爬取豆瓣TOP250的电影信息(代码+可视化+数据分析)
爬取豆瓣TOP250的电影信息(代码+可视化+数据分析)
数据获取
主要是从豆瓣250的网页,获取相应的信息。首先分析豆瓣电影top250的网页https://movie.douban.com/top250,在浏览器中打开这个网页,网页的大致内容如下所示:

我们需要爬取的信息都在上面有显示了,电影的年份,国家,电影的类型等 都是有显示,但我们需要的是豆瓣250得所有电影信息,而一个网页只显示25条电影的信息,所以我们需要观察每个网页的链接的变化。通过网址的规律变化,就可以构造每一页的网址。
可以看到一页显示的是25个电影的信息一共分十页显示,要抓取250 部电影的信息需要抓取10次,前5页的网址链接:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
第五页:https://movie.douban.com/top250?start=100&filter=
通过分析上面的链接可以得出一个规律:start=0显示1到25部电影的信息,start=25,显示26到30部的电影信息。以此类推,在抓取每一页的时候只需要改变start的值即可。这样就可以循环得到请求每一页的信息url,我们通过使用一个函数来实现URL的动态变化。
if __name__ == '__main__':
for i in range(10):
a = i*25
url = "https://movie.douban.com/top250?start="+str(a)+"&filter="
write_one_page(url)
分析完请求信息的 url 以及返回结果信息的结构之后开始定义爬虫程序。在定义爬虫程序的时候,因为有些网页会有反爬虫的设置,所以在爬虫程序运行过程中会出现问题,因此在爬虫程序中需要添加一个头部 headers 信息,模拟成浏览器访问网页的形式,headers 头部信息中包含 User-Agent 以及 Cookies 等信息。
User-Agent 可以用来判断是否是浏览器发起的 Request,是一个特殊的字符串头,可以识别客户使用的操作系统及浏览器版本等信息。对于 User-Agent 的设置方法有两种,一是自定义 User-Agent 的数组,然后使用 random 的方式随机调用 User-Agent 数组;二是使用 Python 的第三方类库 fake-useragent,它里面提供了很多的 User-Agent,使用时只需要只需要导入第三方库,使用 fake_useragent 类库首先需要在命令行通过 pip 提前安装该类库然后进行使用。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
html = requests.get(url, headers=headers).text
# lxml:html解析库(把HTML代码转化成Python对象)
soup = BeautifulSoup(html, 'lxml')
通过上述代码可以学习request类库中如何使用headers信息。还有request库的使用。HTTP 中最常见的请求之一就是 GET 请求,利用 requests 构建 GET 请求的方法。
然后开始抓取每一部电影电影的信息,首先查看网页的源代码,在浏览器中先把要访问的网页找出来,按下键盘上的F12,就可以查看网页的源代码。也可以点击自己感兴趣的内容,鼠标右键点击审查元素。也可以看点网页的源代码如下图所示。

为了方便后续进行可视化和数据分析我们主要爬取的是
每一部电影的排名,评分,年份,国家,类型。这些数据都可以大方向的反应一部电影的整体水平。
数据的保存
将数据保存在CSV文件中,写了一个保存数据在CSV中的通用代码,爬取到的数据都可以使用这个函数进行保存。
def write_dictionary_to_csv(dict,filename):
# file_name='{}.csv'.format(filename)
file_exists = os.path.isfile(filename)
with open(filename, 'a',encoding='utf-8') as f:
# headers=dict.keys();
w =csv.DictWriter(f, dict.keys(),delimiter=',', quotechar='"', lineterminator='\n',quoting=csv.QUOTE_ALL, skipinitialspace=True)
if not file_exists :
w.writeheader()
w.writerow(dict)
print('当前行写入csv成功!')
完整的爬虫函数代码:
完整的爬虫代码包括,主函数需要用来爬取数据,保存数据,对爬取的网页链接进行改变。
from bs4 import BeautifulSoup
from lxml import html
import xml
import requests
import json,os,csv
import io
def write_dictionary_to_csv(dict,filename):
# file_name='{}.csv'.format(filename)
file_exists = os.path.isfile(filename)
with open(filename, 'a',encoding='utf-8') as f:
# headers=dict.keys();
w =csv.DictWriter(f, dict.keys(),delimiter=',', quotechar='"', lineterminator='\n',quoting=csv.QUOTE_ALL, skipinitialspace=True)
if not file_exists :
w.writeheader()
w.writerow(dict)
print('当前行写入csv成功!')
rank = 1
def write_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
html = requests.get(url, headers=headers).text
# lxml:html解析库(把HTML代码转化成Python对象)
soup = BeautifulSoup(html, 'lxml')
global rank
for k in soup.find('div',class_='article').find_all('div',class_='info'):
name = k.find('div',class_='hd').find_all('span')#电影名字
score = k.find('div',class_='star').find_all('span')#分数
# inq = k.find('p',class_='quote').find('span')#一句话简介
#抓取年份、国家
actor_infos_html = k.find(class_='bd')
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
actor_infos = actor_infos_html.find('p').get_text().strip().split('\n')
actor_infos1 = actor_infos[0].split('\xa0\xa0\xa0')
director = actor_infos1[0][3:]
role = actor_infos[1]
year_area = actor_infos[1].lstrip().split('\xa0/\xa0')
year = year_area[0]
country = year_area[1]
type = year_area[2]
print(rank,name[0].string,score[1].string,year,country,type)
data={
'rank':rank,
'name':name[0].string,
'score':score[1].string,
'year':year,
'country':country,
'type':type
# '评论信息':com2,
}
# print(data)
write_dictionary_to_csv(data,'aaa.csv')
#写txt
if __name__ == '__main__':
for i in range(10):
a = i*25
url = "https://movie.douban.com/top250?start="+str(a)+"&filter="
write_one_page(url)
数据分析
使用jupyter和SublimeText进行数据分析:jupyter的使用可以去网上找一些教程来自己安装。使用jupyter通过对数据的操作可以更好的看到数据的变化。
数据的预览:
把存入CSV的数据进行查看 ,数据是否完整,存入的格式是否正确。
import numpy as np
import pandas as pd
df = pd.read_csv(r'C:\Users\XXX\Desktop\aaa.csv',encoding='gb18030')
df.head()
把自己存储的CSV文件的路径写上.

查看数据基本信息
import numpy as np
import pandas as pd
df = pd.read_csv(r'C:\Users\XXX\Desktop\aaa.csv',encoding='unicode_escape')
df.info()
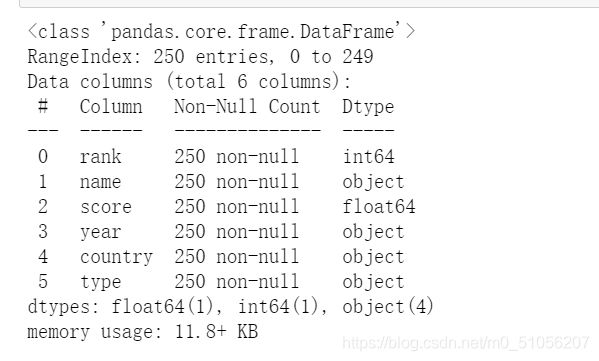
可以看到数据的类型 数据时候有空缺,以及数据一个有多少条。
重复值检查
检查是否有重复项,或者重复的电影名:
df.duplicated().value_counts()
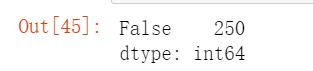
可以看到没有重复项
len(df.name.unique())

没有重复值和电影名的重复
查看国家或地区参与电影制作的排名情况
对于 country 列,有些电影由多个国家或地区联合制作,所以在计算一个电影的制作国家时,对参与制作的国家都需要,进行计算:

我们可以看到,有些国家甚至有5个国家或地区参与制作,对于这么多的空值,可以通过先按列计数,将空值 NaN 替换为“0”,再按行汇总。我们统计每个区域里相同国家的总数
all_country = country.apply(pd.value_counts).fillna('0')
all_country.columns = ['area1','area2','area3','area4','area5','area6']
all_country['area1'] = all_country['area1'].astype(int)
all_country['area2'] = all_country['area2'].astype(int)
all_country['area3'] = all_country['area3'].astype(int)
all_country['area4'] = all_country['area4'].astype(int)
all_country['area5'] = all_country['area5'].astype(int)
all_country['area6'] = all_country['area6'].astype(int)
all_country['all_counts'] = all_country['area1']+all_country['area2']+all_country['area3']+all_country['area4']+all_country['area5']+all_country['area6']
all_country.sort_values(['all_counts'],ascending=False)
all_country
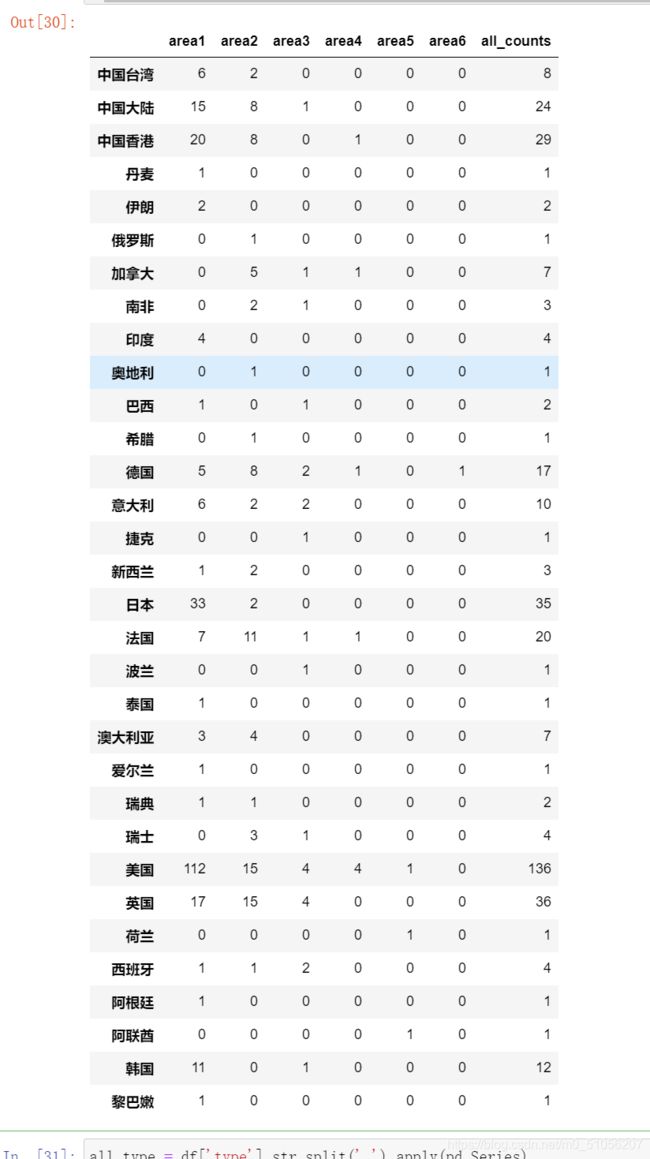
通过上一个表的展示,通过all-count这一列,我们就可以看到电影的产地信息了,可以看到是美国产的电影最多,但是这样不够直观。我们把电影的产地信息生产一个柱状图来看一看,这样更加的直观
country_rank = pd.DataFrame({
'counts':all_country['all_counts']})
country_rank
country_rank.sort_values(by='counts',ascending=False).plot(kind='bar',figsize=(14,6))

这样可以清楚的看到,还是美国比较厉害呀,上榜的电影最多,而且远超其他的国家,中国的电影上榜的也有不少,也还是不错的,继续发展呀。从丹麦开始 后面的国家上榜的电影就比较少了,我也觉得有一部分是因为文化的差异 。比如我在看电影的时候,如果我不够够了解这个电影的背景和国家的话 就比较的难懂,所以看的就比较少。
关于电影类型的分析
同一部电影也可能是多个类型的电影,所以向对电影的产出国家一样,对电影的类型要统计,对一部电影有多重类型的情况,每一个类型都要进行统计。
all_type = df['type'].str.split(' ').apply(pd.Series)
all_type.head(10)

对类型的数据做和产地同样的处理,将同一班部电影不同的类型都要做一个统计。
all_type = df['type'].str.split(' ').apply(pd.Series)
all_type = all_type.apply(pd.value_counts).fillna('0')
all_type.columns = ['tpye1','type2','type3','type4','type5']
all_type['tpye1'] = all_type['tpye1'].astype(int)
all_type['type2'] = all_type['type2'].astype(int)
all_type['type3'] = all_type['type3'].astype(int)
all_type['type4'] = all_type['type4'].astype(int)
all_type['type5'] = all_type['type5'].astype(int)
all_type.head(10)
all_type['all_counts'] = all_type['tpye1']+all_type['type2']+all_type['type3']+all_type['type4']+all_type['type5']
all_type = all_type.sort_values(['all_counts'],ascending=False)
all_type.head(10)
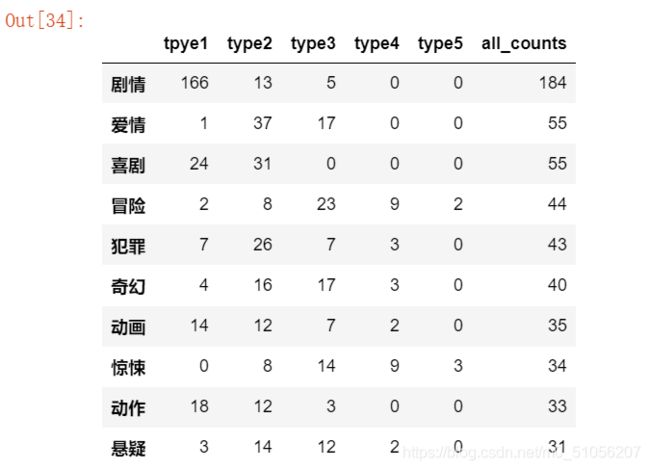
上图也通过all-count这一列也可以看到有剧情这一分类的电影是最多的 但是这样同样的不够直观,同样我们生成一个柱状图来看看。
country_rank = pd.DataFrame({
'counts':all_type['all_counts']})
country_rank
country_rank.sort_values(by='counts',ascending=False).plot(kind='bar',figsize=(14,6))
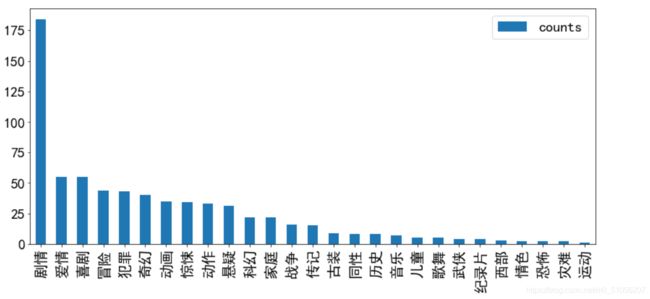
可以看到几乎百分之七十的电影都包含在含有剧情这一个类型中,其次大家比较喜欢看的电影类型,爱情和喜剧.运动,灾难,恐怖这些类型的片子上榜的比较少了,但也有可能是因为绝大部分的电影类型都包括了剧情这一分类中,所以导致这一类型的比例特别高。
评分与排名的联系情况
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 20
plt.figure(figsize=(20,5))
plt.subplot(1,2,1)
plt.scatter(df['score'],df['rank'])
plt.xlabel('score')
plt.ylabel('rank')
plt.gca().invert_yaxis()
plt.subplot(1,2,2)
plt.hist(df['score'],bins=15)
df['score'].corr(df['rank'])
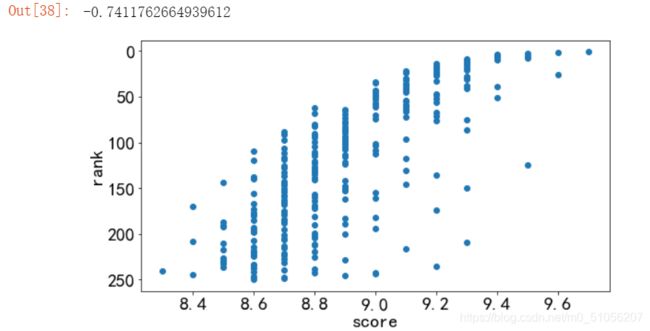
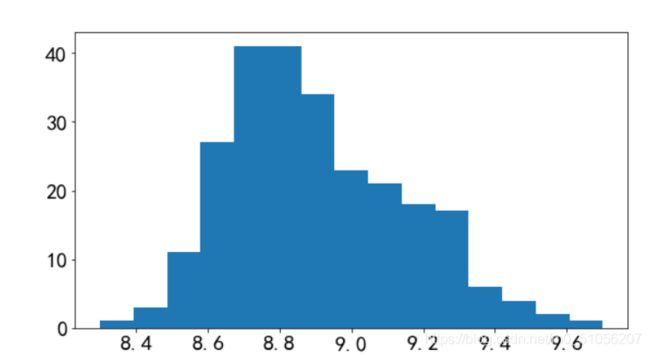
评分大多是集中在 8.5 - 9.3之间,随评分的升高,豆瓣Top250排名名次也提前,相关系数为-0.7411762664939612,为强相关性
评分分布的饼图:
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
# import re
# from numpy import rank
# from builtins import map
# from datashape.coretypes import Map
# import io
# import sys
# sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
Movie=pd.read_csv('right.csv' ,encoding='gb18030') #数据读取
#Rating pie
Rating=Movie['电影评分']
bins=[8,8.5,9,9.5,10] #分区(0,8],(8,8.5]....
rat_cut=pd.cut(Rating,bins=bins)
rat_class=rat_cut.value_counts() #统计区间个数
rat_pct=rat_class/rat_class.sum()*100 #计算百分比
# rat_arr_pct=np.array(rat_pct)#将series格式转成array,为了避免pie中出现name
f1=plt.figure(figsize=(9,9))#设置大小
plt.title('TOP250 movieScore')
# matplotlib.pyplot.pie函数:画一个饼图
plt.pie(rat_pct,labels=rat_pct.index,colors=['r','b','g','y'],autopct='%.2f%%',startangle=75,explode=[0.05]*4) #autopct属性显示百分比的值
plt.savefig('MovieTop2503.png')#保存图片
f1.show()#一定要调用show函数
#explode:将某部分爆炸出来, 使用括号,将第一块分割出来,数值的大小是分割出来的与其他两块的间隙
#labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
#autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
#shadow,饼是否有阴影
#startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
#pctdistance,百分比的text离圆心的距离
#patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本

对电影的产出年份进行分析
year=Movie['year']
for i in year.index:
if len(year[i])>4:
year.drop(i,inplace=True) # year.drop(i,inplace=True) 去除多个年代的特例,inplace重要,修改改变原值
year=year.astype(int)
bins=np.linspace(min(year)-1,max(year)+1,10).astype(int) #产生区间,bins一般为(,]的,所以+1
year_cut=pd.cut(year,bins=bins)
year_class=year_cut.value_counts()
year_pct=year_class/year_class.sum()*100
year_arr_pct=np.array(year_pct)
color=['b', 'g', 'r', 'c', 'm', 'y', (0.2,0.5,0.7), (0.6,0.5,0.7),(0.2,0.7,0.1)] #RGB 0-1之间的tuple
f2=plt.figure(figsize=(9,9))
patches,out_text,in_text=plt.pie(year_arr_pct,labels=year_pct.index,colors=color,autopct='%.2f%%',explode=[0.05]*9,startangle=30)
plt.title('MovieTop250\nYears Distribution')
f2.show()

可以看到在2009年到2019年的电影上榜的最多,可以猜测一下,大家都比较喜欢新的电影,太过久远的电影,可能已经不太符号当今的社会文化了,但经典永远都是经典.1939到1949年的电影也有上榜的,以前电影的拍摄画质都能上榜,真真是很不错了.
啦啦啦,这就是我的全部总结啦,初学者,如果有不正确的地方也欢迎大家指正,一起探讨呀.生活不易,点个赞支持一下吧....