论文评析-Incremental Boosting Convolutional Neural Network for Facial Action Unit Recognition,NIPS, 2016
Incremental Boosting Convolutional Neural Network for Facial Action Unit Recognition
- 前言
- 文章亮点
-
- 模型结构
- CNN
- Boosting CNN
-
- Loss function
- IB-CNN
-
-
- 弱分类器的更新
- 增量强分类器的更新:
- Loss function
- IB-CNN的优化
-
前言
这篇论文是将GBDT与CNN结合用于 Facial Action Unit Recognition。文章挺不错,就是有些图画的有些抽象,符号比较多,导致细节的地方看了好几遍才看明白。
文章亮点
1.AU训练集小导致训练的CNN model泛化能力差,作者提出了Incremental Boosting CNN (IB-CNN): 通过Incremental boosting layer将boosting tree与CNN进行结合。
2.综合考虑Incremental boosting classifier与各个weak classifier提出了新的损失函数用于训练。
模型结构

如上图所示, 因为Incremental boosting classifier是随着Batch增量更新的,因此上面的图是沿着Iteration/Batch展开后的效果,以便于说明。图比较抽象,为了更好的说明一些概念,笔者花了一个草图:

为了介绍IB-CNN,作者沿着CNN -> Boosting CNN (B-CNN) -> IB-CNN 的顺序逐步深入,这里也按照同样的顺序。
CNN
传统CNN的话就没有中间那个GBDT了, 最后一层FC的神经元数目=类别数,decision layer 使用的score function即:导数第二层FC的输出 x 权重 然后再经过sigmoid/softmax激活, 原文中的原话是:
The score function used by the decision layer is generally the inner
product of the activations in the FC layer and the corresponding
weights.
Boosting CNN
Boosting CNN相比于CNN的变化在于:决策层使用了GBDT, 这样可以获得更复杂的决策边界。原文中的描述:
. In this paper, we substitute the inner-product score function with a
boosting score function to achieve a complex decision boundary
因此,最终的预测输出为boosting方式所构建的强分类器 H H H的输出,定义如下: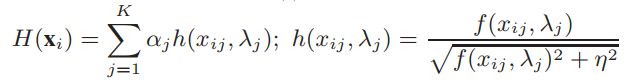
其中 f ( ⋅ , λ j ) f(\cdot, \lambda_{j}) f(⋅,λj)为决策树桩,其threshold参数记为 λ j \lambda_{j} λj, 弱学习器 h ( ⋅ , λ j ) h(\cdot, \lambda_{j}) h(⋅,λj)就是决策树桩 f ( ⋅ , λ j ) f(\cdot, \lambda_{j}) f(⋅,λj)经过如下变换得来的:
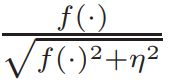
该变换实际上模拟了符号函数 s i g n sign sign,
Loss function
动机:传统的boosting算法只考虑了强分类器的损失,这种损失可能会被一些权重较大的弱分类器所控制,从而可能导致过度拟合。
因此,作者综合考虑了强分类器的损失和弱分类器的损失,定义如下:
![]()
其中,强分类器损失如下

弱分类器损失如下:

其中 M M M为Batch大小, K K K为弱分类器的数量,
由于在构建GBDT时,Boosting本身具有feature selection的功能,只有那些被选择的feature (实际上就是FC中的神经元,这些feature的状态称之为active)参与损失的计算以及训练,因此上式中N (N
IB-CNN
动机:B-CNN存在的问题是:,先前捕获的信息,例如,活跃神经元的权重 α j ( > 0 ) \alpha_{j} (>0) αj(>0)和threshold— λ j \lambda_{j} λj,在下一个batch上训练新的GBDT时被完全丢弃。由于每个Batch的样本量很少,经过训练的B-CNN (特别是GBDT部分)非常容易出现过拟合。
为了克服上述问题,作者借助了增量学习。
IB-CNN与B-CNN对比如下图:

具体讲,
弱分类器的更新
每个弱分类器 h t − 1 ( ⋅ ) h^{t-1}(\cdot) ht−1(⋅)通过更新自身的参数—— λ j t − 1 → λ j t \lambda_{j}^{t-1} \rightarrow \lambda_{j}^{t} λjt−1→λjt更新为 h t ( ⋅ ) h^{t}(\cdot) ht(⋅)。具体来讲,分两种情况:
(1)第j个弱分类器之前没有被选择过
在当前Iteration, λ j t \lambda_{j}^{t} λjt通过boosting被估计。
(2)第j个弱分类器之前被选择过
通过反向传播来更新 λ j t \lambda_{j}^{t} λjt,如下:

其中 ε H I \varepsilon^{H_{I}} εHI为强分类器的损失。
增量强分类器的更新:
在第 t t t个Iteration时,当前Iteration被激活的神经元(蓝色neuron)与之前Iterations被激活的神经元(红色neuron)增量结合一起构建所谓的Incremental strong classifier, 定义如下:

其中, H I t − 1 H_{I}^{t-1} HIt−1为第t-1 iteration之后的Incremental strong classifier, H t H^{t} Ht为在当前Batch上构建的GBDT强分类器,将 H t H^{t} Ht的定义(即 H H H)带入,可得:
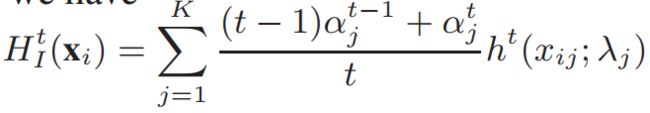
示意图如下:

Loss function
总的损失定义如下(与B-CNN的loss类似):

其中增量强分类器损失如下:
![]()
该损失关于activate feature— x i j x_{ij} xij以及threshold— λ j \lambda_{j} λj的梯度计算如下。

特别注意:
- ∂ ∂ x i j ε I B \frac{\partial}{\partial x_{ij}}\varepsilon^{IB} ∂xij∂εIB可以进一步传递到FC module以及CNN Module.
IB-CNN的优化
