闭:
vim /etc/selinux/config
SELINUX=disabled
3.3、禁用swap
#临时禁用
swapoff -a
#永久禁用
vim /etc/fstab
# 注释下面的行
#/dev/mapper/centos-swap swap swap
4、通过kubeadm搭建集群
4.1、导出集群初始化配置文件
# 切换到家目录
cd ~
# 导出配置文件
kubeadm config print init-defaults --kubeconfig ClusterConfiguration > kubeadm.yml
4.2、修改kubeadm.yaml 配置文件中的 imageRepository 为阿里镜像源
vi kubeadm.yaml
# 替换 imageRepository: k8s.gcr.io 为下面的内容
imageRepository: registry.aliyuncs.com/google_containers
4.3、查看所需镜像列表且拉取所有镜像到本地
# 查看所需镜像列表
kubeadm config images list --config kubeadm.yml
# 拉取k8s集群所需要的镜像
kubeadm config images pull --config kubeadm.yml
# 拉取完成之后查看本地镜像列表
docker images | grep registry.aliyuncs.com

本地镜像列表
4.4、初始化master节点
kubeadm init --kubernetes-version=1.18.2 \
--apiserver-advertise-address=192.168.99.100 \
--image-repository=registry.aliyuncs.com/google_containers \
--pod-network-cidr=10.244.0.0/16
# --kubernetes-version:kubelet 版本信息,可以通过kubelet --version 查看
# --apiserver-advertise-address:填写master节点的IP地址
# --image-repository:填写registry.aliyuncs.com/google_containers;k8s默认的镜像是从k8s.gcr.io仓库下拉取镜像的
# 这里需要解释下:因为天朝的网络太顺畅所以我们在4.2步骤中将镜像仓库替换成了 registry.aliyuncs.com/google_containers
# 然后我们将镜像拉取到了本地之后同4.3步骤的截图一样会以registry.aliyuncs.com/google_containers开头
# 如果这里不指明使用registry.aliyuncs.com/google_containers下的镜像的话默认会从k8s.gcr.io 下找,因为我们本地没有会又去从k8s.gcr.io 拉取镜像,我们4.3的步骤就白做了
# 当然这里如果你不想添加--image-repository参数就想使用k8s.gcr.io的话也是有办法的
# 就是通过 docker tag 将4.3步骤拉取下来的所有镜像全部重新打成 k8s.gcr.io/*** 就行了;可以通过下面的脚本来做
#!/bin/sh
new_reg="k8s.gcr.io"
for reg in $(docker images | grep registry.aliyuncs.com/google_containers | awk '{print $1":"$2}');
do
image=$(echo ${reg} | awk -F '/' '{print $3}')
docker tag ${reg} ${new_reg}/${image}
done
# --pod-network-cidr:指定集群中pod的网段
常见的问题:
1、[ERROR NumCPU] 或者 [ERROR Swap]

k8s集群初始化错误信息
上图两个报错信息已经说得很明显了,而且已经告诉怎么解决了
1、k8s 是需要机器的cup核最少在2核以上
2、需要关闭内存交换分区
# 关闭交换分区
swapoff -a
# 明确告知忽略cpu核数 ,增加参数
--ignore-preflight-errors=NumCPU
# 改动之后的master初始化参数如下
kubeadm init --kubernetes-version=1.18.2 \
--apiserver-advertise-address=192.168.99.100 \
--image-repository registry.aliyuncs.com/google_containers \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=NumCPU
2、另外可能会有这么一个WARNING
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
我们通过docker info查看信息如下
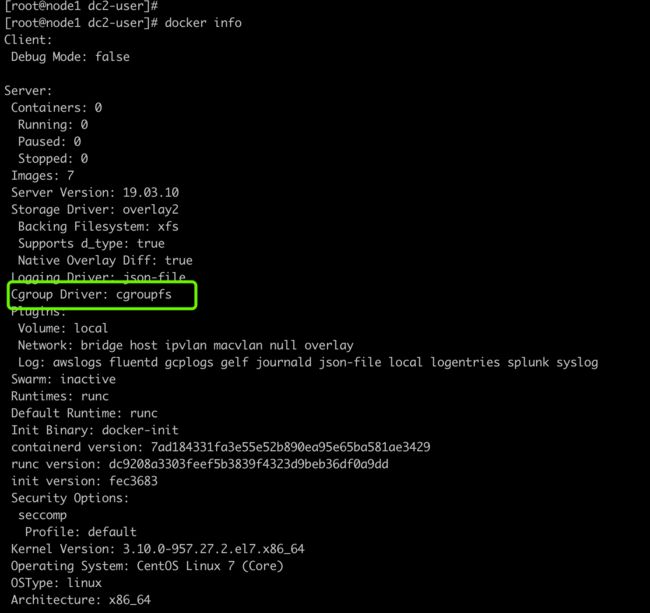
图片.png
解决办法
修改 /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
# 重启docker
systemctl restart docker
3、关于共有用上使用公网IP部署时不能使用公网IP启动ETCD的解决方案
https://www.cnblogs.com/life-of-coding/p/11879067.html
4、[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
这个问题找了好久不知道什么原因;最后通过日志查看有下面一段错误信息
6月 05 22:35:19 master kubelet[19182]: F0605 22:35:19.656462 19182 kubelet.go:1383] Failed to start ContainerManager failed to initialize top level QOS containers: failed to update top level Burstable QOS cgroup : failed to set supported cgroup subsystems for cgroup [kubepods burstable]: failed to find subsystem mount for required subsystem: pids
6月 05 22:35:19 master systemd[1]: kubelet.service: main process exited, code=exited, status=255/n/a
6月 05 22:35:19 master systemd[1]: Unit kubelet.service entered failed state.
6月 05 22:35:19 master systemd[1]: kubelet.service failed
最终解决办法如下参考链接
for i in $(systemctl list-unit-files --no-legend --no-pager -l | grep --color=never -o .*.slice | grep kubepod); do
systemctl stop $i;
done
5、failed to find subsystem mount for required subsystem
kubectl describe nodes master
Normal NodeHasSufficientPID 5m44s kubelet, master Node master status is now: NodeHasSufficientPID
Normal NodeHasNoDiskPressure 5m44s kubelet, master Node master status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientMemory 5m44s kubelet, master Node master status is now: NodeHasSufficientMemory
Normal Starting 3m15s kubelet, master Starting kubelet.
Normal NodeAllocatableEnforced 3m15s kubelet, master Updated Node Allocatable limit across pods
Normal NodeHasSufficientMemory 3m14s (x8 over 3m15s) kubelet, master Node master status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 3m14s (x8 over 3m15s) kubelet, master Node master status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 3m14s (x7 over 3m15s) kubelet, master Node master status is now: NodeHasSufficientPID
解决办法参考地址
等几分钟看到如下图所示说明master节点初始化成功

k8s集群master节点初始化成功
4.5 按照最后的提示添加配置信息
# 注意以下操作必须要在家目录操作
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 然后记录kubeadm join ****信息,work节点加入集群时需要用到
kubeadm join 192.168.99.100:6443 --token 7tjayn.43smtouy6b24nujn \
--discovery-token-ca-cert-hash sha256:f674da21d422317082a0725c695c4bd16fcf1d94ee7b838c672679dbc5baa1a7
4.6 查看集群信息
kubectl get nodes
# 显示如下
NAME STATUS ROLES AGE VERSION
node1 NotReady master 27m v1.18.2
# STATUS 显示当前节点为NotReady 状态
# 我们在安装完 kubelet 之后查看了它的运行状态发现它是未启动状态
# 现在我们再次查看 kubelet 的运行状态,如下图
systemctl status kubelet

kubelet运行状态
可以从报错信息得知是因为缺少网络插件所以处于NotReady状态
4.7、安装网络插件 flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 会发现没法解析raw.githubusercontent.com 这个域名;会报如下图的错误信息
# 解决办法,打开下面地址,输入 raw.githubusercontent.com查看服务器的IP地址,如下图
https://site.ip138.com/raw.githubusercontent.com/
# 在/etc/hosts 中添加域名解析(我这里选择的是香港的IP)
151.101.76.133 raw.githubusercontent.com
# 重新获取flannel 插件yaml配置信息
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 获取成功之后安装
kubectl apply -f kube-flannel.yml

raw.githubusercontetn.com无法解析

raw.githubusercontent.com解析IP
4.8、检查网络插件是否安装成功
# 查看所有的pods信息
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-7ff77c879f-pw7tl 0/1 Pending 0 44m
kube-system coredns-7ff77c879f-zhzvz 0/1 Pending 0 44m
kube-system etcd-node1 1/1 Running 0 44m
kube-system kube-apiserver-node1 1/1 Running 0 44m
kube-system kube-controller-manager-node1 1/1 Running 0 44m
kube-system kube-flannel-ds-amd64-58j6d 0/1 Init:0/1 0 22s
kube-system kube-proxy-mnvfl 1/1 Running 0 44m
kube-system kube-scheduler-node1 1/1 Running 0 44m
# 会发现STATUS有的处于Pending状态,说明正在安装
# 等所有的STATUS状态都变成Running状态之后再次查看节点信息
kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready master 49m v1.18.2
# 这时候发现当前节点node1即master节点已经初始化完成了
4.9、安装kubernetes-dashboard
# 下载dashboard的配置yaml文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc7/aio/deploy/recommended.yaml
# kubernetes-dashboard 默认只能集群内部访问;所以这里修改配置文件让端口暴露给宿主机
vim recommended.yaml
# 加入下面的字段到recommended.yaml(如下图)
type: NodePort
# 安装dashboard
kubectl apply -f recommended.yaml

为kubernetes-dashboard添加type: NodePort
4.10、查看集群所有pods状态信息
kubectl get pods --all-namespaces
# 等STATUS状态全部变成Running状态
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-7ff77c879f-pw7tl 1/1 Running 0 67m
kube-system coredns-7ff77c879f-zhzvz 1/1 Running 0 67m
kube-system etcd-node1 1/1 Running 0 67m
kube-system kube-apiserver-node1 1/1 Running 0 67m
kube-system kube-controller-manager-node1 1/1 Running 6 67m
kube-system kube-flannel-ds-amd64-58j6d 1/1 Running 0 23m
kube-system kube-proxy-mnvfl 1/1 Running 0 67m
kube-system kube-scheduler-node1 1/1 Running 6 67m
kubernetes-dashboard dashboard-metrics-scraper-dc6947fbf-l28v9 1/1 Running 0 8m7s
kubernetes-dashboard kubernetes-dashboard-5d4dc8b976-s8chd 1/1 Running 0 8m7s
4.11、查看kubernetes-dashboard映射到宿主机的端口
# 查看kubernetes-dashboard映射到宿主机的端口
kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.106.200.77 8000/TCP 10m
kubernetes-dashboard NodePort 10.100.186.120 443:31178/TCP 10m
# 在火狐浏览器中访问 dashboard,如下图选择Token登录
https://192.168.99.100:31178
# 获取kubernetes-dashboard 登录Token
kubectl -n kube-system describe $(kubectl get secret -n kube-system -o name | grep namespace) | grep token:
# 使用获取到的Token登录

kubernetes-dashboard登录界面

kuberntes-dashboard登录成功
4.12、work节点加入集群
# 使用4.5步骤保存的 kubeadm join ****在work节点执行加入集群
kubeadm join 192.168.99.100:6443 --token 7tjayn.43smtouy6b24nujn \
--discovery-token-ca-cert-hash sha256:f674da21d422317082a0725c695c4bd16fcf1d94ee7b838c672679dbc5baa1a7
# 等加入集群成功之后在master 节点查看集群信息
kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready master 5d2h v1.18.2
node2 Ready 5d v1.18.2
node3 Ready 5d v1.18.2