35行代码爬取豆瓣top250最全信息,Beautifulsoup(二)
说明
看官多多点赞呀~
上次爬取到了电影名,但远远不够,笔者试图对top250再进行数据分析,因此需要爬到更多的信息。代码如下,应该是CSDN代码量最少最简单的了~
关于怎么保存爬取的数据,参看我之前的博客,很简单的;另外,为防止被封,爬取一页需要短暂的sleep(),我设定的1s
import requests
from bs4 import BeautifulSoup
import time
import re
import pandas as pd
headers = {
'Cookie': 'douban-fav-remind=1; __yadk_uid=CKhB1u3n6xEqzyUBAyvDcIG0qqutnMNR; bid=3tIcGsf0QDM; __gads=ID=8dc5077d330e5d35-22f3e8e3e6c6005d:T=1617088787:RT=1617088787:S=ALNI_MYFQCk-CtmQowxEUgWKzk-nkWX55w; __utmc=30149280; __utmz=30149280.1618455783.8.5.utmcsr=sogou.com|utmccn=(referral)|utmcmd=referral|utmcct=/link; __utmc=223695111; __utmz=223695111.1618455783.6.3.utmcsr=sogou.com|utmccn=(referral)|utmcmd=referral|utmcct=/link; ll="118318"; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1618623032%2C%22https%3A%2F%2Fwww.sogou.com%2Flink%3Furl%3DhedJjaC291PRk6U3MmR8l1gSvBeWzmiQ6zoJDnqY_nQO5VUb2AU5IA..%22%5D; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.193803470.1583831845.1618586080.1618623033.10; __utmb=30149280.0.10.1618623033; __utma=223695111.744523459.1601995022.1618586080.1618623033.8; __utmb=223695111.0.10.1618623033; _vwo_uuid_v2=D7B1C2A974658E5E33A73E04665581A99|349fac20bbf0f95e5ab5e381b8995d91; _pk_id.100001.4cf6=3ded1b2e1c85efc8.1601995022.8.1618623046.1618586085.',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
}
target = []
for i in range(10):
res = requests.get(
'https://movie.douban.com/top250?start='+str(i*25), headers=headers)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='item')
for item in items:
movieName = item.find('span', class_='title').text # 影名
otherName = item.find('span', class_='other').text.replace(
'\xa0/\xa0', '').replace(' / ', ',') # 别名
inq = item.find('span', class_='inq') # 一句话评语
inq = inq.text if inq else inq == '无短评'
rating = item.find('span', class_='rating_num').text # 评分
countNum = re.findall(re.compile(
r'(\d*)人评价'), str(item))[0] # 评价数
info = re.findall(re.compile(r'(.*?)
', re.S), str(item))[0].replace(
'\n ', '').replace('\xa0\xa0\xa0', ',').replace(r' /...
\n', ',')
info = info.replace(' /...
', ',').replace('\xa0/\xa0',
',').replace('\n ', '').replace('...
', ',').replace('
', ',')
year = re.findall(re.compile(r',(\d+),'), info)
year = year[0] if len(year) != 0 else year == '未知'
target.append(
[movieName, year, otherName, inq, rating, countNum, info])
time.sleep(1)
print('已经爬取{}页'.format(i+1))
# 写进csv
output = pd.DataFrame(target)
output.columns = ['movieName', 'year', 'otherName',
'inq', 'rating', 'countNum', 'info']
output.to_csv('Top250.csv')
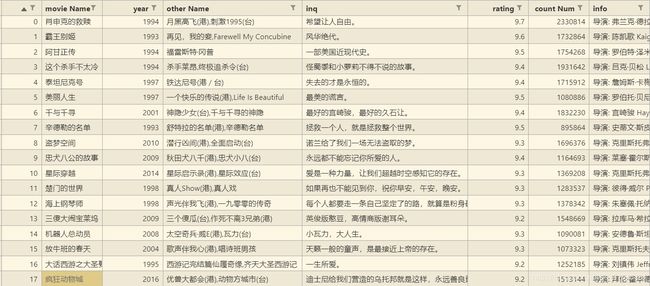
最终的效果如下