镀金天空- 验证码1
前言:
①仅作学习所用,不可非法利用
②网页结构的变化较多,代码的可用周期较短,仅作学习分享思路
③如有侵权,请联系我删除!!谢谢
正文:
普天同庆,就在年前我终于把镀金天空上的13道题写完了。从我做镀金天空开始,飘飘散散也有三四个月了,期间找工作、忙毕业也耽误了不少时间,最后还是坚持下来写完啦。在镀金天空学到了很多反爬知识,在此感谢群主大大~~。本来是打算过年的时候就把镀金天空系列的解题思路写下来,但是我欢乐的6天春节biu的一下就没了,呜呜呜
言归正传,今天就来讲一讲验证码-1的解题思路吧。这道题和前面的题一样,需要将1000页的数字和加起来。进入页面就是一个验证码,需要将滑块拖到指定位置才可以看到页面的数字。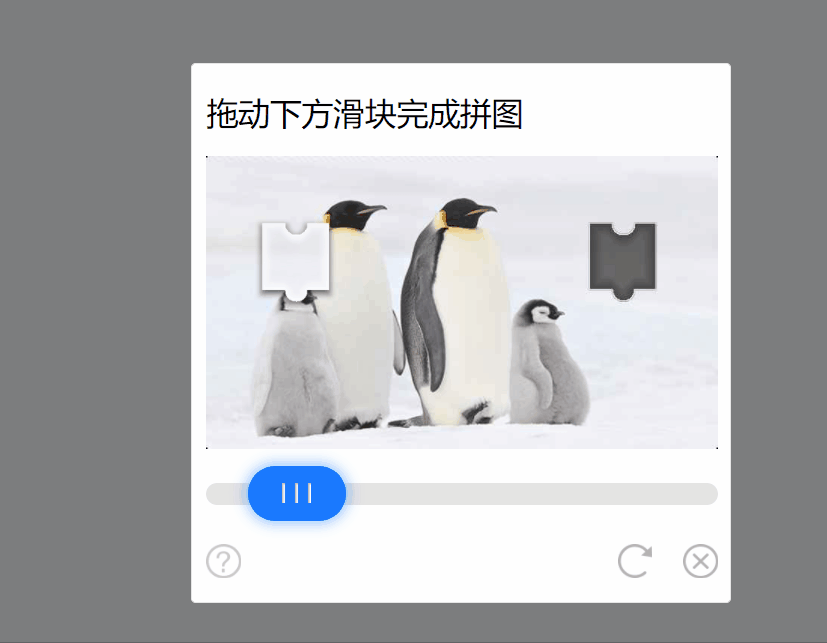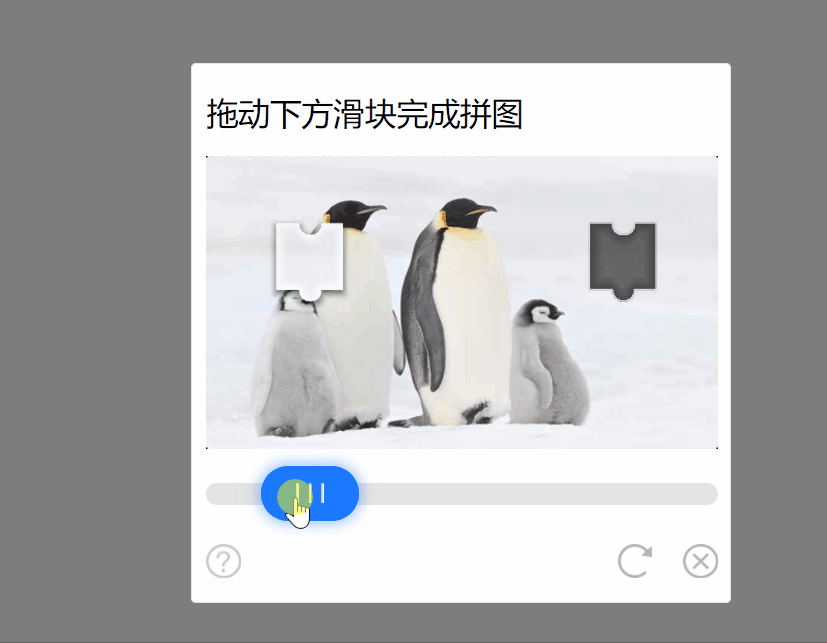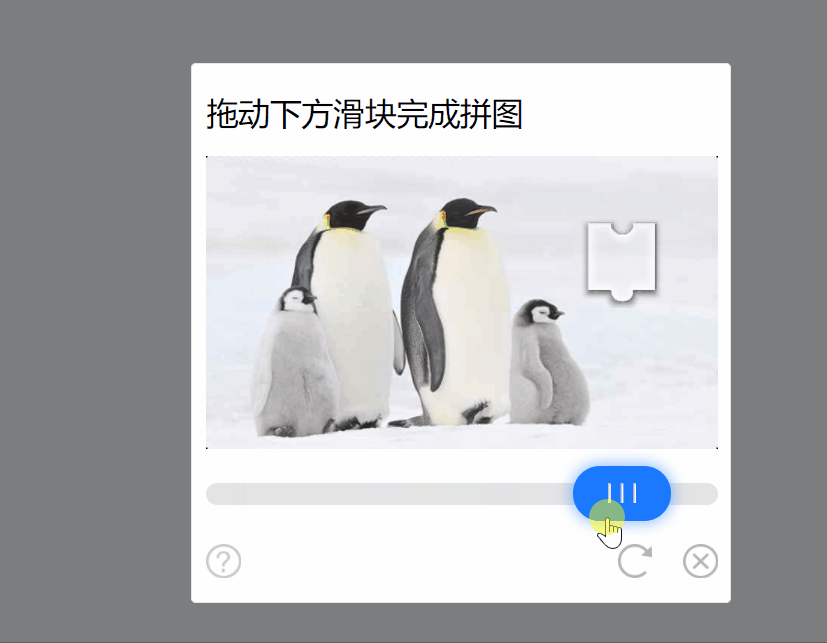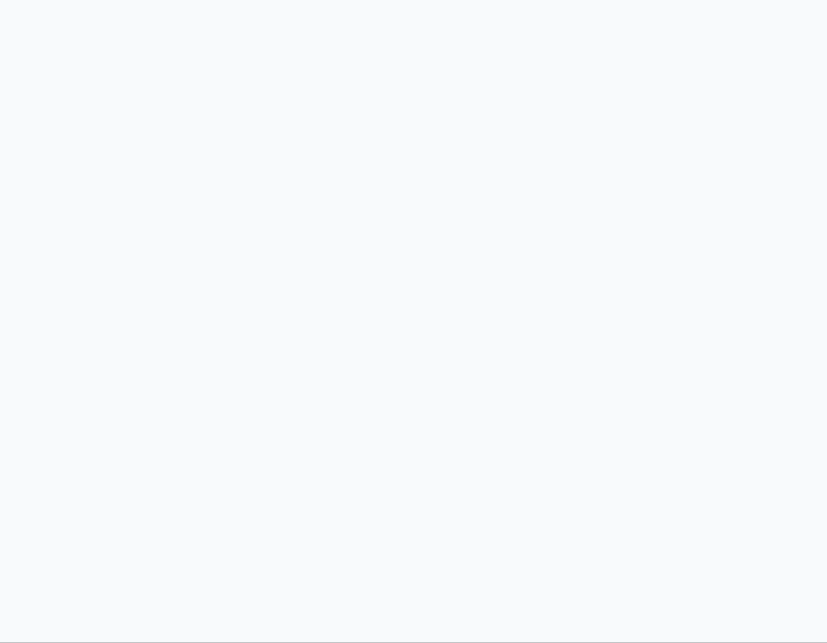
因此这道题主要的难点也就是完成滑块的验证,有两个解决办法:①使用JavaScript自动化渲染库去模拟人的动作滑动滑块完成验证,②分析滑动滑块后的请求,逆向破解验证码的文本内容加密,通过验证码的轨迹验证获取参数( ticket )完成验证。
第二钟方法当然是最好的了,但是博主太菜了,所以采用的是selenium。使用selenium的话可以分为五个各部分
-
登录
-
进入待爬取页面获取验证码背景图片 和 滑块图片
-
用滑块图片匹配背景图片的缺口位置
-
模拟人的滑动
-
解析页面,获取数字累加和
第一步可以直接将cookies注入到浏览器实现登录,当然你也可以从登录页面开始输入账号密码进行登录,这样做的好处是在日后的使用中可以不用自己去赋值cookies,坏处是又慢一点。代码如下:
def getABrower():
# 实例化出一个 浏览器
# options.add_argument("--headless")
window = webdriver.Chrome(chrome_options=options)
# window = webdriver.Chrome()
with open('JS/stealth.min.js') as f:
js = f.read()
window.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
# 设置浏览器窗口的位置和大小
window.maximize_window()
# 打开一个登录页
window.get("http://glidedsky.com/login")
# 输入账号
input_account = window.find_element_by_id('email')
input_account.send_keys('Your Mail')
# 输入密码
input_password = window.find_element_by_id('password')
input_password.send_keys('Your Passwor')
# login
login_button = window.find_elements_by_xpath('//button[@type="submit"]')[0]
login_button.click()
return window
第二步进入到带爬取页面后可以直接使用find_element_by_xpath或者其他的element匹配手段匹配到之后获取src属性就好了,代码如下:
# 大图 url
bk_block = window.find_element_by_xpath(
'//img[@id="slideBg"]').get_attribute('src')
# 小滑块 图片url
slide_block = window.find_element_by_xpath(
'//img[@id="slideBlock"]').get_attribute('src')
第三步可以使用第三库 cv2 的matchTemplate去匹配缺口位置,我发现这个库对腾讯防水墙(本题验证码出处)有着极高的匹配度,hh(差不多有80%+)代码如下:
def getPostion(chunk, canves):
"""
判断缺口位置
:param chunk: 验证码背景图
:param canves: 验证码缺口图
:return: 缺口匹配位置 x, y
"""
otemp = chunk
oblk = canves
target = cv2.imread(otemp, 0)
template = cv2.imread(oblk, 0)
# w, h = target.shape[::-1]
temp = 'temp.jpg'
targ = 'targ.jpg'
cv2.imwrite(temp, template)
cv2.imwrite(targ, target)
target = cv2.imread(targ)
target = cv2.cvtColor(target, cv2.COLOR_BGR2GRAY)
target = abs(255 - target)
cv2.imwrite(targ, target)
target = cv2.imread(targ)
template = cv2.imread(temp)
result = cv2.matchTemplate(target, template, cv2.TM_CCOEFF_NORMED)
x, y = np.unravel_index(result.argmax(), result.shape)
return x, y
第四步模拟人为去滑动滑块,腾讯防水墙是有行为验证的,如果滑动的轨迹过于“工整”是会被怀疑为机器滑动的,无论如何都过不去的。因此轨迹必须拟人或者随机一点,我起初是使用了网上的一个加速度划过缺口之后划回来的方案,后来自己又写了一个真瞎随机的。。。代码如下:
def getTrack3(distance):
"""
返回一个随机滑动轨迹
:param distance: 滑动长度
:return: 滑动轨迹 tracks
"""
length = random.choice(np.arange(15, 25))
avge = int(distance / length)
difference = int(distance - avge * length)
tracks = [avge] * length
# print(distance, sum(tracks)+difference,difference)
ranndomFlag = 0
for i in range(length):
if ranndomFlag:
tracks[random.randint(0, length - 1)] += ranndomFlag
ranndomFlag = 0
if random.choice([False, True]):
if tracks[i] > 1:
ranndomFlag = random.randint(1, tracks[i])
else:
ranndomFlag = random.randint(tracks[i], 1)
tracks[i] -= ranndomFlag
if ranndomFlag:
tracks[random.randint(0, length - 1)] += ranndomFlag
luck = random.randint(0, length - 1)
# 补全损失值
tracks[luck] = tracks[luck] + difference
return tracks
第五步解析文本就不多说了可以使用find_element_by_class_name定位到元素位置获取texj就可以了。我这边使用的是etree.xpath
#用于判断是否验证成功,比较cs2.matchTemplate匹配也有失败的时候
window.find_element_by_class_name('row')
Html = window.page_source
tree = etree.HTML(Html.encode('gbk', 'ignore'))
numList = tree.xpath('//div[@class="row"]/div/text()')
numList = [int(x.replace('\n', '').replace(' ', ''))
for x in numList]
res += sum(numList)
print(pageNum, res, numList)
代码说到这就基本结束了,但是你以为这就完了吗?不不不,远不能如此,如果你按照我上面所说的去写跑了十几分钟之后你就会来骂我,什么坑爹博主啊?按照你的思路写代码跑了20页怎么也划不过去(就算你缺口对的整整齐齐,甚至还很快),你的题不会是抄的吧?
先前我说过一句腾讯防水墙是有行为验证的诸位是否还记得hh,当你使用selenium多次滑动通过验证时,在腾讯防水墙处就会留下指纹,当你滑到大概第20页时就会被定义为机器模拟,我刚开始时怀疑为轨迹不够拟人被发现了,但是当我将window(window = webdriver.Chrome(chrome_options=options))关闭再次开启后发现浏览器的再次滑动就可以通过验证了。
因此当遇到滑块匹配5次还是无法获取到页面的数字时,我们将浏览器重启就可以了。
但是事情并没有就此结束,又又又发生了转折,当你滑动到200页的样子你会发现,当你重启window也没有用了。这个时候我们不要着急,这是你在这段时间验证的太频繁了,腾讯防水墙给你的IP设限了,这个时候你可以更换IP(换Wifi)或者休眠20-30min就又可以一战了。
到这里这道题算是完完整整的解完了,博主跑了7,8个小时。。。。害