Python爬虫 反爬机制:验证码识别 基于cookie登录:session会话对象
验证码识别
反爬机制:验证码
验证码是门户网站使用的一种反爬机制。
识别验证码图片中的数据,用于模拟登录操作。
识别验证码
方式
- 人工肉眼识别(不推荐,效率低)
- 第三方自动识别
第三方自动识别
超级鹰
收费的,不能白嫖了,量力而行吧
http://www.chaojiying.com/
图鉴
tesserocr
穷逼的我选择这个-_-
tesserocr 是 Python 的一个 OCR 识别库
tesserocr其实是对 tesseract 做的一 层 Python API 封装,所以它的核心是 tesseract。
因此,在安装 tesserocr 之前,我们需要先安装 tesseract 。
tesseract 下载地址: http://digi.bib.uni-mannheim.de/tesseract
tesseract 语言包: http://github.com/tesseract-ocr/tessdata
tesseract 文档: https://github.com/tesseract-ocr/tesseract/wiki/Documentation
1、下载 tesseract ,安装
2、配置环境变量

3、安装 tesserocr(很麻烦,容易报错)
pip install tesserocr pillow
如果通过 pip 安装失败,可以尝试 Anaconda 下的 conda 来安装:
conda install -c simonflueckiger tesserocr pillow
测试:
import tesserocr
from PIL import Image
image = Image.open('image.png')
result = tesserocr.image_to_text(image)
print(result)
还可以直接调用 tesserocr 模块的 file_to_text() 方法,可以达到同样的效果:
import tesserocr
print(tesserocr.file_to_text('image.png'))
参考文章:
https://www.cnblogs.com/Jimc/p/9772930.html
http://www.xueshanlinghu.com/excellent-articles/2555.html
实战
由于特殊原因不能使用自动识别,故使用人工肉眼智能(智障)识别。
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
text_data = requests.get(url=url, headers=headers).text
tree = etree.HTML(text_data)
img_src = tree.xpath('//*[@id="imgCode"]/@src')[0]
img_url = 'https://so.gushiwen.cn' + img_src
img_data = requests.get(url=img_url).content
with open('./验证码/code.png', 'wb') as fp:
fp.write(img_data)
input('查看图片并输入验证码:')
尝试登录:
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
text_data = requests.get(url=url, headers=headers).text
tree = etree.HTML(text_data)
img_src = tree.xpath('//*[@id="imgCode"]/@src')[0]
img_url = 'https://so.gushiwen.cn' + img_src
img_data = requests.get(url=img_url).content
with open('./验证码/code.png', 'wb') as fp:
fp.write(img_data)
code = input('查看图片并输入验证码:')
print(code)
login_url = 'https://so.gushiwen.cn/user/login.aspx'
data = {
'__VIEWSTATE': 'XwGXwnmgjuYvGDFXiaR9sYog4Hn1IxtR5VYtCGIPMpUJTjV9H3VVZuUhYQP/ysrXR//JQ7DKf4ZuP2Qj0Y69qnsyoTIThEWaoDrU/MxP8cvyqOb/2C2HT8RQ594=',
'__VIEWSTATEGENERATOR': 'C93BE1AE',
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '[email protected]',
'pwd': 'xxxx',
'code': code,
'denglu': '登录'
}
login_text = requests.post(url=login_url, data=data, headers=headers).text
with open('./验证码/login.html', 'w', encoding='utf_8') as fp:
fp.write(login_text)
print('over')
基于cookie登录
HTTPS/HTTP 协议特性:无状态
cookie:用来让服务端记录客户端的相关状态。
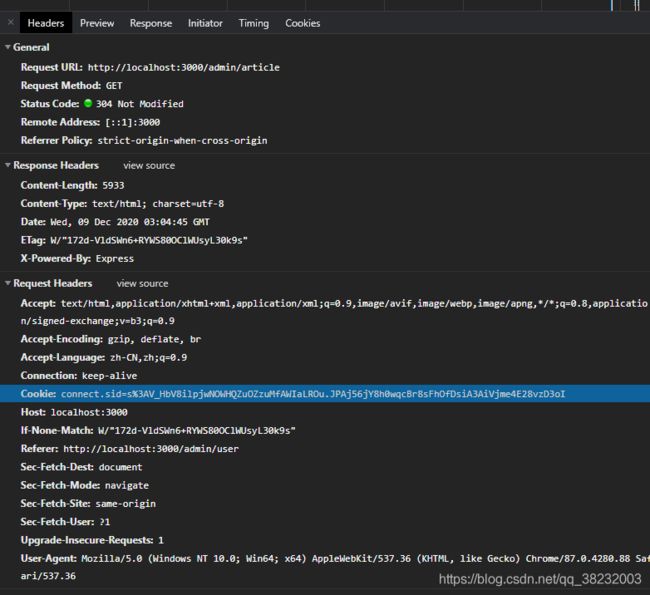
手动cookie处理(不推荐)
将浏览器的cookie复制,加入的爬虫的headers中
headers = {
'Cookie': 'connect.sid=s%3AnZ1GkHakY0UePD2zbPSsepLSU8-iOGHS.p9nAcl9UODaCMgaA4JoeUUptCy%2BslPks8FR84BJ%2FKk8'
}
requests.get(url=user_url, headers=headers)
缺点:通用性不强
- 不方便
- cookie有有效时长
- 有些网站cookie有可能随时变化
自动处理
模拟登录时,服务器端创建的,并设置在响应头上
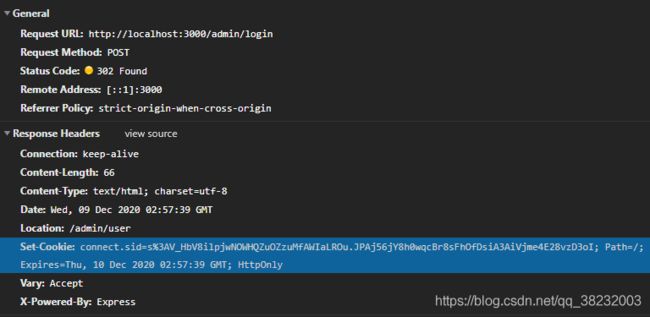
session会话对象
作用:
- 可以进行请求的发送
- 如果请求过程中产生cookie,则该cookie会被自动存储/携带在该session回话对象中
创建一个session对象
session = requests.Session()
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'http://localhost:3000/admin/login'
data = {
'email': '[email protected]',
'password': '1'
}
# 创建session对象,cookie会自动存储/携带
session = requests.Session()
# 使用session请求登录
session.post(url=url, data=data, headers=headers).text
# 使用session请求登录后的页面
user_url = 'http://localhost:3000/admin/article'
response = session.get(url=user_url, headers=headers).text
with open('./验证码/login.html', 'w', encoding='utf-8') as fp:
fp.write(response)
print('over')