作者:Richard_Yi
链接:https://segmentfault.com/a/1190000021639286
前言
关键词:Prometheus; Grafana; Alertmanager; SpringBoot; SpringBoot Actuator; 监控; 告警;
在前一篇Spring Boot Actuator 模块 详解:健康检查,度量,指标收集和监控中,我们学习了 Spring Boot Actuator 模块的作用、配置和重要端点的介绍。
我也提到了,我主要目的是想要给我们项目的微服务应用都加上监控告警。Spring Boot Actuator的引入只是第一步,在本章中,我会介绍:
如何集成监控告警系统Prometheus 和图形化界面Grafana
如何自定义监控指标,做应用监控埋点
Prometheus 如何集成 Alertmanager 进行告警

理论部分
Prometheus
Prometheus 中文名称为普罗米修斯,受启发于Google 的Brogmon 监控系统,从2012年开始由前Google工程师在Soundcloud 以开源软件的形式进行研发,2016年6月发布1.0版本。Prometheus 可以看作是 Google 内部监控系统Borgmon 的一个实现。
下图说明了Prometheus 的体系结构及其部分生态系统组件。其中 Alertmanager 用于告警,Grafana 用于监控数据可视化,会在文章后面继续提到。
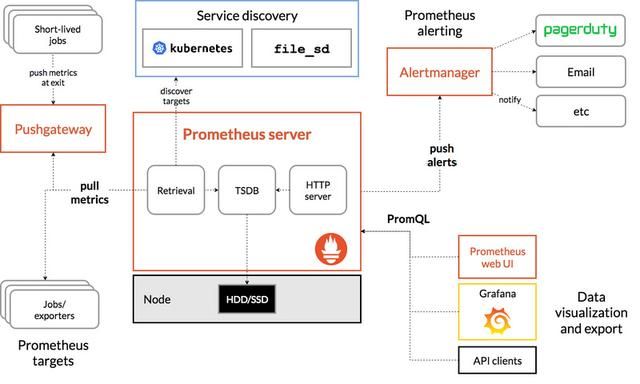
在这里我们了解到Prometheus 这几个特征即可:
数据收集器,它以配置的时间间隔定期通过HTTP提取指标数据。
一个时间序列数据库,用于存储所有指标数据。
一个简单的用户界面,您可以在其中可视化,查询和监视所有指标。
详细了解请阅读Prometheus 官方文档
Grafana
Grafana 是一款采用 go 语言编写的开源应用,允许您从Elasticsearch,Prometheus,Graphite,InfluxDB等各种数据源中获取数据,并通过精美的图形将其可视化。
除了Prometheus的AlertManager 可以发送报警,Grafana 同时也支持告警。Grafana 可以无缝定义告警在数据中的位置,可视化的定义阈值,并可以通过钉钉、email等平台获取告警通知。最重要的是可直观的定义告警规则,不断的评估并发送通知。
由于Grafana alert告警比较弱,大部分告警都是通过Prometheus Alertmanager进行告警.
请注意Prometheus仪表板也具有简单的图形。 但是Grafana的图形化要好得多。
延伸阅读:
官方文档Grafana全面瓦解
Alertmananger
Prometheus 监控平台中除了负责采集数据和存储,还能定制事件规则,但是这些事件规则要实现告警通知的话需要配合Alertmanager 组件来完成。
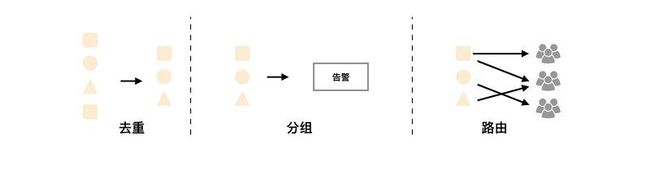
AlertManager 支持告警分组(将多个告警合并一起发送)、告警抑制以及告警静默(同一个时间段内不发出重复的告警)功能。
延伸阅读:官网对Alertmanager的介绍
监控Java 应用
监控模式
目前,监控系统采集指标有两种方式,一种是『推』,另一种就是『拉』:
推的代表有 ElasticSearch,InfluxDB,OpenTSDB 等,需要你从程序中将指标使用 TCP,UDP 等方式推送至相关监控应用,只是使用 TCP 的话,一旦监控应用挂掉或存在瓶颈,容易对应用本身产生影响,而使用 UDP 的话,虽然不用担心监控应用,但是容易丢数据。
拉的代表,主要代表就是 Prometheus,让我们不用担心监控应用本身的状态。而且可以利用 DNS-SRV 或者 Consul 等服务发现功能就可以自动添加监控。
如何监控
Prometheus 监控应用的方式非常简单,只需要进程暴露了一个用于获取当前监控样本数据的 HTTP 访问地址。这样的一个程序称为Exporter,Exporter 的实例称为一个 Target 。Prometheus 通过轮训的方式定时从这些 Target 中获取监控数据样本,对于应用来讲,只需要暴露一个包含监控数据的 HTTP 访问地址即可,当然提供的数据需要满足一定的格式,这个格式就是 Metrics 格式.
metric name>{
主要分为三个部分各个部分需符合相关的正则表达式
metric name:指标的名称,主要反映被监控样本的含义 a-zA-Z_:*_
label name: 标签 反映了当前样本的特征维度 [a-zA-Z0-9_]*
label value: 各个标签的值,不限制格式
需要注意的是,label value 最好使用枚举值,而不要使用无限制的值,比如用户 ID,Email 等,不然会消耗大量内存,也不符合指标采集的意义。
MicroMeter
前面简述了Prometheus 监控的原理。那么我们的Spring Boot 应用怎么提供这样一个 HTTP 访问地址,提供的数据还得符合上述的 Metrics 格式 ?
还记得吗,在Spring Boot Actuator 模块 详解:健康检查,度量,指标收集和监控中,我有提到过Actuator 模块也可以和一些外部的应用监控系统整合,其中就包括Prometheus 。那么Spring Boot Actuator 怎么让 Spring Boot 应用和Prometheus 这种监控系统结合起来呢?
这个桥梁就是[MicroMeter]()。Micrometer 为 Java 平台上的性能数据收集提供了一个通用的 API,应用程序只需要使用 Micrometer 的通用 API 来收集性能指标即可。Micrometer 会负责完成与不同监控系统的适配工作。

实操部分一
接下去我们一边结合实际的Demo,一边讲解说明。
初始的Demo项目创建请参照Spring Boot Actuator 模块 详解:健康检查,度量,指标收集和监控
实操部分会将分为两个部分,本部分主要是将应用如何集成Prometheus 和 Grafana 完成指标收集和可视化。
一、添加依赖
为了让Spring Boot 应用和Prometheus 集成,你需要增加micrometer-registry-prometheus依赖。
io.micrometer
micrometer-registry-prometheus
添加上述依赖项之后,Spring Boot 将会自动配置 PrometheusMeterRegistry 和 CollectorRegistry来以Prometheus 可以抓取的格式(即上文提到的 Metrics 格式)收集和导出指标数据。
所有的相关数据,都会在Actuator 的 /prometheus端点暴露出来。Prometheus 可以抓取该端点以定期获取度量标准数据。
Actuator 的 /prometheus端点
我们还是以我们之前的Demo项目为例子。深究一下这个端点的内容。添加micrometer-registry-prometheus依赖后,我们访问http://localhost:8080/actuator/prometheus地址,可以看到一下内容:
# HELP jvm_buffer_total_capacity_bytes An estimate of the total capacity of the buffers in this pool
# TYPE jvm_buffer_total_capacity_bytes gauge
jvm_buffer_total_capacity_bytes{id="direct",} 90112.0
jvm_buffer_total_capacity_bytes{id="mapped",} 0.0
# HELP tomcat_sessions_expired_sessions_total
# TYPE tomcat_sessions_expired_sessions_total counter
tomcat_sessions_expired_sessions_total 0.0
# HELP jvm_classes_unloaded_classes_total The total number of classes unloaded since the Java virtual machine has started execution
# TYPE jvm_classes_unloaded_classes_total counter
jvm_classes_unloaded_classes_total 1.0
# HELP jvm_buffer_count_buffers An estimate of the number of buffers in the pool
# TYPE jvm_buffer_count_buffers gauge
jvm_buffer_count_buffers{id="direct",} 11.0
jvm_buffer_count_buffers{id="mapped",} 0.0
# HELP system_cpu_usage The "recent cpu usage" for the whole system
# TYPE system_cpu_usage gauge
system_cpu_usage 0.0939447637893599
# HELP jvm_gc_max_data_size_bytes Max size of old generation memory pool
# TYPE jvm_gc_max_data_size_bytes gauge
jvm_gc_max_data_size_bytes 2.841116672E9
# 此处省略超多字...
可以看到,这些都是按照上文提到的 Metrics 格式组织起来的程序监控指标数据。
metric name>{
二、Prometheus 安装与配置
安装请参阅官方文档。内容不多但是很细致。你可以选择二进制安装或者是docker 的方式。这里不赘述。
Prometheus官方网站
配置Prometheus
接下去,我们需要配置Prometheus 去收集我们 Demo 项目/actuator/prometheus的指标数据。
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# demo job
- job_name: 'springboot-actuator-prometheus-test' # job name
metrics_path: '/actuator/prometheus' # 指标获取路径
scrape_interval: 5s # 间隔
basic_auth: # Spring Security basic auth
username: 'actuator'
password: 'actuator'
static_configs:
- targets: ['10.60.45.113:8080'] # 实例的地址,默认的协议是http
重点请关注这里的配置:
# demo job
- job_name: 'springboot-actuator-prometheus-test' # job name
metrics_path: '/actuator/prometheus' # 指标获取路径
scrape_interval: 5s # 间隔
basic_auth: # Spring Security basic auth
username: 'actuator'
password: 'actuator'
static_configs:
- targets: ['10.60.45.113:8080'] # 实例的地址,默认的协议是http
测试
配置完成之后,我们启动Prometheus 测试一下,如果你是docker 方式的话,在prometheus.yml 文件所在目录执行如下命令,即可启动Prometheus:
docker run -d -p 9090:9090 \
-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus --config.file=/etc/prometheus/prometheus.yml
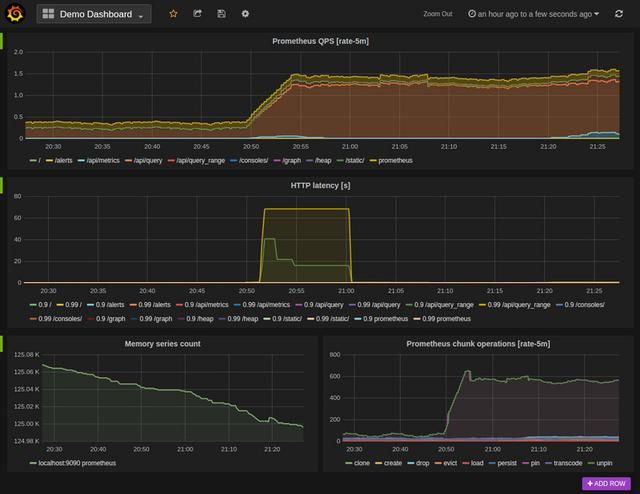
访问http://ip:9090 ,可看到如下界面:

点击 Insert metric at cursor ,即可选择监控指标;点击 Graph ,即可让指标以图表方式展示;点击Execute 按钮,即可看到类似下图的结果:
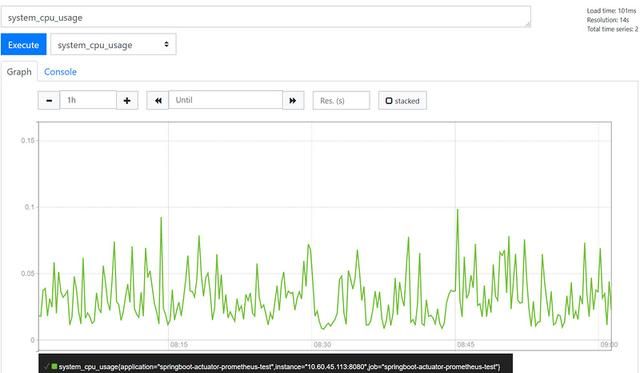
你也可以在输入框中输入PromQL来进行更高级的查询。
PromQL是Prometheus 的自定义查询语言,通过PromQL用户可以非常方便地对监控样本数据进行统计分析。
配置热加载
curl -X POST http://ip:9090/-/reload
三、Grafana安装和配置
可以看到,Prometheus 自带的监控面板非常“简陋”。所以引入Grafana 来实现更友好、更贴近生产的监控可视化。
1. 启动
$ docker run -d --name=grafana -p 3000:3000 grafana/grafana
2. 登录
访问 http://ip:3000/login ,初始账号/密码为:admin/admin ,第一次登录会让你修改密码。
3. 配置数据源
点击Configuration中Add Data Source,会看到如下界面:
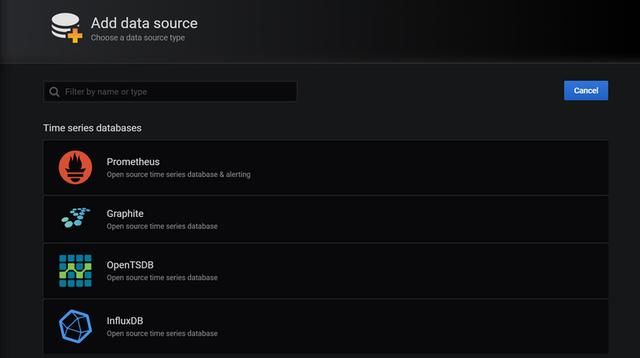
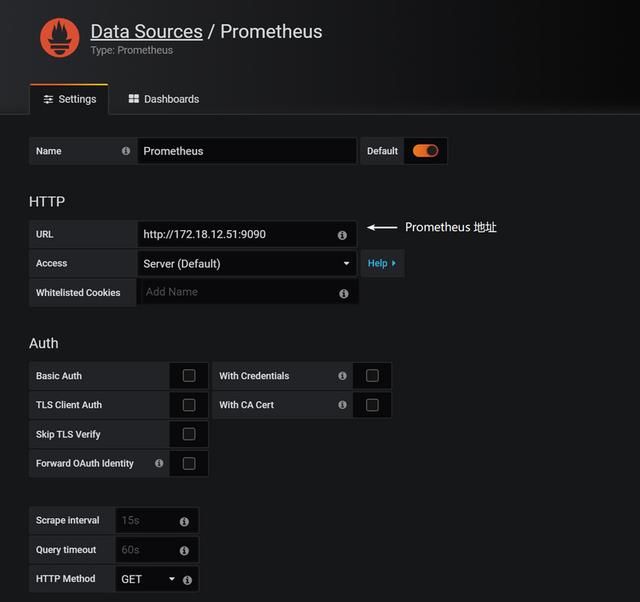
这里我们选择Prometheus 当做数据源,这里我们就配置一下Prometheus 的访问地址,点击 Save & Test:
4. 创建监控Dashboard
点击导航栏上的 + 按钮,并点击Dashboard,将会看到类似如下的界面:
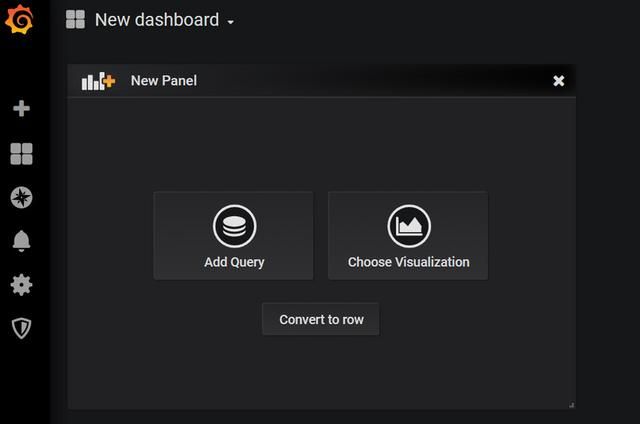
点击 Add Query ,即可看到类似如下的界面:
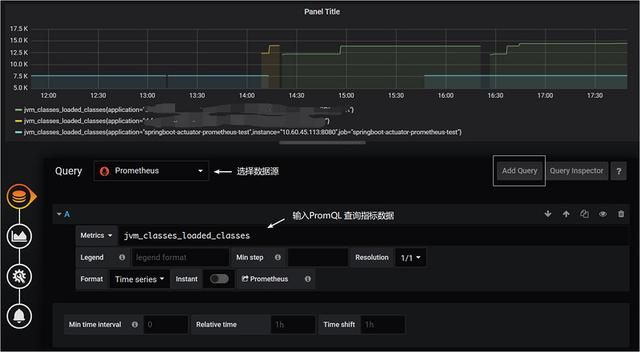
在Metrics处输入要查询的指标,指标的取值详见Spring Boot应用的 /actuator/prometheus 端点,例如jvm_memory_used_bytes 、jvm_threads_states_threads 、jvm_threads_live_threads 等,Grafana会给你较好的提示,并且可以用PromQL实现较为复杂的计算,例如聚合、求和、平均等。如果想要绘制多个线条,可点击Add Query 按钮,
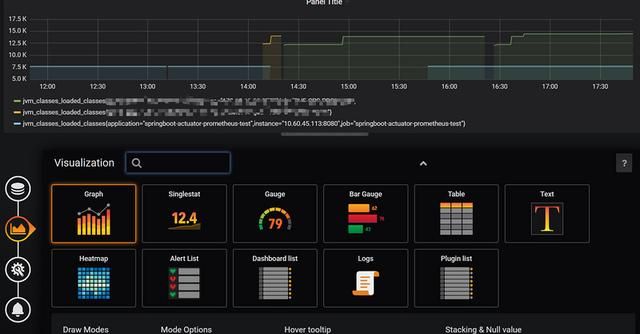
再点击下面那个Visualization,可以选择可视化的类型和一些相关的配置。这里就不多赘述,留给读者自己探索。
再点击下一步General进行基础配置,不赘述:
5. Dashboard 市场
到这里,我想聪明的读者们应该已经学会如何去可视化一个指标数据了。但是应该很多人都会觉得,如果有好多指标的话,配置起来实际上是蛮繁琐的。
是否有开箱即用、通用型的DashBoard模板呢?
前往 Grafana Lab - Dashboards ,输入关键词即可搜索指定Dashboard。你就可以获得你想要的。
另外,这些已有的dashboard也可以让我们更快掌握一些panel的配置和dashboard的使用。

6. 引入dashboard
这里直接给出两款我觉得比较好用的dashboard:
JVM (Micrometer)
Spring Boot Statistics这一款我需要提一下,刚开始我引入的时候是无效的,不知道读者会不会遇到和我一样的问题,如果遇到了,请到dashboard的设置里面,修改 variables 中 $application和$instance两个变量的Definition。
还有我个人是推荐,在这两款dashboard上面做一些定制化操作,或者说把两者的panel结合起来。
引入的操作很简单,首选你要在 Grafana Lab - Dashboards中选好你心仪的dashboard,然后记下它的ID

就是点击Import按钮:

输入ID 之后,完成配置,点击Import按钮:

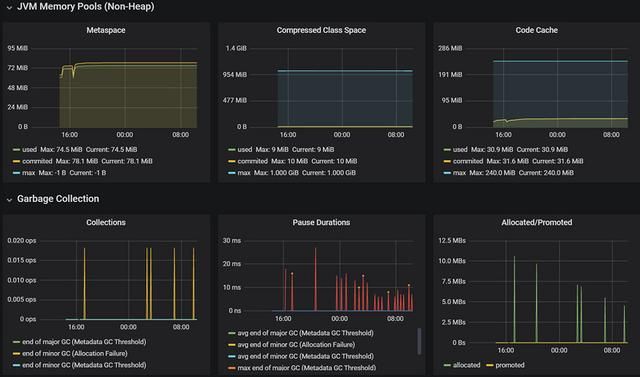
效果如下:
实操部分二
在实操部分二,主要讲如何自定义监控指标(比如我们的一些业务数据,这也叫做埋点)和如何使用Alertmanager完成监控告警。
一、自定义(业务)监控指标
模拟需求:有一个订单服务,监控 [实时订单金额]、[10分钟内下单失败率]
1. 创建 Prometheus 监控管理类PrometheusCustomMonitor
这里面我们自定义了三个metrics:
requests_error_total: 下单失败次数
order_request_count:下单总次数
order_amount_sum:下单金额统计
@Component
public class PrometheusCustomMonitor {
/**
* 记录请求出错次数
*/
private Counter requestErrorCount;
/**
* 订单发起次数
*/
private Counter orderCount;
/**
* 金额统计
*/
private DistributionSummary amountSum;
private final MeterRegistry registry;
@Autowired
public PrometheusCustomMonitor(MeterRegistry registry) {
this.registry = registry;
}
@PostConstruct
private void init() {
requestErrorCount = registry.counter("requests_error_total", "status", "error");
orderCount = registry.counter("order_request_count", "order", "test-svc");
amountSum = registry.summary("order_amount_sum", "orderAmount", "test-svc");
}
public Counter getRequestErrorCount() {
return requestErrorCount;
}
public Counter getOrderCount() {
return orderCount;
}
public DistributionSummary getAmountSum() {
return amountSum;
}
}
2. 新增/order接口
当 flag="1"时,抛异常,模拟下单失败情况。在接口中统计order_request_count和order_amount_sum。
@RestController
public class TestController {
@Resource
private PrometheusCustomMonitor monitor;
//....
@RequestMapping("/order")
public String order(@RequestParam(defaultValue = "0") String flag) throws Exception {
// 统计下单次数
monitor.getOrderCount().increment();
if ("1".equals(flag)) {
throw new Exception("出错啦");
}
Random random = new Random();
int amount = random.nextInt(100);
// 统计金额
monitor.getAmountSum().record(amount);
return "下单成功, 金额: " + amount;
}
}
PS:实际项目中,采集业务监控数据的时候,建议使用AOP的方式记录,不要侵入业务代码。不要像我Demo中这样写。
3. 新增全局异常处理器GlobalExceptionHandler
统计下单失败次数requests_error_total:
@ControllerAdvice
public class GlobalExceptionHandler {
@Resource
private PrometheusCustomMonitor monitor;
@ResponseBody
@ExceptionHandler(value = Exception.class)
public String handle(Exception e) {
monitor.getRequestErrorCount().increment();
return "error, message: " + e.getMessage();
}
}
测试:
启动项目,访问http://localhost:8080/order和http://localhost:8080/order?flag=1模拟下单成功和失败的情况,然后我们访问http://localhost:8080/actuator/prometheus,可以看到我们自定义指标已经被/prometheus端点暴露出来了:
# HELP requests_error_total
# TYPE requests_error_total counter
requests_error_total{application="springboot-actuator-prometheus-test",status="error",} 41.0
# HELP order_request_count_total
# TYPE order_request_count_total counter
order_request_count_total{application="springboot-actuator-prometheus-test",order="test-svc",} 94.0
# HELP order_amount_sum
# TYPE order_amount_sum summary
order_amount_sum_count{application="springboot-actuator-prometheus-test",orderAmount="test-svc",} 53.0
order_amount_sum_sum{application="springboot-actuator-prometheus-test",orderAmount="test-svc",} 2701.0
4. 在Grafana 中添加对应监控面板
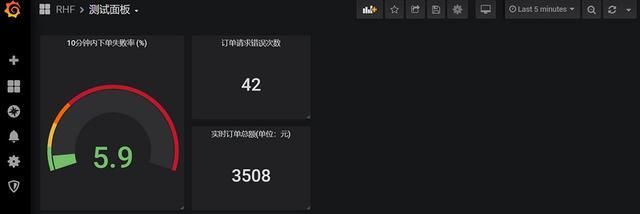
这里我新增一个dashboard作为演示用,一些步骤前面讲过这里就直接省略:
首先是创建10分钟内下单失败率
sum(rate(requests_error_total{application="springboot-actuator-prometheus-test"}[10m])) / sum(rate(order_request_count_total{application="springboot-actuator-prometheus-test"}[10m])) * 100
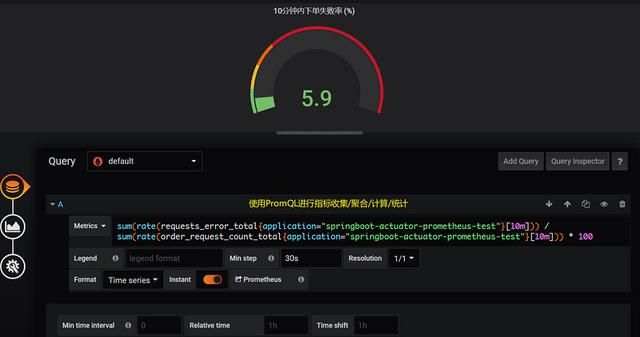
然后是统计订单总金额:
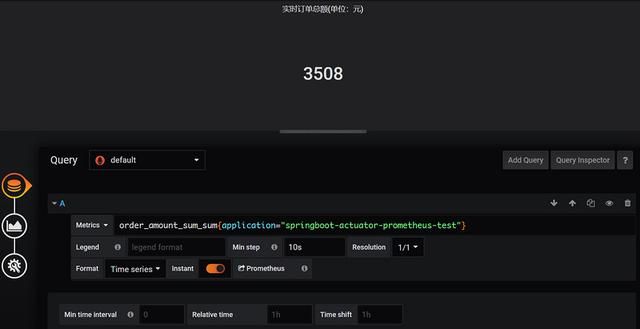
最终结果
二、添加监控
模拟告警规则:
服务是否下线10分钟内下单失败率是否大于10%
1. 部署 Alertmanager
这里采用二进制包的方式部署。
Alertmanager最新版本的下载地址可以从Prometheus官方网站https://prometheus.io/downloa...
下载完成后,解压后会包含一个默认的alertmanager.yml配置文件,我们在里面添加发送邮件配置
# 全局配置
global:
resolve_timeout: 5m
smtp_smarthost: 'xxxxxx'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'XXXXXX'
# 路由配置
route:
receiver: 'default-receiver' # 父节点
group_by: ['alertname'] # 分组规则
group_wait: 10s # 为了能够一次性收集和发送更多的相关信息时,可以通过group_wait参数设置等待时间
group_interval: 1m #定义相同的Group之间发送告警通知的时间间隔
repeat_interval: 1m
routes: # 子路由,根据match路由
- receiver: 'rhf-mail-receiver'
group_wait: 10s
match: # 匹配自定义标签
team: rhf
# 告警接收者配置
receivers:
- name: 'default-receiver'
email_configs:
- to: '[email protected]'
- name: 'rhf-mail-receiver'
email_configs:
- to: '[email protected]'
目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。Alertmanager的通知方式中还可以支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持(钉钉、企业微信等)。
相关配置延伸阅读:
延伸阅读1延伸阅读2
启动
Alermanager会将数据保存到本地中,默认的存储路径为data/。因此,在启动Alertmanager之前需要创建相应的目录:
./alertmanager
用户也在启动Alertmanager时使用参数修改相关配置。--config.file用于指定alertmanager配置文件路径,--storage.path用于指定数据存储路径。
查看运行状态,启动之后我们访问9093端口:

Alert菜单下可以查看Alertmanager 接收到的告警内容。Silences菜单下则可以通过UI创建静默规则。Status菜单下面可以看到Alertmanager 的配置信息。
配置热加载
curl -X POST http://ip:9093/-/reload
2. 设置告警规则
在Prometheus 目录下新建test-svc-alert-rule.yaml来设置告警规则,内容如下:
groups:
- name: svc-alert-rule
rules:
- alert: svc-down # 服务是否下线
expr: sum(up{job="springboot-actuator-prometheus-test"}) == 0
for: 1m
labels: # 自定义标签
severity: critical
team: rhf # 我们小组的名字,对应上面match 的标签匹配
annotations:
summary: "订单服务已下线,请检查!!"
- alert: order-error-rate-high # 10分钟内下单失败率是否大于10%
expr: sum(rate(requests_error_total{application="springboot-actuator-prometheus-test"}[10m])) / sum(rate(order_request_count_total{application="springboot-actuator-prometheus-test"}[10m])) > 0.1
for: 1m
labels:
severity: major
team: rhf
annotations:
summary: "订单服务响应异常!!"
description: "10分钟订单错误率已经超过10% (当前值: {{ $value }} !!!"
实际项目中,可以用一个rule目录存放所有的告警规则,然后rule/*.yaml的方式配置
3. 配置Prometheus
在 prometheus.yml文件下,引用test-svc-alert-rule.yaml告警规则配置,并开启 Alertmanager。
alerting:
alertmanagers:
- static_configs:
- targets:
# alertmanage default start port 9093
- localhost:9093
rule_files:
- /data/prometheus-stack/prometheus/rule/*.yml
4. 测试
现在我们配置完成之后,热加载一下Prometheus 的配置。然后尝试触发告警条件。
测试服务下线,把测试服务手动停掉

测试下单异常
在http://ip:9093界面可以看到触发的告警
小结
到这里我们的Spring Boot 微服务监控告警模块也就算讲述完毕了。希望能给你带来一些收获。
对应的源码可以Github上看到。。
喜欢对你有帮助的话记得加个关注不迷路哦
还有关注我私信回复【资料】可以领取到一些个人收集的面试及电子书资料,或许对你有帮助!《Java学习、面试;文档、视频资源免费获取》