python多线程爬取王者荣耀高清壁纸过程
多线程与爬虫
- 目标url
-
- json中查找url
- 访问url
-
- 读取json
-
- 查看json的list数组
- 全部图片
- 粗暴的单线程获取
- 多线程执行
目标url
查看http://pvp.qq.com/web201605/wallpaper.shtml
有一个需要注意的就是图片url在html源码中找不到,直接被js渲染了,可以仔细查找访问服务器的url

查看html源码找不到该链接
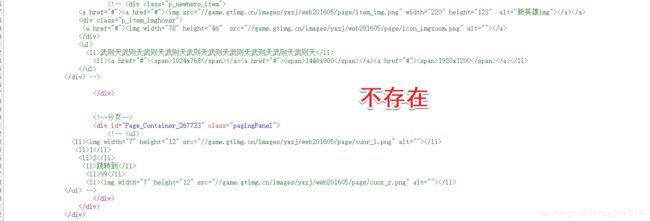
json中查找url
在一个woKList中
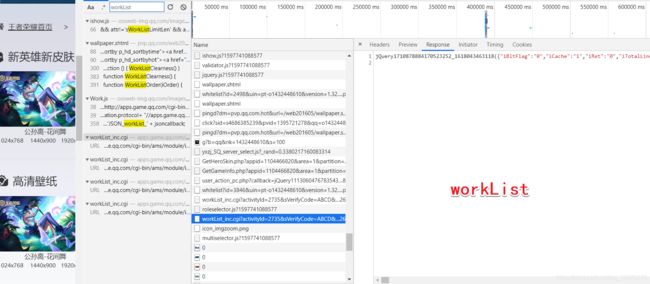
使用csdn的json插件打开,查看链接
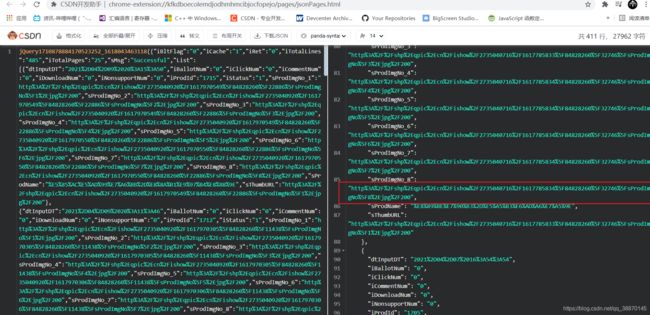
这些链接明显不正常需要处理
引用urllib库的parse
按照标准, URL 只允许一部分 ASCII 字符(数字字母和部分符号),其他的字符(如汉字)是不符合 URL 标准的
unqutote进行编码
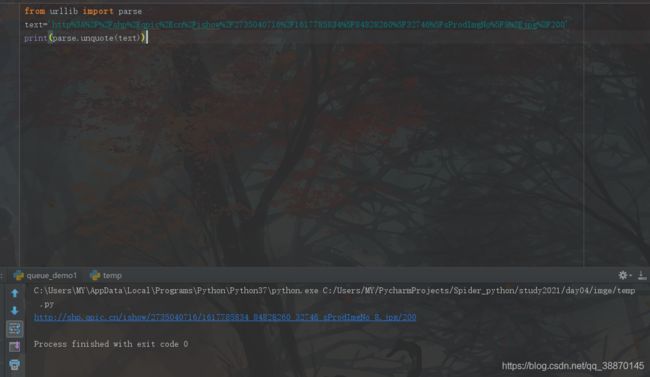
可以访问,明显看出这分辨率不是高清壁纸
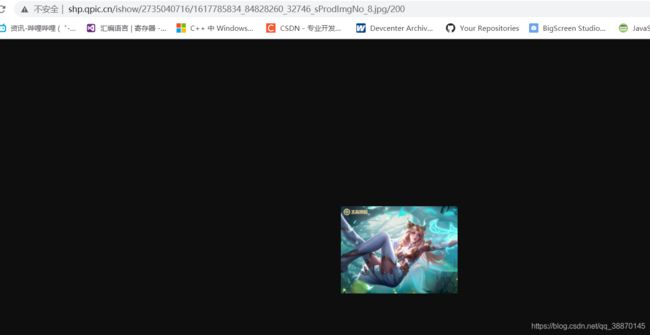
对比高清壁纸
对比高清壁纸:
python获取的url
http://shp.qpic.cn/ishow/2735040716/1617785834_84828260_32746_sProdImgNo_8.jpg/200
高清图的url
http://shp.qpic.cn/ishow/2735040716/1617785834_84828260_32746_sProdImgNo_8.jpg/0
url结尾的数字是0,处理一下url就可以啦!
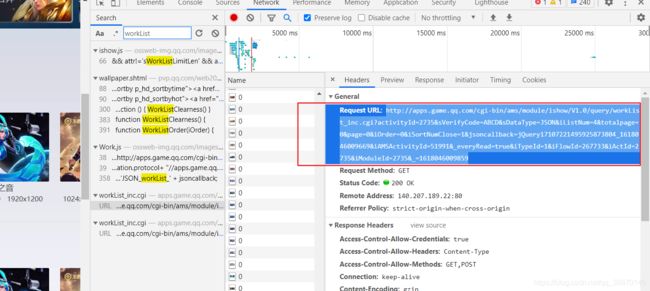
访问url
查看RequestURL
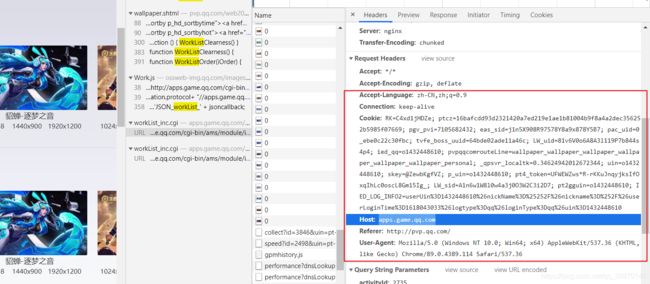
添加ua
import requests
from urllib import parse
from lxml import etree
import xlwt
def requests_get(url):#访问url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Referer":"http://pvp.qq.com/web201605/wallpaper.shtml",
"Host": "apps.game.qq.com",
# "Cookie": '***'
#
}
htmlText=''
try:
resp = requests.get(url, headers=headers)
htmlText = resp.text # 返回的不是html
except Exception as e:
print(e)
return htmlText
def deal_url(text):#url进行编码
return parse.unquote(text)
if __name__=='__main__':
url='http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17107221495925873804_1618046009669&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1618046009859'
print(requests_get(url))
查看打印的内容,ok呼应上了但是,但是数据在jquery中 
去掉url中jsoncallback=jQuery
- 原始
url=‘http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17107221495925873804_1618046009669&iAMSActivityId=51991&everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&=1618046009859’- 去掉之后
url=‘http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&=1618046009859’
返回json的格式
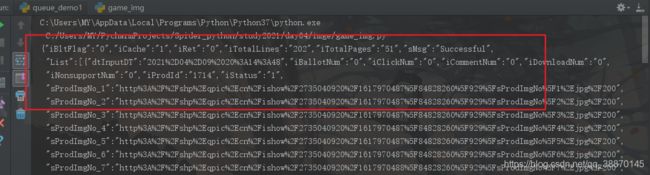
读取json
查看json的list数组
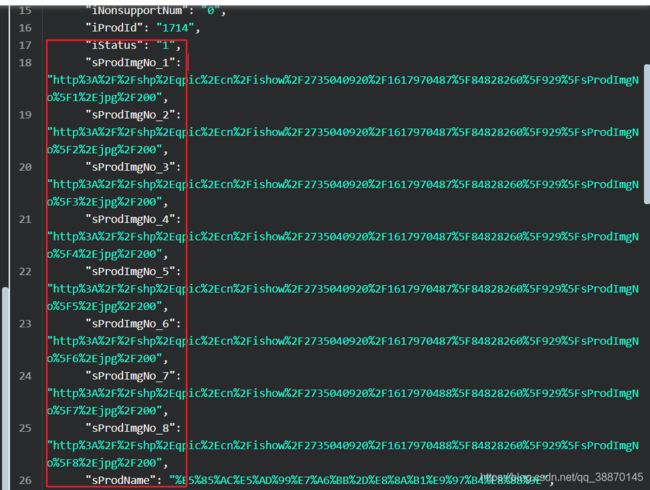
List数组
- sProdImgNo_[1-8] 对应8张不同分辨率的图片
- sProdName 图片名字

初步获取图片的名字和8张分辨率不同的图片
import requests
from urllib import parse
from lxml import etree
import xlwt
def requests_get(url):#访问url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Referer":"http://pvp.qq.com/web201605/wallpaper.shtml",
"Host": "apps.game.qq.com",
"Cookie": '***'
}
htmlText=''
try:
resp = requests.get(url, headers=headers)
json_url=resp.json() #返回json
datas=json_url['List']
for d in datas:
img_data=img_url(d)
img_name=parse.unquote(d['sProdName'])
print('-'*30)
print(img_name)
print(img_data)
print('-' * 30)
except Exception as e:
print(e)
return htmlText
def img_url(data):#url进行编码
img_data=[]
for x in range(1,9):#获取8张分辨率不同的图片
img_url=parse.unquote(data['sProdImgNo_%d'%x].replace('200','0'))#替换为高清的url
img_data.append(img_url)
return img_data
if __name__=='__main__':
url = 'http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1618046009859'
print(requests_get(url))
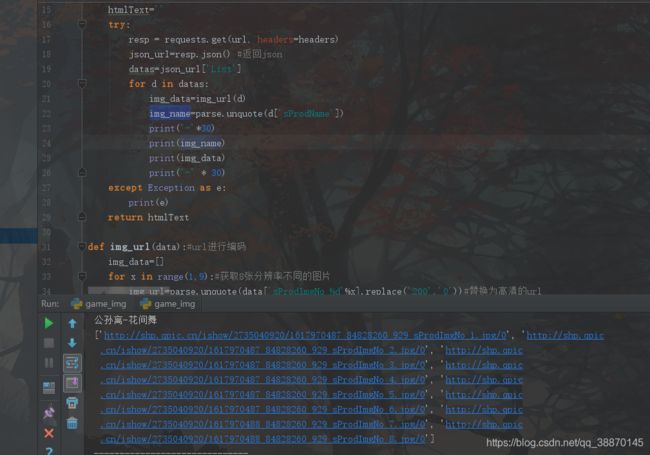
全部图片
只是获取4个英雄的图片
修改iListNum=20获取20个英雄的
修改page实现翻页
url='''http://apps.game.qq.com/cgi-
bin/ams/module/ishow/V1.0/query/workList_inc.cgi?
activityId=2735&sVerifyCode=ABCD&sDataType=JSON
&iListNum=4
&totalpage=0
&page=0
&iOrder=0
&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1618046009859'''
粗暴的单线程获取
import requests
from urllib import parse,request
import os
def requests_get(url):#访问url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Referer":"http://pvp.qq.com/web201605/wallpaper.shtml",
"Host": "apps.game.qq.com",
"Cookie": '***'
}
try:
resp = requests.get(url, headers=headers)
json_url=resp.json() #返回json
datas=json_url['List']
for d in datas:
img_data=img_url(d)
img_name=parse.unquote(d['sProdName']).replace("1:1",'').strip()
dirpath = os.path.join('images',img_name)
if not os.path.exists(dirpath):
os.mkdir(dirpath) # 创建目录
for index,image_url in enumerate(img_data):#枚举
request.urlretrieve(image_url,os.path.join(dirpath,'%d.jpg'%(index+1)))
print('%s下载完成'%(image_url))
except Exception as e:
print(e)
return True
def img_url(data):#url进行编码
img_data=[]
for x in range(1,9):#获取8张分辨率不同的图片
img_url=parse.unquote(data['sProdImgNo_%d'%x].replace('200','0'))#替换为高清的url
img_data.append(img_url)
return img_data
if __name__=='__main__':
url = 'http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=40&totalpage=0&page={page}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1618046009859'
for i in range(1,18):
url=url.format(page=i)#替换页码
requests_get(url)
多线程执行
模拟生产者消费者
import requests
from urllib import parse,request
import os
import threading
from queue import Queue
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Referer": "http://pvp.qq.com/web201605/wallpaper.shtml",
"Host": "apps.game.qq.com",
"Cookie": '***'
}
class Producer(threading.Thread):
def __init__(self,page_que,img_que,*arges,**kwargs):
threading.Thread.__init__(self)#重写
self.page_que=page_que
self.img_que=img_que
def run(self)->None:
while not self.page_que.empty():
page_url=self.page_que.get()
try:
resp = requests.get(page_url, headers=headers)
json_url = resp.json() # 返回json
datas = json_url['List']
for d in datas:
img_data = img_url(d)
img_name = parse.unquote(d['sProdName']).replace("1:1", '').strip()
dirpath = os.path.join('images', img_name)
if not os.path.exists(dirpath):
os.mkdir(dirpath) # 创建目录
for index, image_url in enumerate(img_data): # 枚举
self.img_que.put({
'image_url':image_url,'img_path':os.path.join(dirpath, '%d.jpg' % (index + 1))})#图片路径加入队列
except Exception as e:
print(e)
#执行某一页的获取url
#下载
class Consumer(threading.Thread):#下载图片
def __init__(self,img_que,*arges,**kwargs):
threading.Thread.__init__(self)
self.img_que=img_que
def run(self)->None:
while True:
try:
img_obj = self.img_que.get(timeout=8)
img_url = img_obj.get('image_url')
img_path = img_obj.get('img_path')
try:
request.urlretrieve(img_url, img_path)
print('%s下载完成' % (img_path))
except:
print('%s下载失败' % (img_path))
except:
break
def img_url(data):#url进行编码
img_data=[]
for x in range(1,9):#获取8张分辨率不同的图片
img_url=parse.unquote(data['sProdImgNo_%d'%x].replace('200','0'))#替换为高清的url
img_data.append(img_url)
return img_data
if __name__=='__main__':
url = 'http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=40&totalpage=0&page={page}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1618046009859'
page_queue=Queue(18)# 18页
img_queue=Queue(1000)#
for i in range(1,18):
url=url.format(page=i)#替换页码
page_queue.put(url)#页面url提取
for i in range(3):
th1=Producer(page_queue,img_queue,name='生产者%s号'%i)
th1.start()
for i in range(5):
th1=Consumer(img_queue,name='消费者%s号'%i)
th1.start()

抓取成功!