一、先看结果
1.1创造营2020撑腰榜前三甲
创造营2020撑腰榜前三名分别是 希林娜依·高、陈卓璇 、郑乃馨
>>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']]
排名 姓名 身高 体重 生日 出生地
0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆
1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州
2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国

1.2青春有你2当前官方榜前三甲
青春有你2官方榜(35进20)前三名分别是 刘雨昕、虞书欣、喻言
>>>df2[df2['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']]
排名 姓名 身高 体重 生日 出生地
107 1.0 刘雨昕 168.0 48.0 1997年04月20日 贵阳
117 2.0 虞书欣 169.0 50.0 1995年12月18日 上海
118 3.0 喻言 172.0 50.0 1997年05月26日 北京

1.3Face++男女视角颜值最高
1.3.1女性视角颜值第一名
得分95.23,来自《创造营2020》的黄若元(已经告别舞台)
>>>df.sort_values(by = 'face++女性眼中颜值',ascending = False).head(1)[['face++女性眼中颜值','姓名','来源','身高','体重','生日','出生地']]
face++女性眼中颜值 姓名 来源 身高 体重 生日 出生地
95 95.23 黄若元 创造营2020 NaN NaN 1996-03-01 NaN

1.3.2男性视角颜值第一名
得分93.773,来自《创造营2020》的孙珍妮(目前位列撑腰榜第19)
>>>df.sort_values(by = 'face++男性眼中颜值',ascending = False).head(1)[['face++男性眼中颜值','姓名','来源','身高','体重','生日','出生地']]
face++男性眼中颜值 姓名 来源 身高 体重 生日 出生地
18 93.773 孙珍妮 创造营2020 165.0 NaN 2000-05-05 上海

1.4小姐姐们籍贯分布(pyecharts作图)
创造营2020的小姐姐有籍贯记录的41位中,来自四川的有7位,江西、浙江、湖南和湖北的各3位

青春有你2小姐姐来自最多的省市分别是北京、台湾 各9名,重庆、成都各6名

二、再看下统计分析
以下是整体数据部分截图(Spyder变量查看器)

因为整合的信息较多,共17个字段,我们在做分 数据指标 统分的时候只需要用到部分即可。
在做统计分析时,这里核心就是一个 分组统计 (df.groupby())。
>>>df.info()RangeIndex: 210 entries, 0 to 209 Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 排名 136 non-null float64 1 编号 210 non-null int64 2 姓名 210 non-null object 3 照片 210 non-null object 4 状态 210 non-null object 5 粉丝数 101 non-null object 6 星座 168 non-null object 7 身高 137 non-null float64 8 体重 120 non-null float64 9 出生地 149 non-null object 10 生日 160 non-null object 11 AI预测年龄 210 non-null int64 12 AI颜值评分 210 non-null int64 13 face++AI预测年龄 210 non-null int64 14 face++女性眼中颜值 210 non-null float64 15 face++男性眼中颜值 210 non-null float64 16 来源 210 non-null object dtypes: float64(5), int64(4), object(8) memory usage: 28.0+ KB
2.1小姐姐出生地分布
《创造营2020》小姐姐官方信息数据中,出生地只有41/101个,且多以省为标尺,我们统计结果如下:
>>>pro = df1.groupby('出生地')['编号'].count().to_frame('count').sort_values(by = 'count',ascending = False).reset_index()
>>>pro.head()
出生地 count
0 四川 7
1 江西 3
2 浙江 3
3 湖南 3
4 湖北 3
《青春有你2》小姐姐官方数据比较全,出生地有108/109,且多以市为标尺,我们统计结果如下:
>>>city = df2.groupby('出生地')['编号'].count().to_frame('count').sort_values(by = 'count',ascending = False).reset_index()
>>>city.head()
出生地 count
0 北京 9
1 台湾 9
2 重庆 6
3 成都 6
4 上海 5
2.2小姐姐的出生年份分布
出生年份我们合并数据做统一处理吧,一共有160/210份数据,我们统计结果如下:
>>>year = df.groupby('year')['编号'].count().to_frame('count').sort_values(by = 'count',ascending = False).reset_index()
>>>year.head()
year count
0 1997.0 27
1 1995.0 25
2 1996.0 24
3 1998.0 20
4 1999.0 19
2.3小姐姐星座分布
星座分布我们合并数据做统一处理吧,一共有168/210份数据,我们统计结果如下:
>>>conste = df.groupby('星座')['编号'].count().to_frame('count').sort_values(by = 'count',ascending = False).reset_index()
>>>conste
星座 count
0 狮子座 23
1 天秤座 19
2 摩羯座 19
3 白羊座 16
4 双子座 14
5 射手座 13
6 金牛座 13
7 双鱼座 11
8 天蝎座 11
9 巨蟹座 11
10 水瓶座 10
11 处女座 8
2.4小姐姐身高分布
身高分布我们合并数据做统一处理吧,一共有137/210份数据,我们统计结果如下:
>>>height = df.groupby('身高')['编号'].count().to_frame('count').sort_values(by = 'count',ascending = False).reset_index()
>>>height
身高 count
0 168.0 27
1 170.0 11
2 165.0 11
3 166.0 11
4 163.0 10
5 167.0 9
身高这种属性,咱们还可以做简单的描述统计分析如下:
(可以看到,最高175cm,最低158cm,平均167.12cm,中位数168cm)
>>>df['身高'].describe() count 137.000000 mean 167.124088 std 4.080883 min 158.000000 25% 165.000000 50% 168.000000 75% 170.000000 max 175.000000 Name: 身高, dtype: float64
2.5小姐姐体重分布
体重分布我们合并数据做统一处理吧,一共有120/210份数据,我们统计结果如下:
>>>weight = df.groupby('体重')['编号'].count().to_frame('count').sort_values(by = 'count',ascending = False).reset_index()
>>>weight.head()
体重 count
0 48.0 20
1 46.0 15
2 50.0 13
3 47.0 13
4 49.0 12
身高这种属性,咱们还可以做简单的描述统计分析如下:
(可以看到,最高87kg???,最低40kg,平均48kg,中位数48kg)
>>>df['体重'].describe() count 120.000000 mean 48.012500 std 5.081877 min 40.000000 25% 46.000000 50% 48.000000 75% 50.000000 max 87.000000 Name: 体重, dtype: float64
赶快查一下这个87KG的妹子是谁,看了下照片,感觉是官网数据填错了吧,应该47kg或者87斤?才对吧,算了不改了~
>>>df[df['体重']==87][['编号','姓名','来源']]
编号 姓名 来源
170 540476547 孙美楠 青春有你2

2.6小姐姐颜值分布
因为腾讯云ai评分,过百的就有40来个,咱们还是用Face++吧
颜值评分这个因为是精确到了小数点后3位,所以咱们在做统分的时候,更适合先进行分箱操作
2.6.1女性角度颜值评分
先看描述统计分析结果:
(可以看到,最高95.23,最低65.596,平均83.742,中位数84.837)
>>>df['face++女性眼中颜值'].describe() count 210.000000 mean 83.742038 std 5.340208 min 65.596000 25% 81.028000 50% 84.837500 75% 87.449750 max 95.230000 Name: face++女性眼中颜值, dtype: float64
颜值按照60-100每10分一个档位,我们统计结果如下:
90分以上颜值居然高达16位~
>>>beauty_bins = [60,70,80,90,100] >>>beauty_labels = ['60-70', '70-80', '80-90', '90-100'] >>>df['face++女-颜值区间'] = pd.cut(df['face++女性眼中颜值'], bins=beauty_bins, labels=beauty_labels) >>>df['face++女-颜值区间'].value_counts() 80-90 155 70-80 34 90-100 16 60-70 5 Name: face++女-颜值区间, dtype: int64
2.6.2男性角度颜值评分
先看描述统计分析结果:
(可以看到,最高93.77,最低66.404,平均82.606,中位数83.482)
>>>df['face++男性眼中颜值'].describe() count 210.000000 mean 82.605929 std 5.055116 min 66.404000 25% 79.699250 50% 83.482500 75% 86.409000 max 93.773000 Name: face++男性眼中颜值, dtype: float64
颜值按照60-100每10分一个档位,我们统计结果如下:
90分以上颜值居然只有6位~【难道男性对颜值的要求更高???】
>>>df['face++男-颜值区间'].value_counts() 80-90 147 70-80 52 90-100 6 60-70 5 Name: face++男-颜值区间, dtype: int64
三、载入需要的库
import requests from fake_useragent import UserAgent import pandas as pd import json from lxml import etree
3.1使用requests+json获取小姐姐列表
通过F12在开发者界面Network—>XHR中我们可以发现真实数据请求地址(见Headers里的General),以及请求响应的数据格式 是 json。
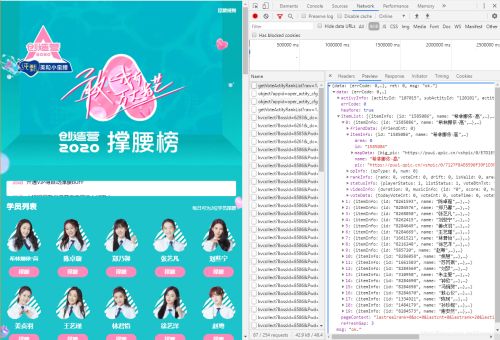
参数可以在Headers里的Query String Parameters 里找到
于是我们可以编写以下代码进行数据爬取
def get_Girllist():
url = 'https://zbaccess.video.qq.com/fcgi/getVoteActityRankList?'
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
params = {'raw': 1,
'vappid': 51902973,
'vsecret': '14816bd3d3bb7c03d6fd123b47541a77d0c7ff859fb85f21',
'actityId': 107015,
'pageSize': 101,
'vplatform': 3,
'listFlag': 0,
'pageContext':'' ,
'ver': 1,
#以下两个时间戳参数可以省略
'_t': 1590324974706,
'_': 1590324974708
}
#请求数据
re = requests.get(url,headers = headers,params = params)
#用json解析json数据成字典
data = json.loads(re.text)
Li_list = data['data']['itemList']
rank = 0
data_list = []
#获取每个选手的基础信息
for li in Li_list:
rank += 1
item = {}
#获取基础信息
item['当前排名'] = rank
item['选手编号'] = li['itemInfo']['id']
item['选手姓名'] = li['itemInfo']['name']
item['选手照片'] = li['itemInfo']['mapData']['poster_pic']
item['选手状态'] = li['statusInfo']['voteBtnTxt']
#获取选手doki页,需要传递选手编号id信息用于循环请求
#根据选手编号id到选手doki页面获取粉丝数、星座、身高、生日等基础个人信息
#简单的静态页面,这里用到xpath做解析
id_ = item['选手编号']
#调用获取选手doki页数据的函数,具体见get_Girlinfo函数
html = get_Girlinfo(id_)
item['粉丝数'] = html.xpath('.//div[@class="followers_count"]/text()')[0]
info = html.xpath('.//div[@class="wiki_info_1"]//span[@class="content"]/text()')
item['星座'] = info[-5]
item['身高'] = info[-3]
item['体重'] = info[-2]
item['出生地'] = info[-1]
info2 = html.xpath('.//div[@class="wiki_info_2"]//span[@class="content"]/text()')
item['生日'] = info2[0]
url_ai = item['选手照片']
#获取腾讯云AI颜值评分
age,beauty = txfaceScore(url_ai)
item['AI预测年龄'] = age
item['AI颜值评分'] = beauty
#获取face++颜值评分
faceage,beauty_w,beauty_m = ksfaceScore(url_ai)
item['face++AI预测年龄'] = faceage
item['face++女性眼中颜值'] = beauty_w
item['face++男性眼中颜值'] = beauty_m
data_list.append(item)
return data_list
3.2使用requests+xpath获取小姐姐基础信息
def get_Girlinfo(id_):
url_ = f'https://v.qq.com/x/star/{id_}?tabid=2'
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
re_ = requests.get(url_,headers = headers)
#直接获取的数据中中文是乱码,我们转化一下编码格式即可
re_.encoding='utf-8'
#因本次爬虫我们解析网站源码用到的是xpath,所以需要处理一下
html = etree.HTML(re_.text)
#返回处理后的网站数据源码,在小姐姐列表中我们再行处理
return html
四、使用requests调用api接口获取小姐姐颜值评分
一开始我用的是腾讯云的人脸识别,跑完数据发现101个创造营小姐姐里有21个颜值得了满分,而我喜欢的一个小姐姐朱主爱居然得分最低,那怎么行。所以,本次我们新增了旷视的FACE++人脸识别做颜值评分对比。
4.1腾讯云人脸识别
腾讯云人脸识别需要使用到第三方库tencentcloud-sdk-python
pip install tencentcloud-sdk-python
在进行调用的时候,需要先加载有关包
from tencentcloud.common import credential from tencentcloud.common.profile.client_profile import ClientProfile from tencentcloud.common.profile.http_profile import HttpProfile from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException from tencentcloud.iai.v20180301 import iai_client, models
#腾讯云人脸检测与分析
#检测给定图片中的人脸(Face)的位置、相应的面部属性和人脸质量信息
#位置包括 (x,y,w,h)
#面部属性包括性别(gender)、年龄(age)、表情(expression)、魅力(beauty)、眼镜(glass)、发型(hair)、口罩(mask)和姿态 (pitch,roll,yaw)
#人脸质量信息包括整体质量分(score)、模糊分(sharpness)、光照分(brightness)和五官遮挡分(completeness)
在第一次使用云 API 之前,用户首先需要在腾讯云控制台上申请安全凭证,安全凭证包括 SecretID 和 SecretKey, SecretID 是用于标识 API 调用者的身份,SecretKey 是用于加密签名字符串和服务器端验证签名字符串的密钥。SecretKey 必须严格保管,避免泄露。
由于我们只需要年龄和颜值评分,因此创建函数时只需要返回age和beauty两个字段即可。
def txfaceScore(url):
try:
# 实例化一个认证对象,入参需要传入腾讯云账户 secretId,secretKey
cred = credential.Credential("secretId", "secretKey")
httpProfile = HttpProfile()
httpProfile.endpoint = "iai.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = iai_client.IaiClient(cred, "ap-beijing", clientProfile)
req = models.DetectFaceRequest()
#url即我们需要做颜值评分的小姐姐照片所在网页地址url
param = {"Url":url,"NeedFaceAttributes":1}
params = json.dumps(param)
req.from_json_string(params)
resp = client.DetectFace(req)
respstr = resp.to_json_string().replace('false','0').replace('true','1')
respdic = eval(respstr)
#返回的数据格式是json,所以在转化为字典后很简单就能找到你需要的数据
age = respdic['FaceInfos'][0]['FaceAttributesInfo']['Age']
beauty = respdic['FaceInfos'][0]['FaceAttributesInfo']['Beauty']
except TencentCloudSDKException as err:
print(err)
return age,beauty
4.2Face++人脸识别
接口调用很简单,设置好你需要的请求参数(这里我们选择年龄和颜值:age,beauty),由于Face++颜值评分分为男女视角下的颜值分两种,所以我们需要返回三个值:年龄、男/女视角颜值分。
具体函数见下方:
def ksfaceScore(pic_url):
url = 'https://api-cn.faceplusplus.com/facepp/v3/detect'
APIKey = '你的key'
APISecret = '你的secret'
data = {"api_key":APIKey,
"api_secret":APISecret,
"image_url":pic_url,
"return_attributes":"age,beauty"
}
res = requests.post(url,data = data)
dic_ = eval(res.text)
#返回的数据格式是json,所以在转化为字典后很简单就能找到你需要的数据
age = dic_['faces'][0]['attributes']['age']['value']
beauty_w = dic_['faces'][0]['attributes']['beauty']['female_score']
beauty_m = dic_['faces'][0]['attributes']['beauty']['male_score']
return age,beauty_w,beauty_m
到此这篇关于Python爬虫之爬取2020女团选秀数据的文章就介绍到这了,更多相关python爬取女团内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!