分布式缓存问题
假设我们有一个网站,最近发现随着流量增加,服务器压力越来越大,之前直接读写数据库的方式不太给力了,于是我们想引入Memcached作为缓存机制。现在我们一共有三台机器可以作为Memcached服务器,如下图所示。
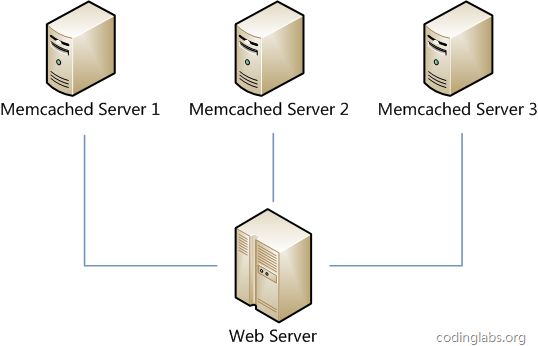
很显然,最简单的策略是将每一次Memcached请求随机发送到一台Memcached服务器,但是这种策略可能会带来两个问题:一是同一份数据可能被存在不同的机器上而造成数据冗余,二是有可能某数据已经被缓存但是访问却没有命中,因为无法保证对相同key的所有访问都被发送到相同的服务器。因此,随机策略无论是时间效率还是空间效率都非常不好。
要解决上述问题只需做到如下一点:保证对相同key的访问会被发送到相同的服务器。很多方法可以实现这一点,最常用的方法是计算哈希。例如对于每次访问,可以按如下算法计算其哈希值:
h = Hash(key) % 3
其中Hash是一个从字符串到正整数的哈希映射函数。这样,如果我们将Memcached Server分别编号为0、1、2,那么就可以根据上式和key计算出服务器编号h,然后去访问。
这个方法虽然解决了上面提到的两个问题,但是存在一些其它的问题。如果将上述方法抽象,可以认为通过:
h = Hash(key) % N
这个算式计算每个key的请求应该被发送到哪台服务器,其中N为服务器的台数,并且服务器按照0 – (N-1)编号。
这个算法的问题在于容错性和扩展性不好。所谓容错性是指当系统中某一个或几个服务器变得不可用时,整个系统是否可以正确高效运行;而扩展性是指当加入新的服务器后,整个系统是否可以正确高效运行。
现假设有一台服务器宕机了,那么为了填补空缺,要将宕机的服务器从编号列表中移除,后面的服务器按顺序前移一位并将其编号值减一,此时每个key就要按h = Hash(key) % (N-1)重新计算;同样,如果新增了一台服务器,虽然原有服务器编号不用改变,但是要按h = Hash(key) % (N+1)重新计算哈希值。因此系统中一旦有服务器变更,大量的key会被重定位到不同的服务器从而造成大量的缓存不命中。而这种情况在分布式系统中是非常糟糕的。
一个设计良好的分布式哈希方案应该具有良好的单调性,即服务节点的增减不会造成大量哈希重定位。一致性哈希算法就是这样一种哈希方案。
一致性哈希算法
算法简述
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - 232-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和232-1在零点中方向重合。
下一步将各个服务器使用H进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如下:
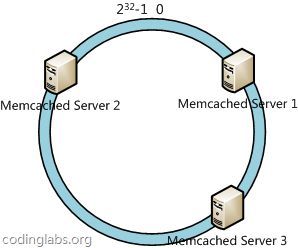
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
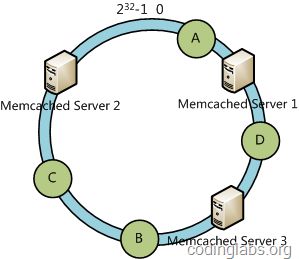
根据一致性哈希算法,数据A会被定为到Server 1上,D被定为到Server 3上,而B、C分别被定为到Server 2上。
容错性与可扩展性分析
下面分析一致性哈希算法的容错性和可扩展性。现假设Server 3宕机了:

可以看到此时A、C、B不会受到影响,只有D节点被重定位到Server 2。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果我们在系统中增加一台服务器Memcached Server 4:
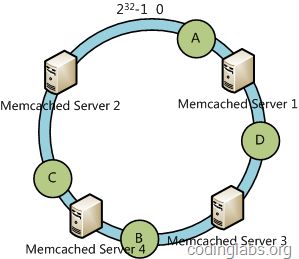
此时A、D、C不受影响,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
虚拟节点
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:

此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六个虚拟节点:
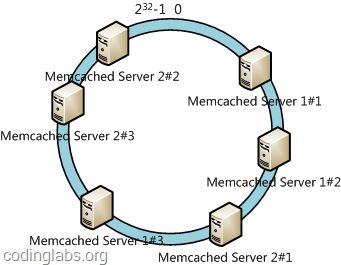
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”三个虚拟节点的数据均定位到Server 1上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
总结
目前一致性哈希基本成为了分布式系统组件的标准配置,例如Memcached的各种客户端都提供内置的一致性哈希支持。本文只是简要介绍了这个算法,更深入的内容可以参看论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》,同时提供一个C语言版本的实现供参考。
转:http://blog.codinglabs.org/articles/consistent-hashing.html
===================================
二.算法设计
1.问题来源
一个由6台服务器组成的服务,每台Server负责存储1/6的数据,当Server1出现宕机之后,服务重新恢复可用时的场景。
如下表格可以很清楚的看到,当Server1宕机时,Hash1的服务完全不可用了,所以需要ReHash由剩余5台机器提供所有的数据服务,但由于每台机器负责的数据段大小不相同,那么需要在不同的服务器之间大量迁移数据,并且数据迁移完成之前服务会不可用。

2.经典一致性哈希算法
针对ReHash的弊端,Karger提出了一种算法,算法的核心是”虚拟节点”。
将所有的数据映射成一组大于服务器数量的虚拟节点,虚拟节点再映射到真实的服务器。所以当服务器宕机时,由于虚拟节点的数量固定不变,所有不需要ReHash,而只需要将服务不可用的虚拟节点重新迁移,这样只需要迁移宕机节点的数据。
经典的算法中,宕机服务器的下一个真实节点将提供服务。

三.算法改进
1.经典一致性哈希算法的问题
经典的算法只是解决了ReHash算法的缺陷,当本身并不完美。主要存在以下几个问题:
(1)Server1宕机会导致Server2的服务承受一倍的数据服务,且如果Server1就此退役,那么整个系统的负载完全不均衡了。
(2)如果所有的Server都能承受一倍的数据读写,那么如果在正常情况下所有的数据写两份到不同的服务器,主备或者负载均衡,宕机时直接读备份节点的数据,根本不需要出现经典算法中的数据迁移。

2.Dynamo改进实践
Amazon的大数据存储平台”Dynamo”使用了一致性哈希,但它并没有使用经典算法,而是使用了故障节点ReHash的思路。
系统将所有的虚拟节点和真实服务器的对应关系保存到一个配置系统,当某些虚拟节点的服务不可用时,重新配置这些虚拟节点的服务到其他真实服务器,这样既不用大量迁移数据,也保证了所有服务器的负载相对均衡。
| 虚拟节点 | 0-4/5 | 10-14/6 | 15-19/7 | 20-24/8 | 24-29/9 |
| 恢复 | Server0 | Server2 | Server3 | Server4 | Server5 |
四.算法扩展
一致性哈希算法本身是用于解决服务器宕机与扩容的问题,但”虚拟节点”的算法思想有所发展,一些分布式的系统用于实现系统的负载均衡和最优访问策略。
在真实的系统情况下,相同部署的两套系统可能不能提供相同的服务,主要原因:
(1)硬件个体差异导致服务器性能不同。
(2)机房交换机和网络带宽导致IDC服务器之间的网络通信效率不同。
(3)用户使用不同的网络运营商导致电信IDC和联通IDC提供的服务性能不同。
(4)服务器所在网络或机房遭遇攻击。
所以完全相同的两套系统可能也需要提供差异化的服务,通过使用虚拟节点可以灵活的动态调整,达到系统服务的最优化。
对于由2个节点,每个节点3台服务器组成的分布式系统,S0-1为分布式系统1的Server0,系统配置管理员可以根据系统真实的服务效率动态的调整虚拟节点与真实服务器的映射关系,也可以由客户系统自身根据响应率或响应时间等情况调整自身的访问策略。
转;http://blog.jobbole.com/80334/