title: "ggplot2学习笔记3"
author: "Liang"
date: "2019年6月3日"
output: html_document
knitr::opts_chunk$set(echo = TRUE, message=FALSE, warning=FALSE)
第5章 工具箱
5.1 简介
ggplot2鼓励我们以一种结构化的方式来设计和构建图形。
本章旨在概述一些可用的几何对象和统计变换,每一节解决一个特定的作图问题。
5.2 图层叠加的总体策略
总体来说,图层有三种作用:
- 展示数据本身。
- 展示数据的统计摘要。
- 添加额外的元数据(metadata)、上下文信息和注解。
5.3 基本图形类型
以下几何对象是ggplot2图形的基本组成部分,
- 可独立构建图形,也可以组合构建更复杂的几何对象。
- 都是二维的,x和y两种图形属性不可或缺。
- 都可以接受colour和size图形属性。
- 填充型几何对象(条形、瓦片和多边形)还可以接受fill图形属性。
- 点使用shape图形属性,线和路径使用linetype图形属性。
| 函数 | 图形类型 | 说明 |
|---|---|---|
| geom_area() | 面积图 | 在普通线图的基础上,依y轴方向填充下方面积的图形。 对于分组数据,各组依次堆积。 |
| geom_bar(stat="identity") | 条形图 | bar本质上是一维图,默认统计变换将自动对“值”计数。 指定stat="identity"保持数据不变。 分组数据,各组依次向上堆积。 |
| geom_line() | 线条图 | 图形属性group决定哪些观测是连接在一起的。 geom_path与geom_line类似,但线条按数据出现顺序连接。 |
| geom_point() | 散点图 | |
| geom_polygon() | 多边形 | 数据中每一行代表多边形一个顶点。 在绘图前最好将多边形顶点坐标数据和原始数据进行合并。 |
| geom_text() | 指定点添加标签 | 需要指定label参数。 图形属性hjust和vjust控制文本的横纵位置。 图形属性angle控制文本的旋转。 |
| geom_tile() | 色深图(image plot)水平图(level plot) | 所有的瓦片(tile)构成对平面的一个规则切分,且往往将fill图形属性映射至另一个变量。 |
library(ggplot2)
library(gridExtra)
df <- data.frame(
x = c(3,1,5),
y = c(2,4,6),
label = c("a","b","c")
)
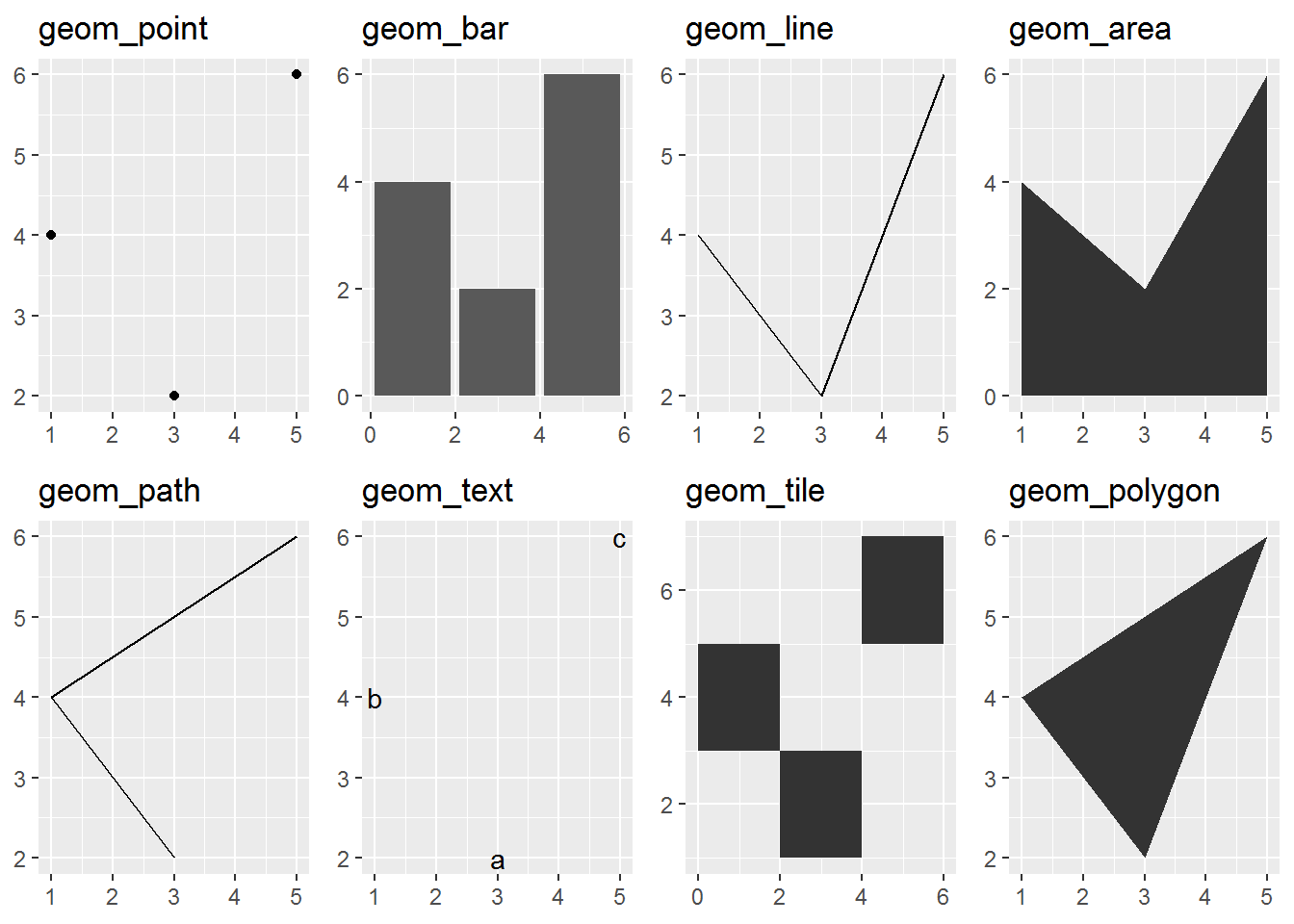
p <- ggplot(df, aes(x,y)) + xlab(NULL) + ylab(NULL)
p1 <- p + geom_point() + labs(title="geom_point")
p2 <- p + geom_bar(stat="identity") + labs(title = "geom_bar")
p3 <- p + geom_line() + labs(title = "geom_line")
p4 <- p + geom_area() + labs(title = "geom_area")
p5 <- p + geom_path() + labs(title = "geom_path")
p6 <- p + geom_text(aes(label=label)) + labs(title = "geom_text")
p7 <- p + geom_tile() + labs(title = "geom_tile")
p8 <- p + geom_polygon() + labs(title = "geom_polygon")
grid.arrange(p1,p2,p3,p4,p5,p6,p7,p8, ncol=4)
5.4 展示数据分布
具体使用哪种几何对象,取决于分布的维度、分布是连续的还是离散的,以及是条件分布还是联合分布。
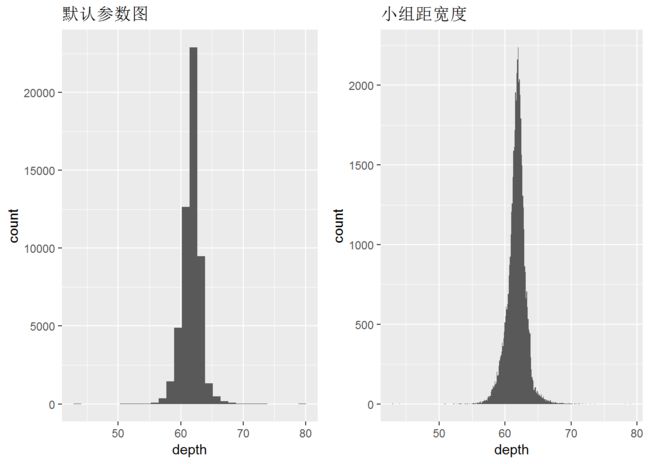
对于一维连续型分布,最重要的几何对象是直方图。
depth_dist <- ggplot(diamonds, aes(depth))
d1 <- depth_dist + geom_histogram() + labs(title = "默认参数图")
d2 <- depth_dist + geom_histogram(binwidth = 0.1)+ labs(title="小组距宽度")
grid.arrange(d1, d2, ncol=2)
分布的跨组比较:
- 同时绘制多个小的直方图,facets=.~var;
- 使用频率多边形(frequency polygon), geom="freqploy";
- 使用条件密度图,position="fill"。
depth_dist <- ggplot(diamonds, aes(depth)) + xlim(58, 68)
d3 <- depth_dist + geom_histogram(aes(y=..density..), binwidth = 0.1) + facet_grid(cut ~.)
d4 <- depth_dist + geom_histogram(aes(fill=cut), binwidth = 0.2, position="fill")
d5 <- depth_dist + geom_freqpoly(aes(y=..density.., colour=cut), binwidth=0.1)
grid.arrange(d3,d4,d5,ncol=2)
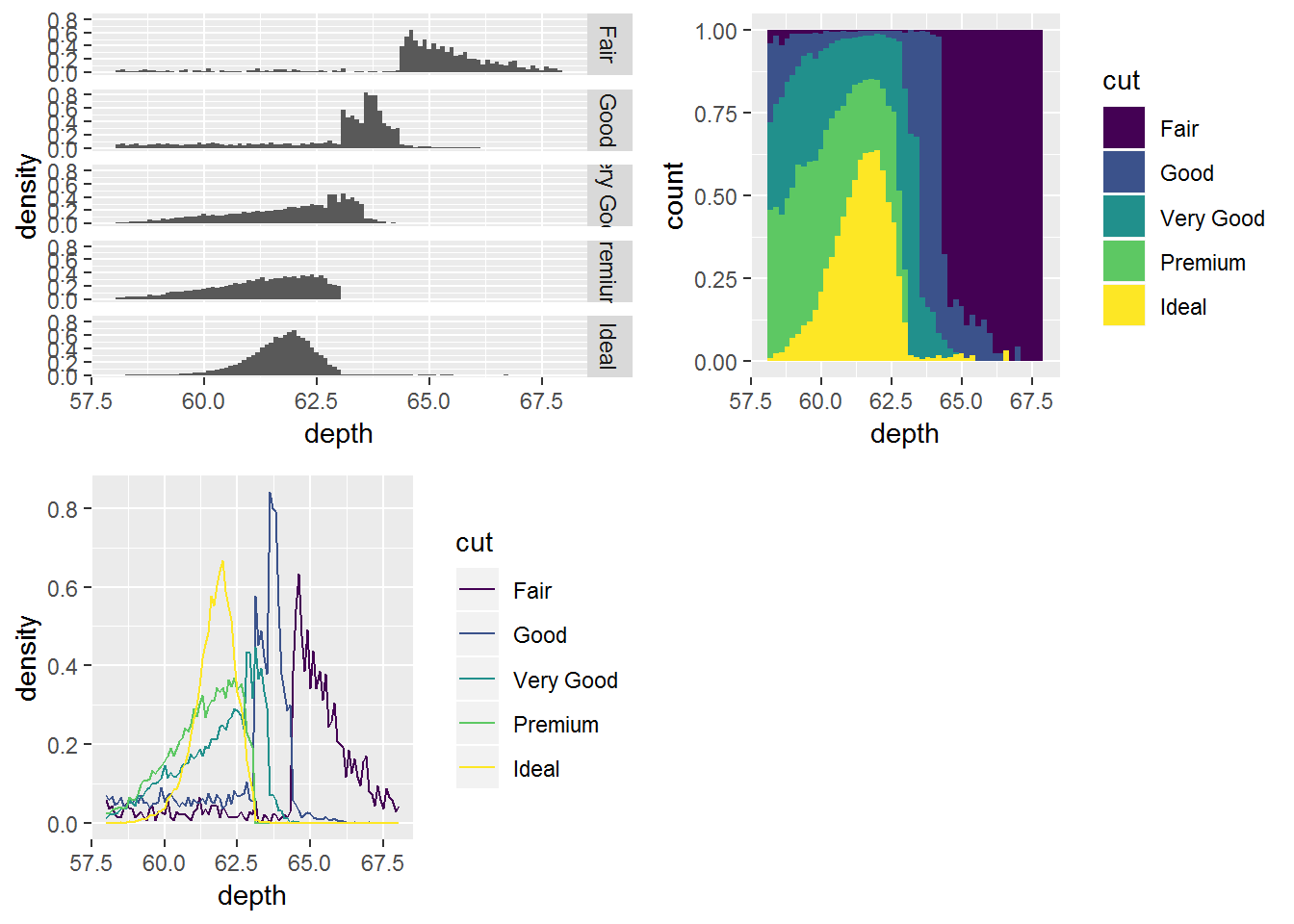
作为几何对象的直方图和频率多边形均使用了stat_bin统计变换。
- 此统计变换生成了两个输出变量count和density。
- 变量count是默认值。
- 当我们想比较不同大小子集的分布,而不是数据的绝对大小时,density更有用。
和分布相关的许多几何对象都是以几何对象(geom)和统计变换(stat)的形式成对出现。
geom_boxplot = stat_boxplot + geom_boxplot 箱线图(boxplot):一个连续型变量针对一个类别变量取条件所得的图形。
- 当类别型变量有许多独立的取值值,这种图形比较有用。
- 当类别型变量的取值很少时,直接研究分布的具体形状更佳。
- 箱线图也可以对连续型变量取条件,前提是数据预先经过巧妙地封箱(binning)处理。
- 封箱处理:round_any(x, accuracy, f=round): Round to multiple of any number
- x: numeric vector to round
- accuracy: number to round to
- f: rounding function: floor, ceiling, round
library(plyr)
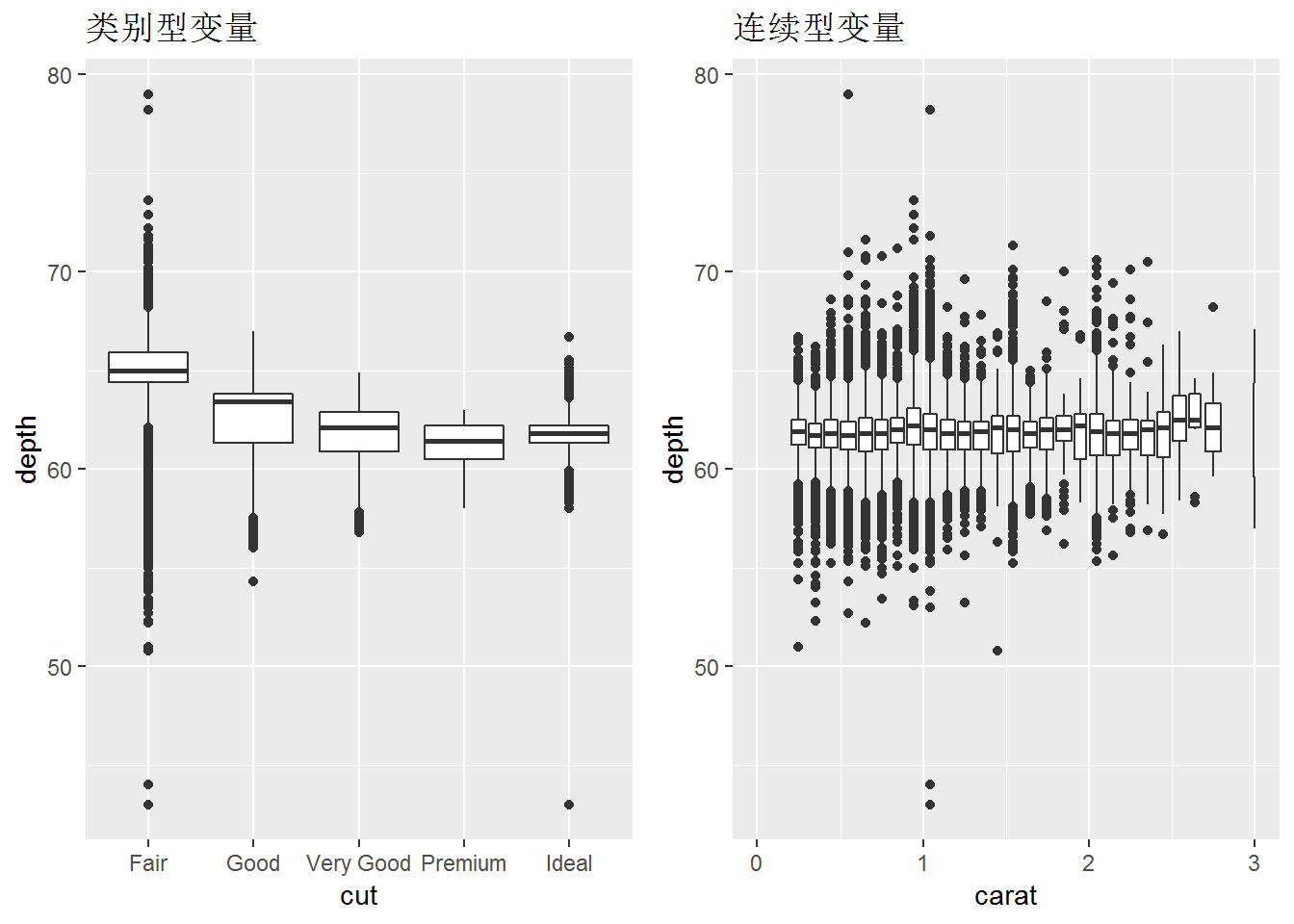
box1 <- qplot(cut, depth, data=diamonds, geom="boxplot") + labs(title="类别型变量")
box2 <- qplot(carat, depth, data = diamonds, geom = "boxplot", group = round_any(carat, 0.1, floor), xlim=c(0,3)) + labs(title="连续型变量")
grid.arrange(box1, box2, ncol=2)
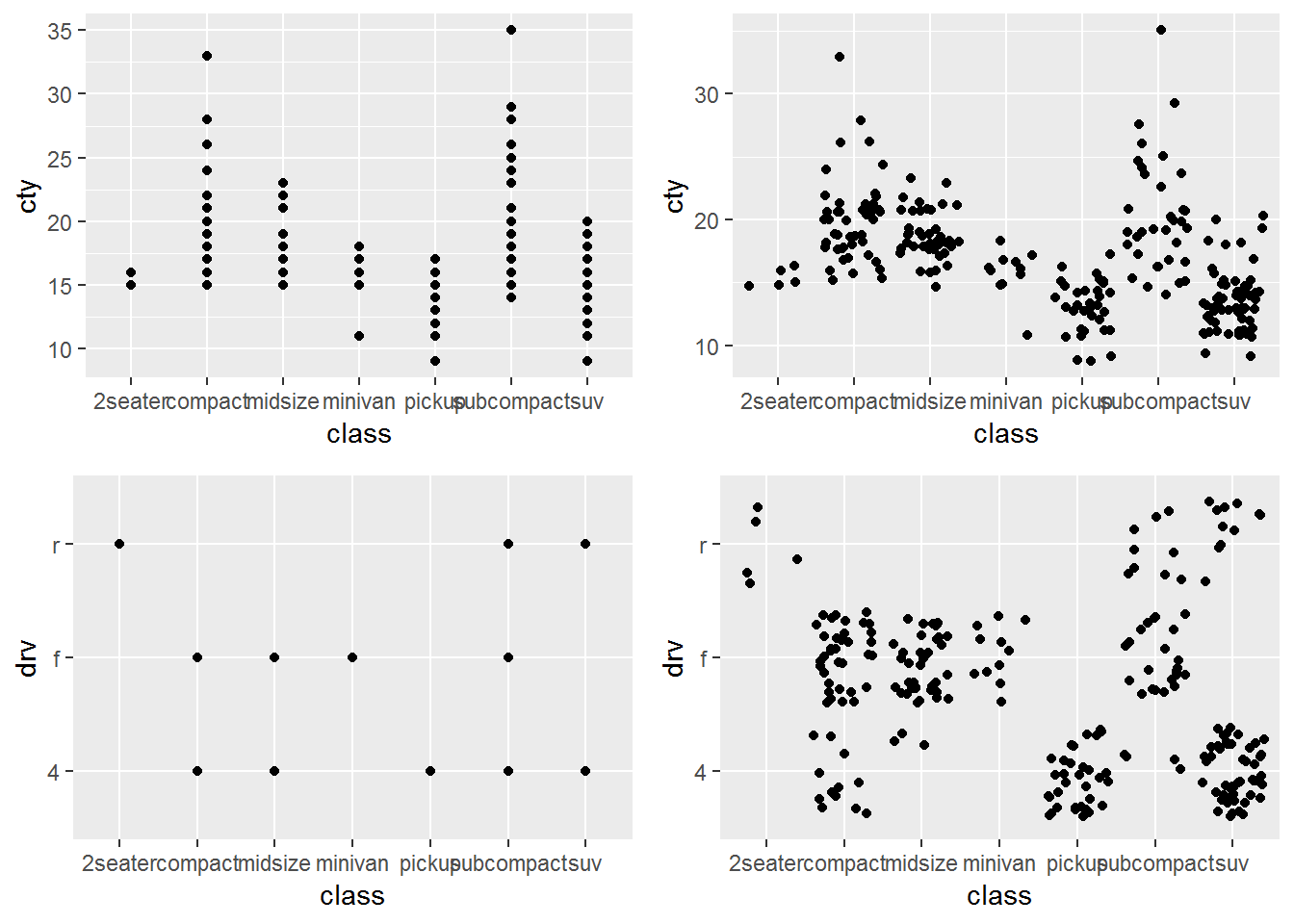
geom_jitter = position_jitter = geom_point: 通过在离散型分布上添加随机噪声以避免遮盖绘制问题。
j1 <- qplot(class, cty, data=mpg)
j2 <- qplot(class, cty, data=mpg, geom="jitter")
j3 <- qplot(class, drv, data=mpg)
j4 <- qplot(class, drv, data=mpg, geom="jitter")
grid.arrange(j1, j2, j3, j4, ncol=2)
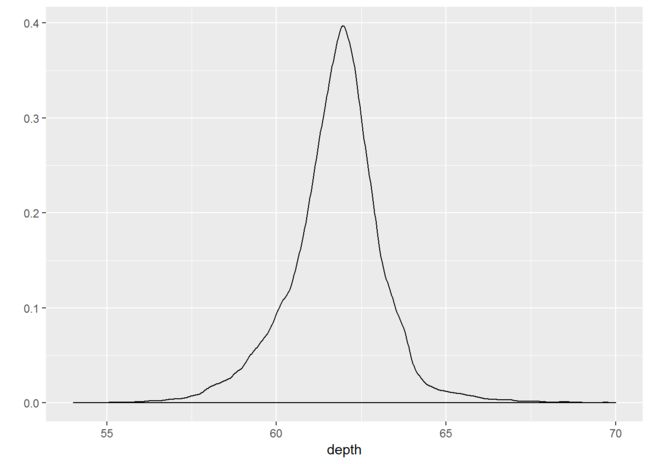
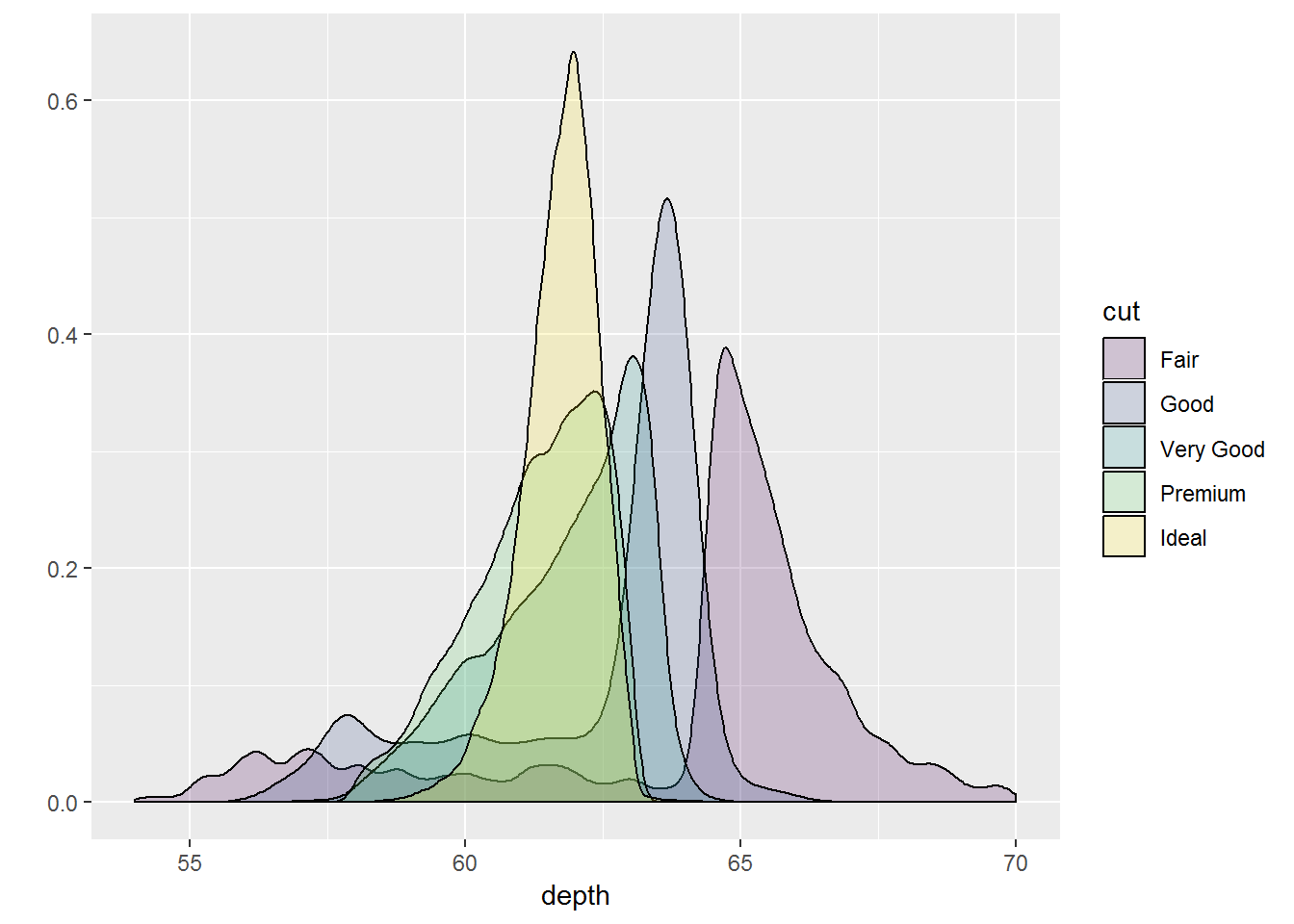
geom_density = stat_density + geom_area: 基于核平滑方法进行平滑后得到的频率多边形。
- 密度图实际上是直方图的平滑版本。它的理论性质比较理想,但难以由图回溯到数据本身。
- 仅在已知潜在的密度分布为平滑、连续且无界的时候使用这种密度图。
- 可以使用参数adjust来调节所得密度曲线的平滑程度。
qplot(depth, data=diamonds, geom="density", xlim=c(54, 70))
qplot(depth, data=diamonds, geom="density", xlim=c(54, 70), fill=cut, alpha=I(0.2))
5.5 处理遮盖绘制问题
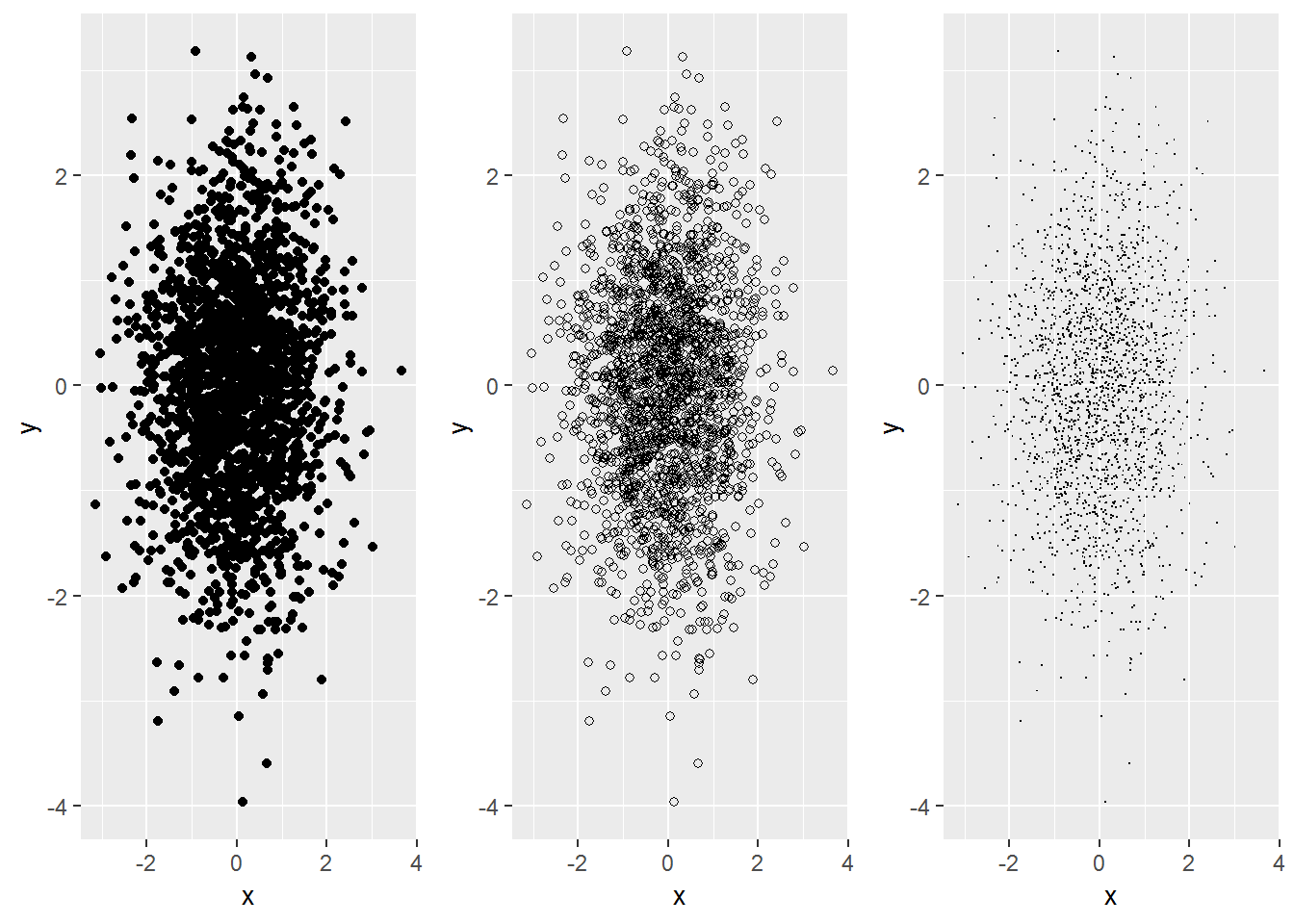
当数据量很大时,散点图的点经常会出现重叠现象,从而掩盖真实的关系。这种问题被称为遮盖绘制(overplotting)。对付它的方法:
- 小规模的遮盖绘制问题可以通过绘制更小的点加以缓解,或使用中空的符号。
df <- data.frame(x=rnorm(2000), y =rnorm(2000))
norm <- ggplot(df, aes(x,y))
n1 <- norm + geom_point()
n2 <- norm + geom_point(shape=1)
n3 <- norm + geom_point(shape=".") #点的大小为像素级
grid.arrange(n1, n2, n3, ncol=3)
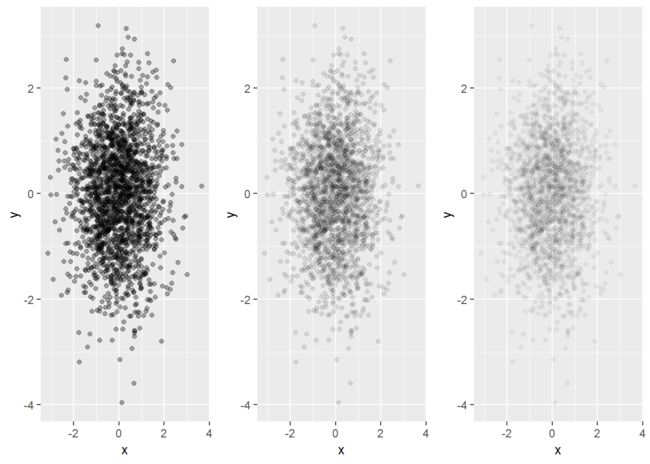
- 对于更大的数据集产生的更为严重的遮盖绘制问题,可以调整透明度让点呈现透明效果。
- 假设我们以比值形式指定的值,则分母代表的是一个位置的颜色变为完全不透明时所需要重叠点的数量。
- 在R中,可用的最小透明度为1/256。
n4 <- norm + geom_point(colour = "black", alpha=1/3)
n5 <- norm + geom_point(colour = "black", alpha=1/10)
n6 <- norm + geom_point(colour = "black", alpha=1/20)
grid.arrange(n4, n5, n6, ncol=3)
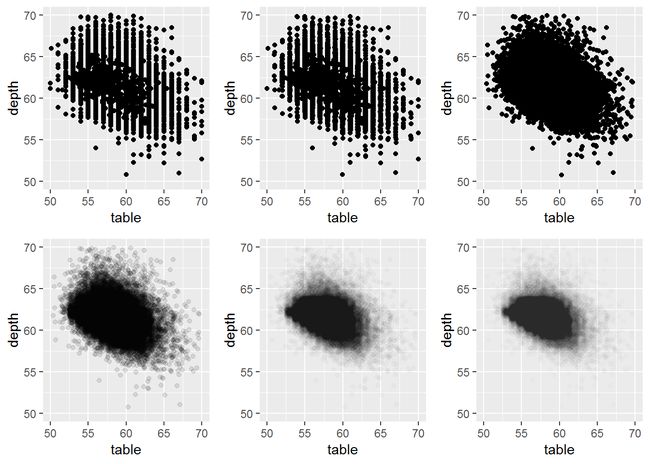
- 如果数据存在一定的离散性,我们可以通过在点上增加随机扰动来减轻重叠。
- 特别是在与透明度一起使用时,这种方法很有效。
- 默认情况下,增加的扰动量是数据分辨率(resolution)的40%。
td <- ggplot(diamonds, aes(table, depth)) + xlim(50,70) + ylim(50, 70)
td1 <- td + geom_point()
td2 <- td + geom_jitter()
jit <- position_jitter(width = 0.5)
td3 <- td + geom_jitter(position = jit)
td4 <- td + geom_jitter(position = jit, colour="black", alpha=1/10)
td5 <- td + geom_jitter(position = jit, colour="black", alpha=1/50)
td6 <- td + geom_jitter(position = jit, colour="black", alpha=1/100)
grid.arrange(td1, td2, td3, td4, td5,td6, ncol=3)
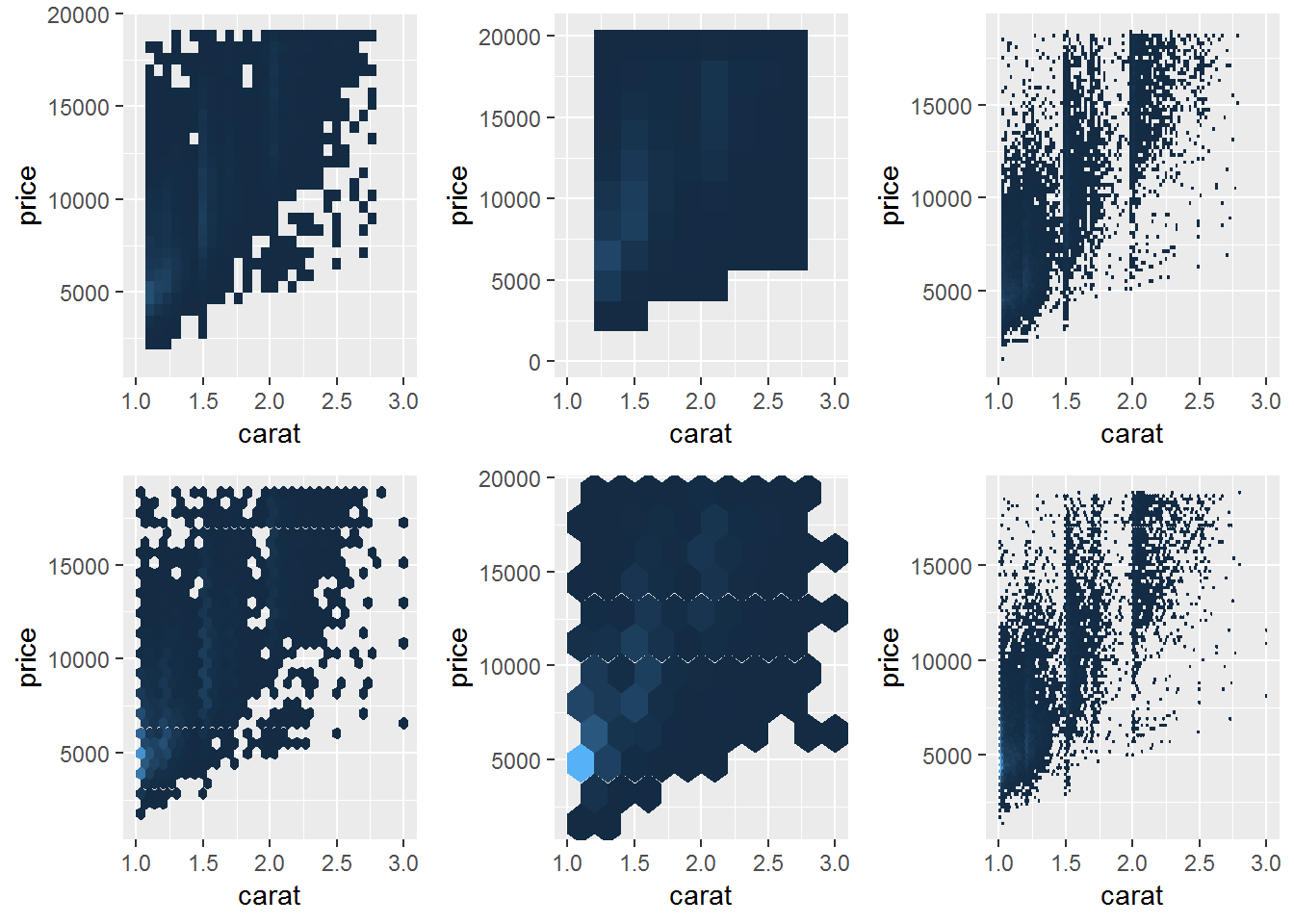
遮盖绘制问题其实可以认为是一种二维核密度估计问题于是又要吧引申出以下两种方法:
- 将点分箱并统计每个箱中点的数量,然后通过某种方式可视化这个数量(直方图的二维推广)。
- 将图形划分成小的正方形箱可能会产生分散注意力的视觉假象。
- 建议使用六边形代之,这类图形可以使用geom_hexagon几何对象实现,它使用了hexbin包提供的功能。
d <- ggplot(diamonds, aes(carat, price)) + xlim(1,3) + theme(legend.position = "none") #省略图例
# 正方形显示分箱
d1 <- d + stat_bin2d()
d2 <- d + stat_bin2d(bins = 10) #bins,数字向量,设定在垂直和水平方向的箱数,默认是30。
d3 <- d + stat_bin2d(binwidth = c(0.02, 200)) # binwidth,数字向量,设定垂直和水平方向箱子的宽度。
# 六边形显示分箱
d4 <- d + stat_binhex() #需要安装hexbin包。
d5 <- d + stat_binhex(bins = 10)
d6 <- d + stat_binhex(binwidth = c(0.02, 200))
grid.arrange(d1, d2, d3, d4, d5 ,d6, ncol=3)
- 使用stat_density2d作二维密度估计,并将等高线添加到散点图中,或以着色瓦片(colored tiles)直接展示密度,或者使用大小与分布密度成比例的点进行展示。
d <- ggplot(diamonds, aes(carat, price)) + xlim(1,3) + theme(legend.position = "none")
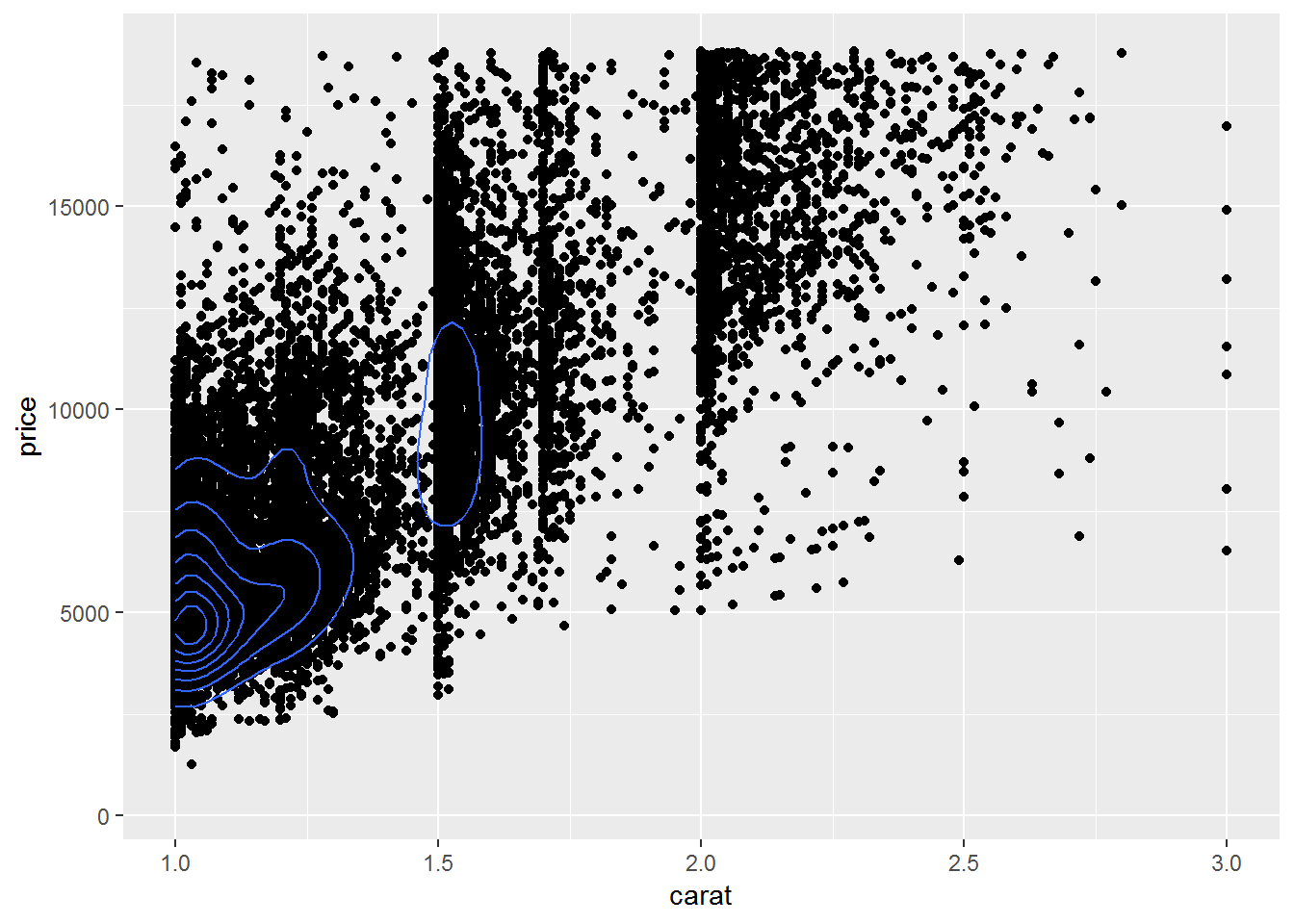
d + geom_point() + geom_density2d()
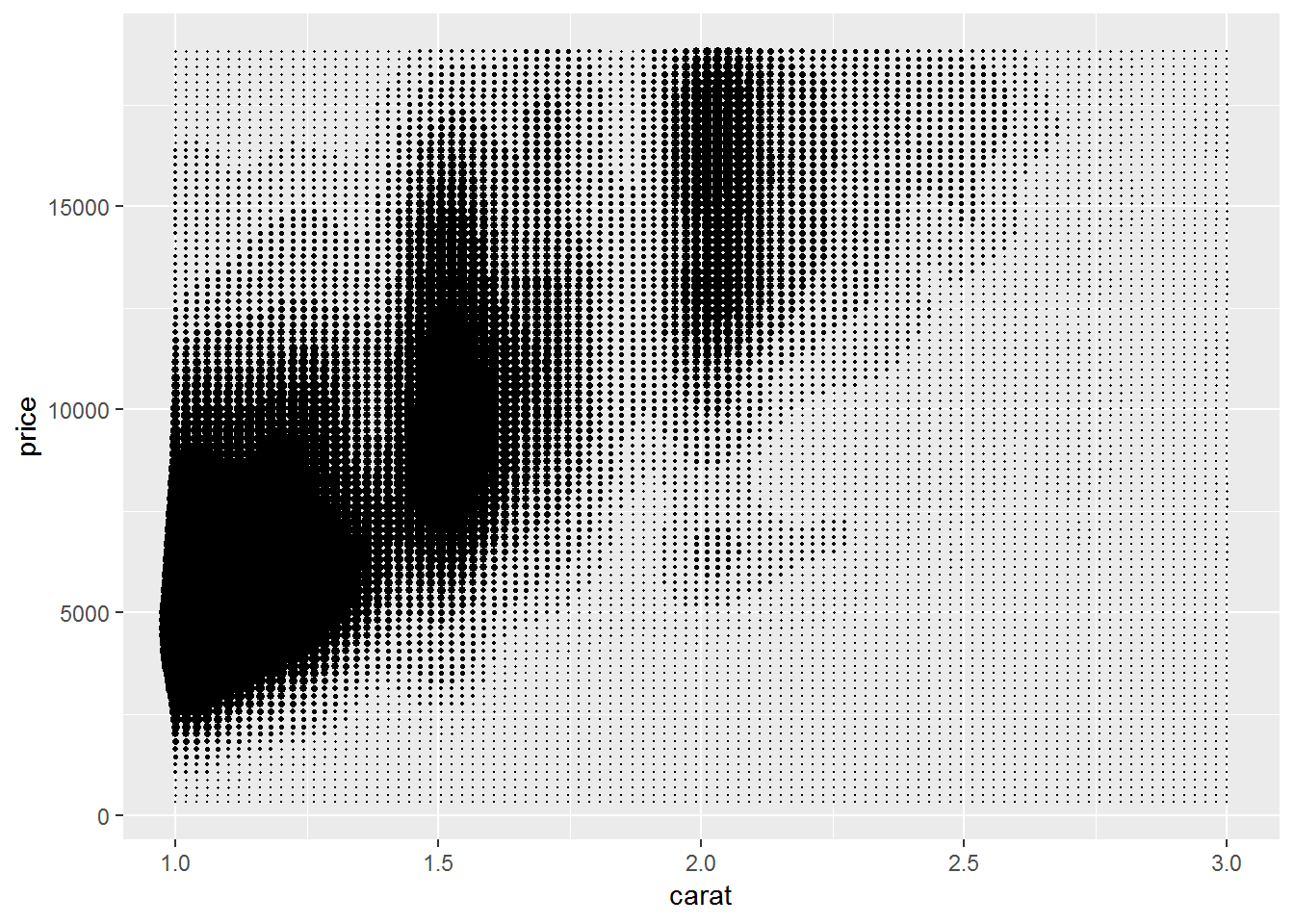
d + stat_density2d(geom="point", aes(size=..density..), contour = F) + scale_size_area()
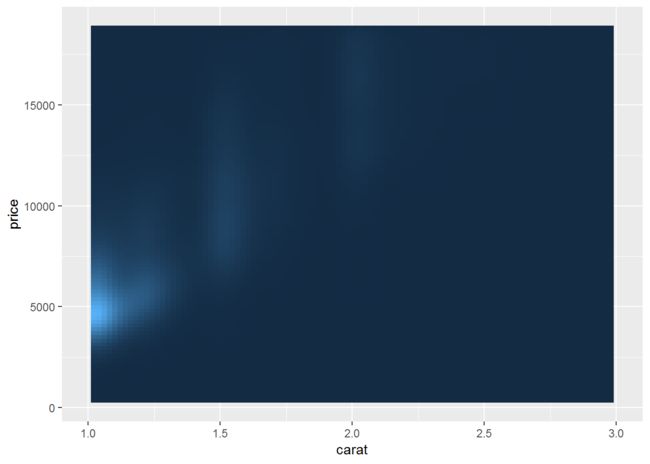
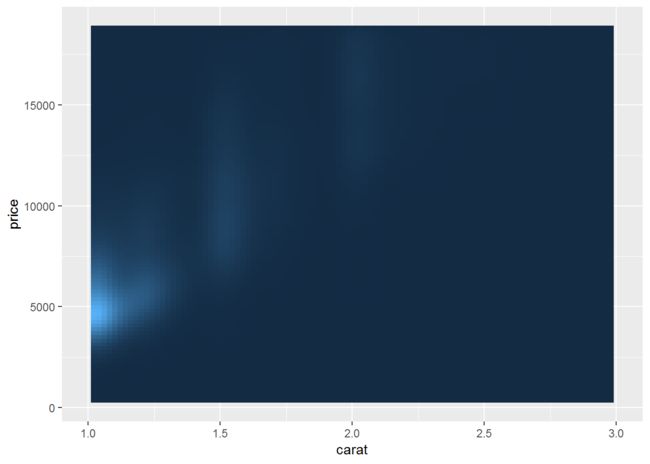
d + stat_density2d(geom="tile", aes(fill=..density..), contour = F)
last_plot() + scale_fill_gradient((limits=c(1e-5, 8e-4)))
5.6 曲面图
ggplot2暂不支持真正的三维曲面图。
具有在维平面上展现三维曲面的常见工具:等高线图、着色瓦片以及气泡图。
对于三维交互式图形和真实三维曲面的绘制,参见RGL包。
5.7 绘制地图
几何对象geom_map(),使用maps包绘制的地图与其他ggplots图形相结合。
关于中国地图的绘制,参见[《用R软件绘制中国分省市地图》](http://cos.name/2009/07/drawing-china-map-using-r/)
我们使用地图数据可能有两种主要原因:
- 一是为空间数据图形添加参考轮廓线,
- 二是通过在不同的区域填充颜色以构建等值线图(choropleth map)。
表5.1 maps包中可用的地图
| 国家 | 地图数据名 |
|---|---|
| 法国 | france |
| 意大利 | italy |
| 新西兰 | nz |
| 美国(郡级) | county |
| 美国(州级) | state |
| 美国(边界) | usa |
| 世界 | world |
添加地图边界可通过函数borders()来完成,参数map指定要绘制的地图数据名,参数region控制要绘制的具体区域,colour控制边界颜色,size控制线条粗细,fill控制多边形颜色填充。
library(maps)
data("us.cities")
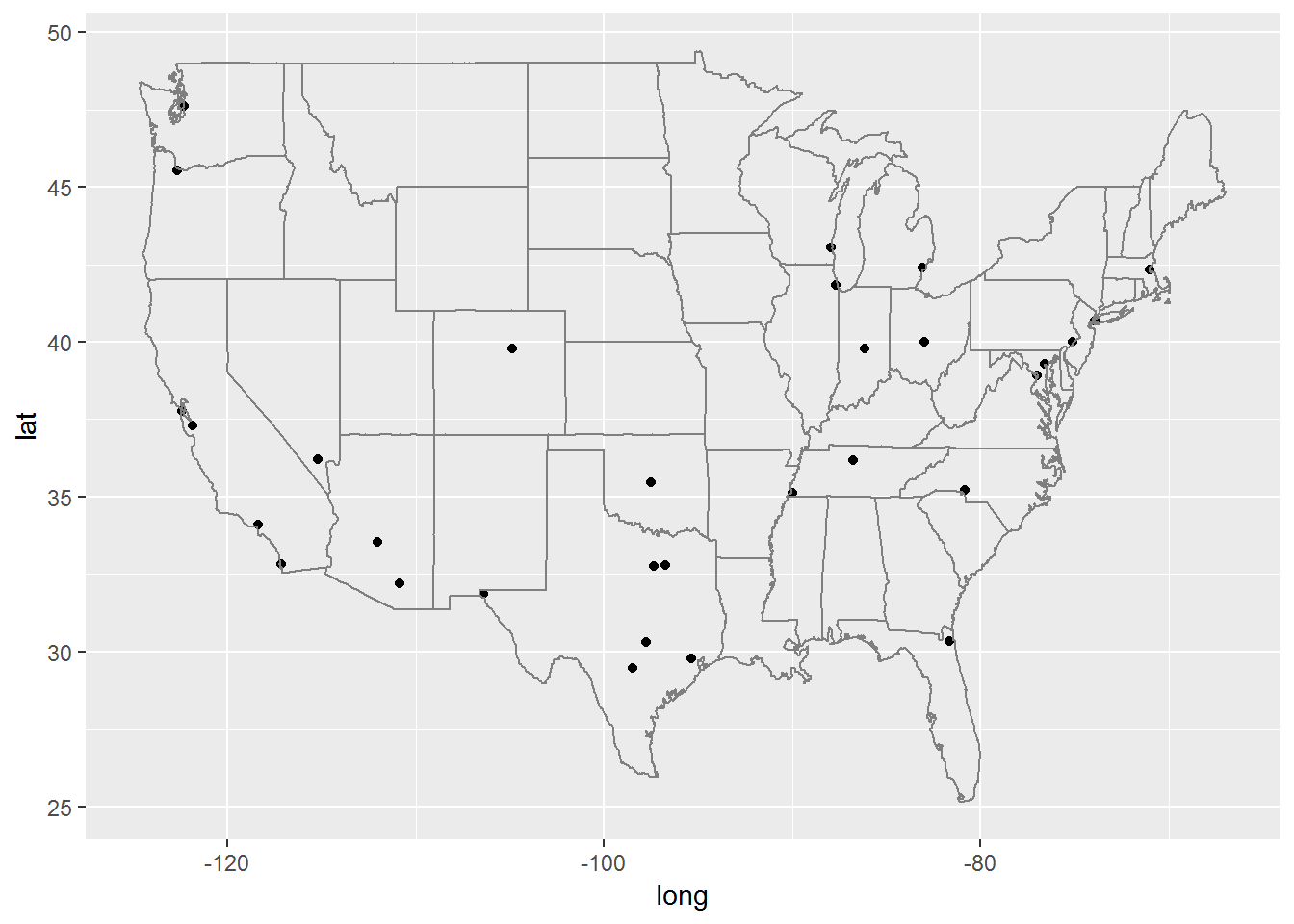
head(us.cities) #这个数据框中包含经度和纬度。
big_cities <- subset(us.cities, pop>500000)
qplot(long, lat, data = big_cities) + borders("state", size=0.5)
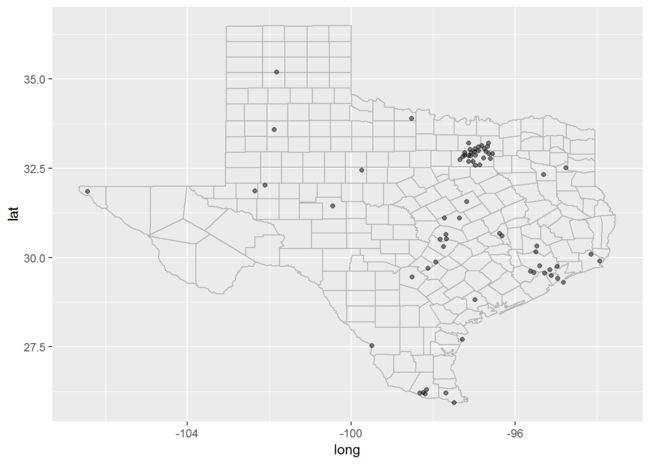
tx_cities <- subset(us.cities, country.etc == "TX")
ggplot(tx_cities, aes(long, lat)) + borders("county", "texas", colour = "grey70") + geom_point(colour = "black", alpha=0.5)
等值线图(choropleth map),要将数据中的标识符(identifier)和地图数据中的标识符完全匹配起来。
- 使用map_data()将地图数据转换为数据框;
- 使用merge()操作将该数据框与我们的数据相整合;
- 绘制等值线图。
library(maps)
states <- map_data("state") #将地图数据转换为数据框
arrests <- USArrests
names(arrests) <- tolower(names(arrests))
arrests$region <- tolower(rownames(USArrests))
choro <- merge(states, arrests, by = "region") #合并地图数据框和需要绘制的数据框
choro <- choro[order(choro$order),] ##merge破坏了原始排序,故重新进行排序。
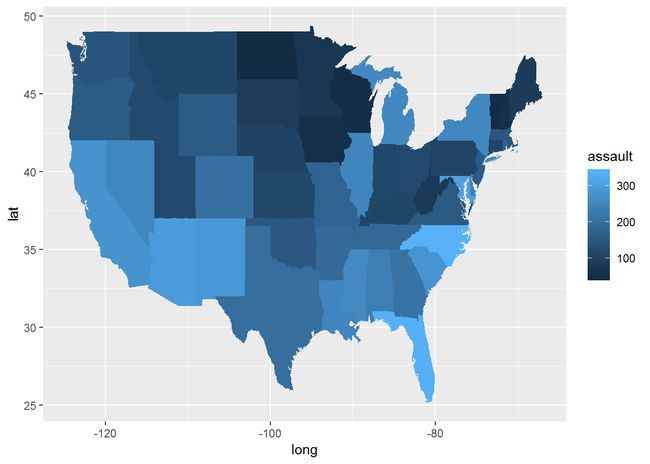
qplot(long, lat, data = choro, group=group, fill=assault, geom="polygon")
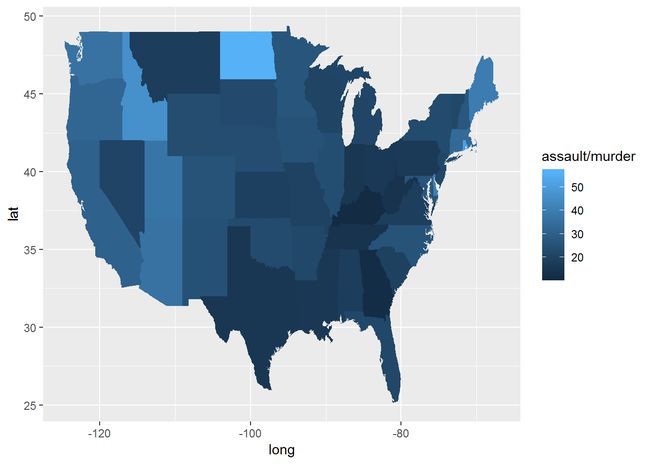
qplot(long, lat, data = choro, group=group, fill=assault/murder, geom="polygon")
使用geom_map()画等值线图不用再合并数据框。
library(maps)
states <- map_data("state")
arrests <- data.frame(region=tolower(rownames(USArrests)), USArrests) #整理数据框,州名(region)必须与地图数据中的州名完全一致,因此改为小写。
ggplot(arrests, aes(map_id = region)) + geom_map(aes(fill=Assault), map=states) + expand_limits(x= states$long, y=states$lat)

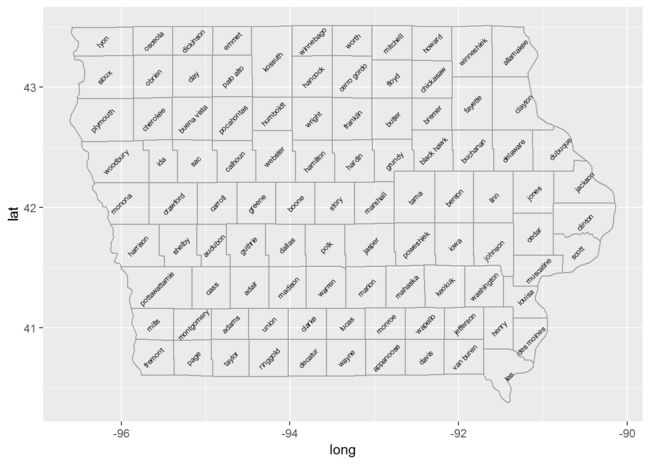
地名标注:利用map_data()计算地区的中心,然后利用这些中心位置数据在地图上对其名称进行标注。
library(plyr) #plyr: the split-apply-combine paradigm for R.
ia <- map_data("county", "iowa")
mid_range <- function(x) mean(range(x, na.rm = TRUE))
#ddply(): For each subset of a data frame, apply function then combine results into a data frame. 对一个数据框的子集应用函数,并把结果合并入一个数据框。
#colwise():Turn a function that operates on a vector into a function that operates column-wise on a data.frame. 在一个数据框中对列操作函数。
centres <- ddply(ia, .(subregion), colwise(mid_range, .(lat, long)))
ggplot(ia, aes(long, lat)) + geom_polygon(aes(group=group), fill=NA, colour="grey60") + geom_text(aes(label=subregion), data=centres, size=2, angle=45)
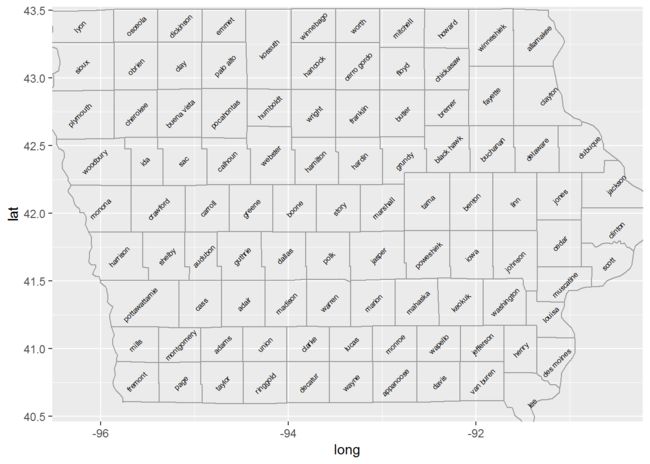
#使用geom_map绘制
ggplot(ia, aes(map_id=subregion)) + geom_map(map=ia, colour="grey60", fill=NA) + geom_text(aes(long, lat, label=subregion), data=centres, size=2, angle=45)
5.8 揭示不确定性
在ggplot2中,共有四类几何对象可以用于这项工作,具体使用哪个取决于x的值是离散的还是连续的,以及我们是否想要展示区间内的中间值,或者是仅仅展示区间。
它们均假设我们对给定x时y的条件分布感兴趣,并且都使用了图形属性ymin和ymax来确定y的值域。
| 变量x的类型 | 仅展示区间 | 同时展示区间和中间值 |
|---|---|---|
| 连续型 | geom_ribbon | geom_smooth(stat="identity") |
| 离散型 | geom_errorbar | geom_crossbar |
| geom_linearange | geom_pointrange |
下例拟合了一个双因素含交互效应回归模型,并且展示了如何提取边际效应(marginal effects)和条件效应(conditional effects),以及如何将其可视化。
d <- subset(diamonds, carat <0.5 & rbinom(nrow(diamonds), 1, 0.2)==1)
d$lcarat <- log10(d$carat)
d$lprice <- log10(d$price)
#剔除整体的线性趋势
detrend <- lm(lprice ~ lcarat, data=d)
d$lprice2 <- resid(detrend)
mod <- lm(lprice2 ~ lcarat*color, data=d)
library(effects)
effectdf <- function(...){ suppressWarnings(as.data.frame(effect(...)))}
color <- effectdf("color", mod)
both1 <- effectdf("lcarat:color", mod)
carat <- effectdf("lcarat", mod, default.levels=50)
both2 <- effectdf("lcarat:color", mod, default.levels =3)
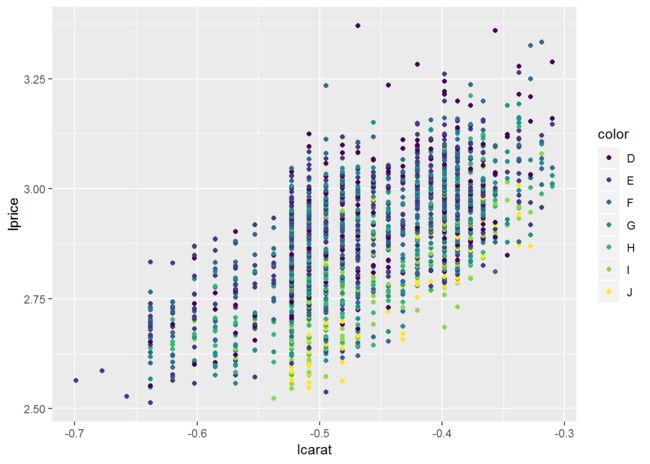
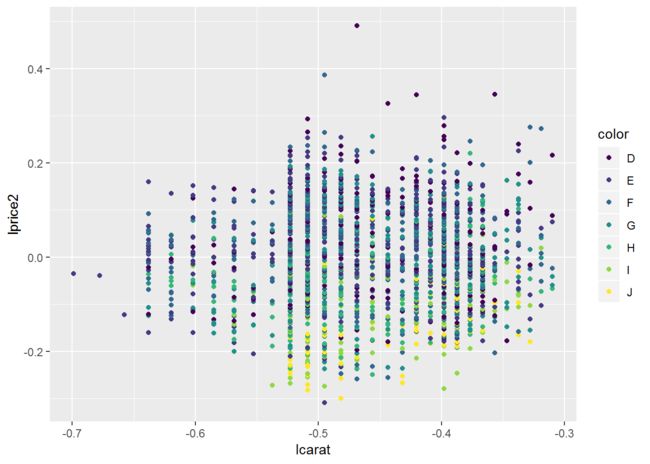
##图5.14
qplot(lcarat, lprice, data=d, colour=color)
qplot(lcarat, lprice2, data=d, colour=color)
#图5.15
fplot <- ggplot(mapping=aes(y=fit, ymin=lower, ymax=upper)) + ylim(range(both2$lower, both2$upper))
# color的边际效应
fplot %+% color + aes(x = color) + geom_point() + geom_errorbar()
# 针对caret的不同水平,变量color的条件效应。
fplot %+% both2 + aes(x=color, colour=lcarat, group=interaction(color, lcarat)) + geom_errorbar() + geom_line(aes(group=lcarat)) + scale_colour_gradient()
#carat的边际效应
fplot %+% carat + aes(x=lcarat) + geom_smooth(stat="identity")
# 针对变量color的不同水平,变量carat的条件效应。误差带显示95%的逐点置信区间。
ends <- subset(both1, lcarat==max(lcarat))
fplot %+% both1 + aes(lcarat, colour=color) +
geom_smooth(stat = "identity") +
scale_colour_hue() + theme(legend.position = "none") +
geom_text(aes(label=color, x=lcarat+0.02), ends )
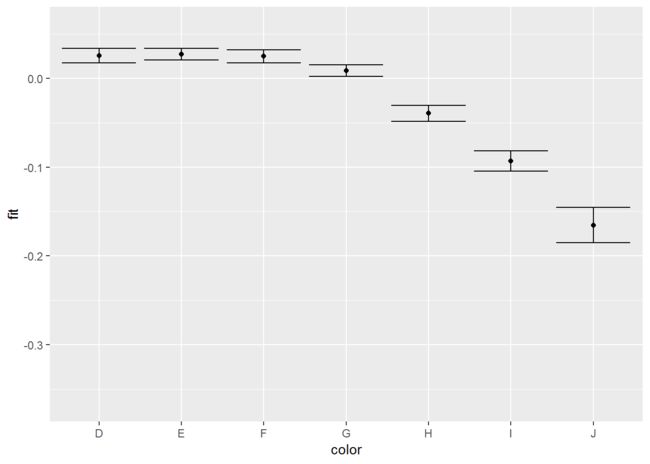
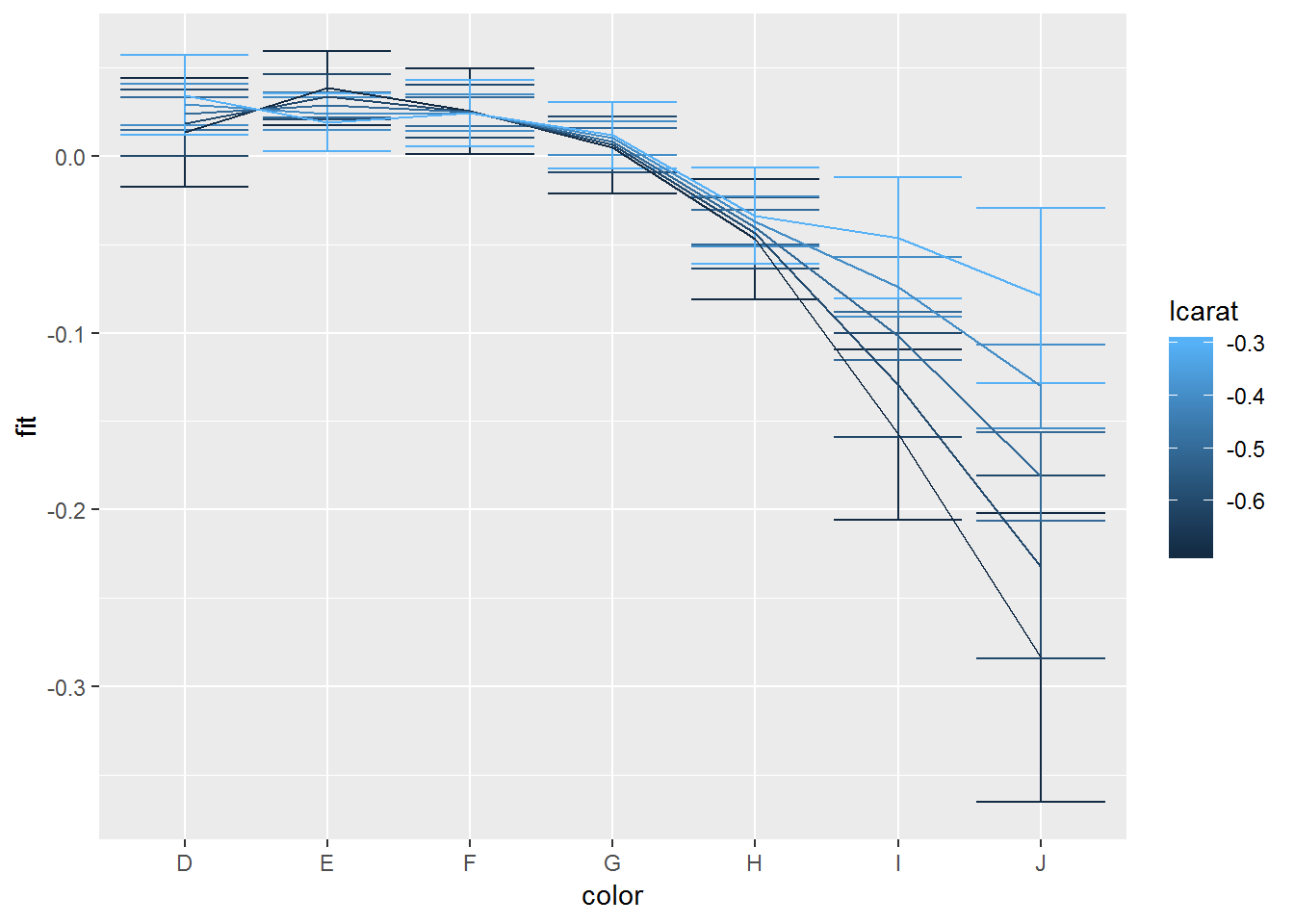
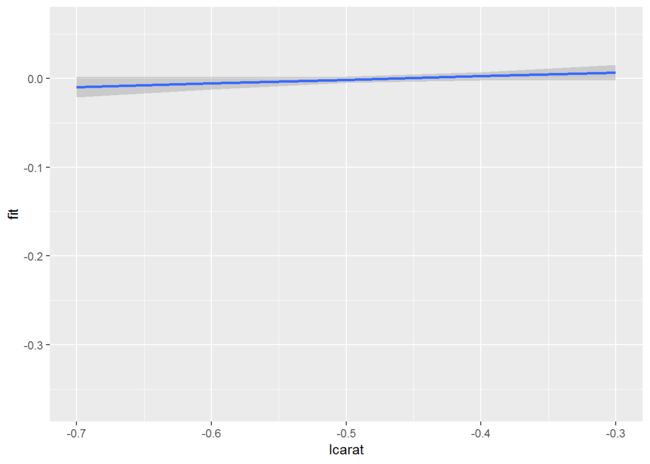
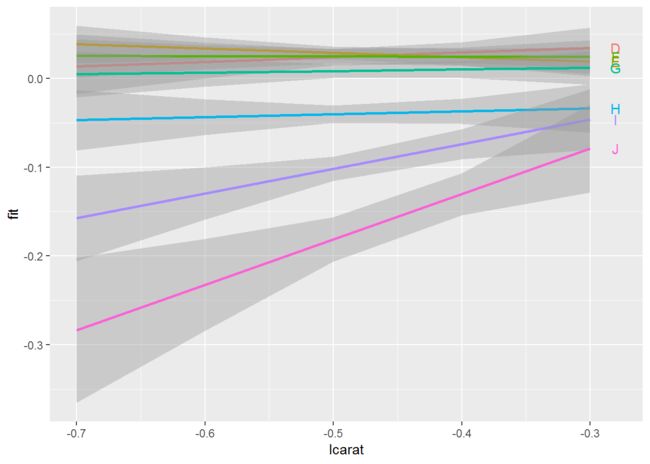
注意,在为这类图形添加题注时,我们需要细致地描述其中所含置信区间的本质,并说明观察置信区间之间重叠是否有意义。
+ 说明: 当比较不同组时,如果区间没有重叠,则说明差异显著。
即,这些标准误是针对单组的均值的,还是针对不同组件均值之差的。
在计算和展示这些标准误时,multcomp包和multcompView包将非常有用,同时他们在多重比较中能正确地对自由度进行调整。
5.9 统计摘要
对于每个x的取值,计算对应y值的统计摘要,这一角色由stat_summary()担当。
5.9.1 单独的摘要计算函数
参数fun.y, fun.ymin和fun.ymax能够接受简单的数值型摘要计算函数,即该函数能够传入一个数值向量并返回一个数值型结果,如mean(), median(), min(), max()。
midm <- function(x) mean(x, trim=0.5)
m2 + stat_summary(aes(colour="trimmed"), fun.y=midm, geom="point") +
stat_summary(aes(colour="raw"), fun.y=mean, geom="point") +
scale_color_hue("Mean")
5.9.2 统一的摘要计算函数
fun.data可以支持更复杂的摘要计算函数,如下表罗列的来自Hmisc包中的函数。
也可以自己编写。
| stat_summary函数名 | Hmisc包中原名 | 中间值类型 | 所计算区间 |
|---|---|---|---|
| mean_cl_norm() | smean.cl.normal() | 均值 | 正态渐近所得标准误 |
| mean_cl_boot() | smean.cl.boot() | 均值 | Bootstrap所得标准误 |
| mean_sdl() | smean.sdl() | 均值 | 标准差的倍数 |
| median_hilow() | smedian.hilow() | 中位数 | 尾部面积相同的外分位点对 |
注意:这些函数调用自Hmisc包中的摘要计算函数,stat_summary调用需要事先安装Hmisc包。
5.10 添加图形注解
在使用额外的标签注解图形时,注意,这些注解仅仅是额外的数据而已。
添加图形注解有两种基本的方式:逐个添加或批量添加。
- 逐个添加的方式适合少量的、图形属性多样化的注解。
- 如果需要添加多个具有类似属性的注解,则将它们放到数据框中一次性添加完成。
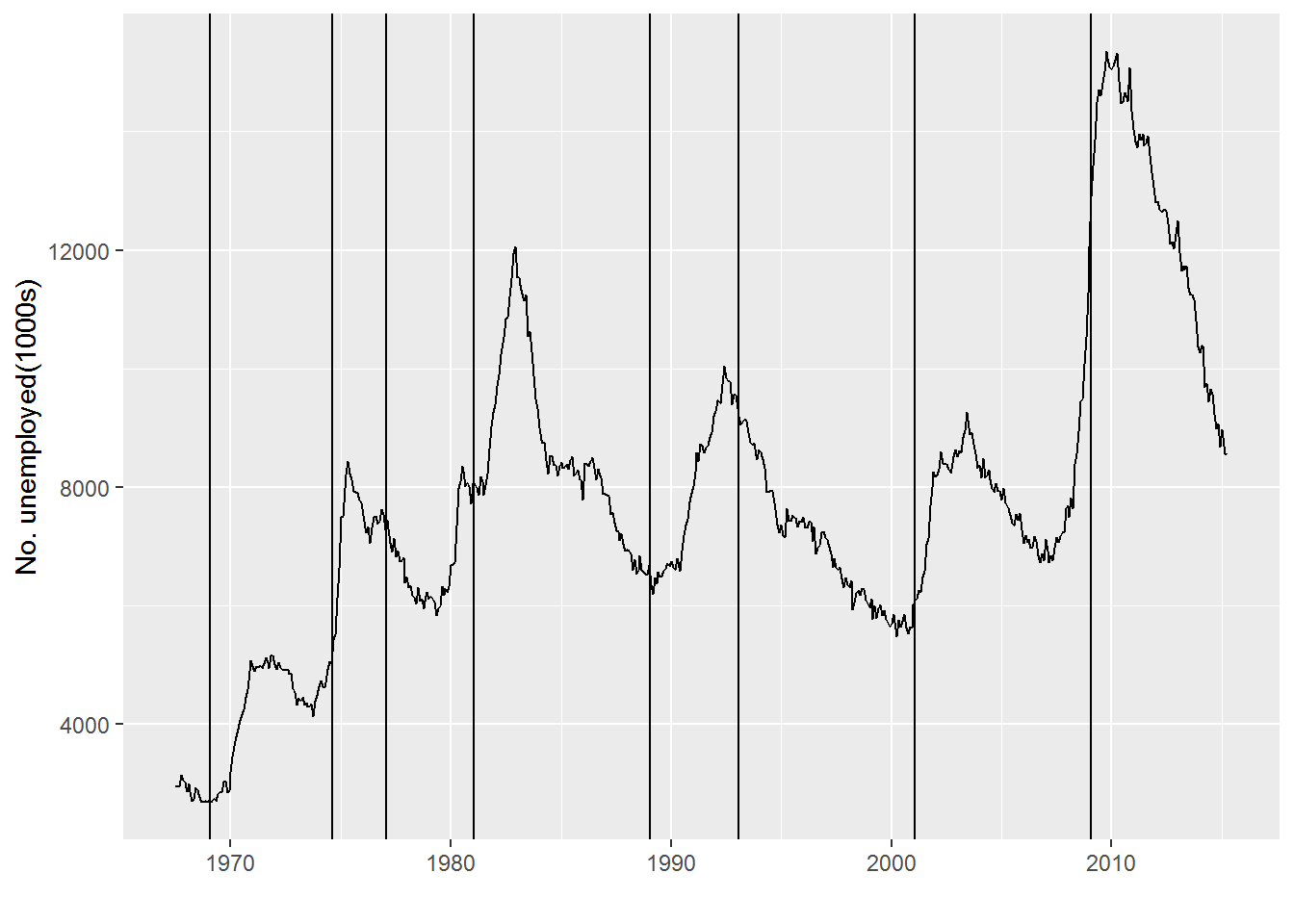
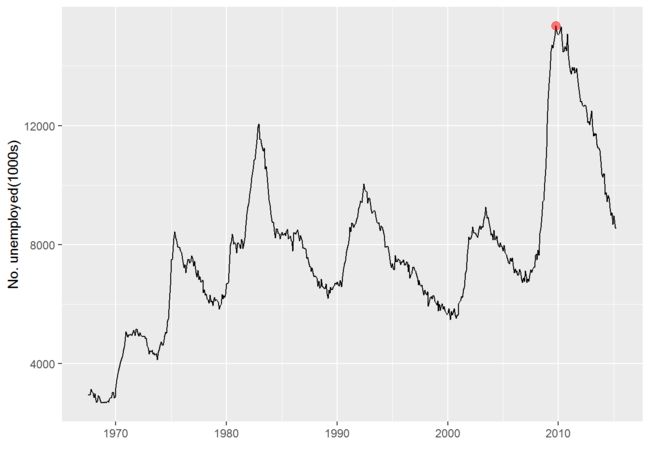
unemp <- qplot(date, unemploy, data = economics, geom="line", xlab="", ylab="No. unemployed(1000s)") #economics经济周期数据框,变量有date, pce, pop, psavert, unempmed, unemploy.
presidential <- presidential[-(1:3),] #presidential总统任期数据框,变量有name, start, end, party。
yrng <- range(economics$unemploy) #失业人数取值范围
xrng <- range(economics$date)
unemp + geom_vline(aes(xintercept = as.numeric(start)), data=presidential)
library(scales) #Generic plot scaling methods
# geom_rect()中mapping参数:默认NULL,继承ggplot()调用的映射。
# geom_rect()中data参数:默认为NULL,继承ggplot()调用的数据框。
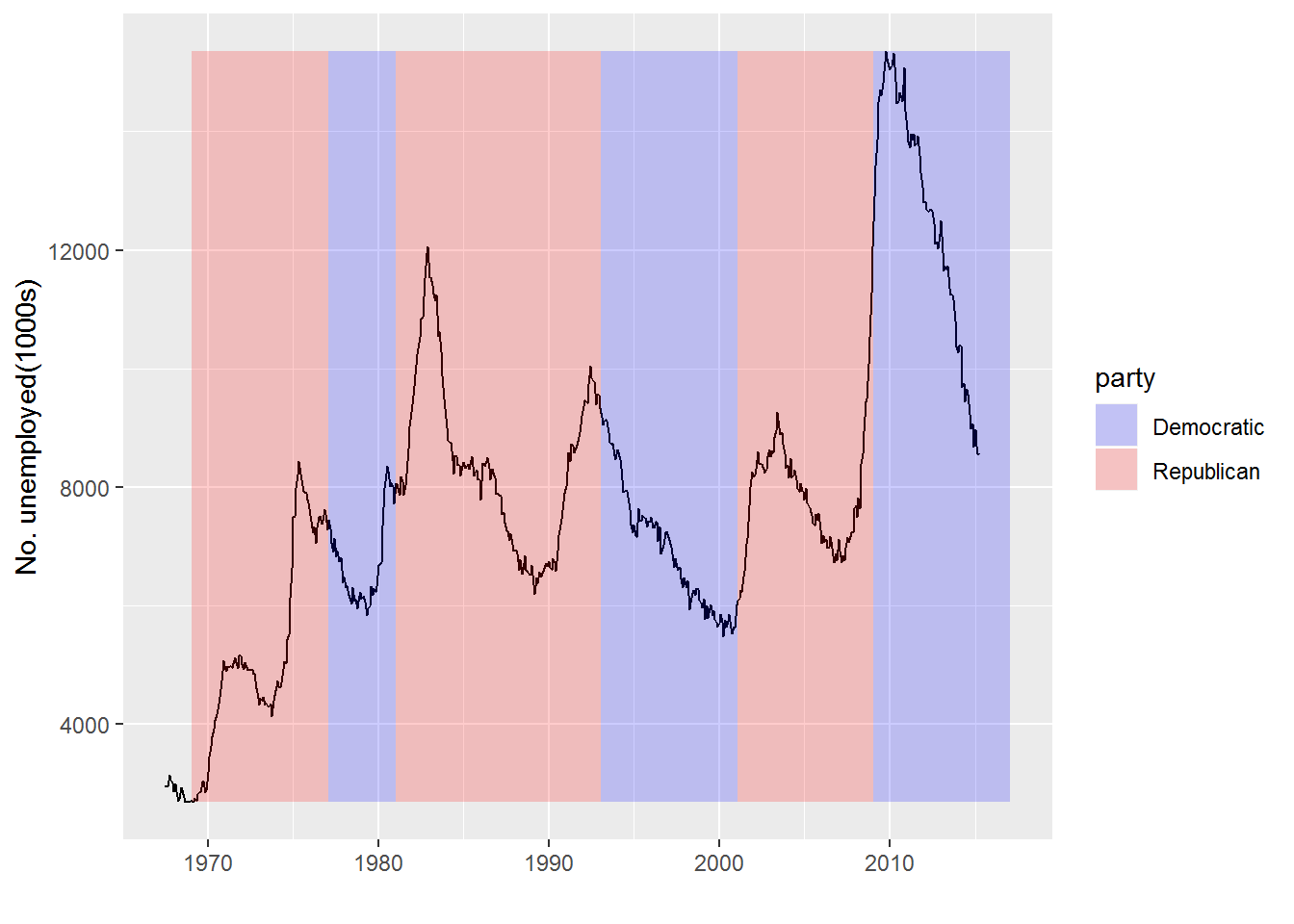
unemp + geom_rect(aes(NULL, NULL, xmin = start, xmax=end, fill=party), ymin=yrng[1], ymax=yrng[2], data=presidential, alpha=0.2) + scale_fill_manual(values=c("blue", "red"))
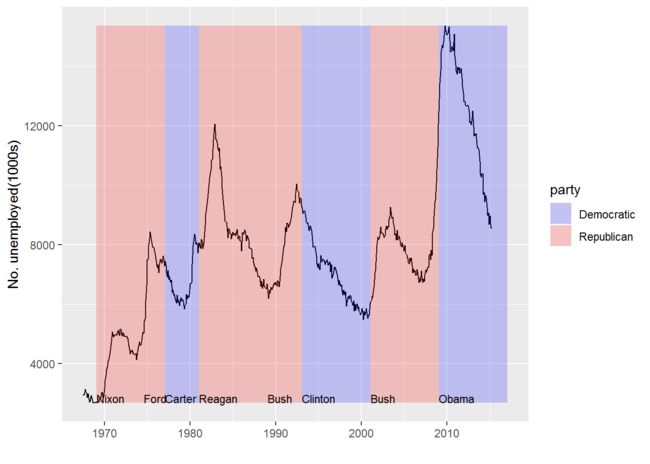
last_plot() + geom_text(aes(x=start, y=yrng[1], label=name), data=presidential, size=3, hjust=0, vjust=0)
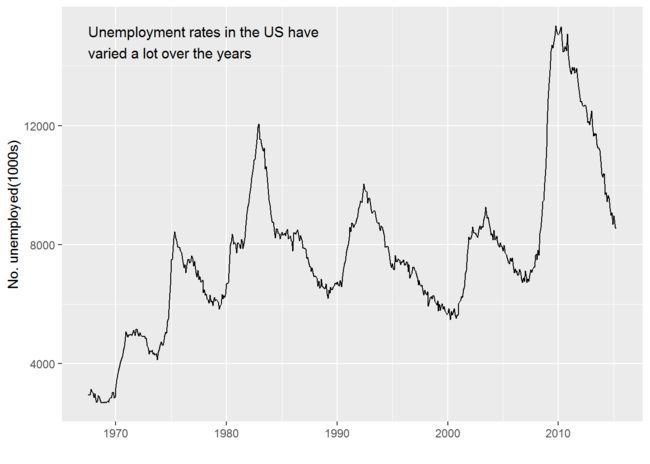
caption <- paste(strwrap("Unemployment rates in the US have varied a lot over the years", 40), collapse = "\n") #strwrap()给字符串套用固定的格式。
unemp + geom_text(aes(x,y,label=caption), data = data.frame(x=xrng[1], y=yrng[2]), hjust=0, vjust=1, size=4) #hjust水平0左适应,1右适应;vjust垂直,0下适应,1上适应。
# 原书的数据截止至2006,数据框的数据更新至2017。因此,根据新数据,调整作图(标题位置)。
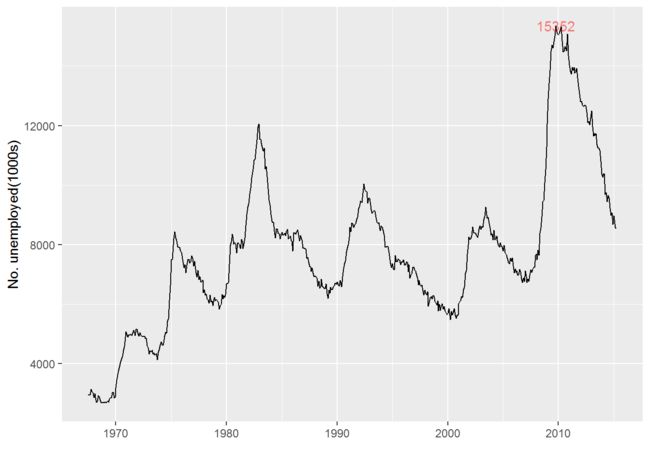
highest <- subset(economics, unemploy == max(unemploy))
#用点标记最大失业
unemp + geom_point(data = highest, size=3, colour="red", alpha=0.5)
#用数据标记最大失业
unemp + geom_text(aes(date, unemploy, label=unemploy), colour="red", alpha=0.5, data = highest)
- geom_text,添加文字叙述或为点添加标签。
- geom_vline, geom_hline,添加垂直线或水平线。
- geom_abline,添加任意斜率和截距的直线。
- geom_rect,添加感兴趣的矩形区域。
-
geom_line, geom_path和geom_segment添加直线。他们都有一个arrow参数,可以用来在线上放置一个箭头。也可以使用arrow()函数绘制箭头。
 美国总统与经济-1.png
美国总统与经济-1.png
5.11 含权数据
在处理整合后的数据时,数据集每一行可能代表了多种观测值,这时我们需要以某种方式把权重变量考虑进去。
以2000年美国人口普查中,中西部各州的统计数据为例。数据中包含的是比例型数据,如白人比例,贫困线以下人口比例,大学学历人口比例等,和每个郡的基本信息,如面积、人口总数、人口密度。
有一些数据可能可以作为权重使用:
- 什么都不用,即直接观察郡的数量。
- 总人数,与原始的绝对数配合使用。
- 面积,用于研究地缘效应。
权重的不同将极大影响图形内容以及观察结论。
有两种可以用于表现权重的可调图形属性。
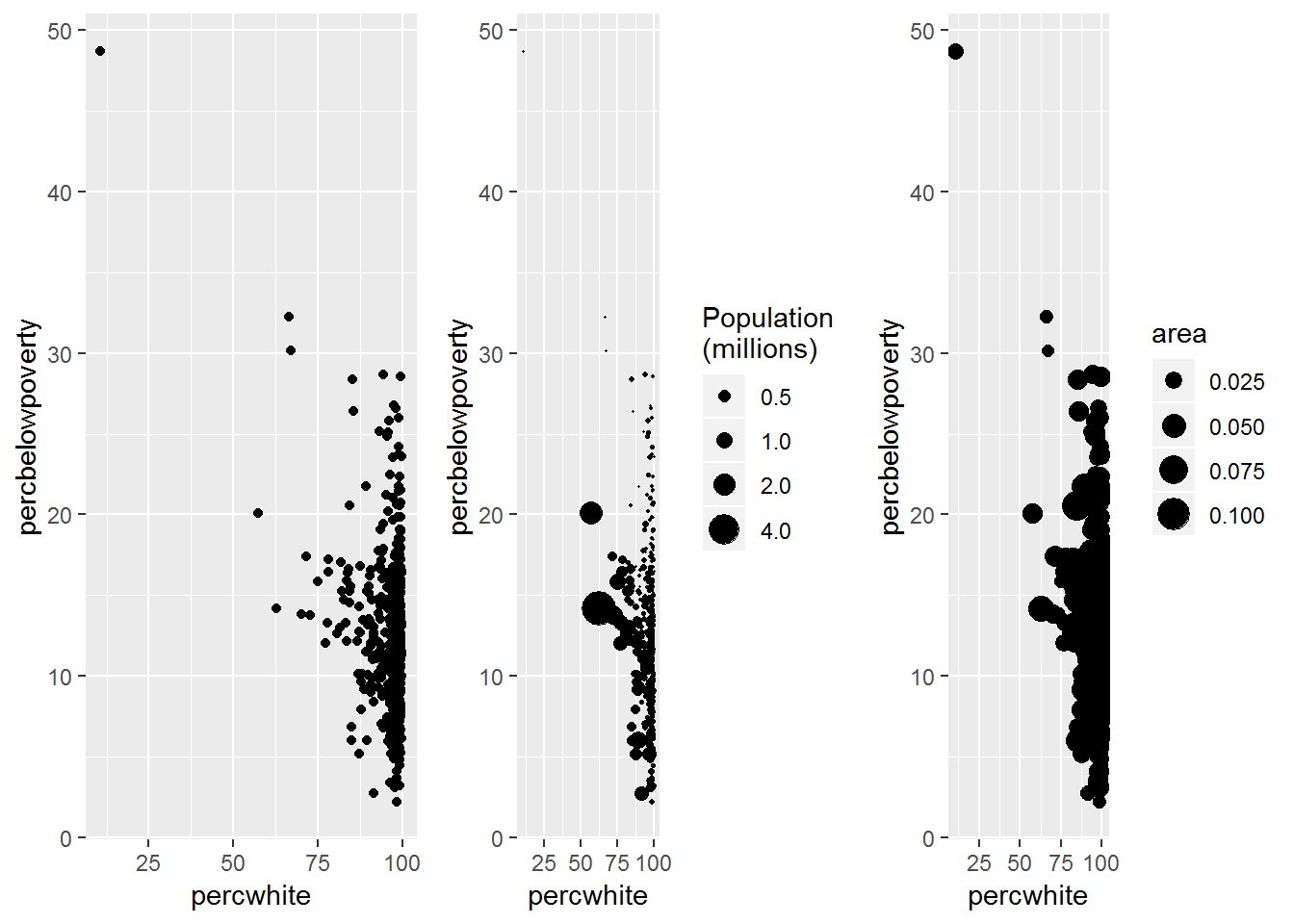
- 首先,对于线和点这类简单的几何对象,可以根据点的数量调整图形属性size来改变点的大小。
q1 <- qplot(percwhite, percbelowpoverty, data=midwest)
q2 <- qplot(percwhite, percbelowpoverty, data = midwest, size=poptotal/1e6) + scale_size_area("Population\n(millions)", breaks=c(0.5,1,2,4))
q3 <- qplot(percwhite, percbelowpoverty, data = midwest, size=area) + scale_size_area()
grid.arrange(q1, q2, q3, ncol=3)
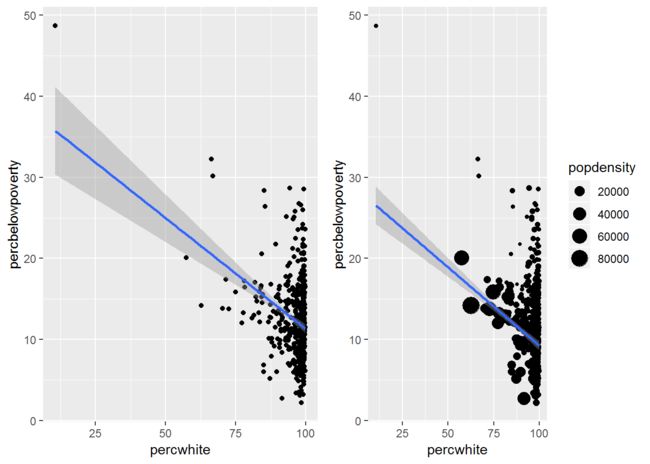
- 对于更复杂的、涉及统计变换的情况,我们通过修改weight图形属性来表现权重。这些权重将被传递给统计汇总计算函数。
- 在权重有意义的情况下,各种元素基本都支持权重设定,如各类平滑器、分位回归、箱线图、直方图以及各类密度图。
- 我们无法直接看到这个权重变量,它也没有对应图例,但却会改变统计汇总的结果。
lm_smooth <- geom_smooth(method = lm, size=1)
q4 <- qplot(percwhite, percbelowpoverty, data=midwest) + lm_smooth
q5 <- qplot(percwhite, percbelowpoverty, data=midwest, weight=popdensity, size=popdensity)+lm_smooth
#人口密度作为权重对白人比例与贫困线以下人口比例的关系的影响
grid.arrange(q4, q5, ncol=2)
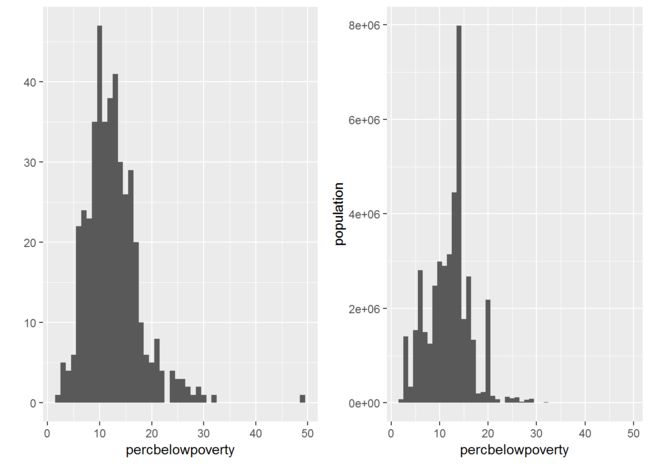
q6 <- qplot(percbelowpoverty, data=midwest, binwidth=1) #对郡的数量分布的观察
q7 <- qplot(percbelowpoverty, data=midwest, binwidth=1, weight=poptotal)+ylab("population") #对人口数量分布的观察
grid.arrange(q6, q7, ncol=2)