建表
CREATE TABLE `ts_ab` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` varchar(20) CHARACTER SET utf8 DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ind_b` (`b`) USING BTREE,
KEY `ind_a` (`a`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
CREATE TABLE `ts_ef` (
`id` int(11) NOT NULL,
`e` int(11) DEFAULT NULL,
`f` varchar(20) CHARACTER SET utf8 DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ind_e` (`e`) USING BTREE,
KEY `ind_f` (`f`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
插入数据
create PROCEDURE addDataab()
BEGIN
DECLARE i int;
set i=1;
WHILE(i<=10000) DO
INSERT ts_ab(id, a, b) VALUES(i, i, CONCAT('b',i));
set i= i+1;
end WHILE;
WHILE(i<=20000) DO
INSERT ts_ab(id, a, b) VALUES(i, i, CONCAT('c',i));
set i= i+1;
end WHILE;
WHILE(i<=30000) DO
INSERT ts_ab(id, a, b) VALUES(i, i, CONCAT('d',i));
set i= i+1;
end WHILE;
end;
CALL addDataab();
create PROCEDURE addDataef()
BEGIN
DECLARE i int;
DECLARE j int;
set i=1;
set j=1;
WHILE(i<=200) DO
set j=i;
if i >100 and i<=105 THEN
set j=105;
end if;
INSERT ts_ef(id, e, f) VALUES(i, j, CONCAT('b',j));
set i= i+1;
end WHILE;
end;
CALL addDataef();
1、索引
sql执行慢,第一想法就是加个索引呗。但有时尽管加了索引了,为什么执行还是这么慢的呢。这就要问你真正使用对了索引没有了。我们一般可以使用EXPLAIN来查看是否sql执行时是否使用了索引。对于索引还不怎么清楚的同学,建议你自行查看下我的上一篇文章【MySQL】索引
1.1对索引字段进行了函数操作


a字段上面建有索引,图1中对a字段进行了运算,图2中没有对a字段进行运算。
从结果可知,图1中进行了全表扫描,大概扫描了29484行,没有使用索引快速查询。图2表示查询使用了索引,扫描了1行。出现这种现场的原因是图1中的sql对索引字段进行的运算操作,你可以想象我们的索引是一棵B+树,如果一张表中有日期这个字段,并且对此字段加了索引。现在我们需要查询8月份的数据,如果我们sql写成
select * from cyj_test where month(createDate) = 8。createDate这个字段的索引是有序的,你觉得month(createDate) 还会是有序的吗?想想都觉得不会是有序的,所以,在对索引字段做了函数操作时,会破坏了索引的有序性,MySQL就干脆不走索引了。或许你会说加1操作后还是有序的啊,但对于MySQL来说,做了运算操作了,不会去理会操作后是否还是跟原索引一样的顺序,这可以理解为MySQL的一个"偷懒"行为。
1.2隐式类型转换


你会发现图4的查询没有走索引,在你对照了建表sql后你发现了原来a是int类型,去跟字符串做对比,而b是字符串类型去跟int做对比。那么,为什么图3却可以走索引呢?
如果你用对应的sql去查询数据,是能准确的查询到需要的结果数据的,这时候我们猜想肯定是数据库做了类型转换,那么数据库在字段类型不匹配时,是把字符串转换成int类型,还是把int类型转换成字符串呢?
测试sql
select '10' > 9;
如果返回结果是1,那么是字符串转成int
如果返回结果是0,那么是int转成字符串
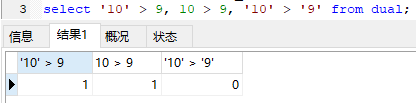
从结果上来看,是把字符串转换成了int。
回到一开始的图3和图4。图3中
a='1'会把字符串1转换成int类型的1,所以不影响索引。图4中
b=1会把字符串的b转换成int类型,实际操作为
CAST(b AS signed int) = 1。
对索引字段进行了函数操作,优化器在选择索引时会放弃走树索引搜索功能。
1.3隐式编码转换
待补充。。。(原因:查询很多资料说两表编辑不一样,例如utf8与utf8mp4,联表查询会导致索引失效,但我不能重现啊。)
1.4扫描行数过多
使用哪个索引是在优化器时决定的,在决定因素中就有一个是sql执行需要扫描的行数,当行数过多时,优化器会决定不使用该索引,例如下面:


需要扫描的行数是一个预估值,可以使用
show index from ts_ab;进行查看
Cardinality字值的估值,有时也会因这个预估值的不准确而导致走了全表扫描而没走索引,这时我们可以使用
analyze table ts_ab;让数据库重新采样估值,例如我执行完后重新查询的结果便走了索引。

当然,这个办法不可控。如果你的环境是真的要走a索引准确无误的话,可以使用
force index(ind_a)强行走索引。

1.5最左前缀没使用对
【MySQL】索引中介绍了最左前缀的定义:最左前缀原则指的是只要sql满足最左前缀,就可以利用索引进行高效的查询。最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。如果我们使用最左前缀时没理解好定义来操作,是不能使用索引的。


图11中没真正的使用字符串索引的最左M个字符进行查询。还有就是如果联合索引为
INDEX index_a_b (a, b),这时候根据最左前缀原则可以对a单独使用索引,但却不可以对b单独使用索引。这个可以自己尝试下。
2、等待锁
2.1表级别的锁或行锁都会使查询处于等待状态。
表级别锁分为表锁和元数据锁MDL(meta data lock)。
表锁使用lock tables t1 read, t2 write。执行这个命令后,当前线程只能对表t1读,对表t2读书,不能对表t1写。其他线程写t1、请写t2都会被阻塞。
MDL是在mysql5.5时引入的,当对一个表进行增删改查时对表加锁,当对一个表做数据结构变更时加锁,在加锁时会进行阻塞。
上述锁可以使用show processlist进行查看,会提示Waiting for table metadata lock。
2.2flush
在session1中执行select sleep(1) from ts_ef,在session2中执行flush tables ts_ef,在session3中执行select * from ts_ef where id = 1。这时session3中的查询会被卡住,使用show processlist进行查看,会提示Waiting for table flush。
这个是因为在session1中的sleep(1)是指执行1万秒,导致session2中的flush被卡住,进而影响了session3。
2.3行锁
java开发中会使用事务,当进行for update查询或增改删时会对对应行进行锁定,这时如果事务会影响其他sql。
使用show processlist查看会出现State字段为statistics。这时可以使用select * from sys.innodb_lock_waits;进行查看。
图12和图13拼接起来看,这里的信息非常全面,
blocking_pid指出是119837的线程被卡住了,可以使用
KILL 119837结束此线程。
3、刷脏页
WAL:全称为Write Ahead Log。在数据更新的时候,InnoDB会先更新日志(redo log)并更新内存,再写磁盘。具体来说就是一条更新InnoDB会先写入到redo log中,然后更新内存,那么这条更新就算是完成了,至于什么时候会更新到磁盘中,InnoDB会在适当的时候进行更新。
脏页:内存中的数据页跟磁盘中的数据页不一致。
干净页:内存中的数据刷入了磁盘后,跟磁盘的数据一致。
InnoDB什么时候会进行刷脏页呢?一般是出现下面四种情况的时候
1、redo log日志被写满了,必须先把数据刷一部分到磁盘中。
2、内存不够用时,会淘汰一部分数据页,当淘汰的刚好是脏页时,必须刷回磁盘。
3、mysql认为系统比较空闲的时候。
4、mysql正常关闭的时候。
4、undo log
oracle默认事务隔离级别为读提交,mysql默认事务隔离级别为可重复读。可重复读是指一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一样的。
数据库中每一行的数据都是有多个版本的,每个版本都有自己的row trx_id。undo log(回滚日志)会记录每个更新的过程。在需要查询低版本的数据时,会根据当前版本的数据与undo log进行计算得出。
根据可重复读的定义,如果A事务启动时表id=1的字段num=1,此时A事务先执行别的逻辑。期间启动B事务,进行update t set num=num+1 where id=1,加到100000。此时数据库中id=1的num为100000,这时A事务查询到的结果应该是num=1才正确。mysql就会执行上面回滚版本的过程了,查询到A事务启动时行对应的版本号数据,这个过程会耗费一定的时间,所以此时一个简单的查询select num from t where id=1都会比平时花费时间大很多。
注:
redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。