TCGA学习01:数据下载与整理 -
TCGA学习02:差异分析 -
TCGA学习03:生存分析 -
TCGA学习04:建模预测-cox回归 -
TCGA学习04:建模预测-lasso回归 -
TCGA学习04:建模预测-随机森林&向量机 -
法2:lasso回归
- lasso回归在建立广义线型模型的时候,可以包含一维连续因变量、多维连续因变量、非负次数因变量、二元离散因变量、多元离散因变,除此之外,无论因变量是连续的还是离散的,lasso都能处理,总的来说,lasso对于数据的要求是极其低的,所以应用程度较广。
- lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。
- 这里我们以基因表达矩阵的count值为变量,来做预测生死event的模型,看看会采用多少变量。
1、挑选合适模型
load("tosur.RData")
exprSet=exp_tumor #套用老师的代码
identical(substring(colnames(exprSet),1,12),substring(rownames(meta),1,12))
#保证相同
x=t(log2(exprSet+1))
#行名为ID,列名为基因名
y=meta$event
library(glmnet)
model_lasso <- glmnet(x, y,nlambda=10, alpha=1)
print(model_lasso)
1、 nlambda参数表示做个nlambda个模型,当然多一点比较好,从而准确挑出最合适的模型,默认值为100;alpha=1为lasso回归标准参数。
2、如下图返回的三列值,即为所建的10个模型的情况
- Df列为自由度,即模型所使用的基因数;
- %Dev列为评价模型的好坏程度,越接近1说明模型的表现越好;
- Lambda列为建模的λ值
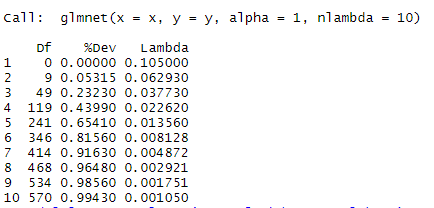
一般选取%Dev值高,同时Df自由度较小的值,可如下作图选取合适的模型
cv_fit <- cv.glmnet(x=x, y=y, nlambda = 1000,alpha = 1)
#这里选取了1000个,精确些
plot(cv_fit)

如上图两条虚线分别指示了两个特殊的λ值,一个是lambda.min,一个是lambda.1se,这两个值之间的lambda都认为是合适的。lambda.1se构建的模型最简单,即使用的基因数量少,而lambda.min则准确率更高一点,使用的基因数量更多一点。
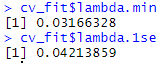 lambda.1se与lambda.min参数
lambda.1se与lambda.min参数
2、确定合适模型
- 这里我们两个参数的模型都看下
model_lasso_min <- glmnet(x=x, y=y, alpha = 1, lambda=cv_fit$lambda.min)
model_lasso_1se <- glmnet(x=x, y=y, alpha = 1, lambda=cv_fit$lambda.1se)
- 看看模型中用了哪些基因
choose_gene_min=rownames(model_lasso_min$beta)[as.numeric(model_lasso_min$beta)!=0]
choose_gene_1se=rownames(model_lasso_1se$beta)[as.numeric(model_lasso_1se$beta)!=0]
length(choose_gene_min) #70个
length(choose_gene_1se) #40个
3、看看模型预测效果如何
lasso.prob <- predict(cv_fit, newx=x , s=c(cv_fit$lambda.min,cv_fit$lambda.1se) )
#如上得到根据模型预测每个样本的生存概率的单列矩阵
re=cbind(y ,lasso.prob)
#合并样本预测值与真实值
head(re)

结果可视化-1、箱线图
re=as.data.frame(re)
colnames(re)=c('event','prob_min','prob_1se')
re$event=as.factor(re$event)
library(ggpubr)
p1 = ggboxplot(re, x = "event", y = "prob_min",
color = "event", palette = "jco",
add = "jitter")+ stat_compare_means()
p1
-
如下图,横轴为实际event值,y轴为模型预测值,还是较能能看出模型的区分度
 p1
p1
结果可视化-2、ROC曲线
ROC曲线评价模型很重要的一个概念
- ROC的全称是“受试者工作特征”(Receiver Operating Characteristic)曲线;
- ROC能衡量某种诊断方法对疾病的识别能力,是确定诊断试验标准(即区分正常和异常的界值)的重要手段。
-
以此次数据为基础,如下图观测值为实际的生死(0/1;negative/positive)情况;预测值为预测值情况。其中重点关注一下两个概念
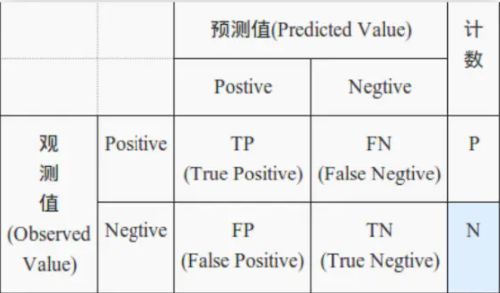 混淆矩阵
混淆矩阵
(1)真正类率(True positive rate, TPR),即真阳性率:在所有实际为阳性的样本中,被正确地判断为阳性之比率,公式为TPR=TP/P。一般希望该值越大越好。
(2)伪正类率(False positive rate, FPR),即假阳性率:在所有实际为阴性的样本
中,被错误地判断为阳性之比率,公式为FPR=FP/P。一般希望该值越小越好。 - ROC 曲线其实就是以FPR为横轴,TPR为纵轴绘制的曲线。
但是,我们还要注意一个问题
- 在0/1二分类变量中,模型的预测值为概率,比如0.15、0.63之类的值。因此就要确定分类阈值(threshold),比如大于0.6的,归为事件1;否则归为事件0。此时就有一个确定的坐标(FPR,TPR)
- 如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。就确定了另外一坐标点。
- ROC曲线正是通过不断移动分类器/模型的预测值“阈值”来生成曲线上的一组关键点的。最后通过这条ROC曲线可以用于评价一个分类器/模型。
如下利用R包绘制
library(ROCR)
pred_min <- prediction(re[,2], re[,1])
auc_min = performance(pred_min,"auc")@y.values[[1]]
#求得AUC值
perf_min <- performance(pred_min,"tpr","fpr")
plot(perf_min,colorize=FALSE, col="blue")
#绘图
lines(c(0,1),c(0,1),col = "gray", lty = 4 )
# y=x
text(0.8,0.2, labels = paste0("AUC = ",round(auc_min,3)))
# 加AUC值
如上图,可以想到,最两边的两点(0,0)、(1,1)的阈值分别为1.0,与0.0两个极限值。
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,是ROC用来评价模型好坏的重要参数。
-
由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
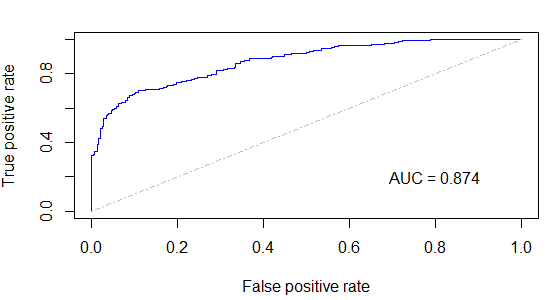 ROC,根据AUC值看还不错
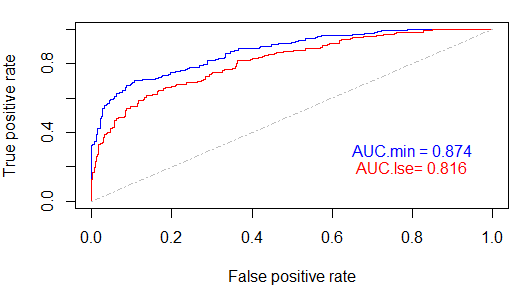
ROC,根据AUC值看还不错 比较两个模型的AUC值
model_lasso_min <- glmnet(x=x, y=y, alpha = 1, lambda=cv_fit$lambda.min)
model_lasso_1se <- glmnet(x=x, y=y, alpha = 1, lambda=cv_fit$lambda.1se)
lasso.prob <- predict(cv_fit, newx=x , s=c(cv_fit$lambda.min,cv_fit$lambda.1se) )
re=cbind(y ,lasso.prob)
re=as.data.frame(re)
colnames(re)=c('event','prob_min','prob_1se')
re$event=as.factor(re$event)
pred_min <- prediction(re[,2], re[,1])
perf_min <- performance(pred_min,"tpr","fpr")
auc_min = performance(pred_min,"auc")@y.values[[1]]
pred_1se <- prediction(re[,3], re[,1])
perf_1se <- performance(pred_1se,"tpr","fpr")
auc_1se = performance(pred_1se,"auc")@y.values[[1]]
plot(perf_min,colorize=FALSE, col="blue")
plot(perf_1se,colorize=FALSE, col="red",add = T)
lines(c(0,1),c(0,1),col = "gray", lty = 4 )
text(0.8,0.3, labels = paste0("AUC.min = ",round(auc_min,3)),col = "blue")
text(0.8,0.2, labels = paste0("AUC.lse= ",round(auc_1se,3)),col = "red")
4、训练集与验证集
一般建模分析,将数据分为两部分,一部分为训练集;一部分为验证集。根据前者建模,再根据模型预测验证集,看看效果如何,比较客观。过程基本同上,就是一开分数据要注意,一般7-3分,或者5-5分
load("tosur.RData")
exprSet=exp_tumor
library(caret)
set.seed(12345679)
sam<- createDataPartition(meta$event, p = .7,list = FALSE)
head(sam)
train <- exprSet[,sam]
test <- exprSet[,-sam]
train_meta <- meta[sam,]
test_meta <- meta[-sam,]
x = t(log2(train+1))
y = train_meta$event
cv_fit <- cv.glmnet(x=x, y=y, nlambda = 1000,alpha = 1)
plot(cv_fit)
model_lasso_min <- glmnet(x=x, y=y, alpha = 1, lambda=cv_fit$lambda.min)
model_lasso_1se <- glmnet(x=x, y=y, alpha = 1, lambda=cv_fit$lambda.1se)
lasso.prob <- predict(cv_fit, newx=t(log2(test+1)), s=c(cv_fit$lambda.min,cv_fit$lambda.1se) )
# 注意这里newx参数之前设置的同建模数据,现在设置的是验证集数据test
re=cbind(test_meta$event ,lasso.prob)
head(re)
re=as.data.frame(re)
colnames(re)=c('event','prob_min','prob_1se')
re$event=as.factor(re$event)
library(ggpubr)
p1 = ggboxplot(re, x = "event", y = "prob_min",
color = "event", palette = "jco",
add = "jitter")+ stat_compare_means()
p2 = ggboxplot(re, x = "event", y = "prob_1se",
color = "event", palette = "jco",
add = "jitter")+ stat_compare_means()
library(patchwork)
p1+p2
library(ROCR)
#min
pred_min <- prediction(re[,2], re[,1])
auc_min = performance(pred_min,"auc")@y.values[[1]]
perf_min <- performance(pred_min,"tpr","fpr")
#1se
pred_1se <- prediction(re[,3], re[,1])
auc_1se = performance(pred_1se,"auc")@y.values[[1]]
perf_1se <- performance(pred_1se,"tpr","fpr")
tpr_min = performance(pred_min,"tpr")@y.values[[1]]
tpr_1se = performance(pred_1se,"tpr")@y.values[[1]]
dat = data.frame(tpr_min = [email protected][[1]],
fpr_min = [email protected][[1]],
tpr_1se = [email protected][[1]],
fpr_1se = [email protected][[1]])
ggplot() +
geom_line(data = dat,aes(x = fpr_min, y = tpr_min),color = "blue") +
geom_line(data = dat,aes(x = fpr_1se, y = tpr_1se),color = "red")+
geom_line(aes(x=c(0,1),y=c(0,1)),color = "grey")+
theme_bw()+
annotate("text",x = .75, y = .25,
label = paste("AUC of min = ",round(auc_min,2)),color = "blue")+
annotate("text",x = .75, y = .15,label = paste("AUC of 1se = ",round(auc_1se,2)),color = "red")+
scale_x_continuous(name = "fpr")+
scale_y_continuous(name = "tpr")
-
如下图,果然模型质量原形毕露.....,看来分为训练组与模型组很客观的。
 箱线图
箱线图
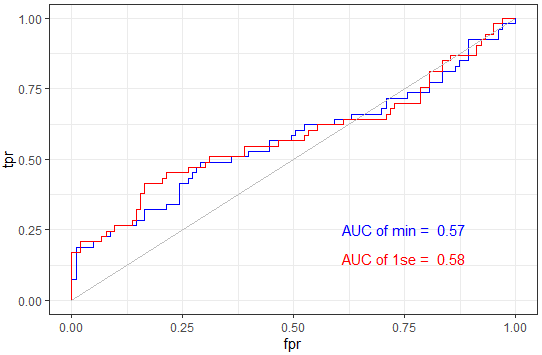 ROC图与AUC值
ROC图与AUC值 老师的一篇教程中还有一种考虑生存时间的ROC曲线-timeROC绘图教程,这里就先不展开了,之后再看下。
参考资料
1、TCGA数据分析流程梳理总结(含目录) -
2、ROC曲线-阈值评价标准_人工智能_Rachel Zhang的专栏-CSDN博客
3、ROC曲线和PR曲线 -
4、机器学习基础(1)- ROC曲线理解 -
5、【r<-ROC|包】分析与可视化ROC——plotROC、pROC -