本章内容
数学和统计函数
字符处理函数
循环和条件执行
自编函数
数据整合与重塑
在第4章,我们审视了R中基本的数据集处理方法,本章我们将关注一些高级话题。本章分为三个基本部分。在第一部分中,我们将快速浏览R中的多种数学、统计和字符处理函数。为了让这一部分的内容相互关联,我们先引入一个能够使用这些函数解决的数据处理问题。在讲解过这些函数以后,再为这个数据处理问题提供一个可能的解决方案。
接下来,我们将讲解如何自己编写函数来完成数据处理和分析任务。首先,我们将探索控制程序流程的多种方式,包括循环和条件执行语句。然后,我们将研究用户自编函数的结构,以及在编写完成如何调用它们。
最后,我们将了解数据的整合和概述方法,以及数据集的重塑和重构方法。在整合数据时,你可以使用任何内建或自编函数来获取数据的概述,所以你在本章前两部分中学习的内容将会派上用场。
一个数据处理难题
要讨论数值和字符处理函数,让我们首先考虑一个数据处理问题。一组学生参加了数学、科学和英语考试。为了给所有学生确定一个单一的成绩衡量指标,需要将这些科目的成绩组合起来。
另外,你还想将前20%的学生评定为A,接下来20%的学生评定为B,依次类推。最后,你希望按字母顺序对学生排序。数据如表5-1所示。
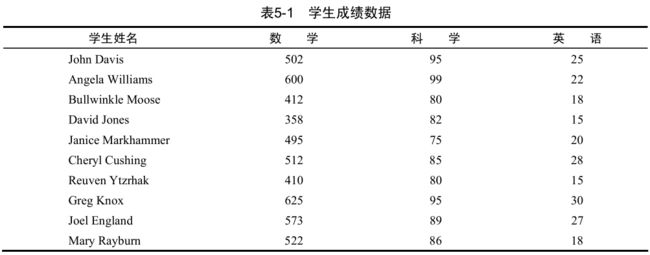
观察此数据集,马上可以发现一些明显的障碍。首先,三科考试的成绩是无法比较的。由于它们的均值和标准差相去甚远,所以对它们求平均值是没有意义的。你在组合这些考试成绩之前,必须将其变换为可比较的单元。其次,为了评定等级,你需要一种方法来确定某个学生在前述得分上百分比排名。再次,表示姓名的字段只有一个,这让排序任务复杂化了。为了正确地将其排序,需要将姓和名拆开。
以上每一个任务都可以巧妙地利用R中的数值和字符处理函数完成。在讲解完下一节中的各种函数之后,我们将考虑一套可行的解决方案,以解决这项数据处理难题。
数值和字符处理函数
本节我们将综述R中作为数据处理基石的函数,它们可分为数值(数学、统计、概率)函数和字符处理函数。在阐述过每一类函数以后,我将为你展示如何将函数应用到矩阵和数据框的列(变量)和行(观测)上(参见5.2.6节)。
数学函数
表5-2列出了常用的数学函数和简短的用例。
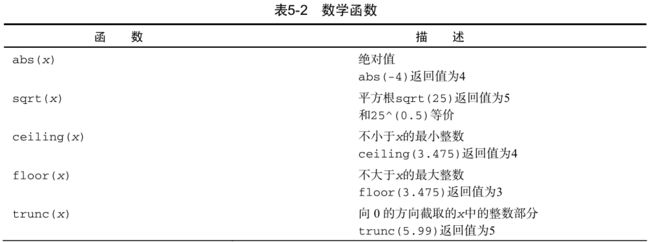

对数据做变换是这些函数的一个主要用途。例如,你经常会在进一步分析之前将收入这种存在明显偏倚的变量取对数。数学函数也被用作公式中的一部分,用于绘图函数(例如 x 对 sin(x) )和在输出结果之前对数值做格式化。
表5-2中的示例将数学函数应用到了标量(单独的数值)上。当这些函数被应用于数值向量、矩阵或数据框时,它们会作用于每一个独立的值。例如, sqrt(c(4, 16, 25)) 的返回值为 c(2,4, 5) 。
统计函数
常用的统计函数如表5-3所示,其中许多函数都拥有可以影响输出结果的可选参数。举例来说:y <- mean(x)提供了对象 x 中元素的算术平均数,而:z <- mean(x, trim =0.05, na.rm=TRUE则提供了截尾平均数,即丢弃了最大5%和最小5%的数据和所有缺失值后的算术平均数。请使用help() 了解以上每个函数和其参数的用法。

要了解这些函数的实战应用,请参考代码清单5-1。这段代码演示了计算某个数值向量的均值和标准差的两种方式。
x <- c(1, 2, 3, 4, 5, 6, 7, 8)
mean(x)
sd(x)
n <- length(x)
meanx <- sum(x)/n
css <- sum((x - meanx)^2)
sdx <- sqrt(css / (n-1))
meanx
sdx
第二种方式中修正平方和( css )的计算过程是很有启发性的:
(1) x 等于 c(1, 2, 3, 4, 5, 6, 7, 8) , x 的平均值等于4.5( length(x) 返回了 x 中元素的数量);
(2) (x – meanx) 从 x 的每个元素中减去了4.5,结果为 c(-3.5, -2.5, -1.5, -0.5, 0.5,1.5, 2.5, 3.5) ;
(3) (x – meanx)^2 将 (x - meanx) 的每个元素求平方,结果为 c(12.25, 6.25, 2.25,0.25, 0.25, 2.25, 6.25, 12.25) ;
(4) sum((x - meanx)^2) 对 (x - meanx)^2) 的所有元素求和,结果为42。
R中公式的写法和类似MATLAB的矩阵运算语言有着许多共同之处。(我们将在附录E中具体关注解决矩阵代数问题的方法。)
数据的标准化
默认情况下,函数 scale() 对矩阵或数据框的指定列进行均值为0、标准差为1的标准化:
newdata <- scale(mydata)
要对每一列进行任意均值和标准差的标准化,可以使用如下的代码:
newdata <- scale(mydata)*SD + M
其中的 M 是想要的均值, SD 为想要的标准差。在非数值型的列上使用 scale() 函数将会报错。
要对指定列而不是整个矩阵或数据框进行标准化,你可以使用这样的代码:
newdata <- transform(mydata, myvar = scale(myvar)*10+50)
此句将变量 myvar 标准化为均值50、标准差为10的变量。你将在5.3节数据处理问题的解决方法中用到 scale() 函数。
概率函数
你可能在疑惑为何概率函数未和统计函数列在一起。(你真的对此有些困惑,对吧?)虽然根据定义,概率函数也属于统计类,但是它们非常独特,应独立设一节进行讲解。概率函数通常用来生成特征已知的模拟数据,以及在用户编写的统计函数中计算概率值。
在R中,概率函数形如 :
[dpqr]distribution_abbreviation()
其中第一个字母表示其所指分布的某一方面:
d = 密度函数(density)
p = 分布函数(distribution function)
q = 分位数函数(quantile function)
r = 生成随机数(随机偏差)
常用的概率函数列于表5-4中。
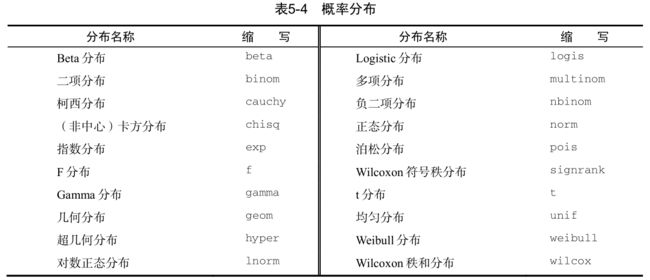
我们不妨先看看正态分布的有关函数,以了解这些函数的使用方法。如果不指定一个均值和一个标准差,则函数将假定其为标准正态分布(均值为0,标准差为1)。密度函数( dnorm )、分布函数( pnorm )、分位数函数( qnorm )和随机数生成函数( rnorm )的使用示例见表5-5。
x <- pretty(c(-3, 3), 30)
y <- dnorm(x)
plot(x, y, type = "l", xlab = "NormalDeviate", ylab = "Density", yaxs = "i")
pnorm(1.96)
qnorm(0.9, mean = 500, sd = 100)
rnorm(50, mean = 50, sd = 10)
[图片上传失败...(image-69f4c8-1577187687248)]
如果读者对 plot() 函数的选项不熟悉,请不要担心。这些选项在第11章中有详述。 pretty()在本章稍后的表5-7中进行了解释。
设定随机数种子
在每次生成伪随机数的时候,函数都会使用一个不同的种子,因此也会产生不同的结果。你可以通过函数 set.seed() 显式指定这个种子,让结果可以重现(reproducible)。代码清单5-2给出了一个示例。这里的函数 runif() 用来生成0到1区间上服从均匀分布的伪随机数。
> runif(5)
> [1] 0.03119642 0.51657814 0.86438179 0.74237510 0.69981268
> runif(5)
> [1] 0.07797611 0.90215220 0.46832530 0.28086833 0.86071339
通过手动设定种子,就可以重现你的结果了。这种能力有助于我们创建会在未来取用的,以及可与他人分享的示例。
生成多元正态数据
在模拟研究和蒙特卡洛方法中,你经常需要获取来自给定均值向量和协方差阵的多元正态分布的数据。 MASS 包中的 mvrnorm() 函数可以让这个问题变得很容易。其调用格式为:
mvrnorm(n, mean, sigma)
其中 n 是你想要的样本大小, mean 为均值向量,而 sigma 是方差协方差矩阵(或相关矩阵)。代
码清单5-3从一个参数如下所示的三元正态分布中抽取500个观测。

...
字符处理函数
数学和统计函数是用来处理数值型数据的,而字符处理函数可以从文本型数据中抽取信息,或者为打印输出和生成报告重设文本的格式。举例来说,你可能希望将某人的姓和名连接在一起,并保证姓和名的首字母大写,抑或想统计可自由回答的调查反馈信息中含有秽语的实例
(instance)数量。一些最有用的字符处理函数见表5-6。

请注意,函数 grep() 、 sub() 和 strsplit() 能够搜索某个文本字符串( fixed=TRUE )或某个正则表达式( fixed=FALSE ,默认值为 FALSE )。正则表达式为文本模式的匹配提供了一套清晰而简练的语法。例如,正则表达式:
^[hc]?at
可匹配任意以0个或1个 h 或 c 开头、后接 at 的字符串。因此,此表达式可以匹配hat、cat和at,但不会匹配bat。要了解更多,请参考维基百科的regular expression(正则表达式)条目。
其他实用函数
表5-7中的函数对于数据管理和处理同样非常实用,只是它们无法清楚地划入其他分类中。
[图片上传失败...(image-caf3a5-1577187687248)]
表中的最后一个例子演示了在输出时转义字符的使用方法。 \n 表示新行, \t 为制表符, \'为单引号, \b 为退格,等等。(键入 ?Quotes 以了解更多。)例如,代码:
name <- "Bob"
cat( "Hello", name, "\b.\n", "Isn\'t R", "\t", "GREAT?\n")
可生成:
Hello Bob.
Isn't R GREAT?
请注意第二行缩进了一个空格。当 cat 输出连接后的对象时,它会将每一个对象都用空格分开。这就是在句号之前使用退格转义字符( \b )的原因。不然,生成的结果将是“Hello Bob .”。
在数值、字符串和向量上使用我们最近学习的函数是直观而明确的,但是如何将它们应用到矩阵和数据框上呢?这就是下一节的主题。
将函数应用于矩阵和数据框
R函数的诸多有趣特性之一,就是它们可以应用到一系列的数据对象上,包括标量、向量、
矩阵、数组和数据框。代码清单5-4提供了一个示例。
> a <- 5
> sqrt(a)
[1] 2.236068
> b <- c(1.243, 5.654, 2.99)
> round(b)
[1] 1 6 3
> c <- matrix(runif(12), nrow=3)
> c
[,1] [,2] [,3] [,4]
[1,] 0.4205 0.355 0.699 0.323
[2,] 0.0270 0.601 0.181 0.926
[3,] 0.6682 0.319 0.599 0.215
> log(c)
[,1] [,2] [,3] [,4]
[1,] -0.866 -1.036 -0.358 -1.130
[2,] -3.614 -0.508 -1.711 -0.077
[3,] -0.403 -1.144 -0.513 -1.538
> mean(c)
[1] 0.444
请注意,在代码清单5-4中对矩阵 c 求均值的结果为一个标量(0.444)。函数 mean() 求得的是矩阵中全部12个元素的均值。但如果希望求的是各行的均值或各列的均值呢?
R中提供了一个 apply() 函数,可将一个任意函数“应用”到矩阵、数组、数据框的任何维度上。 apply() 函数的使用格式为:
apply(x, MARGIN, FUN, ...)
其中, x 为数据对象, MARGIN 是维度的下标, FUN 是由你指定的函数,而 ... 则包括了任何想传递给 FUN 的参数。在矩阵或数据框中, MARGIN=1 表示行, MARGIN=2 表示列。请看以下例子。
> mydata <- matrix(rnorm(30), nrow=6)
> mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 0.71298 1.368 -0.8320 -1.234 -0.790
[2,] -0.15096 -1.149 -1.0001 -0.725 0.506
[3,] -1.77770 0.519 -0.6675 0.721 -1.350
[4,] -0.00132 -0.308 0.9117 -1.391 1.558
[5,] -0.00543 0.378 -0.0906 -1.485 -0.350
[6,] -0.52178 -0.539 -1.7347 2.050 1.569
> apply(mydata, 1, mean)
[1] -0.155 -0.504 -0.511 0.154 -0.310 0.165
> apply(mydata, 2, mean)
[1] -0.2907 0.0449 -0.5688 -0.3442 0.1906
> apply(mydata, 2, mean, trim=0.2)
[1] -0.1699 0.0127 -0.6475 -0.6575 0.2312
首先生成了一个包含正态随机数的6×5矩阵➊。然后你计算了6行的均值➋,以及5列的均值➌。最后,你计算了每列的截尾均值(在本例中,截尾均值基于中间60%的数据,最高和最低20%的值均被忽略)➍。FUN 可为任意R函数,这也包括你自行编写的函数(参见5.4节),所以 apply() 是一种很强大的机制。 apply() 可把函数应用到数组的某个维度上,而 lapply() 和 sapply() 则可将函数应用到列表(list)上。你将在下一节中看到 sapply() (它是 lapply() 的更好用的版本)的一个示例。
你已经拥有了解决5.1节中数据处理问题所需的所有工具,现在,让我们小试身手。
数据处理难题的一套解决方案
看起来有点繁琐,但还是一步步地仔细看吧
5.1节中提出的问题是:将学生的各科考试成绩组合为单一的成绩衡量指标,基于相对名次(前20%、下20%、等等)给出从A到F的评分,根据学生姓氏和名字的首字母对花名册进行排序。
代码清单5-6给出了一种解决方案。
# 原始的学生花名册已经给出了,options(digits=2)
# 限定了输出小数点后数字的位数,并且让输出更容易阅读
options(digits = 2)
# 创建数据
Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose", "David Jones",
"Janice Markhammer", "Cheryl Cushing", "Reuven Ytzrhak", "Greg Knox", "Joel England",
"Mary Rayburn")
Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
English <- c(25, 22, 18, 15, 20, 28, 15, 30, 37, 18)
roster <- data.frame(Student, Math, Science, English, stringsAsFactors = FALSE)
> roster
Student Math Science English
1 John Davis 502 95 25
2 Angela Williams 600 99 22
3 Bullwinkle Moose 412 80 18
4 David Jones 358 82 15
5 Janice Markhammer 495 75 20
6 Cheryl Cushing 512 85 28
7 Reuven Ytzrhak 410 80 15
8 Greg Knox 625 95 30
9 Joel England 573 89 37
10 Mary Rayburn 522 86 18
# scale()标准化数据
z <- scale(roster[ , 2:4])
> z
Math Science English
[1,] 0.013 1.078 0.31
[2,] 1.143 1.591 -0.11
[3,] -1.026 -0.847 -0.67
[4,] -1.649 -0.590 -1.09
[5,] -0.068 -1.489 -0.39
[6,] 0.128 -0.205 0.73
[7,] -1.049 -0.847 -1.09
[8,] 1.432 1.078 1.01
[9,] 0.832 0.308 1.98
[10,] 0.243 -0.077 -0.67
# mean()来计算各行的均值以获得综合得分
score <- apply(z, 1, mean)
> score
[1] 0.47 0.87 -0.85 -1.11 -0.65 0.22 -0.99 1.17 1.04 -0.17
# cbind()将均值列添加到花名册中
roster <- cbind(roster, score)
> roster
Student Math Science English score
1 John Davis 502 95 25 0.47
2 Angela Williams 600 99 22 0.87
3 Bullwinkle Moose 412 80 18 -0.85
4 David Jones 358 82 15 -1.11
5 Janice Markhammer 495 75 20 -0.65
6 Cheryl Cushing 512 85 28 0.22
7 Reuven Ytzrhak 410 80 15 -0.99
8 Greg Knox 625 95 30 1.17
9 Joel England 573 89 37 1.04
10 Mary Rayburn 522 86 18 -0.17
# quantile()求学生综合得分的百分位数
y <- quantile(score, c(0.8, 0.6, 0.4, 0.2))
> y
80% 60% 40% 20%
0.91 0.32 -0.36 -0.88
# 使用逻辑运算符将学生的百分位数排名重编码为一个新的类别型成绩变量。
# 下面在数据框roster中创建了变量grade 。
roster$grade[score >= y[1]] <- "A"
roster$grade[score < y[1] & score >= y[2]] <- "B"
roster$grade[score < y[2] & score >= y[3]] <- "C"
roster$grade[score < y[3] & score >= y[4]] <- "D"
roster$grade[score < y[4]] <- "F"
> roster
Student Math Science English score grade
1 John Davis 502 95 25 0.47 B
2 Angela Williams 600 99 22 0.87 B
3 Bullwinkle Moose 412 80 18 -0.85 D
4 David Jones 358 82 15 -1.11 F
5 Janice Markhammer 495 75 20 -0.65 D
6 Cheryl Cushing 512 85 28 0.22 C
7 Reuven Ytzrhak 410 80 15 -0.99 F
8 Greg Knox 625 95 30 1.17 A
9 Joel England 573 89 37 1.04 A
10 Mary Rayburn 522 86 18 -0.17 C
#strsplit()函数以空格为分隔分割学生姓名
name <- strsplit((roster$Student), " ")
# sapply()函数分别取姓名的第一位和第二位,
# "["是一个可以提取某个对象的一部分的函数
# 在这里它是用来提取列表name各成分中的第一个或第二个元素的。
lastname <- sapply(name, "[", 2)
firstname <- sapply(name, "[", 1)
# 将姓和名两列加入列头,并舍弃原来第一列的全名列
roster <- cbind(firstname, lastname, roster[, -1])
> roster
firstname lastname Math Science English score grade
1 John Davis 502 95 25 0.47 B
2 Angela Williams 600 99 22 0.87 B
3 Bullwinkle Moose 412 80 18 -0.85 D
4 David Jones 358 82 15 -1.11 F
5 Janice Markhammer 495 75 20 -0.65 D
6 Cheryl Cushing 512 85 28 0.22 C
7 Reuven Ytzrhak 410 80 15 -0.99 F
8 Greg Knox 625 95 30 1.17 A
9 Joel England 573 89 37 1.04 A
10 Mary Rayburn 522 86 18 -0.17 C
# order() 依姓氏和名字对数据集进行排序
roster <- roster[order(lastname, firstname),]
> roster
firstname lastname Math Science English score grade
6 Cheryl Cushing 512 85 28 0.22 C
1 John Davis 502 95 25 0.47 B
9 Joel England 573 89 37 1.04 A
4 David Jones 358 82 15 -1.11 F
8 Greg Knox 625 95 30 1.17 A
5 Janice Markhammer 495 75 20 -0.65 D
3 Bullwinkle Moose 412 80 18 -0.85 D
10 Mary Rayburn 522 86 18 -0.17 C
2 Angela Williams 600 99 22 0.87 B
7 Reuven Ytzrhak 410 80 15 -0.99 F
控制流
在正常情况下,R程序中的语句是从上至下顺序执行的。但有时你可能希望重复执行某些语句,仅在满足特定条件的情况下执行另外的语句。这就是控制流结构发挥作用的地方了。R拥有一般现代编程语言中都有的标准控制结构。首先你将看到用于条件执行的结构,接下来是用于循环执行的结构。
为了理解贯穿本节的语法示例,请牢记以下概念:
- 语句( statement )是一条单独的R语句或一组复合语句(包含在花括号 { } 中的一组R语句,使用分号分隔);
- 条件( cond )是一条最终被解析为真( TRUE )或假( FALSE )的表达式;
- 表达式( expr )是一条数值或字符串的求值语句;
- 序列( seq )是一个数值或字符串序列。
- 在讨论过控制流的构造后,我们将学习如何编写函数。
重复和循环
循环结构重复地执行一个或一系列语句,直到某个条件不为真为止。循环结构包括 for 和
while 结构。
for 结构
for 循环重复地执行一个语句,直到某个变量的值不再包含在序列 seq 中为止。语法为:
for (var in seq) statement
在下例中:
for (i in 1:10) print("Hello")
单词Hello被输出了10次。
while 结构
while 循环重复地执行一个语句,直到条件不为真为止。语法为:
while (cond) statement
作为第二个例子,代码:
i <- 10
while (i > 0) {print("Hello"); i <- i - 1}
又将单词Hello输出了10次。请确保括号内 while 的条件语句能够改变,即让它在某个时刻不再为真——否则循环将永不停止!在上例中,语句:i <- i – 1在每步循环中为对象 i 减去1,这样在十次循环过后,它就不再大于0了。反之,如果在每步循环都加1的话,R将不停地打招呼。这也是 while 循环可能较其他循环结构更危险的原因。
在处理大数据集中的行和列时,R中的循环可能比较低效费时。只要可能,最好联用R中的内建数值/字符处理函数和 apply 族函数。
条件执行
在条件执行结构中,一条或一组语句仅在满足一个指定条件时执行。条件执行结构包括if-else 、 ifelse 和 switch 。
if-else 结构
控制结构 if-else 在某个给定条件为真时执行语句。也可以同时在条件为假时执行另外的语
句。语法为:
if (cond) statement
if (cond) statement1 else statement2
示例如下:
if (is.character(grade)) grade <- as.factor(grade)
if (!is.factor(grade)) grade <- as.factor(grade) else print("Grade already
is a factor")
在第一个实例中,如果 grade 是一个字符向量,它就会被转换为一个因子。在第二个实例中,两个语句择其一执行。如果 grade 不是一个因子(注意符号 ! ),它就会被转换为一个因子。如果它是一个因子,就会输出一段信息。
ifelse 结构
ifelse 结构是 if-else 结构比较紧凑的向量化版本,其语法为:
ifelse(cond, statement1, statement2)
若 cond 为 TRUE ,则执行第一个语句;若 cond 为 FALSE ,则执行第二个语句。示例如下:
ifelse(score > 0.5, print("Passed"), print("Failed"))
outcome <- ifelse (score > 0.5, "Passed", "Failed")
在程序的行为是二元时,或者希望结构的输入和输出均为向量时,请使用 ifelse 。
switch 结构
switch 根据一个表达式的值选择语句执行。语法为:
switch(expr, ...)
其中的 ... 表示与 expr 的各种可能输出值绑定的语句。通过观察代码清单5-7中的代码,可以轻松地理解 switch 的工作原理。
feelings <- c("sad", "afraid")
for(i in feelings)
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = "Cheer up",
angry = "Calm down now"
)
)
[1] "Cheer up"
[1] "There is nothing to fear"
虽然这个例子比较幼稚,但它展示了 switch 的主要功能。你将在下一节学习如何使用switch 编写自己的函数。
用户自编函数
R的最大优点之一就是用户可以自行添加函数。事实上,R中的许多函数都是由已有函数构成的。一个函数的结构看起来大致如此:
myfunction <- function(arg1, arg2, ... ){
statements
return(object)
}
函数中的对象只在函数内部使用。返回对象的数据类型是任意的,从标量到列表皆可。让我们看一个示例。
mydate <- function(type){
switch(type,
long = format(Sys.time(), "%A %B %d %Y"),
short = format(Sys.time(), "%m-%d-%y"),
cat(type, "is not a recognized type\n")
)
}
> mydate("long")
[1] "星期六 十二月 07 2019"
> mydate("short")
[1] "12-07-19"
> mydate("aoe")
aoe is not a recognized type
请注意,函数 cat() 仅会在输入的日期格式类型不匹配 "long" 或 "short" 时执行。使用一个表达式来捕获用户的错误输入的参数值通常来说是一个好主意。
有若干函数可以用来为函数添加错误捕获和纠正功能。你可以使用函数 warning() 来生成一条错误提示信息,用 message() 来生成一条诊断信息,或用 stop() 停止当前表达式的执行并提示错误。20.5节将会更加详细地讨论错误捕捉和调试。
在创建好自己的函数以后,你可能希望在每个会话中都能直接使用它们。附录B描述了如何定制R环境,以使R启动时自动读取用户编写的函数。我们将在第6章和第8章中看到更多的用户自编函数示例。
你可以使用本节中提供的基本技术完成很多工作。第20章的内容更加详细地涵盖了控制流和其他编程主题。第21章涵盖了如何创建包。如果你想要探索编写函数的微妙之处,或编写可以分发给他人使用的专业级代码,个人推荐阅读这两章,然后阅读两本优秀的书籍,你可在本书末尾的参考文献部分找到:Venables & Ripley(2000)以及Chambers(2008)。这两本书共同提供了大量细节和众多示例。
函数的编写就讲到这里,我们将以对数据整合和重塑的讨论来结束本章。
整合与重构
R中提供了许多用来整合(aggregate)和重塑(reshape)数据的强大方法。在整合数据时,往往将多组观测替换为根据这些观测计算的描述性统计量。在重塑数据时,则会通过修改数据的结构(行和列)来决定数据的组织方式。本节描述了用来完成这些任务的多种方式。
在接下来的两个小节中,我们将使用已包含在R基本安装中的数据框 mtcars 。这个数据集是从Motor Trend杂志(1974)提取的,它描述了34种车型的设计和性能特点(汽缸数、排量、马力、每加仑汽油行驶的英里数,等等)。要了解此数据集的更多信息,请参阅 help(mtcars) 。
转置
转置(反转行和列)也许是重塑数据集的众多方法中最简单的一个了。使用函数 t() 即可对一个矩阵或数据框进行转置。对于后者,行名将成为变量(列)名。代码清单5-9展示了一个例子。
使用函数 t() 即可对一个矩阵或数据框进行转置。
整合数据
在R中使用一个或多个by变量和一个预先定义好的函数来折叠(collapse)数据是比较容易的。调用格式为:
aggregate(x, by, FUN)
其中 x 是待折叠的数据对象, by 是一个变量名组成的列表,这些变量将被去掉以形成新的观测,
而 FUN 则是用来计算描述性统计量的标量函数,它将被用来计算新观测中的值。
作为一个示例,我们将根据汽缸数和挡位数整合 mtcars 数据,并返回各个数值型变量的均
值(见代码清单5-10)。
> mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.6 16 0 1 4 4
Mazda RX4 Wag 21 6 160 110 3.9 2.9 17 0 1 4 4
Datsun 710 23 4 108 93 3.8 2.3 19 1 1 4 1
Hornet 4 Drive 21 6 258 110 3.1 3.2 19 1 0 3 1
Hornet Sportabout 19 8 360 175 3.1 3.4 17 0 0 3 2
Valiant 18 6 225 105 2.8 3.5 20 1 0 3 1
Duster 360 14 8 360 245 3.2 3.6 16 0 0 3 4
Merc 240D 24 4 147 62 3.7 3.2 20 1 0 4 2
Merc 230 23 4 141 95 3.9 3.1 23 1 0 4 2
Merc 280 19 6 168 123 3.9 3.4 18 1 0 4 4
Merc 280C 18 6 168 123 3.9 3.4 19 1 0 4 4
Merc 450SE 16 8 276 180 3.1 4.1 17 0 0 3 3
Merc 450SL 17 8 276 180 3.1 3.7 18 0 0 3 3
Merc 450SLC 15 8 276 180 3.1 3.8 18 0 0 3 3
Cadillac Fleetwood 10 8 472 205 2.9 5.2 18 0 0 3 4
Lincoln Continental 10 8 460 215 3.0 5.4 18 0 0 3 4
Chrysler Imperial 15 8 440 230 3.2 5.3 17 0 0 3 4
Fiat 128 32 4 79 66 4.1 2.2 19 1 1 4 1
Honda Civic 30 4 76 52 4.9 1.6 19 1 1 4 2
Toyota Corolla 34 4 71 65 4.2 1.8 20 1 1 4 1
Toyota Corona 22 4 120 97 3.7 2.5 20 1 0 3 1
Dodge Challenger 16 8 318 150 2.8 3.5 17 0 0 3 2
AMC Javelin 15 8 304 150 3.1 3.4 17 0 0 3 2
Camaro Z28 13 8 350 245 3.7 3.8 15 0 0 3 4
Pontiac Firebird 19 8 400 175 3.1 3.8 17 0 0 3 2
Fiat X1-9 27 4 79 66 4.1 1.9 19 1 1 4 1
Porsche 914-2 26 4 120 91 4.4 2.1 17 0 1 5 2
Lotus Europa 30 4 95 113 3.8 1.5 17 1 1 5 2
Ford Pantera L 16 8 351 264 4.2 3.2 14 0 1 5 4
Ferrari Dino 20 6 145 175 3.6 2.8 16 0 1 5 6
Maserati Bora 15 8 301 335 3.5 3.6 15 0 1 5 8
Volvo 142E 21 4 121 109 4.1 2.8 19 1 1 4 2
options(digits = 3)
attach(mtcars)
aggdata <- aggregate(mtcars, by = list(cyl, gear), FUN=mean, na.rm = TRUE)
detach(mtcars)
aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
在结果中, Group.1 表示汽缸数量(4、6或8), Group.2 代表挡位数(3、4或5)。举例来说,拥有4个汽缸和3个挡位车型的每加仑汽油行驶英里数( mpg )均值为21.5。
在使用 aggregate() 函数的时候, by 中的变量必须在一个列表中(即使只有一个变量)。你可 以 在 列 表 中 为 各 组 声 明 自 定 义 的 名 称 , 例 如 by=list(Group.cyl=cyl, Group.gears=gear) 。指定的函数可为任意的内建或自编函数,这就为整合命令赋予了强大的力量。但说到力量,没有什么可以比 reshape2 包更强。
reshape2 包
reshape2 包是一套重构和整合数据集的绝妙的万能工具。由于它的这种万能特性,可能学起来会有一点难度。我们将慢慢地梳理整个过程,并使用一个小型数据集作为示例,这样每一步发生了什么就很清晰了。由于 reshape2 包并未包含在R的标准安装中,在第一次使用它之前需要使用 install.packages("reshape2") 进行安装。
大致说来,你需要首先将数据融合(melt),以使每一行都是唯一的标识符变量组合。然后将数据重铸(cast)为你想要的任何形状。在重铸过程中,你可以使用任何函数对数据进行整合。将使用的数据集如表5-8所示。

用处不大感觉,先不讲了。。。