算法面经汇总(2)
文章目录
-
- 算法面经汇总(1)
- 深度学习
- NLP
- 海量数据
- HR面
- 其他
算法面经汇总(1)
算法面经汇总(1)
深度学习
⭐️ 画出RNN的结构图
NLP模型公式笔记
⭐️ 反向传播的原理
BP算法推导——以矩阵形式
⭐️ 梯度下降陷入局部最优有什么解决办法
[1] 你的模型真的陷入局部最优点了吗
[2] 梯度下降法的神经网络容易收敛到局部最优,为什么应用广泛?
[3] 深度学习里,如何判断模型陷入局部最优?
在高维问题中,梯度下降通常是收敛到鞍点或大块的平坦区域,而不是收敛到局部最小值点。解决办法有:
- 选择合适的优化算法
- 谨慎地进行参数初始化
- 使用BN使得训练过程更加稳定,简化参数初始化等调参过程
BN抑制了参数微小变化随着网络层数加深被放大的问题,从而使得训练过程更加稳定
最后,很多时候我们不一定要全局最优解甚至局部最优解,而只需泛化误差够小,效果够好就行了。
鞍点:若某个一阶导数为0的点在至少一个方向上的二阶导数小于0,那它就是鞍点。
如果用Hessian矩阵来判断:
- 当Hessian矩阵的特征值有正有负的时候,一阶导数为零的点为鞍点
- 当Hessian矩阵的特征值全部为非负的时候,一阶导数为零的点为局部极小值点。
⭐️ Batch normalization原理和用处,先归一化然后恢复有何意义,BN一般放在哪里,BN和LN的区别
[1] BN原理与优点
[2] BN本质原理与为何有效
[3] BN位置
[4] BN有效的原因
深度学习的训练过程有Internal Covariate Shift的现象,也就是网络中参数的变化会引起下一层的输入数据的分布发生变化,从而导致底层网络的细微变化很容易累积到上层网络中,导致模型的训练过程很容易进入到激活函数的梯度饱和区,从而减缓网络收敛速度
(PS:这里并不引用[1]中BN能“让每一层网络的输入数据分布都变得稳定”的说法,因为见[2]的解释,“均值方差一致的分布就是同样的分布吗?当然不是”)
BN的原理见[1],用处有3点:
(1)通过归一化调整了使得激活函数输入数据的分布,使其落在梯度非饱和区,缓解梯度消失的问题,加快收敛速度. 另一方面,可学习的参数 γ \gamma γ 与 β \beta β (即问题中提到的“先归一化然后恢复”)又允许网络有更好的表达能力(representation ability of the network),甚至可以保留原始信息(当 γ = σ 2 + ϵ \gamma=\sqrt{\sigma^2+\epsilon} γ=σ2+ϵ且 β = μ \beta=\mu β=μ时)
(2)抑制了参数微小变化随着网络层数加深被放大的问题,使得训练过程更加稳定,从而简化了精心进行参数初始化等调参过程.
(3)原论文实验结果论证了使用了BN后可去除或减少Dropout的使用,即BN有一定的正则化和防止过拟合的作用. 原因是不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,增强了网络的鲁棒性和泛化性.
何处用:原论文中建议BN应该放到激活函数前,但实践中有时候BN放在激活函数之后效果更好. 其原因仍然是在讨论中的问题.
何时用:当遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决. 另外,在一般情况下也可以加入BN来加快训练速度,提高模型精度. 但是注意,如果batch_size很小,则计算过程需要使用的均值和方差都是有偏估计,不适合使用BN。
⭐️ 梯度消失和梯度爆炸的原因以及解决办法,LSTM为什么可以缓解梯度消失问题
[1] Why LSTMs Stop Your Gradients From Vanishing (中文版见参考资料[2][3][4])
[2] 知乎文章
[3] 知乎答案1
[4] 知乎答案2
[5] On the difficulty of training Recurrent Neural Networks
[6] 详解机器学习中的梯度消失、爆炸原因及其解决方法
[7] 梯度消失的原因
论文[5]指出,在朴素 RNN 中,对权重矩阵 W W W 而言,梯度消失的充分条件是 W W W 的主特征值的绝对值小于 1 γ \frac1 \gamma γ1 ,梯度爆炸的必要条件是 W W W 的主特征值大于 1 γ \frac1 \gamma γ1,其中 γ \gamma γ 是 RNN 中所用的激活函数的导数最大值,对于 tanh \tanh tanh 和 σ \sigma σ, γ \gamma γ 分别为 1 1 1 和 1 4 \frac 14 41.
推导某时刻 t t t 的损失 E t E_t Et 对 W c W_c Wc 的导数,按照参考资料[1]的思路,
∂ E t ∂ W c = ∂ E t ∂ y t ∂ y t ∂ C t ∑ i = 0 t ∂ C t ∂ C i ∂ C i ∂ W c \frac{\partial E_{t}}{\partial W_{c}}= \frac{\partial E_{t}}{\partial y_{t}}\frac{\partial y_{t}}{\partial C_{t}} \sum_{i=0}^{t}\frac{\partial C_{t}}{\partial C_{i}}\frac{\partial C_{i}}{\partial W_{c}} ∂Wc∂Et=∂yt∂Et∂Ct∂yti=0∑t∂Ci∂Ct∂Wc∂Ci
在朴素RNN中,可展开为连乘项的 ∂ h t ∂ h t − 1 \frac{\partial h_t}{\partial h_{t-1}} ∂ht−1∂ht 是是导致梯度消失/爆炸的关键,所以我们应该继续分析LSTM情形下的 ∂ C t ∂ C i \frac{\partial C_{t}}{\partial C_{i}} ∂Ci∂Ct .
∂ C t ∂ C i = ∏ k = i t − 1 ∂ C k + 1 C k \frac{\partial C_{t}}{\partial C_{i}}=\prod_{k=i}^{t-1} \frac{\partial C_{k+1}}{C_k} ∂Ci∂Ct=k=i∏t−1Ck∂Ck+1
对其中的项 ∂ C t C t − 1 \frac{\partial C_{t}}{C_{t-1}} Ct−1∂Ct进行分析,得到(图来自参考资料1)
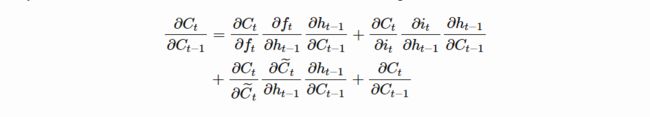
即:
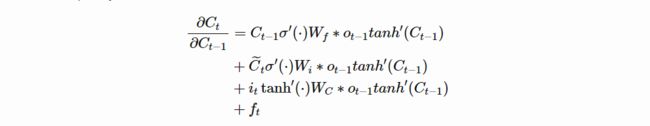
在朴素RNN的分析中,当 W R W_R WR 的主特征值满足一定条件时,连乘项 h t h t − 1 \frac{h_t}{h_{t-1}} ht−1ht 在每个时间步的值都恒介于 [ 0 , 1 ] [0,1] [0,1] ,因此很容易导致梯度消失。而LSTM中的连乘项由上图的4部分相加组成,对任意时间步 t t t, ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct 既可以大于 1 也可以介于0和1,所以多项相乘趋于0的充分条件就很难保证。而且, f t , o t , i t f_t,o_t,i_t ft,ot,it和 C ~ t \tilde C_t C~t 都是可学习的,所以LSTM可以通过设置3个门来控制什么时候让梯度消失(此时是故意让梯度消失,即“遗忘”该部分信息),什么时候让梯度保留。
因此,LSTM缓解梯度消失的原因可以小结如下:
- LSTM中的连乘项是多项式求和,不再由单一项主导,因此恒介于 [ 0 , 1 ] [0,1] [0,1] 的概率要小很多
- LSTM可学习的门机制参数使其可以决定何时让梯度消失,何时让梯度保留,而根据的信息则是隐状态 h t h_t ht 和输入 x t x_t xt
MLP中梯度消失的原因是参数矩阵的梯度表达式含有激活函数(例如sigmoid)导数的连乘项,而sigmoid和tanh的导数最大值都小于1,所以连乘的结果趋于0。可以参考文章[6]和[7]
防止梯度消失与梯度爆炸的方法:
- 选取Relu、leaky-Relu、Elu等激活函数
- Batch Normalization
- 使用深度残差网络或者Highway网络
- 使用LSTM或GRU而不是朴素的RNN
- 梯度截断(仅针对梯度爆炸)
- 添加正则化项对权重矩阵的范数进行约束(仅针对梯度爆炸)
⭐️ 交叉熵损失函数公式,举例计算过程,为什么交叉熵可以用在分类中,可以换用MSE吗?
[1] 熵、交叉熵、KL散度、JS散度、推广的JS散度公式、互信息
[2] Pytorch CrossEntropyLoss
[3] 深度学习中文版 3.13 节
[4] 为什么分类问题使用交叉熵损失而不是均方误差损失——中文
[5] 为什么分类问题使用交叉熵损失而不是均方误差损失——英文
[6] 逻辑回归损失函数为什么使用最大似然估计而不用最小二乘法?
公式见[1],计算过程见[2]
为什么可以用在分类中?为什么不使用MSE?
- 针对分布Q最小化交叉熵等价于最小化KL散度,而KL散度可以衡量分布的相似性 [ 1 ] ^{[1]} [1]
- 使用MSE损失会导致梯度项中含有 σ ′ \sigma^\prime σ′ (sigmoid的导数最大值为0.25)而使得梯度较小、训练过慢,而使用交叉熵损失得到的梯度不含 σ ′ \sigma^\prime σ′项;使用交叉熵损失的导数含有 σ ( z ) − y \sigma(z)-y σ(z)−y项,故当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢
- 在逻辑斯谛回归中,使用负对数似然的目标函数是任意阶可导的凸函数,而使用均方误差得到的不是凸函数 [ 6 ] ^{[6]} [6]
⭐️ 交叉熵与相对熵(KL散度)
[1] 熵、交叉熵、KL散度、JS散度、推广的JS散度公式、互信息
⭐️ 极大似然估计公式,极大似然与交叉熵有什么区别
[1] 手推逻辑斯蒂回归——以向量形式
极大似然估计是参数估计的方法,可以用来推导需要优化的目标函数。交叉熵是信息论中的概念,交叉熵作为损失函数时,最小化交叉熵损失等价于最小化KL散度。
他们的关系是,可以由极大似然估计法来推导出交叉熵损失。
以逻辑斯谛回归为例,最大化似然函数等价于最小化负的对数似然函数,从而等价于最小化交叉熵损失 [ 1 ] ^{[1]} [1]。
⭐️ 二分类交叉熵和多分类交叉熵的区别,分别在什么场景下使用
二分类交叉熵 BinaryCrossEntropy 在二分类和多标签分类的情况下使用;多分类交叉熵在多分类时使用
⭐️ 神经网络前向传播和反向传播的代码实现
TODO。。。
⭐️ softmax的输入为z,输出与y做交叉熵得到C,求C对z的导数
[1] 矩阵求导术
见[1]的例题6,可以参考其用向量表达交叉熵和softmax的思路,但这道例题是求对w而不是z=wx的导数。另外,个人认为直接用向量求导的思路更快。
首先将交叉熵和softmax都表达为向量形式并化简:
C = − y T log s o f t m a x ( z ) = − y T log e z 1 T e z = − y T [ z − 1 log ( 1 T e z ) ] = − y T z + log ( 1 T e z ) \begin{aligned}C&=-\boldsymbol y^T\log softmax(\boldsymbol z)\\ &=-\boldsymbol y^T\log\frac{e^{\boldsymbol z}}{\boldsymbol 1^Te^{\boldsymbol z}}\\ &=-\boldsymbol y^T[\boldsymbol z-\boldsymbol 1\log(\boldsymbol 1^Te^{\boldsymbol z})]\\ &=-\boldsymbol y^T\boldsymbol z+\log(\boldsymbol 1^Te^{\boldsymbol z}) \end{aligned} C=−yTlogsoftmax(z)=−yTlog1Tezez=−yT[z−1log(1Tez)]=−yTz+log(1Tez)
因此有:
∂ C ∂ z = − y + 1 1 T e z ∂ 1 T e z z = − y + e z 1 T e z = s o f t m a x ( z ) − y \begin{aligned} \frac{\partial C}{\partial z}&=-\boldsymbol y+\frac1{\boldsymbol 1^Te^{\boldsymbol z}}\frac{\partial\boldsymbol 1^Te^{\boldsymbol z}}{\boldsymbol z}\\ &=-\boldsymbol y+\frac{e^\boldsymbol z}{\boldsymbol 1^Te^{\boldsymbol z}}\\ &=softmax(\boldsymbol z)-\boldsymbol y \end{aligned} ∂z∂C=−y+1Tez1z∂1Tez=−y+1Tezez=softmax(z)−y
⭐️ 神经网络,深度大有什么特点?宽度大呢?
[1] 深度学习网络的宽度和深度怎么理解,增加宽度和深度对网络模型有什么影响?
- 宽度可以理解为每一层的feature数,深度代表feature进行非线性变换的次数
- 在同样参数量的时候,扩宽网络比加深网络更容易训练,因为每一层都是在GPU中并行计算的;不过通常来说,加深网络通常比扩宽网络更能提高模型的表达能力,更容易取得更高的精度
- 宽度大和深度大都是确保模型的拟合能力的关键,两者都很重要
⭐️ 为什么激活函数选tanh不选sigmoid,sigmoid函数有什么问题
因为sigmoid导数值域在0到0.25,连乘后容易导致梯度消失
⭐️ 简单介绍一下各个激活函数
[1] 常用激活函数优缺点分析
[2] 神经网络激活函数优缺点分析
[3] 常用激活函数及其导数
[4] GELU与Swish激活函数
BERT、RoBERTa、ALBERT、GPT/GPT-2 等预训练模型都使用了GELU激活函数
⭐️ 残差网络中残差块的作用
解决网络过深带来的梯度消失的问题
⭐️ 损失函数常见的有哪几个,原理是什么,有什么特点
[1] 常见回归和分类损失函数比较
均方误差损失、二分类交叉熵(等价于Logistic Loss)、多分类交叉熵、合页损失Hinge Loss、指数损失
Hinge loss为svm中使用的损失函数,hinge loss使得 y f ( x ) > 0 yf(x)>0 yf(x)>0 的样本损失皆为0,由此带来了稀疏解,使得svm仅通过少量的支持向量就能确定最终超平面。
指数损失是AdaBoost中使用的损失函数,使用exponential loss能比较方便地利用加法模型推导出AdaBoost算法 。
⭐️ 初始化权重过程中,权重大小在各种网络结构中的影响,以及一些初始化的方法(公式);偏置的初始化
[1] 聊一聊深度学习的weight initialization
[2] Xavier初始化原理
[3] 深度学习权重初始化的几种方法
[4] 花书:初始化权重:p184; Chapter 8.4 偏置初始化:p186页底 Chapter 8.4
一般不能用全0初始化,但是逻辑斯谛回归可以,理由见:什么时候可以将神经网络的参数全部初始化为0?
一般常用的初始化随机正态分布初始化,Xavier初始化,He初始化
(1)随机正态分布初始化
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01 # 均值为0,标准差为0.01
(2)Xavier 初始化
Xavier初始化有两种,Xavier Uniform和Xavier Normal,适用于激活函数 sigmoid 和 tanh.
Xavier初始化的目标是使得权重矩阵的方差为 [ 2 ] ^{[2]} [2]:
V a r ( w ) = 2 n i n + n o u t Var(w)=\frac{2}{n_{in}+n_{out}} Var(w)=nin+nout2
若希望 w w w 服从正态分布,则可以得到 Xavier Normal 的初始化公式:
w ∼ N ( 0 , 2 n i n + n o u t ) w \sim N(0,\frac{2}{n_{in}+n_{out}}) w∼N(0,nin+nout2)
若希望 w w w 服从均匀分布,则根据 x ∼ U [ a , b ] x \sim U[a,b] x∼U[a,b]的方差公式 ( b − a ) 2 12 \frac{(b-a)^2}{12} 12(b−a)2,可以得到 Xavier Uniform 的初始化公式:
w ∼ U [ − 6 n i n + n o u t , 6 n i n + n o u t ] w\sim U[-\sqrt\frac{6}{ {n_{in}+n_{out}}}, \sqrt\frac{6}{ {n_{in}+n_{out}}}] w∼U[−nin+nout6,nin+nout6]
(3)He 初始化
又称为 MSRA 初始化、Kaiming 初始化,适用于激活函数 Relu.
He初始化的目标是使得权重矩阵的方差为 [ 2 ] ^{[2]} [2]:
V a r ( w ) = 2 n i n Var(w)=\frac{2}{n_{in}} Var(w)=nin2
若希望 w w w 服从正态分布,则可以得到 MSRA Normal 的初始化公式:
w ∼ N ( 0 , 2 n i n ) w \sim N(0,\frac{2}{n_{in}}) w∼N(0,nin2)
若希望 w w w 服从均匀分布,则根据 x ∼ U [ a , b ] x \sim U[a,b] x∼U[a,b]的方差公式 ( b − a ) 2 12 \frac{(b-a)^2}{12} 12(b−a)2,可以得到 MSRA Uniform 的初始化公式:
w ∼ U [ − 6 n i n , 6 n i n ] w\sim U[-\sqrt\frac{6}{ {n_{in}}}, \sqrt\frac{6}{ {n_{in}}}] w∼U[−nin6,nin6]
另外,偏置bias通常初始化为 0 [ 4 ] 0 ^{[4]} 0[4]
⭐️ 学习率算法的做法和特点:SGD、Momentum、AdaGrad、RMSProp、Adam
[1] 从 SGD 到 Adam —— 深度学习优化算法概览(一) 比较简洁通俗地阐述各算法思路
[2] 深度学习——优化器算法Optimizer详解 公式清楚明确
[3] 一个框架看懂优化算法之异同 SGD/AdaGrad/Adam 对动量的解释更清楚,见AdaGrad一节
[4] 深度学习优化器Optimizer公式简记 本人对公式的总结笔记
⭐️ Dropout原理
[1] 神经网络Dropout层中为什么dropout后还需要进行rescale
下图来自资料 [1].

花书7.12节:Dropout可以看做是对多个模型进行Bagging,因为每个子网络用到的训练集(一个Batch)都是有放回采样的原始数据集的一个子集,但区别在于Dropout情况下所有子模型的参数都是来自父网络的,所以是共享参数的,而Bagging的情况下所有子模型是独立的。
花书7.4节,7.12节:Dropout可以被看作是通过噪声相乘构建新输入的过程;Dropout的噪声是乘性的,比加性噪声更有效(什么鬼??).
⭐️ Dropout会有啥问题
[1] 对Dropout的理解
Dropout缺点就是会明显增加训练时间,因为引入dropout之后相当于每次只是训练的原先网络的一个子网络,为了达到同样的精度需要的训练次数会增多。
⭐️ 神经网络如何加速
TODO
https://www.jiqizhixin.com/articles/2018-05-22-9
https://www.jiqizhixin.com/articles/2018-05-18-4
https://zhuanlan.zhihu.com/p/27423806
使用知识蒸馏等模型压缩方法来加速
⭐️ focal loss的原理
TODO
https://zhuanlan.zhihu.com/p/32423092
⭐️ 极大似然估计和梯度下降区别?
极大似然法是参数估计的方法,用极大似然的思路可以推导模型的目标函数;梯度下降是优化算法,用于求解具体的目标函数的最优解.
⭐️ 写一下梯度下降的伪代码
for i in range(epochs):
params_grad = evaluate_gradient(loss_function,data,params)
params = params -learning_rate * params_grad
⭐️ gru cell比lstm cell的优点是什么
除了速度快还有其他的??
⭐️ 实际场景中的softmax按照公式会出现问题(上溢与下溢问题),应该如何解决,softmax代码实现
[1] softmax数值稳定性问题以及CrossEntropyWithLogits的由来
⭐️ 少样本的情况怎么缓解
- 迁移学习
- 数据增强
- 使用各种缓解过拟合的手段,例如 Dropout、L1和L2正则化
- 实在太少可以考虑不使用深度学习,尝试 SVM、XGBoost 等统计机器学习模型
⭐️ batchsize大或小有什么问题
[1] 深度学习中的batch的大小对学习效果有何影响?
| 优点 | 缺点 | |
|---|---|---|
| bs大 | 显存利用率高,训练速度快,梯度方向更准确,收敛更快 | 对内存要求更高,且过大的bs会导致模型泛化性能下降 |
| bs小 | 给梯度计算带来噪声,可以帮助梯度下降脱离局部极小值点 | 梯度下降方向容易震荡,因此收敛速度过慢 |
⭐️ 学习率如何选择
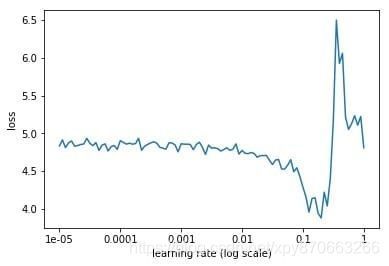
[1] 如何找到最优学习率
一般是直接试下各个量级的初始学习率就行,例如 1 e − 3 1e-3 1e−3, 1 e − 4 1e-4 1e−4 等。不过资料[1]建议可以通过从很小的学习率(例如 1 e − 5 1e-5 1e−5)开始,在每个batch都将学习率递增一点,并记录下每个batch的loss,就得到了学习率与loss的曲线图,据此来判断学习率选择什么值时能使loss具有较大的下降速度。
NLP
⭐️ word2vec激活函数,
W2V隐藏层没有激活函数. 对于输出层,理论上使用 softmax 激活,但实际中使用h-softmax和负采样都是将多分类转化为 k 个二分类问题,所以实际用的是 sigmoid 激活.
⭐️ word2vec对比Glove(w2v缺点,Glove优点)
-
训练方式的不同。Glove在共现矩阵的非零数据上训练,有效地利用了语料库的全局统计信息,而Word2Vec是利用语料库的上下文窗口的数据来训练。
-
Glove仅需要全局统计信息来训练,所以在训练时收敛更快,训练周期较word2vec较短且效果更好。
-
Glove可拓展性好,对于很小或很大的corpus都可以有效地训练;另外,对于限制embedding维度更低的情况,Glove也表现很好。
-
word2vec和Glove共有的缺点是无法解决一词多义现象,直到ELmo出现
⭐️ SG和CBOW各自的优缺点、稀疏词向量用skip-gram还是cbow训练更好 、对生僻词谁更好?
[1] NLP中的Embedding方法总结
两方面对比SG和CBOW:
- 训练的速度不同。CBOW比SG的训练速度快了几倍,因为从训练集的样本数量来说,CBOW的样本数量比SG样本数量少得多。
- 训练的效果不同。SG适用于相对少量的训练数据,对于生僻词的效果更好,而CBOW对常用词的表征的效果要比SG稍微好一点。
⭐️ fasttext原理,fasttext哈希规则,怎么把语义相近的词哈希到一个桶里
[1] NLP中的Embedding方法总结
[2] fastText原理和文本分类实战,看这一篇就够了
Fasttext特点小结:
1、对于一个词,将其字符级 n-gram 的Embedding与该词的Embedding求和作为原词的Embedding,作用:
- 为生僻词生成更好的Embedding,即使一个单词出现的次数很少,组成该单词的字符和其他单词也有共享的部分,而那些字符级n-gram可以通过对常用词来训练得很好.
- 为未登录词(OOV)提供更好的Embedding,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量
2、为了节省内存,对哈希到同一个位置的字符n-gram使用相同的Embedding,哈希函数使用的是FNV函数(具体来说是衍生版本Fowler–Noll–Vo 1a).
3、在分类任务中,使用词语级别的n-gram,与Text-CNN很类似,都是基于n-gram理论,可以捕捉到词序信息
⭐️ 层次化softmax和负采样的优缺点、层次softmax每次是怎么更新参数的、负采样下的目标函数,具体实现细节
[1] NLP中的Embedding方法总结——负采样与分层softmax
- h-softmax对生僻词的训练效果更好
- 负采样对常用词的效果更好,并且在Embedding维度较低的限制下效果比h-softmax更好
- 层次化softmax和负采样都是将softmax层的多分类转换成 K 个二分类问题,具体实现见资料[1]
⭐️ 滑动窗口大小以及负采样个数的参数设置以及设置的比例;
[1] NLP中的Embedding方法总结
- 对高频词进行下采样(sub-sampling)可以提高精度与速度,其对应的sample参数通常在 1 e − 3 1e-3 1e−3 到 1 e − 5 1e-5 1e−5 之间,默认 1 e − 3 1e-3 1e−3
- 负采样的参数选择:对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words
- 通常来说Embedding维度越高,效果越好,但不是总是这样
- 窗口大小,SG常使用10左右,而CBOW常使用5左右
⭐️ 怎么衡量学到的embedding的好坏
- 相似的词应该具有距离接近的Embedding
- Embedding应该可以衡量词语pair的关系,例如 v m a n − v w o m a n , v k i n g − v q u e e n , v b r o t h e r − v s i s t e r v_{man} - v_{woman}, v_{king} - v_{queen}, v_{brother} - v_{sister} vman−vwoman,vking−vqueen,vbrother−vsister应该大致相等
⭐️ N-Gram,TF-IDF
[1] N-Gram语言模型
[2] 自然语言处理中N-Gram模型介绍
[3] NLP中的Embedding方法总结——TFIDF
⭐️ 不同场景下如何得到文本语义相似度:短文本与短文本、长文本与长文本、短文本与长文本
[1] 短文本相似度计算
- 编辑距离、词袋模型/VSM/TDIDF这些传统方法;
- 直接用各种深度学习模型得到句子向量,然后计算余弦相似度;
- Sentence2Vector
- 长文本引入主题模型辅助判断
⭐️ 命名实体识别的Bi-LSTM+CRF,具体实现步骤,crf的原理,优势。
[1] Bi-LSTM+CRF理解
CRF的优势:
LSTM 生成的标签是相互独立的,相当于假设一个标签序列 y y y 在给定输入文本 x x x 时的条件概率 P ( y 1 , y 2 , . . . , y T ∣ x ) = ∏ i = 1 T P ( y i ∣ x ) P(y_1,y_2,...,y_T|x)=\prod_{i=1}^T P(y_i|x) P(y1,y2,...,yT∣x)=∏i=1TP(yi∣x)。
CRF有转移矩阵,可以考虑相邻的 tag 之间的依赖关系,相当于假设一个标签序列 y y y 在给定输入文本 x x x 时的条件概率 P ( y 1 , y 2 , . . . , y T ∣ x ) = ∏ i = 1 T P ( y i ∣ y i − 1 , x ) P(y_1,y_2,...,y_T|x)=\prod_{i=1}^T P(y_i|y_{i-1},x) P(y1,y2,...,yT∣x)=∏i=1TP(yi∣yi−1,x)。
⭐️ CNN和RNN各自在文本方面的特点,什么时候用
TextCNN基于N-gram理论,适用于需要提取局部特征的任务,TextRNN则可以捕获长距离依赖,所以更适用于需要分析长距离依赖的文任务
⭐️ seq2seq模型的缺点是什么,怎么解决这个缺点
[1] Seq2Seq中的Exposure Bias现象的原因以及解决办法
[2] Seq2Seq中的Copy Mechanism、Coverage Mechanism和Review Mechanism
[3] 论文阅读 seq2seq模型的copy机制
[4] 论文阅读 seq2seq模型的coverage机制
问题一:Exposure Bias
解决办法:
- Scheduled Sampling
- Sentence Level Oracle Word + Gumbel Noise
- 启发式的随机替换、梯度惩罚
- 基于强化学习直接优化BLEU,包括 MIXER 及其改进
问题二:无法生成 OOV(Out of Vocabulary)词汇
解决办法:Pointer Generator Network(Copy Mechanism)
问题三:生成重复内容,特别是对于长文本生成任务
解决办法:
- Coverage Mechanism
- Review Mechanism
⭐️ 介绍LDA
TODO
⭐️ 注意力机制的原理,其几种不同的情形
[1] attention模型方法综述
[2] Neural Machine Translation by Jointly Learning to Align and Translate
[3] Effective Approaches to Attention-based Neural Machine Translation
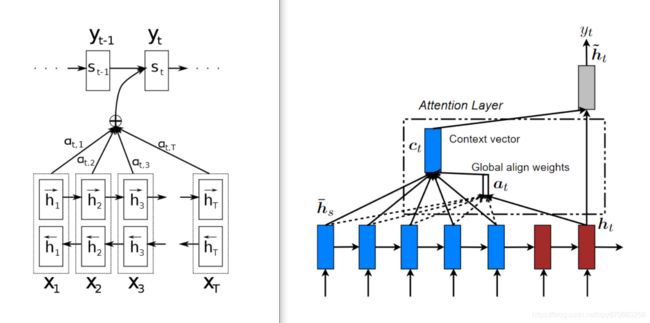
soft-attention:给一个向量 s s s 和一组向量 H = [ h 1 , h 2 , ⋯ , h T ] H=[h_1,h_2,\cdots,h_T] H=[h1,h2,⋯,hT],attention操作是指用某种评分函数得到 s s s 与每个 h t h_t ht 的分数,然后用 softmax 归一化作为权重,再用这些权重对 H H H 做加权和,最终得到一个向量.
注意评分函数的三种选择:点乘 s T h t s^Th_t sTht,加权点乘 s T W h t s^TWh_t sTWht,加和 v T tanh ( W s s + W h h t + b ) v^T\tanh(W_s s+W_h h_t+b) vTtanh(Wss+Whht+b),中括号表示拼接, v v v 与 W W W 是可学习的.
- 在 Decoder 的每个时间步,用上一个时间步的隐状态 h t − 1 h_{t-1} ht−1 来对 Encoder 的所有时间步的隐状态 H H H 作 soft-attention 操作,得到的 c t c_t ct 与上一个时间步的输出/标签 y t − 1 y_{t-1} yt−1 拼接起来作为RNN的输入 [ 2 ] ^{[2]} [2].
- 在 Decoder 的每个时间步,只使用上一时间步的输出/标签 y t − 1 y_{t-1} yt−1 作为输入,然后得到该时间步的隐状态 h t h_t ht 后,用其与 Encoder 的所有时间步的隐状态 H H H 作 soft-attention 操作,得到的 c t c_t ct 与 h t h_t ht 拼接,再经过全连接层和 Softmax 层得到输出 [ 3 ] ^{[3]} [3].
- HAN也是使用soft-attention的。在每个层级(词/句),经过双向 RNN 能得到句子/文档的隐状态 H H H,然后经过一次非线性变化得到 H ′ H^\prime H′,再用一个 trainable 的向量来和 H ′ H^\prime H′ 做 soft-attention操作得到句子/文档的representation.
- Self-Attention 见下个问题的答案.
⭐️ 画一下ELMo的模型图,讲一下ELMo的原理,为什么它能解决词歧义的问题?
[1] NLP中的Embedding方法总结——ELMO, GPT2, BERT
⭐️ self-attention公式,multi-head attention代码实现
self-attention:
输入:
- 一组Tensor, X = [ x 1 , x 2 , ⋯ , x N ] X=[x_1,x_2,\cdots,x_N] X=[x1,x2,⋯,xN], X X X 维度为 [ N , i n p u t ] [N,input] [N,input],以二维Tensor为例
- 该self-attention层的参数矩阵 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV,维度均为 [ i n p u t , h i d d e n ] [input,hidden] [input,hidden]
输出:一组Tensor, Z = [ z 1 , z 2 , ⋯ , z n ] Z=[z_1,z_2,\cdots,z_n] Z=[z1,z2,⋯,zn], Z Z Z维度为 [ N , h i d d e n ] [N,hidden] [N,hidden]
操作: Q = X W Q Q=XW_Q Q=XWQ K = X W K K=XW_K K=XWK V = X W V V=XW_V V=XWV Z = s o f t m a x ( Q K T h i d d e n ) V Z=softmax(\frac{QK^T}{\sqrt{hidden}})V Z=softmax(hiddenQKT)V
multi-head attention代码:
def attention(query, key, value, mask):
d_k = query.size(-1)
# scores维度:[batch_size, head, query_seq_len, key_seq_len]
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
return torch.matmul(p_attn, value)
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_input, d_model):
super(MultiHeadedAttention, self).__init__()
self.d_k = d_model // h
self.h = h
self.linears = nn.ModuleList([nn.Linear(d_input if n!=3 else d_model, d_model) for _ in range(4)])
def forward(self, query, key, value, mask):
bs = query.size(0)
# project, view, transpose
query, key, value = [l(x).view(bs, -1, self.h, self.d_k).transpose(1, 2)\
for l, x in zip(self.linears, (query, key, value))]
# scaled dot-product attention
x = attention(query, key, value, mask)
# transpose, view, project
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
⭐️ self-attention的点积结果为什么要缩放,为什么其他场景下的softmax前不需要scale?
[1] transformer中的attention为什么scaled?
[2] 知乎答案2
随着 d k d_k dk 的增大, q T k q^Tk qTk 的结果也随之增大,这样会将softmax函数推入梯度非常小的区域,使得收敛困难. 具体关于softmax对输入的梯度为什么会非常小,见[1].
其实所有地方的softmax都一样,只要softmax的输入的数量级比较大,就有必要进行scaled。但是如果具体分析softmax的使用场景,会发现有些场景不需要scaled。
- 对于attention场景下的softmax,如果使用 s c o r e ( s , h t ) = v T tanh ( W [ s , h t ] ) score(s,h_t)=v^T\tanh(W[s,h_t]) score(s,ht)=vTtanh(W[s,ht]) 形式的评分函数,由于有 t a n h tanh tanh 输出值在 [ − 1 , 1 ] [-1,1] [−1,1] 这个限制,分数值的数量级不会太大;而对于点乘 s T h t s^Th_t sTht(self-attention中使用的)和加权点乘 s T W h t s^TWh_t sTWht,他们的输出值的数量级(可以由数据分布的均值和方差来衡量)是与输入向量的维度大小 d k d_k dk 有关的(证明过程见[1]),所以需要scaled。如果问为啥其他用加权点乘的论文不使用scaled,是因为[2]给的论文实验表明,在 d k d_k dk 不大的情况下问题不大, d k d_k dk 更大时其实有必要使用scaled.
- 对于分类场景下的softmax,我们一般都使用交叉熵损失,这种情况下损失函数 C C C 对softmax的输入 z z z 的导数是 s o f t m a x ( z ) − y softmax(z)-y softmax(z)−y,不会出现 d k d_k dk 较大梯度较小的情形。
⭐️ Transformer的原理,画Transformer的结构
 ⭐️ Transformer 中 mask 的作用
⭐️ Transformer 中 mask 的作用
Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
Padding Mask是指attention机制不应该把注意力放在这些padding字符上,具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),经过 softmax,这些位置的权重就会为0。
Sequence mask是为了使得 decoder 不能看见未来的信息,即第 t t t 个时间步的attention只能看到前n个单词,假如mask中 False表示需要遮盖的地方,
具体做法是:产生一个下三角矩阵,上三角的值全为0,在pytorch中mask用法是 tensor.masked_fill(target,mask==0,-1e9)。
mask实际使用时维度为:[ batch_size, head_num, query_seq_len, key_seq_len ]
对于padding mask,我们构造[ batch_size, key_seq_len ],然后加上维度1和维度2,得到[ batch_size, 1, 1, key_seq_len ]
对于sequence mask,我们构造[ batch_size, query_seq_len, key_seq_len ],然后加上维度1得到[ batch_size, 1, query_seq_len, key_seq_len ]
Decoder 的 self-attention 使用的 mask 为 padding mask 与 sequence mask 求 AND 操作(使用0/1时则是乘法操作)的结果
⭐️ self-attention替代lstm的优势
[1] transformer和LSTM对比的设想?
self-attention对比lstm的优势:
- self-attention 建立长程依赖的能力比LSTM强
- self-attention 的每个时间步可以并行计算,效率更高(但解码部分不能并行)
self-attention 建立长程依赖的能力比 LSTM 强,但是要设计好位置编码,Transformer 中使用的位置编码函数不是很好,有不少论文尝试修改这里,包括Bert使用的是可学习的位置编码
⭐️ Transformer中Multi-head的作用?
这可以类比CNN中同时使用多个卷积核的作用,可以让模型去关注不同方面的信息,有助于网络捕捉到更丰富的特征。
⭐️ Bert原理,损失函数
[1] NLP中的Embedding方法总结——ELMO, GPT2, BERT
| 特征提取器 | 预训练阶段的任务 | 将得到的representation运用到下游任务的策略 | |
|---|---|---|---|
| ELMo | 2个单向双层 LSTM | biLM: forward LM + backward LM | feature-based |
| GPT | Transformer Decoder | unidirectional LM | fine-tuning |
| BERT | Transformer Encoder | Masked LM + Next Sentence Prediction | fine-tuning |
设 N 为样本编号集合,在MLM任务中,设 M M M 为被mask的输入 token 的下标的集合,则损失函数是:
L o s s = ∑ n ∈ N ∑ i ∈ M C E ( y n , i , y ^ n , i ) Loss=\sum_{n\in N}\sum_{i \in M}CE(y_{n,i},\hat y_{n,i}) Loss=n∈N∑i∈M∑CE(yn,i,y^n,i)
NSP任务的损失函数是:
L o s s = ∑ n ∈ N B C E ( y n , y ^ n ) Loss=\sum_{n\in N} BCE(y_n,\hat y_n) Loss=n∈N∑BCE(yn,y^n)
⭐️ 同样是双向模型,ELMO和BERT的区别在哪
ELMO只是2个单向语言模型拼到一起,BERT才是真正的双向语言模型,也就是在预测一个词时,是基于全局上下文信息而不是只使用了来自一个方向的句子信息。
⭐️ Roberta和Bert有什么区别
[1] 改进版的RoBERTa到底改进了什么?
[2] BERT及RoBERTa论文笔记


⭐️ GPT2和GPT有什么区别


⭐️ XLNet和Bert有什么区别
[1] 从语言模型到Seq2Seq:Transformer如戏,全靠Mask
[2] 知乎文章
GPT/GPT2在预训练的时候是用Transformer的decoder来做传统的单向语言模型,而Bert用的是Transformer的encoder来做Mask LM,双向的语言模型,XLNet和他们最大的区别在于用的是Permutation LM,也叫做乱序语言模型。
语言模型实际上是将句子的所有单词的联合概率分解为单词的条件概率的乘积,然后对每个条件概率进行建模。而传统的单向语言模型都是分解为
P ( x 1 , x 2 , . . . , x n ) = P ( x 1 ) P ( x 2 ∣ x 1 ) . . . P ( x n ∣ x 1 , x 2 , . . . , x n − 1 ) P(x_1,x_2,...,x_n)=P(x_1)P(x_2|x_1)...P(x_n|x_1,x_2,...,x_{n-1}) P(x1,x2,...,xn)=P(x1)P(x2∣x1)...P(xn∣x1,x2,...,xn−1)
而XLNet的乱序语言模型则相当于考虑了单词联合概率所有的分解顺序,一共有 n ! n! n! 种分解顺序:

乱序语言模型又称为Permutation LM,由XLNet提出。特点在于:
1、预训练与finetune阶段都没有使用[MASK]字符,而是对输入单词序列不做任何改变,这解决了降噪自编码模型中,预训练阶段与微调阶段之间有分歧mismatch的缺陷。
2、通过随机重拍 Position Embedding 来达到对单词进行重排列的效果(而不需要修改输入单词的顺序和Transformer Decoder中的下三角掩码),在预训练阶段,对所有排列方式进行随机采样,用少数的排列顺序进行训练,解决了自回归语言模型中,无法同时使用双向的上下文信息的缺陷。

⭐️ 如何用预训练语言模型来解决文本生成的问题?微软的MASS了解吗
传统的文本生成NLG的架构一般是encoder-decoder,encoder负责编码源文本信息,decoder负责解码目标文本。解码的时候都是一步一步decode的,生成一个词后,将这个输出或者对应的真实标签作为下一个时间步的输入。
从结构上来说,Bert相当于一个Transformer encoder,GPT2相当于一个Transformer decoder,最大的区别是Bert的预训练过程是双向的语言模型,被称为DAE LM。而GPT2则利用了带mask的多头注意力来实现单向的语言模型,也就是预测每一个词时只能使用上文的信息而不能使用下文的信息。
如果你对Denoising Autoencoder比较熟悉的话,会看出 Masked LM 确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音
Bert预训练时候的 DAE LM 任务决定了Bert是更适合用来做特征抽取的,因为输出可以考虑到双向的信息。但是 Bert 的这种 DAE 模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题(生成文本的时候不是“上文+[MASK]+下文”的形式)
而GPT2则更适合用来做文本生成,因为它带mask的多头注意力可以在decode一个词的时候防止看到后面的信息。当然如果我们只给Bert前文信息+[MASK],不给Bert后文的信息,然后用[MASK]的输出去预测词也是可以的,只不过这样就没有利用到Bert的双向抽取信息的特点了。
另外要说明的是,无论是单独用Bert还是单独用GPT2,他们都更适合用来做无条件(unconditional)的文本生成,也就是作为一个decoder直接根据上文来解码下文,因为没有encoder端,所以没有考虑目标文本在给定源文本的条件下的条件概率。
基于 Bert 和 GPT2 没办法做条件文本生成 的缺陷,微软针对文本生成提出了新的预训练模型MASS,它是在Transformer的架构上设计了一个新的预训练任务,mask掉encoder端的源文本连续的某段,然后需要decoder来解码被mask掉的部分。通过这样的任务来使得encoder必须能够理解并编码未被mask的源文本,而decoder必须能够从编码后的源文本中抽取有用的信息来解码目标文本。
⭐️ 了解UNILM吗
[1] 从语言模型到Seq2Seq:Transformer如戏,全靠Mask
[2] 【NLP】BERT生成式之UNILM
UNILM是直接将Seq2Seq当成句子补全来做,认为不管是什么LM,本质都是在训练时能获取到什么信息,在实现层面其实就是对输入的哪部分进行mask的问题。所以完全可以把Seq2Seq的LM整合到BERT里。UNILM 预训练的输入类似于Bert的NSP任务,由两个句子用特殊字符拼接而成, [SOS] S1 [EOS] S2 [EOS] ,但是区别在于修改了MASK的形式,S1可以获取整个S1所有位置的信息(当然,除了padding部分),S2中的token只能获取S1和自己之前的token信息,如下图所示。
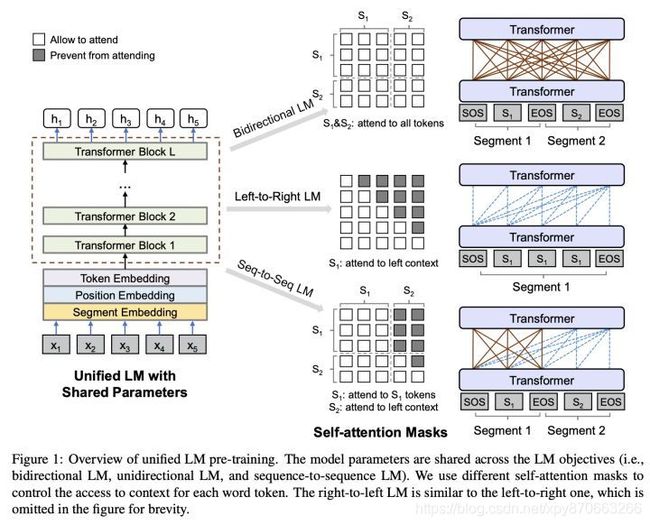
⭐️ 语言模型的发展历史
[1] 知乎文章
[2] 从语言模型到Seq2Seq:Transformer如戏,全靠Mask
一、自回归语言模型
如ELMo/GPT/GPT2,特点是单向的,在预测一个词时只能利用它的上文(或者只能利用下文)的信息来预测。
二、降噪自编码模型(DAE)
以BERT为代表,特点是双向语言模型,缺陷是训练过程和在下游fine-tune的过程不一致(fine-tune时没有[MASK]字符),所以不适合用于作为NLG任务。
三、Permutation LM,又称为乱序语言模型
由XLNet提出。特点在于:
1、预训练与finetune阶段都没有使用[MASK]字符,而是对输入单词序列不做任何改变,这解决了降噪自编码模型中,预训练阶段与微调阶段之间有分歧mismatch的缺陷。
2、通过随机重拍 Position Embedding 来达到对单词进行重排列的效果(而不需要修改输入单词的顺序和Transformer Decoder中的下三角掩码),在预训练阶段,对所有排列方式进行随机采样,用少数的排列顺序进行训练,解决了自回归语言模型中,无法同时使用双向的上下文信息的缺陷。
四、适用于条件文本生成的语言模型
MASS中基于Transformer设计的Seq2Seq的语言模型。mask掉encoder端的源文本连续的某段,然后需要decoder来解码被mask掉的部分
UNILM中将Seq2Seq任务整合到Bert架构中的语言模型。对于输入序列 [SOS] S1 [EOS] S2 [EOS],预训练任务是根据S1的所有信息和和S2中上文的信息来预测S2中的下一个单词,这是通过修改了Bert的 self-attention 的MASK矩阵来实现的,S1可以获取整个S1所有位置的信息(当然,除了padding部分),S2中的token只能获取S1和在自己之前的S2的token的信息。
⭐️ 标签平滑
[1] 标签平滑——处理标注噪声的方法
就是把 k k k 维标签 y y y 这个 one-hot 向量里面的 1 1 1 替换为 1 − ϵ 1- \epsilon 1−ϵ,把 k − 1 k-1 k−1 个 0 0 0 替换为 ϵ k − 1 \frac{\epsilon}{k-1} k−1ϵ ,这是因为大多数数据集的标签都有一定错误,这样处理可以显式地对标签上的噪声进行建模,使得模型更加鲁棒.
⭐️ 根据任务选用CNN、RNN和Transformer的一般原则
- 允许 pretrain,用基于transformer的预训练模型;
- 大量数据 from scratch,用transformer;
- 小数据 from scratch,分类用CNN,标注和生成用RNN。
⭐️ 文本生成用什么评价指标,BELU不一定好,想想其他的
[1] 机器翻译评价指标 — BLEU算法
[2] 自动文摘评测方法:Rouge-1、Rouge-2、Rouge-L、Rouge-S
[3] CIDER paper
[4] 文本生成不同的评价指标的优缺点?——回答1
[5] 文本生成不同的评价指标的优缺点?——回答2
BLEU、METEOR、ROUGE,一般在翻译或摘要里用,CIDEr 一般在图像字幕生成(Image Captioning)里用。
1、BLEU只看重precision,不看重recall。而且短句得分较高。虽然引入了brevity penalty,也还是不够。
2、ROUGE-1、ROUGE-2,ROUGE-3基于召回率,ROUGE-L基于F值。
3、METEOR考虑了同义词、词干相同的翻译,并基于F值来评价。
3、CIDer基于n-gram的TFIDF值,常用于图像字幕生成,因为图像字幕生成评价的要点是看模型有没有抓取到关键信息。
⭐️ 介绍一下beam search
[1] seq2seq中的beam search算法过程
[2] 笔记 | 什么是Beam Search
假设词表大小为3,包含[A, B, C],Beam Width为2
生成第1个词的时候,对 P ( A ) 、 P ( B ) 、 P ( C ) P(A)、P(B)、P(C) P(A)、P(B)、P(C) 进行排序,选取概率最大的两个,假设为A,C
生成第2个词的时候,分别将A,C作为输入,得到词表上的概率分布,得到新的6个序列为AA、AB、AC,CA、CB、CC,然后同样取概率最大的两个作为当前序列,假设为AA、CB,则下一步的输入分别是A和B
重复以上的过程,直到遇到结束符为止,最终输出2个得分最高的序列。
⭐️ 维特比算法与beam-search的时间复杂度以及区别
时间复杂度都是 O ( T × N ) O(T \times N) O(T×N),其中 T T T 为序列长度, N N N 为可选的标记个数。
⭐️ 如何评价文本生成的质量
BLEU、METEOR、ROUGE,一般在翻译或摘要里用,CIDEr 一般在图像字幕生成(Image Captioning)里用。
⭐️ 文本分类的评价指标
对于多分类来说,常使用Macro-F1@K,Micro-F1@K,Recall@K。Micro-F1需要先计算出每一个类别的f1,然后通过求均值得到在整个样本上的f1。Micro-F1不区分类别,直接使用整体样本的precision和recall来计算f1.
⭐️ 文本分类的发展历史
⭐️ 机器翻译:pointer network和copynet
[1] Seq2Seq中的Copy Mechanism、Coverage Mechanism和Review Mechanism
[2] 论文阅读 seq2seq模型的copy机制
Copy Mechanism用于解决无法生成OOV词汇的问题,我目前了解到的Copy Mechanism有两种,比较常用的是pointer generator network。
1、在decoder的每个时间步,使用隐状态、attention结果、上一时间步的真实标签来作为输入,计算出一个标量的概率值 p g e n p_{gen} pgen,代表这一步需要使用生成词汇的概率。
2、复用attention过程得到的attention权重,将其作为输入文本词汇的概率分布。
3、使用拓展后的词表,修改词 w 的概率分布为下图中的(1)式,用于计算交叉熵。

⭐️ textcnn原理,pooling的作用,有哪些pooling
花书p207; p210 Chapter 9.3-4:pooling的意义
⭐️ sentence embedding有哪些方式,文章embedding
⭐️ 摘要抽取怎么做的
⭐️ albert相对于bert的改进
⭐️ 基于业务的问答系统如何设计
⭐️ 如何训练基于知识图谱的问答系统
⭐️ 基于匹配的问答系统的关键技术是什么
文本相似度匹配
⭐️ 开放式的对话系统如何训练
⭐️ 对话系统评价指标
⭐️ 介绍一下非任务型对话系统
https://blog.csdn.net/qq_28031525/article/details/79855018
海量数据
[1] 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
[2] 十道海量数据处理面试题与十个方法大总结
1、内存不足的问题:分治,先切分为多个文件,分别处理后,再将各自的结果归并。
2、使用哈希表来做统计,去重。
3、使用堆来获取Top k,时间复杂度 O ( N log k ) O(N\log k) O(Nlogk)。
⭐️ 千万向量中找到和单个向量相似度最高的一个
先聚类,然后输入向量先与聚类中心比较再与类中的向量比较
⭐️ 假如有10亿条搜索请求,怎么找出最热的前10条?
见:海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
⭐️ 代码实现海量数据处理问题:现在有一个比较小的数据表(包括id, score),另外有一个十分大的(上千万级别)的数据表(包括id, name),现在需要以id为索引将两张表合并,如何在O(n)时间复杂度完成。(hash map解决,参照这篇博客:十道海量数据处理面试题与十个方法大总结
)
⭐️ 海量数据处理。现在有1千万行词,需要统计各个词出现的次数,目前有一台机器内存1G,磁盘100G?(海量数据处理blog的第一题,先对原始文本进行分割再使用hashmap在各个文件中分别统计)。
⭐️ 千万级的数,选出最小的100个数
HR面
⭐️ 自我介绍
您好,我叫谢朋宇,来自中山大学数据科学与计算机学院,我在实验室负责的项目是一个交叉领域的项目,而自己感兴趣的研究方向是自然语言处理,特别是文本生成这块,理论学习方面的话,我就关键短语生成做过调研,对关键短语生成或文本生成的常用策略比较熟悉,实践方面的话,我在Kaggle上参加过两个NLP方面的比赛,一次是和别人组队拿了金牌,另一个SOLO的,现在正在进行中,距离比赛结束还有一个月,我目前名次是前 3%,处于银牌区。以上就是我的基本情况,谢谢。
⭐️ 是否能接受加班
我身边的人经常评价我是一个工作狂,实验室第一个到的和最后一个走的经常都是我,我也理解公司有时候会因为项目赶着上线或者出现故障需要修复等等原因而导致需要加班,这种情况下是可以接受的,也是职责范围内的事,另外如果团队里面强调工作效率,保证任务按时按点完成,那么有些加班就是可以避免的。
⭐️ 为什么转算法?
个人感觉算法的工作内容更有挑战性也更有趣,而且这几年国内也挺需要这方面的人的。
⭐️ 对我们部门的了解(阿里巴巴供应链平台事业部)
我在三面之后去查了一下,了解到ASCP(阿里巴巴供应链平台)事业部属于新零售技术事业群,主要的职责是整合供应链资源、解决产业痛点、服务消费者,为各个零售业务提供供应链管理的优化方案和大数据决策能力。例如算法团队可以提供 销售预测、动态定价、库存分布规划等模型来打造供应链平台的核心引擎,指导供应链全链路的决策和计划。
⭐️ 你觉得你加入我们部门的机遇是什么
在实际业务中打磨自己,把理论和业务结合,为公司带来实际的业绩提高,希望自己表现优秀,顺利转正。
⭐️ 比赛遇到的困难,项目遇到的困难
kaggle比赛困难:技术上的困难的话,数据不平衡,数据噪声多,数据量不够大。
simpedb困难:技术困难主要是join算法的优化,和死锁的检测和解除,这些都要查阅大量的中英文资料才能完成。
planner困难:原作者没有公开代码,用的数据集也是付费数据集,而有些细节论文也没讲的很清楚,所以复现起来很困难。
⭐️ Kaggle比赛的团队合作
我是主力之一,队伍5人里面有2个人不是很积极,我会找他们沟通,希望大家齐心协力打好比赛,不过他们有的时候的确是有其他事在忙,这也是没有办法的事。
⭐️ 在学校经历印象深刻的一件事
数学是我的优势学科,但是高考忘了涂答题卡,只能去普通一本,这也是我考研的初衷之一。
⭐️ 成长过程中影响最大的一件事
同上
⭐️ 失败经历
同上
⭐️ 为啥考计算机研究生
1、高考失手
2、想做算法岗,研究生学历比较合适
⭐️ 你大学有没有什么特别难的时候?怎么克服的?
大一的时候,花了很多精力才逐渐从高考失利的阴影中走出来,主要是靠和知心朋友一起聊,自己也加入社团,丝毫没有放松学习,紧张充实地过好学习和课余生活,就慢慢让时间淡化了。
⭐️ 在学校的生活有什么遗憾
我身边的人都评价我是工作狂,我的确将自己的时间基本都安排给了学习工作,社交娱乐都基本限于自己的小圈子,不是很主动参加社交,现在回想起来觉得安排多一点社交娱乐或许会更好。
⭐️ 职业生涯规划?
我一直都在关注和思考自己应该在NLP方向的发展,结合一些师兄师姐的建议,我以后可能还会偏重推荐系统、对话系统方向的学习。
职业发展的话,希望能有幸进入阿里实习并希望顺利转正,然后在大公司先待几年开阔熟悉下公司和行业的情况,再后面的事可能就要看到时候的情况了。
⭐️ 对实习有什么期许,对即将要实习的业务部门有什么看法
希望能扎实地提高自己的技术水平,并且为部门带来实际的收益,达到双赢,当然最大的期望还是能够顺利转正。我了解过ASCP的基本情况,觉得这是一个很有前景,对阿里在新零售方面的部署起到关键作用的一个部门,我也和面试官了解过部门中应用NLP的场景,他们也说我挺匹配岗位的,所以我很期待能加入实习。
⭐️ 目前在干些什么事
一方面是在准备各个公司的实习笔试面试,另一方面也在继续学习NLP方面的东西,例如二面面试官就建议我可以看看知识图谱方面的东西,另外我还在继续关注kaggle上的比赛,加入了一个新的比赛,目前位于银牌区,希望能拿到一个solo的金牌,这样写在简历上会比较有说服力。
⭐️ 反向提问环节
1、能够提前入职
2、是否支持远程实习,不能的话关于隔离的事情
⭐️ 简单描述一下自己是怎么样的人,或三个关键词评价自己 (优点)
自学能力强、踏实勤奋、喜欢专研问题。
⭐️ 缺点
1、没做好劳逸结合,是个工作狂,这样对身体有很大伤害,我也正在改善这点
2、我不是一个社交达人,只在自己的小圈子里面玩,没有很主动地去参与社交(不过也是有一些知心朋友的)
⭐️ 城市意向
最好广东内,或者杭州也挺好,主要是阿里总部在那
⭐️ 目前offer情况
其他公司都还处于面试流程,阿里这边是处理的比较快的了。
⭐️ 入职时间
可以马上入职,学校开学可能会比较迟,隔壁华工8月份开学。
其他
⭐️ 有什么想问我们的
⭐️ 本科是哪,研究生在哪,研究生的方向
⭐️ 是不是接受去深圳
⭐️ 实习时间段大概是什么时间
⭐️ 研究生最大收获
⭐️ 研究生与本科生区别
⭐️ 印象最深的paper和最近看过的paper