TensorFlow2.0实战笔记之(6):Char RNN 文本生成
1. 简介
Char RNN是一种字符级的循环神经网络,其本质是序列数据的推测,即通过已知的字符,预测下一个字符出现的概率并选取概率最大者为下一个字符。比如,已知hello的前四个字母hell,那我们就可以据此预测下一个字符很可能是o。因为是char级别的,并没有单词或句子层次上的特征提取,相对而言比较简单。
根据Char RNN的特点,它可以用来写诗,写歌,生成文章,生成代码等。
2. 原理
2.1 RNN的原理
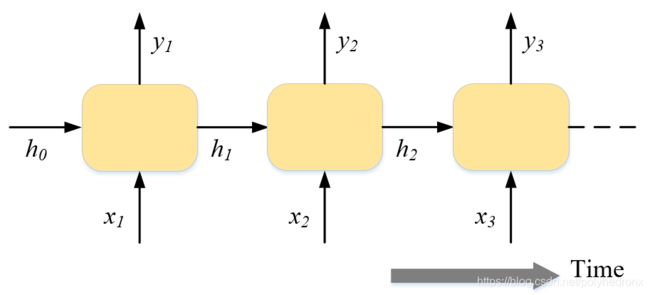
RNN(Recurrent Neural Networks),即循环神经网络。在实际应用中我们可能会碰到很多序列型的数据,如下图,它们可能是自然语言处理问题中的一个个单词,或者是语音处理中的每帧声音信号,也可能是时间序列问题,如每天的股票价格等,RNN就是一种对序列型数据进行建模的深度模型。

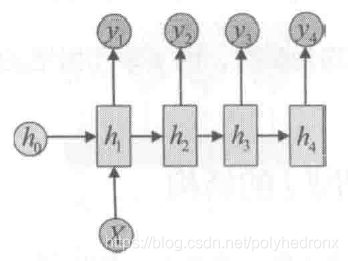
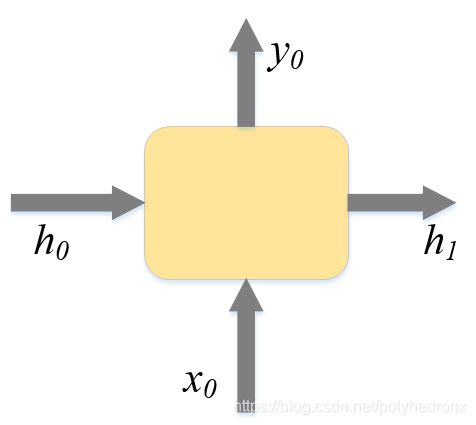
经典的RNN结构如下图所示。它的输入是x序列,输出是y序列,h序列为隐状态。
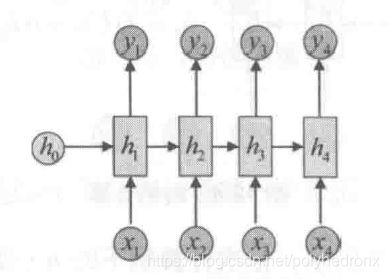
经典RNN的运算过程可以表示为
![]()
![]()
其中,U,W和V是参数矩阵,b和c是偏置参数,f表示激活函数。需要注意的是,在每一步的计算中使用的参数U,W,b,V,c都是一样的,即是参数共享的。
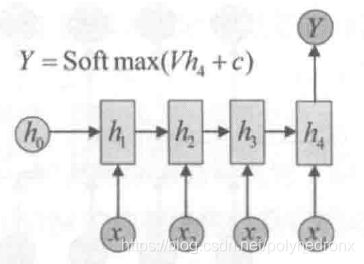
在经典的 “N vs N” RNN结构中,输入和输出序列的等长的。除此之外,还有“N vs 1” RNN以及“1 vs N” RNN的结构。
2.2 LSTM的原理
LSTM(Long Short-Term Memory),即长短期记忆网络。在经典的RNN中,每一层的隐状态都由前一层的隐状态经过变换和激活函数得到,反向传播求导时最终得到的导数会包含每一步梯度的连乘,这会引起梯度爆炸或梯度消失的现象,所以RNN无法学到序列中蕴含的间隔时间较长的规律。LSTM是一种RNN的变体结构,每级LSTM的结构如下。从外部来看,两者的输入和输出都是一样的,但在内部,LSTM的隐状态相较于RNN添加了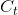 ,图中
,图中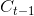 到的水平线是LSTM的主干道,在主干道的无障碍传递(加法代替乘法)解决了在较长序列中梯度失效的问题。此外,图中
到的水平线是LSTM的主干道,在主干道的无障碍传递(加法代替乘法)解决了在较长序列中梯度失效的问题。此外,图中 、
、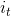 、
、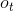 分别为遗忘门、记忆门、输出门的输出,两个tanh层则分别对应记忆单元的输入和输出,向量
分别为遗忘门、记忆门、输出门的输出,两个tanh层则分别对应记忆单元的输入和输出,向量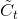 由第一个tanh层生成用于更新记忆单元状态,
由第一个tanh层生成用于更新记忆单元状态, 是Sigmoid激活函数,它的输出在0~1之间。
是Sigmoid激活函数,它的输出在0~1之间。

2.2.1 遗忘门
LSTM的每一个单元中都有一个“遗忘门”,用来控制遗忘掉的哪些部分。遗忘门的结构如下图,它的输入是 和
和 ,是当前时刻的输入,为上一个时刻的隐状态。遗忘门的输出是和相同形状的矩阵,这个矩阵会和逐点相乘,决定要遗忘哪些东西。显然,遗忘门输出接近0的位置的内容是要遗忘的,而接近1的部分是要保留的。
,是当前时刻的输入,为上一个时刻的隐状态。遗忘门的输出是和相同形状的矩阵,这个矩阵会和逐点相乘,决定要遗忘哪些东西。显然,遗忘门输出接近0的位置的内容是要遗忘的,而接近1的部分是要保留的。

2.2.2 记忆门
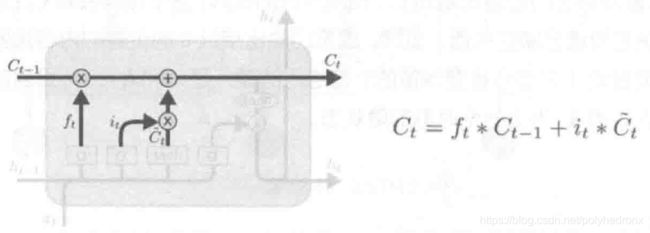
LSTM在遗忘一部分内容的同时也会记住一些新的内容,所以存在下图所示的“记忆门”。记忆门的输入同样是和,它的输出有两项,一项是,的值决定了当前输入有多少将保存到记忆单元状态中,同样经过Sigmoid函数运算得到,因此值都在0~1之间;还有一项是,由tanh层生成,用于更新记忆单元状态。最终要“记住”的内容是和的逐点相乘。
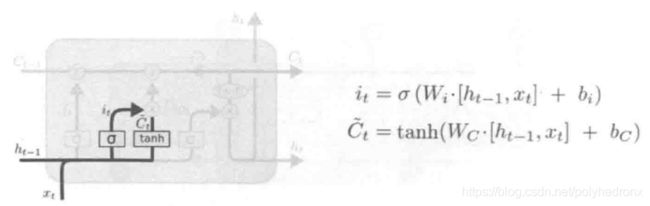
遗忘和记忆的过程如下图所示,是遗忘门的输出(0~1之间),而![]() 是要记住的新东西。
是要记住的新东西。
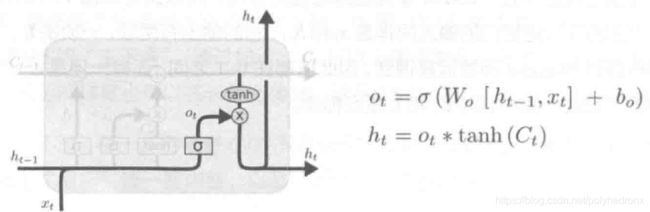
2.2.3 输出门
最后,还需要一个“输出门”,用于输出内容。如图所示,输入同样是和,中的每一个数值在0~1之间, 通过
通过![]() 得到。
得到。
需要注意的是,这里所说的输出其实是计算下一个隐状态的值,真正的输出( )还需要对做进一步运算得到。
)还需要对做进一步运算得到。
2.3 Char RNN的原理
Char RNN使用的是最经典的 “N vs N” RNN模型,即输入是长度为N的序列,输出是与之等长的序列。
在模型训练过程中,输入序列是句子中的字母,输出是对应输入的下一个字母,换句话说,是用已经输入的字母去预测下一个字母的概率。如一个简单的英文句子“Hello!”,输入序列是{H, e, l, l, o},输出序列依次是{e, l, l, o, !}。

使用Char RNN测试生成序列的具体流程为:首先选择一个 作为起始字符,然后通过训练好的模型得到下一个字符的概率,选取概率最大者作为下一个字符,并将该字符作为下一步的输入
作为起始字符,然后通过训练好的模型得到下一个字符的概率,选取概率最大者作为下一个字符,并将该字符作为下一步的输入 ,依此类推。根据需要生成的文本长度选择循环次数,即可生成所需长度的文字。
,依此类推。根据需要生成的文本长度选择循环次数,即可生成所需长度的文字。
对于英文字母,一般使用one-hot编码,假设一共有26个字符,那么字母a的one-hot编码为(1, 0, 0, 0, ..., 0),即第一位为1,其余25位都是0。输出相当于一个26分类问题,每一步的输出向量是26维的,每一维代表相应字母的概率,最后的损失使用交叉熵可以直接得到。在实际模型中,由于字母有大小之分以及其他标点符号和空格等,因此总类别数会比26多。
在对中文建模时,由于汉字总数比较多,可能会导致模型过大,对此有两种优化方法:
- 取最常用的N个汉字,将剩下的汉字单独归为一类,并用一个特殊的字符
进行标注。 - 在输入时,可以加入一层embedding层,该层可以将汉字转换为较为稠密的表示,它可以代替稀疏的one-hot表示方法,取得更好的效果。embedding的参数可以直接从数据中学到。
中文汉字的输出层和处理英文字母类似,都相当于一个N分类问题。
3. Tensorflow中RNN的实现方式
3.1 版本兼容问题
本文中使用的Tensorflow版本为2.3.1,python版本为3.8.5。
2019年10月1日,tensorflow正式发布了2.0版本,相对于1.0版本发生了很大的变化-->tensorflow2.0 新特性,而目前能查阅到的使用tensorflow实现RNN的资料基本上都是基于tensorflow 1.0版本的,为了与时俱进,本文将根据v1版本的资料,使用v2版本的一些新的API对其实现方式进行更新。
首先是v1版本的几个常用API,
tf.nn.rnn_cell.BasicRNNCell # 定义一个基本RNN单元
tf.nn.rnn_cell.BasicLSTMCell # 定义一个基本LSTM单元
tf.nn.rnn_cell.MultiRNNCell # 对单层RNN进行堆叠
tf.nn.dynamic_rnn # 展开时间维度在tensorflow v2版本中,上述API都已被弃用,并会在将来的版本中删除。如果你仍然想在v2版本中使用这些API,则可以以如下方式调用,也就是在每个调用中都加入了“compat.v1”,简直难以忍受有木有!
tf.compat.v1.nn.rnn_cell.BasicRNNCell # 定义一个基本RNN单元
tf.compat.v1.nn.rnn_cell.BasicLSTMCell # 定义一个基本LSTM单元
tf.compat.v1.nn.rnn_cell.MultiRNNCell # 对单层RNN进行堆叠
tf.compat.v1.nn.dynamic_rnn # 展开时间维度如果你不想使用上面兼容的版本,则可以顺应时代发展趋势,使用tensorflow v2中推荐的相应的替代API,
tf.compat.v1.nn.rnn_cell.BasicRNNCell # --> tf.keras.layers.SimpleRNNCell
tf.compat.v1.nn.rnn_cell.BasicLSTMCell # --> tf.keras.layers.LSTMCell
tf.compat.v1.nn.rnn_cell.MultiRNNCell # --> tf.keras.layers.StackedRNNCells
tf.compat.v1.nn.dynamic_rnn # --> tf.keras.layers.RNN此外,在tensorflow v2中,placeholder也已被移除,可以使用tf.compat.v1.placeholder代替,当然,这仍然是v1版本中的实现方法,如果想要迁移到v2版本,则可以选择使用tf.keras.Input代替,它用于实例化一个Keras张量(调用后返回一个tensor),参数如下:
tf.keras.Input(
shape=None, # 整数,表示输入向量的维度大小;设置为'None'表示维度未知
batch_size=None, # 整数,表示可选的静态batch大小
name=None, # 字符串,表示层的可选名称,在model中应该是唯一的;如果未提供,将自动生成
dtype=None, # 字符串,表示输入的数据类型(如float32, float64, int32等)
sparse=False, # 布尔值,指定要创建的placeholder是否稀疏。'sparse'和'ragged'只有一个可以为'True'
tensor=None, # 可选择将现有的张量封装到输入层。如果设置,该层将不会创建placeholder张量
ragged=False, # 布尔值,指定要创建的placeholder是否不规则
**kwargs # 弃用参数支持。支持batch_shape和batch_input_shape
)Keras张量是Tensorflow符号张量对象,并使用了某些属性对其进行扩充,这些属性使我们仅通过了解模型的输入和输出即可构建Keras模型。例如,如果a,b,c是Keras张量,则可以:
model = Model(input=[a, b], output=c)tf.keras.Input的使用举例1(Keras 函数式API):
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(784,), name='img')
h1 = layers.Dense(32, activation='relu')(inputs)
h2 = layers.Dense(32, activation='relu')(h1)
outputs = layers.Dense(10, activation='softmax')(h2)
model = keras.Model(inputs=inputs, outputs=outputs, name='mymodel')
model.summary()tf.keras.Input的使用举例2(Keras Sequential API):
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential()
model.add(keras.Input(shape=(250, 250, 3))) # 250x250 RGB images
model.add(layers.Conv2D(32, 5, strides=2, activation="relu"))
model.add(layers.Conv2D(32, 3, activation="relu"))
model.add(layers.MaxPooling2D(3))
# Can you guess what the current output shape is at this point? Probably not.
# Let's just print it:
model.summary()
# The answer was: (40, 40, 32), so we can keep downsampling...
model.add(layers.Conv2D(32, 3, activation="relu"))
model.add(layers.Conv2D(32, 3, activation="relu"))
model.add(layers.MaxPooling2D(3))
model.add(layers.Conv2D(32, 3, activation="relu"))
model.add(layers.Conv2D(32, 3, activation="relu"))
model.add(layers.MaxPooling2D(2))
# And now?
model.summary()
# Now that we have 4x4 feature maps, time to apply global max pooling.
model.add(layers.GlobalMaxPooling2D())
# Finally, we add a classification layer.
model.add(layers.Dense(10))
值得注意的是,即使启用了eager execution(tensorflow 2.0的默认执行方式,动态计算图),Input也会产生符号张量(即占位符placeholder)。此符号张量可与其他TensorFlow操作一起使用,例如:
x = Input(shape=(32,))
y = tf.square(x)3.2 单层RNN单元的实现
3.2.1 定义一个基本RNN单元(RNN cell)
一个基本的RNN单元如下图所示。Tensorflow v2中使用tf.keras.layers.SimpleRNNCell定义一个基本的RNN单元。
SimpleRNNCell继承自Layer基类,主要包含4个方法:
- init():构造方法,主要用于初始化参数
- build():主要用于初始化网络层中涉及到的权重参数
- call():用于网络层的参数计算,对输入进行计算,并产生相应地输出
- get_config():获取该网络层的参数配置
具体参数如下:
tf.keras.layers.SimpleRNNCell(
units, # 正整数,输出空间的维度,即隐含层神经元的数量
activation='tanh', # 激活函数,默认为"tanh"。如果设置为None,则不使用任何激活(即线性激活,a(x)=x)
use_bias=True, # 布尔值,该层是否使用偏置矢量
kernel_initializer='glorot_uniform', # 输入和隐含层之间权重矩阵的初始化
recurrent_initializer='orthogonal', # 隐含层之间的权重矩阵的初始化
bias_initializer='zeros', # 偏置矢量的初始化
kernel_regularizer=None, # 输入和隐含层之间权重矩阵的正则化函数
recurrent_regularizer=None, # 隐含层之间的权重矩阵的正则化函数
bias_regularizer=None, # 偏置矢量的正则化函数
kernel_constraint=None, # 输入和隐含层之间权重矩阵的约束函数
recurrent_constraint=None, # 隐含层之间的权重矩阵的约束函数
bias_constraint=None, # 偏置矢量的约束函数
dropout=0.0, # float,在0~1之间取值,输入层线性变换时要丢弃的unit的比例
recurrent_dropout=0.0, # float,在0~1之间取值,隐含层线性变换时要丢弃的unit的比例
**kwargs
)调用参数有:
- input:一个二维的张量,形状为[batch, feature],表示t时刻的输入
- states:一个二维的张量,形状为[batch, units],表示t-1时刻的状态
- training:布尔值,指示该层是在训练模式还是在推理模式下运行。仅在使用dropout或者recurrent_dropout才相关。
实例1:
import tensorflow as tf
batch_size = 10
time_step = 20
embedding_dim = 100 # 特征维度
hidden_dim = 64 # 隐含层维度
train_x = tf.random.normal(shape=[batch_size, time_step, embedding_dim])
x0 = train_x[:, 0, :] # timestep=0时的输入
h0 = tf.random.normal(shape=[batch_size, hidden_dim])
cell = tf.keras.layers.SimpleRNNCell(hidden_dim)
out, h1 = cell(x0, [h0]) # 将当前时间步的输入x_t和上一时间步隐含层的输出h_{t-1} feed to cell
print(out.shape, h1[0].shape)
print(out._id, h1[0]._id) # 二者id完全相同
注意:这里的输出out其实是和隐含层输出h1一样的(从shape和id可以看出),而不是最终的输出y,还需要额外对out定义新的变换,才能得到真正的输出y。例如,如果是处理的多分类问题,还需要对out添加单独的Softmax层才能得到最后的分类概率输出。
实例2(官方,多层timestep堆叠):
inputs = np.random.random([32, 10, 8]).astype(np.float32)
rnn = tf.keras.layers.RNN(tf.keras.layers.SimpleRNNCell(4))
output = rnn(inputs) # The output has shape `[32, 4]`.
rnn = tf.keras.layers.RNN(
tf.keras.layers.SimpleRNNCell(4),
return_sequences=True,
return_state=True)
# whole_sequence_output has shape `[32, 10, 4]`.
# final_state has shape `[32, 4]`.
whole_sequence_output, final_state = rnn(inputs)多层timestep堆叠,即将单个RNN单元在时间维度上展开,在3.3节中有详细介绍。
3.2.2 定义一个基本LSTM单元
Tensorflow v2中使用tf.keras.layers.LSTMCell定义一个基本的LSTM单元。其参数如下:
tf.keras.layers.LSTMCell(
units, # 正整数,输出空间的维度,即隐含层神经元的数量
activation='tanh', # 激活函数,默认为"tanh"。如果设置为None,则不使用任何激活(即线性激活,a(x)=x)
recurrent_activation='sigmoid', # 门激活函数
use_bias=True, # 布尔值,该层是否使用偏置矢量
kernel_initializer='glorot_uniform', # 输入和隐含层之间权重矩阵的初始化
recurrent_initializer='orthogonal', # 隐含层之间的权重矩阵的初始化
bias_initializer='zeros', # 偏置矢量的初始化
unit_forget_bias=True, # 布尔值,若为True,则在初始化时将1加到遗忘门的偏置上。将其设为True还将强制bias_initializer="zeros"
kernel_regularizer=None, # 输入和隐含层之间权重矩阵的正则化函数
recurrent_regularizer=None, # 隐含层之间的权重矩阵的正则化函数
bias_regularizer=None, # 偏置矢量的正则化函数
kernel_constraint=None, # 输入和隐含层之间权重矩阵的约束函数
recurrent_constraint=None, # 隐含层之间的权重矩阵的约束函数
bias_constraint=None, # 偏置矢量的约束函数
dropout=0.0, # float,在0~1之间取值,输入层线性变换时要丢弃的unit的比例
recurrent_dropout=0.0, # float,在0~1之间取值,隐含层线性变换时要丢弃的unit的比例
implementation=2, # 实现模式,取值为1或者2。模式1会将其操作构造为大量较小的点积和加法运算,而模式2(默认)会将其分为更少的较大操作
**kwargs
)调用参数有:
- input:一个二维的张量,形状为[batch, feature],表示t时刻的输入
- states:包含两个张量的列表,每个张量的形状均为[batch, units],第一个张量是t-1时刻的存储状态
- training:布尔值,指示该层是在训练模式还是在推理模式下运行。仅在使用dropout或者recurrent_dropout才相关。
实例(官方,多层timestep堆叠):
import tensorflow as tf
inputs = tf.random.normal([32, 10, 8])
rnn = tf.keras.layers.RNN(tf.keras.layers.LSTMCell(4))
output = rnn(inputs)
print(output.shape)
rnn = tf.keras.layers.RNN(
tf.keras.layers.LSTMCell(4),
return_sequences=True,
return_state=True)
whole_seq_output, final_memory_state, final_carry_state = rnn(inputs)
print(whole_seq_output.shape, final_memory_state.shape, final_carry_state.shape)
3.3 多层timestep堆叠(按时间维度展开)
3.3.1 tf.keras.layers.RNN
对于单个的RNN cell,使用它的call函数进行计算时,只是在序列时间上前进行了一步,如使用、 得到
得到 ,通过、得到
,通过、得到 等。如果序列长度为n,则要调用n次call函数,比较麻烦。对此,Tensorflow提供了一个tf.keras.layers.RNN函数,使用该函数相当于调用了n次call函数,即通过
等。如果序列长度为n,则要调用n次call函数,比较麻烦。对此,Tensorflow提供了一个tf.keras.layers.RNN函数,使用该函数相当于调用了n次call函数,即通过![]() 直接得到
直接得到![]() 。
。
函数参数有:
tf.keras.layers.RNN(
cell, # RNN单元实例或者RNN单元实例列表
return_sequences=False, # 布尔值,True:返回完整的输出序列,False:仅返回输出序列中的最后一个输出
return_state=False, # 布尔值,True:返回最后一个隐含层的状态,False:不返回
go_backwards=False, # 布尔值,True:反向处理输入序列并返回反向的序列
stateful=False, # 布尔值,True:将batch中索引i的每个样本的最后状态用作下一个batch中索引i的样本的初始状态
unroll=False, # 布尔值,True:展开网络,False:使用符号循环。展开可以加快RNN的速度,但是会占用更多内存。展开仅适用于短序列
time_major=False, # 布尔值,表示输入和输出张量的形状格式。True:输入和输出的形状为 (timesteps, batch, ...),False: (batch, timesteps, ...)
**kwargs
) 调用参数有:
- input:输入张量
- mask:形状为 [batch_size, timesteps] 的二进制张量,指示是否屏蔽给定的timestep
- training:布尔值,指示该层是在训练模式还是在推理模式下运行。该参数在调用时被传递到cell。适用于使用dropout的cells
- initial_state:要传递给第一个调用的cell的初始状态张量列表
- constants:在每个timestep传递到cell的恒定张量列表
Input shape:
- N维的张量,默认形状为 [batch_size, timesteps, ...]。当time_major=True时,形状为 [timesteps, batch_size, ...]。
Output shape:
- 如果 return_state=True:张量列表。第一个张量是输出。其余的张量是最后一个隐含层的状态,形状为 [batch_size, state_size],其中state_size可以是高维张量形状。
- 如果 return_sequences=True:形状为 [batch_size, timesteps, output_size]的N维张量,其中output_size可以是高维张量形状。当time_major=True时,形状为 [timesteps, batch_size, output_size]。
- 其它情况,形状为 [batch_size, output_size]的N维张量,其中output_size可以是高维张量形状。
Masking:
- 该层支持对输入数据进行可变数量的timestep的屏蔽。如果要引入数据屏蔽,请使用一个 [tf.keras.layers.Embedding] 层,并将其mask_zero参数设置为True。
应用实例:
import tensorflow as tf
cell = tf.keras.layers.SimpleRNNCell(32)
x = tf.keras.Input((None, 5))
layer = tf.keras.layers.RNN(cell)
y = layer(x)
print(y.shape)
# Here's how to use the cell to build a stacked RNN:
cell1 = tf.keras.layers.SimpleRNNCell(32)
cell2 = tf.keras.layers.SimpleRNNCell(64)
cells = [cell1, cell2]
x = tf.keras.Input((None, 5))
layer = tf.keras.layers.RNN(cells)
y = layer(x)
print(y.shape)
此外,从3.2.1节和3.2.2节中的官方实例可以看出,tf.keras.layers.RNN不仅可以完成SimpleRNNCell基本单元的堆叠,还可以完成LSTMCell基本单元的堆叠。
除此之外,还可以使用tf.keras.layers.SimpleRNN和tf.keras.layers.LSTM,在不借助tf.keras.layers.RNN的情况下完成RNN cell和LSTM cell在时间维度上的扩展。
3.3.2 tf.keras.layers.SimpleRNN
全连接的RNN,其输出将被反馈到输入。部分继承自tf.keras.layers.RNN。
其参数如下:
tf.keras.layers.SimpleRNN(
units, # 正整数,输出空间的维度,即隐含层神经元的数量
activation='tanh', # 激活函数,默认为"tanh"。如果设置为None,则不使用任何激活(即线性激活,a(x)=x)
use_bias=True, # 布尔值,该层是否使用偏置矢量
kernel_initializer='glorot_uniform', # 输入和隐含层之间权重矩阵的初始化
recurrent_initializer='orthogonal', # 隐含层之间的权重矩阵的初始化
bias_initializer='zeros', # 偏置矢量的初始化
kernel_regularizer=None, # 输入和隐含层之间权重矩阵的正则化函数
recurrent_regularizer=None, # 隐含层之间的权重矩阵的正则化函数
bias_regularizer=None, # 偏置矢量的正则化函数
activity_regularizer=None, # 层输出(它的激活值)的正则化函数
kernel_constraint=None, # 输入和隐含层之间权重矩阵的约束函数
recurrent_constraint=None, # 隐含层之间的权重矩阵的约束函数
bias_constraint=None, # 偏置矢量的约束函数
dropout=0.0, # float,在0~1之间取值,输入层线性变换时要丢弃的unit的比例
recurrent_dropout=0.0, # float,在0~1之间取值,隐含层线性变换时要丢弃的unit的比例
return_sequences=False, # 布尔值,True:返回完整的输出序列,False:仅返回输出序列中的最后一个输出
return_state=False, # 布尔值,True:返回最后一个隐含层的状态,False:不返回
go_backwards=False, # 布尔值,True:反向处理输入序列并返回反向的序列
stateful=False, # 布尔值,True:将batch中索引i的每个样本的最后状态用作下一个batch中索引i的样本的初始状态
unroll=False, # 布尔值,True:展开网络,False:使用符号循环。展开可以加快RNN的速度,但是会占用更多内存。展开仅适用于短序列
**kwargs
)调用参数:
- input:三维张量,形状为 [batch, timesteps, feature]
- mask:形状为 [batch, timesteps] 的二进制张量,指示是否屏蔽给定的timestep
- training:布尔值,指示该层是在训练模式还是在推理模式下运行。该参数在调用时被传递到cell。仅在使用dropout或者recurrent_dropout才相关。
- initial_state:要传递给第一个调用的cell的初始状态张量列表
应用实例:
inputs = np.random.random([32, 10, 8]).astype(np.float32)
simple_rnn = tf.keras.layers.SimpleRNN(4)
output = simple_rnn(inputs) # The output has shape `[32, 4]`.
simple_rnn = tf.keras.layers.SimpleRNN(
4, return_sequences=True, return_state=True)
# whole_sequence_output has shape `[32, 10, 4]`.
# final_state has shape `[32, 4]`.
whole_sequence_output, final_state = simple_rnn(inputs)3.3.3 tf.keras.layers.LSTM
长短期记忆层--Hochreiter 1997。部分继承自tf.keras.layers.RNN。
其参数如下:
tf.keras.layers.LSTM(
units, # 正整数,输出空间的维度,即隐含层神经元的数量
activation='tanh', # 激活函数,默认为"tanh"。如果设置为None,则不使用任何激活(即线性激活,a(x)=x)
recurrent_activation='sigmoid', # 门激活函数
use_bias=True, # 布尔值,该层是否使用偏置矢量
kernel_initializer='glorot_uniform', # 输入和隐含层之间权重矩阵的初始化
recurrent_initializer='orthogonal', # 隐含层之间的权重矩阵的初始化
bias_initializer='zeros', # 偏置矢量的初始化
unit_forget_bias=True, # 布尔值,若为True,则在初始化时将1加到遗忘门的偏置上。将其设为True还将强制bias_initializer="zeros"
kernel_regularizer=None, # 输入和隐含层之间权重矩阵的正则化函数
recurrent_regularizer=None, # 隐含层之间的权重矩阵的正则化函数
bias_regularizer=None, # 偏置矢量的正则化函数
activity_regularizer=None, # 层输出(它的激活值)的正则化函数
kernel_constraint=None, # 输入和隐含层之间权重矩阵的约束函数
recurrent_constraint=None, # 隐含层之间的权重矩阵的约束函数
bias_constraint=None, # 偏置矢量的约束函数
dropout=0.0, # float,在0~1之间取值,输入层线性变换时要丢弃的unit的比例
recurrent_dropout=0.0, # float,在0~1之间取值,隐含层线性变换时要丢弃的unit的比例
implementation=2, # 实现模式,取值为1或者2。模式1会将其操作构造为大量较小的点积和加法运算,而模式2(默认)会将其分为更少的较大操作
return_sequences=False, # 布尔值,True:返回完整的输出序列,False:仅返回输出序列中的最后一个输出
return_state=False, # 布尔值,True:返回最后一个隐含层的状态,False:不返回
go_backwards=False, # 布尔值,True:反向处理输入序列并返回反向的序列
stateful=False, # 布尔值,True:将batch中索引i的每个样本的最后状态用作下一个batch中索引i的样本的初始状态
time_major=False, # 布尔值,表示输入和输出张量的形状格式。True:输入和输出的形状为 (timesteps, batch, ...),False: (batch, timesteps, ...)
unroll=False, # 布尔值,True:展开网络,False:使用符号循环。展开可以加快RNN的速度,但是会占用更多内存。展开仅适用于短序列
**kwargs
)调用参数:
- input:三维张量,形状为 [batch, timesteps, feature]
- mask:形状为 [batch, timesteps] 的二进制张量,指示是否屏蔽给定的timestep(可选的,默认为 None)
- training:布尔值,指示该层是在训练模式还是在推理模式下运行。该参数在调用时被传递到cell。仅在使用dropout或者recurrent_dropout才相关。(可选的,默认为 None)
- initial_state:要传递给第一个调用的cell的初始状态张量列表(可选的,默认为 None,即创建全零的初始状态张量)
应用实例:
inputs = tf.random.normal([32, 10, 8])
lstm = tf.keras.layers.LSTM(4)
output = lstm(inputs)
print(output.shape)
lstm = tf.keras.layers.LSTM(4, return_sequences=True, return_state=True)
whole_seq_output, final_memory_state, final_carry_state = lstm(inputs)
print(whole_seq_output.shape, final_memory_state.shape, final_carry_state.shape)
基于可用的运行时硬件和约束,该层将选择不同的实现(基于cuDNN或纯TensorFlow)以最大限度地提高性能。如果有可用GPU,并且该层的所有参数都满足CuDNN内核的要求(详见下文),则该层将使用一个快速的CuDNN实现。
使用cuDNN实现的要求为:
- activation == tanh
- recurrent_activation == sigmoid
- recurrent_dropout == 0
- unroll == False
- use_bias == True
- Inputs, if use masking, are strictly right-padded.
- Eager execution is enabled in the outermost context.
3.4 多层RNN的堆叠(堆叠隐含层层数)
正如我们可以增加CNN网络的深度一样,我们同样可以通过增加RNN深度的方法提升它的能力。具体来说就是堆叠网络中的隐含层层数,如下图所示。
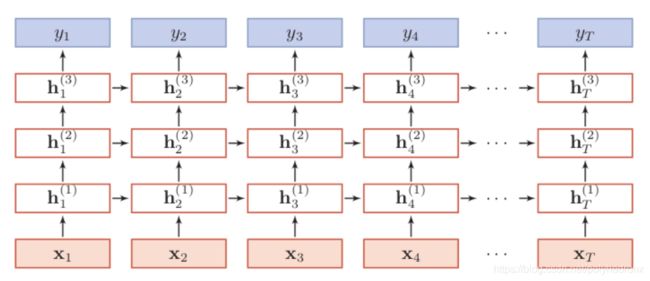
以上是按时间展开的堆叠循环神经网络。一般地,定义![]() 为在时刻t时第l层隐含层的状态,它是由t-1时刻第l层隐含层的状态以及t时刻第l-1层隐含层的状态共同决定的,
为在时刻t时第l层隐含层的状态,它是由t-1时刻第l层隐含层的状态以及t时刻第l-1层隐含层的状态共同决定的,
![]()
其中,![]() 、
、 为权重矩阵,
为权重矩阵,![]() 是偏置,
是偏置,![]() 。
。
在tensorflow中,可以使用tf.keras.layers.StackedRNNCells函数对RNN单元进行堆叠,函数参数如下:
tf.keras.layers.StackedRNNCells(
cells, # RNN单元实例列表
**kwargs
)tf.keras.layers.StackedRNNCells是一个封装器,可以将一堆RNN单元封装为一个单元,然后再通过tf.keras.layers.RNN展开时间维度。
应用实例:
import tensorflow as tf
batch_size = 32
sentence_max_length = 10
n_features = 100
x = tf.random.normal([batch_size, sentence_max_length, n_features])
hidden_dim = 128 # 隐含层维度
n_hidden_layer = 3 # 隐含层层数
rnn_cells = [tf.keras.layers.LSTMCell(hidden_dim) for _ in range(n_hidden_layer)] # RNN单元实例列表
stacked_lstm = tf.keras.layers.StackedRNNCells(rnn_cells)
print(stacked_lstm.state_size) # 三个隐含层状态,每个隐含层状态的大小为 [128, 128]
lstm_layer = tf.keras.layers.RNN(stacked_lstm)
result = lstm_layer(x)
print(result.shape)
4. Char RNN的Tensorflow实现
首先要吐槽一下,Tensorflow1.0到2.0版本的变化太大了,很多1.0版本的代码已经不能直接用了,所以为了让自己逐渐适应变化,打算先用Tensorflow2.0复现一下之前一篇博客的内容(TensorFlow实战笔记之(2):简单神经网络 实现手写数字识别),熟悉一下手感(笑哭脸),不感兴趣的话,4.1节和4.2节可以直接跳过。
4.1 简单神经网络 实现手写数字识别 -- Tensorflow2.0 实现
话不多说,先贴代码:
from tensorflow import keras
from tensorflow.keras import layers
# 构建模型 (keras 函数式API)
# 输入层:输入为28×28的图片,转换成向量后长度为784
inputs = keras.Input(shape=(784,), name="digits")
# 两层隐含层,神经元个数为64,激活函数为ReLU
h1 = layers.Dense(64, activation="relu", name="dense_1")(inputs)
h2 = layers.Dense(64, activation="relu", name="dense_2")(h1)
# 输出层,神经元个数为10,激活函数为Softmax
outputs = layers.Dense(10, activation='softmax', name="predictions")(h2)
# 通过在层计算图中指定模型的输入和输出来创建Model
model = keras.Model(inputs=inputs, outputs=outputs, name="mnist_model")
# 打印模型摘要
model.summary()
# 将模型绘制为计算图
keras.utils.plot_model(model, "mnist_model_with_shape.png", show_shapes=True)
# 生成训练和测试数据
path = 'D:/MyFiles/python/PycharmProjects/RNN/Char RNN/data/mnist.npz'
# x_train:(60000, 28, 28), y_train:(60000,),x_test:(10000, 28, 28), y_test:(10000,)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data(path)
# 数据处理
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# 指定训练配置(优化器、损失、指标)
model.compile(
optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 模型在训练和测试期间要评估的指标列表
metrics=["accuracy"]
)
# 模型训练
# 返回的history对象保留训练期间的损失值和指标值记录
history = model.fit(
x_train,
y_train,
# 每次梯度更新使用的样本数,迭代iteration次以遍历全部训练样本
batch_size=64,
# 单次epoch = 全部训练样本/batch_size/iteration = 1
epochs=2,
# 详细模式,0 = silent, 1 = progress bar, 2 = one line per epoch
verbose=2,
# 训练数据中用作验证数据的比例。模型不会对这部分数据进行训练,在每个epoch结束时会根据这部分验证数据评估损失(loss)和模型指标(metrics)
validation_split=0.2
)
# 根据测试数据评估模型
test_scores = model.evaluate(x_test, y_test, verbose=2)
print("Test loss:", test_scores[0])
print("Test accuracy:", test_scores[1])
# 根据模型对输入进行预测
x_pre = x_test[:3]
predictions = model.predict(x_pre)
print("predictions shape:", predictions.shape)
# 保存模型
model.save("mnist_model")
下面针对程序中的一些重点模块进行详细描述。
4.1.1 构建模型
这里是使用的keras 函数式API进行模型构建,同样地,我们可以使用keras Sequential API构建模型:
model = keras.Sequential()
model.add(keras.Input(shape=(784,)))
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
model.summary()它等价于:
model = keras.Sequential(
[
keras.Input(shape=(784,)),
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
model.summary()PS:函数式API比Sequential API的模型创建方式更加灵活,函数式API可以处理具有非线性拓扑的模型、具有共享层的模型,以及具有多个输入或输出的模型。 如果想要了解更多,请参考官方文档:
https://www.tensorflow.org/guide/keras/sequential_model
https://www.tensorflow.org/guide/keras/functional
4.1.2 生成训练和测试数据
数据集使用MNIST,由数万张28像素×28像素的手写数字组成,这些图片只包含灰度值信息。它的调用方式为:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# x_train:(60000, 28, 28), y_train:(60000,),x_test:(10000, 28, 28), y_test:(10000,)在执行该语句时,程序会从链接 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz下载mnist数据集,但是我由于网络原因一直下载不了,解决方法就是先从这个链接把 mnist.npz 文件下载下来,保存到本地文件夹,然后使用下面的方式调用:
path = 'D:/MyFiles/python/PycharmProjects/RNN/Char RNN/data/mnist.npz' # 保存mnist文件的本地路径
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data(path)4.1.3 模型训练配置 model.compile
该部分用于指定模型训练所用的优化器、损失函数和评估指标等。
compile(
optimizer='rmsprop', # string(优化器名称)或优化器实例,详见tf.keras.optimizers
loss=None, # string(目标函数名称),目标函数,或者tf.keras.losses.Loss实例,详见tf.keras.losses
metrics=None, # 模型在训练和测试期间需要评估的指标的列表。string(内置函数名称),函数,或者tf.keras.metrics.Metric实例,详见tf.keras.metrics。一般设置为 metrics=['accuracy']
loss_weights=None, # (可选的)列表或字典,指定标量系数,用以加权不同模型输出的损耗贡献值
weighted_metrics=None, # 在训练和测试期间要通过sample_weight或class_weight评估和加权的指标列表
run_eagerly=None, # 布尔值,默认为False。如果为True,则该Model的逻辑不会包装在tf.function中
steps_per_execution=None, # int,默认值为1。每个tf.function调用期间要运行的batch数
**kwargs # 仅支持向后兼容的参数
)常用的优化器有:
# Keras优化器的基类
tf.keras.optimizers.Optimizer(
name, gradient_aggregator=None, gradient_transformers=None, **kwargs
)
# 实现Adadelta算法的优化器
tf.keras.optimizers.Adadelta(
learning_rate=0.001, rho=0.95, epsilon=1e-07, name='Adadelta',
**kwargs
)
# 实现Adagrad算法的优化器
tf.keras.optimizers.Adagrad(
learning_rate=0.001, initial_accumulator_value=0.1, epsilon=1e-07,
name='Adagrad', **kwargs
)
# 实现Adam算法的优化器
tf.keras.optimizers.Adam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
name='Adam', **kwargs
)
# 实现Adamax算法的优化器
tf.keras.optimizers.Adamax(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07,
name='Adamax', **kwargs
)
# 实现FTRL算法的优化器
tf.keras.optimizers.Ftrl(
learning_rate=0.001, learning_rate_power=-0.5, initial_accumulator_value=0.1,
l1_regularization_strength=0.0, l2_regularization_strength=0.0,
name='Ftrl', l2_shrinkage_regularization_strength=0.0, beta=0.0,
**kwargs
)
# 实现NAdam算法的优化器
tf.keras.optimizers.Nadam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07,
name='Nadam', **kwargs
)
# 实现RMSprop算法的优化器
tf.keras.optimizers.RMSprop(
learning_rate=0.001, rho=0.9, momentum=0.0, epsilon=1e-07, centered=False,
name='RMSprop', **kwargs
)
# 梯度下降(带动量)优化器
tf.keras.optimizers.SGD(
learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs
)常用的损失函数有:
# Loss基类
tf.keras.losses.Loss(
reduction=losses_utils.ReductionV2.AUTO, name=None
)
# 计算真实标签和预测标签之间的交叉熵损失
tf.keras.losses.BinaryCrossentropy(
from_logits=False, label_smoothing=0, reduction=losses_utils.ReductionV2.AUTO,
name='binary_crossentropy'
)
# 计算标签和预测之间的交叉熵损失
tf.keras.losses.CategoricalCrossentropy(
from_logits=False, label_smoothing=0, reduction=losses_utils.ReductionV2.AUTO,
name='categorical_crossentropy'
)
# 计算y_true和y_pred之间的分类hinge loss
tf.keras.losses.CategoricalHinge(
reduction=losses_utils.ReductionV2.AUTO, name='categorical_hinge'
)
# 计算标签和预测之间的余弦相似度
tf.keras.losses.CosineSimilarity(
axis=-1, reduction=losses_utils.ReductionV2.AUTO,
name='cosine_similarity'
)
# 计算y_true和y_pred之间的hinge loss
tf.keras.losses.Hinge(
reduction=losses_utils.ReductionV2.AUTO, name='hinge'
)
# 计算y_true和y_pred之间的Huber loss
tf.keras.losses.Huber(
delta=1.0, reduction=losses_utils.ReductionV2.AUTO, name='huber_loss'
)
# 计算y_true和y_pred之间的KL散度损失
tf.keras.losses.KLDivergence(
reduction=losses_utils.ReductionV2.AUTO, name='kl_divergence'
)
# 计算预测误差的双曲余弦的对数
tf.keras.losses.LogCosh(
reduction=losses_utils.ReductionV2.AUTO, name='log_cosh'
)
# 计算标签和预测之间的绝对差的平均值
tf.keras.losses.MeanAbsoluteError(
reduction=losses_utils.ReductionV2.AUTO, name='mean_absolute_error'
)
# 计算y_true和y_pred之间的平均绝对百分比误差
tf.keras.losses.MeanAbsolutePercentageError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_absolute_percentage_error'
)
# 计算标签和预测之间的均方误差
tf.keras.losses.MeanSquaredError(
reduction=losses_utils.ReductionV2.AUTO, name='mean_squared_error'
)
# 计算y_true和y_pred之间的均方对数误差
tf.keras.losses.MeanSquaredLogarithmicError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_squared_logarithmic_error'
)
# 计算y_true和y_pred之间的泊松损失
tf.keras.losses.Poisson(
reduction=losses_utils.ReductionV2.AUTO, name='poisson'
)
# 计算标签和预测之间的交叉熵损失
tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=False, reduction=losses_utils.ReductionV2.AUTO,
name='sparse_categorical_crossentropy'
)
# 计算y_true和y_pred之间的平方hinge loss
tf.keras.losses.SquaredHinge(
reduction=losses_utils.ReductionV2.AUTO, name='squared_hinge'
)
评估指标有:
太多了,就不一一列举了,感兴趣的话请查看官方文档:https://www.tensorflow.org/api_docs/python/tf/keras/metrics
4.1.4 模型训练 model.fit
该函数用于在数据集上迭代训练模型。
fit(
x=None, # 输入数据
y=None, # 目标数据
batch_size=None, # 每次梯度更新使用的样本数。将全部训练样本分为大小为batch_size的iteration份,迭代运行iteration次为1个epoch
epochs=1, # 训练模型epochs轮
verbose=1, # 训练模型过程中窗口提示信息的模式,0 = silent, 1 = progress bar, 2 = one line per epoch
callbacks=None, # 训练期间要应用的callbacks列表
validation_split=0.0, # 0到1之间的float值。训练数据中用作验证数据的比例。模型不会对这部分数据进行训练,在每个epoch结束时会根据这部分验证数据评估损失(loss)和模型指标(metrics)
validation_data=None, # 在每个epoch结束时用于评估损失和模型指标的验证数据
shuffle=True, # 布尔值(是否在每个epoch之前打乱训练数据),或者str(用于batch)
class_weight=None, # (可选的)字典。映射类索引(整数)为权重值(float),用于加权损失函数(仅在训练期间)
sample_weight=None, # (可选的)numpy数组。训练样本的权重,用于加权损失函数(仅在训练期间)
initial_epoch=0, # 整数。开始训练的epoch(用于恢复以前的训练运行)
steps_per_epoch=None, # 整数或None。默认为None,等于数据集中的样本数除以batch_size
validation_steps=None, # 验证集的steps(概念和上一条类似)。仅当提供validation_data且为tf.data数据集时才有用
validation_batch_size=None, # 整数或None。验证集的batch大小
validation_freq=1, # 整数或collections_abc.Container实例。仅在提供验证数据时有用。如果是整数,则指定经过多少个epoch才执行一次验证;如果是Container,则指定要运行验证的epoch
max_queue_size=10, # 整数。生成器序列的最大size。仅用于生成器或者keras.utils.Sequence输入
workers=1, # 整数。使用基于进程的线程时,要启动的最大进程数。仅用于生成器或者keras.utils.Sequence输入
use_multiprocessing=False # 布尔值。如果为True,则使用基于进程的线程。仅用于生成器或者keras.utils.Sequence输入
)函数的返回值为一个History对象,它的History.history属性记录了训练期间的损失值和指标值,以及验证集的损失值和指标值(如果有验证集)。
4.1.5 模型评估 model.evaluate
调用该函数以返回测试模式下模型的损失值和指标值。
evaluate(
x=None, # 输入数据
y=None, # 目标数据
batch_size=None, # 每batch的样本数
verbose=1, # 0 = silent, 1 = progress bar, 2 = one line per epoch
sample_weight=None, # (可选的)numpy数组。训练样本的权重,用于加权损失函数
steps=None, # 整数或None。模型评估结束时运行的batch的个数
callbacks=None, # 评估期间要应用的callbacks列表
max_queue_size=10, # 整数。生成器序列的最大size。仅用于生成器或者keras.utils.Sequence输入
workers=1, # 整数。使用基于进程的线程时,要启动的最大进程数。仅用于生成器或者keras.utils.Sequence输入
use_multiprocessing=False # 布尔值。如果为True,则使用基于进程的线程。仅用于生成器或者keras.utils.Sequence输入
return_dict=False # 如果为True,损失和指标结果作为dict返回;如果为False,则作为list返回
)函数的返回值为标量测试集损失(如果模型只有单个输出且没有指标值)或一个标量列表(如果模型有多个输出 和/或 指标值)。
4.1.6 模型预测 model.predict
生成输入样本的预测输出。
predict(
x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10,
workers=1, use_multiprocessing=False
)函数的返回值为numpy数组。
更多和Model相关的Methods请查阅官方文档:https://www.tensorflow.org/api_docs/python/tf/keras/Model
4.2 RNN实现手写数字识别 -- Tensorflow2.0 实现
这个和4.1节类似,直接放代码,就不解释了。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
class MnistRNN:
def __init__(self, batch_size=64, lstm_size=64,
input_dim=28, output_size=10, allow_cudnn_kernel=False):
self.batch_size = batch_size
self.lstm_size = lstm_size
self.input_dim = input_dim
self.output_size = output_size
self.allow_cudnn_kernel = allow_cudnn_kernel
self.model = keras.Sequential()
self.build_model()
# 构建模型
def build_model(self):
# CuDNN is only available at the layer level, and not at the cell level.
# This means `LSTM(units)` will use the CuDNN kernel,
# while RNN(LSTMCell(units)) will run on non-CuDNN kernel.
if self.allow_cudnn_kernel:
# The LSTM layer with default options uses CuDNN.
lstm_layer = layers.LSTM(self.lstm_size, input_shape=(None, self.input_dim))
else:
# Wrapping a LSTMCell in a RNN layer will not use CuDNN.
lstm_layer = layers.RNN(layers.LSTMCell(self.lstm_size), input_shape=(None, self.input_dim))
self.model = keras.Sequential(
[
lstm_layer,
layers.BatchNormalization(),
layers.Dense(self.output_size),
]
)
# 训练模型
def train(self, x_train, y_train, x_test, y_test):
# 指定训练配置(优化器、损失、指标)
self.model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="sgd",
metrics=["accuracy"],
)
# 模型训练
self.model.fit(
x_train, y_train,
validation_data=(x_test, y_test),
batch_size=self.batch_size,
epochs=1
)
def main():
# 参数设置
batch_size = 64
# Each MNIST image batch is a tensor of shape (batch_size, 28, 28).
# Each input sequence will be of size (28, 28) (height is treated like time).
input_dim = 28
lstm_size = 64
output_size = 10 # labels are from 0 to 9
# 加载MNIST数据集
path = 'D:/MyFiles/python/PycharmProjects/RNN/Char RNN/data/mnist.npz'
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data(path)
x_train, x_test = x_train / 255.0, x_test / 255.0
sample, sample_label = x_train[1], y_train[1] # 一个样本
# 搭建并训练模型
model = MnistRNN(
batch_size=batch_size,
lstm_size=lstm_size,
input_dim=input_dim,
output_size=output_size,
allow_cudnn_kernel=False
)
model.train(x_train, y_train, x_test, y_test)
# 模型测试
result = tf.argmax(model.model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)
print("Predicted result is: %s, target result is: %s" % (result.numpy(), sample_label))
plt.imshow(sample, cmap=plt.get_cmap("gray"))
plt.show()
if __name__ == '__main__':
main()
4.3 (真)Char RNN -- Tensorflow2.0 实现
这里以莎士比亚作品的数据集为例,介绍使用char RNN生成文本的方法。下面先逐一介绍,最后再贴出代码。
4.3.1 获取数据
你可以通过下面的代码下载并读取莎士比亚数据集。
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
# 读取并为 py2 compat 解码
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# 文本长度是指文本中的字符个数
print('Length of text: {} characters'.format(len(text)))如果因为网络原因下载不了,可以先在网页中打开此链接,手动复制到本地 shakespeare.txt 文件中,然后使用下面的方法读取。
input_file = 'data/shakespeare.txt'
with codecs.open(input_file, encoding='utf-8') as f: # 打开文件,并转换为utf8编码
text = f.read()
print('Length of text: {} characters'.format(len(text)))4.3.2 处理文本
- 向量化文本
在训练之前,我们需要将字符串映射到数字表示值。创建两个查找表格:一个将字符映射到数字,另一个将数字映射到字符。
# 文本中的非重复字符
vocab = sorted(set(text))
print('{} unique characters'.format(len(vocab)))
# 创建从非重复字符到索引的映射
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])现在,每个字符都有一个整数表示值。请注意,我们将字符映射至索引 0 至 len(unique).
# 打印前20个字符
print('{')
for char,_ in zip(char2idx, range(20)):
print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))
print(' ...\n}')# 显示文本首 13 个字符的整数映射
print ('{} ---- characters mapped to int ---- > {}'.format(repr(text[:13]), text_as_int[:13]))- 创建训练样本和目标
接下来,将文本划分为样本序列。每个输入序列包含文本中的 seq_length 个字符。
对于每个输入序列,其对应的目标包含相同长度的文本,但是向右顺移一个字符。
将文本拆分为长度为 seq_length+1 的文本块。例如,假设 seq_length 为 4 而且文本为 “Hello”, 那么输入序列将为 “Hell”,目标序列将为 “ello”。
# 设定每个输入句子长度的最大值
seq_length = 100
examples_per_epoch = len(text)//seq_length
# 创建训练样本 / 目标
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
# 打印第一批样本的输入与目标值
for input_example, target_example in dataset.take(1):
print ('Input data: ', repr(''.join(idx2char[input_example.numpy()])))
print ('Target data:', repr(''.join(idx2char[target_example.numpy()])))Input data: 'First Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou'
Target data: 'irst Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou '
这些向量的每个索引均作为一个时间步来处理。作为时间步 0 的输入,模型接收到 “F” 的索引,并尝试预测 “i” 的索引为下一个字符。在下一个时间步,模型执行相同的操作,但是 RNN 不仅考虑当前的输入字符,还会考虑上一步的信息。
- 创建训练批次
前面我们使用 tf.data 将文本拆分为可管理的序列。但是在把这些数据输送至模型之前,我们需要将数据重新排列 (shuffle) 并打包为批次。
# 批大小
batch_size = 64
# 设定缓冲区大小,以重新排列数据集
# (TF 数据被设计为可以处理可能是无限的序列,
# 所以它不会试图在内存中重新排列整个序列。相反,
# 它维持一个缓冲区,在缓冲区重新排列元素。)
buffer_size = 10000
dataset = dataset.shuffle(buffer_size).batch(batch_size, drop_remainder=True)
此时dataset的属性值为:
4.3.3 创建模型
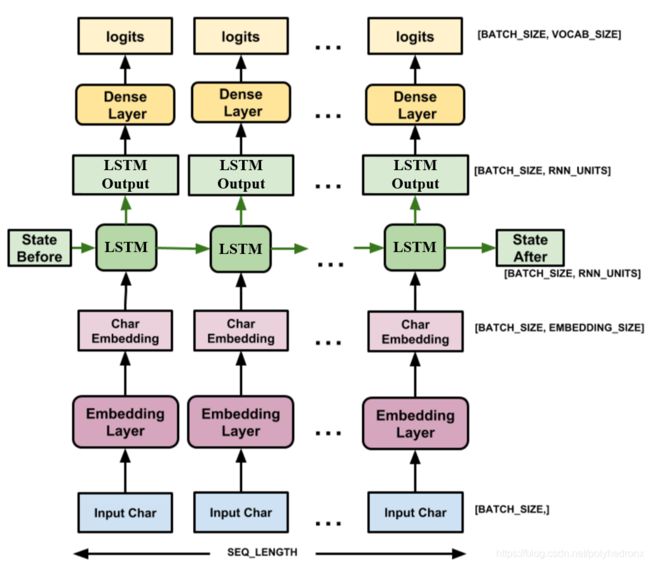
使用 tf.keras.Sequential 定义模型。在这个简单的例子中,我们使用了三个层来定义模型:
tf.keras.layers.Embedding:输入层。一个可训练的对照表,它会将每个字符的数字映射到一个embedding_dim维度的向量。- tf.keras.layers.LSTM:一种 RNN 类型,其大小由
units=rnn_units指定。 tf.keras.layers.Dense:输出层,带有vocab_size个输出。
# 词集的长度
vocab_size = len(vocab)
# 嵌入的维度
embedding_dim = 256
# RNN 的单元数量
rnn_units = 1024def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, batch_input_shape=[batch_size, None]),
tf.keras.layers.RNN(layers.LSTMCell(self.rnn_units, recurrent_initializer='glorot_uniform'),
return_sequences=True,
stateful=True),
tf.keras.layers.Dense(vocab_size)
])
return modelmodel = build_model(
vocab_size = len(vocab),
embedding_dim=embedding_dim,
rnn_units=rnn_units,
batch_size=batch_size)
model.summary()对于每个字符,模型会查找嵌入,把嵌入当作输入运行 LSTM 一个时间步,并用密集层生成逻辑回归 (logits),预测下一个字符的对数可能性。
首先检查一下输出的形状:
for input_example_batch, target_example_batch in dataset.take(1):
example_batch_predictions = model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")(64, 100, 65) # (batch_size, sequence_length, vocab_size)
4.3.4 训练模型
此时,这个问题可以被视为一个标准的分类问题:给定先前的 RNN 状态和这一时间步的输入,预测下一个字符的类别。
- 添加优化器和损失函数
标准的 tf.keras.losses.sparse_categorical_crossentropy 损失函数在这里适用,因为它被应用于预测的最后一个维度。
因为我们的模型返回逻辑回归,所以我们需要设定命令行参数 from_logits。
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
example_batch_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("scalar_loss: ", example_batch_loss.numpy().mean())使用 tf.keras.Model.compile 方法配置训练步骤。我们将使用 tf.keras.optimizers.Adam 并采用默认参数,以及损失函数。
model.compile(optimizer='adam', loss=loss)- 配置检查点
使用 tf.keras.callbacks.ModelCheckpoint 来确保训练过程中保存检查点。
# 检查点保存至的目录
checkpoint_dir = './training_checkpoints'
# 检查点的文件名
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)- 执行训练
为保持训练时间合理,使用 10 个周期来训练模型。
epochs = 10
history = model.fit(dataset, epochs=epochs, callbacks=[checkpoint_callback])4.3.5 生成文本
- 恢复最新的检查点
为保持此次预测步骤简单,将批大小设定为 1。
由于 RNN 状态从时间步传递到时间步的方式,模型建立好之后只接受固定的批大小。
若要使用不同的 batch_size 来运行模型,我们需要重建模型并从检查点中恢复权重。
model = build_model(vocab_size, embedding_dim, rnn_units, batch_size=1)
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model.build(tf.TensorShape([1, None]))
model.summary()- 预测循环
下面的代码块生成文本:
-
首先设置起始字符串,初始化 RNN 状态并设置要生成的字符个数。
-
用起始字符串和 RNN 状态,获取下一个字符的预测分布。
-
然后,用分类分布计算预测字符的索引。把这个预测字符当作模型的下一个输入。
-
模型返回的 RNN 状态被输送回模型。现在,模型有更多上下文可以学习,而非只有一个字符。在预测出下一个字符后,更改过的 RNN 状态被再次输送回模型。模型就是这样,通过不断从前面预测的字符获得更多上下文,进行学习。
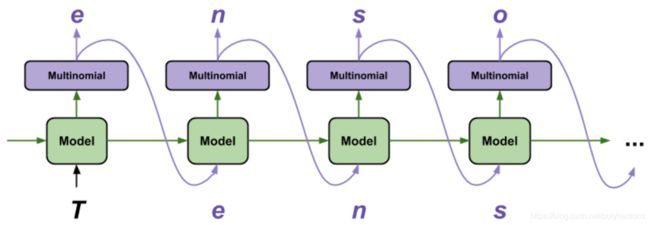
查看生成的文本,你会发现这个模型知道什么时候使用大写字母,什么时候分段,而且模仿出了莎士比亚式的词汇。由于训练的周期小,模型尚未学会生成连贯的句子。
def generate_text(model, start_string):
# 评估步骤(用学习过的模型生成文本)
# 要生成的字符个数
num_generate = 1000
# 将起始字符串转换为数字(向量化)
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
# 空字符串用于存储结果
text_generated = []
# 低温度会生成更可预测的文本
# 较高温度会生成更令人惊讶的文本
# 可以通过试验以找到最好的设定
temperature = 1.0
# 这里批大小为 1
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
# 删除批次的维度
predictions = tf.squeeze(predictions, 0)
# 用分类分布预测模型返回的字符
predictions = predictions / temperature
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
# 把预测字符和前面的隐藏状态一起传递给模型作为下一个输入
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))print(generate_text(model, start_string=u"ROMEO: "))
ROMEO: in't, Romeo rather
say, bid me not say, the adden, and you man for all.
Now, good Cart, or do held. Well, leaving her son,
Some stomacame, brother, Edommen.
PROSPERO:
My lord Hastings, for death,
Or as believell you be accoment.
TRANIO:
Mistraising? come, get abseng house:
The that was a life upon none of the equard sud,
Great Aufidius any joy;
For well a fool, and loveth one stay,
To whom Gare his moved me of Marcius shoulded.
Pite o'erposens to him.
KING RICHARD II:
Come, civil and live, if wet to help and raisen fellow.
CORIOLANUS:
Mark, here, sir. But the palace-hate will be at him in
some wondering danger, my bestilent.
DUKE OF AUMERLE:
You, my lord? my dearly uncles for,
If't be fown'd for truth enough not him,
He talk of youngest young princely sake.
ROMEO:
This let me have a still before the queen
First worthy angel. Would yes, by return.
BAPTISTA:
You have dan,
Dies, renown awrifes; I'll say you.
Provost:
And, come, make it out.
LEONTES:
They call thee, hangions,
Not
若想改进结果,最简单的方式是延长训练时间 (试试epochs=30)。
你还可以试验使用不同的起始字符串,或者尝试增加另一个 RNN 层以提高模型的准确率,亦或调整温度参数以生成更多或者更少的随机预测。
4.3.6 代码
- main.py:主函数,主要用于设置参数等
- read_utils.py:文件的读取、处理,以及生成数据集等
- model.py:模型的搭建、训练,以及利用训练好的模型生成文本等
- main.py
from model import *
import os
def main():
# 参数设置
input_file = 'data/shakespeare.txt'
seq_length = 100 # 每个输入句子的长度,即time_steps
batch_size = 64 # 批大小
rnn_units = 1024 # RNN 的单元数量
embedding_dim = 256 # 嵌入的维度
epochs = 1 # 训练周期
# 配置检查点
checkpoint_dir = './training_checkpoints' # 检查点保存至的目录
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}") # 检查点的文件名
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix, save_weights_only=True)
# 加载数据集
converter, dataset = get_dataset(input_file, batch_size, seq_length)
# 构建并训练模型
model = CharRNN(
vocab_size=converter.vocab_size,
batch_size=batch_size,
rnn_units=rnn_units,
embedding_dim=embedding_dim,
epochs=epochs,
checkpoint_callback=checkpoint_callback
)
model.train(dataset)
# 重建模型并从检查点中恢复权重
model2 = CharRNN(
vocab_size=converter.vocab_size,
batch_size=1,
rnn_units=rnn_units,
embedding_dim=embedding_dim,
)
model2.model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model2.model.build(tf.TensorShape([1, None]))
model2.model.summary()
# 用学习过的模型生成文本
num_generate = 1000 # 要生成的字符个数
print(model2.generate_text(converter, num_generate, start_string=u"ROMEO: "))
if __name__ == '__main__':
main()
- read_utils.py
import tensorflow as tf
import numpy as np
import pickle
import codecs
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
def get_dataset(input_file, batch_size, seq_length, buffer_size=10000):
with codecs.open(input_file, encoding='utf-8') as f: # 打开文件,并转换为utf8编码
text = f.read()
print('Length of text: {} characters'.format(len(text)))
converter = TextConverter(text)
# 创建训练样本 / 目标
text_as_int = converter.text2idx(text)
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
# 将文本拆分为长度为 seq_length+1 的文本块
sequences = char_dataset.batch(seq_length + 1, drop_remainder=True)
# 构建数据集 input_text, target_text
dataset = sequences.map(split_input_target)
dataset = dataset.shuffle(buffer_size).batch(batch_size, drop_remainder=True)
return converter, dataset
class TextConverter(object):
def __init__(self, text=None):
# 文本中的非重复字符
self.vocab = sorted(set(text))
print('{} unique characters'.format(len(self.vocab)))
# 创建从非重复字符到索引的映射
self.char2idx = {u: i for i, u in enumerate(self.vocab)}
self.idx2char = np.array(self.vocab)
@property
def vocab_size(self):
return len(self.vocab)
# 返回某个字符的索引
def char2idx(self, char):
return self.char2idx[char]
# 返回索引对应的字符
def idx2char(self, index):
return self.idx2char[index]
# 将text中的字符映射至索引 0 至 len(unique)
def text2idx(self, text):
return np.array([self.char2idx[c] for c in text])
# 将索引转换为对应的字符
def idx2text(self, arr):
words = []
for index in arr:
words.append(self.idx2char[index])
return "".join(words)
def save_to_file(self, filename):
with open(filename, 'wb') as f:
pickle.dump(self.vocab, f)
- model.py
from tensorflow import keras
from tensorflow.keras import layers
from read_utils import *
class CharRNN:
def __init__(self, vocab_size, batch_size=64,
rnn_units=1024, embedding_dim=256, epochs=1,
checkpoint_callback=None):
self.vocab_size = vocab_size
self.batch_size = batch_size
self.rnn_units = rnn_units
self.embedding_dim = embedding_dim
self.epochs = epochs
self.checkpoint_callback = checkpoint_callback
self.model = keras.Sequential()
self.build_model()
# 构建模型
def build_model(self):
self.model = keras.Sequential([
layers.Embedding(self.vocab_size, self.embedding_dim, batch_input_shape=[self.batch_size, None]),
layers.RNN(layers.LSTMCell(self.rnn_units, recurrent_initializer='glorot_uniform'),
return_sequences=True,
stateful=True),
layers.Dense(self.vocab_size)
])
# self.model.summary()
# keras.utils.plot_model(self.model, "shakespeare_model_with_shape.png", show_shapes=True)
# 定义损失函数
@staticmethod
def loss(labels, logits):
return keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
# 训练模型
def train(self, dataset):
# 指定训练配置(优化器、损失、指标)
self.model.compile(optimizer='adam', loss=self.loss)
# 模型训练
self.model.fit(dataset,
epochs=self.epochs,
callbacks=[self.checkpoint_callback])
# 生成文本
def generate_text(self, converter, num_generate, start_string):
# 将起始字符串转换为数字(向量化)
input_eval = converter.text2idx(start_string)
input_eval = tf.expand_dims(input_eval, 0)
# 空字符串用于存储结果
text_generated = []
# 低温度会生成更可预测的文本,较高温度会生成更令人惊讶的文本,可以通过试验以找到最好的设定
temperature = 1.0
# 这里批大小为 1
self.model.reset_states()
for i in range(num_generate):
predictions = self.model(input_eval)
# 删除批次的维度
predictions = tf.squeeze(predictions, 0)
# 用分类分布预测模型返回的字符
predictions = predictions / temperature
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1, 0].numpy()
# 把预测字符和前面的隐藏状态一起传递给模型作为下一个输入
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(converter.idx2char[predicted_id])
return start_string + ''.join(text_generated)
参考文献
1. 《21个项目玩转深度学习:基于TensorFlow的实践详解》 --何之源著
2. Char RNN原理介绍以及文本生成实践
3. 源码系列01:Keras源码之SimpleRNNCell详解
4. https://www.tensorflow.org/api_docs/python/tf/keras/layers
5. https://www.tensorflow.org/guide/keras/rnn
6. https://www.tensorflow.org/tutorials/text/text_generation